Entwerfen von Indizes
SQL Server bietet mehrere Indextypen zur Unterstützung verschiedener Workloads. Auf einer hohen Ebene kann man sich einen Index als eine Struktur auf dem Datenträger vorstellen, die mit einer Tabelle oder einer Sicht verknüpft ist und es SQL Server ermöglicht, die dem Indexschlüssel (der aus einer oder mehreren Spalten in der Tabelle oder Sicht besteht) zugeordneten Zeilen leichter zu finden, als im Vergleich zum Durchsuchen der gesamten Tabelle.
Gruppierte Indizes
Eine häufige Frage im Vorstellungsgespräch für DBAs besteht darin, den Kandidaten nach dem Unterschied zwischen einem gruppierten und einem nicht gruppierten Index zu fragen, da Indizes grundlegende Datenspeichertechnologien in SQL Server sind. Ein gruppierter Index ist die zugrunde liegende Tabelle, die in auf Grundlage des Schlüsselwerts sortierter Reihenfolge gespeichert wird. Pro Tabelle kann es nur einen gruppierten Index geben, da die Zeilen nur in einer Reihenfolge gespeichert werden können. Eine Tabelle ohne gruppierten Index wird als Heap bezeichnet, und Heaps werden normalerweise nur als Stagingtabellen verwendet. Ein wichtiges Leistungsdesignprinzip ist es, den Schlüssel Ihres gruppierten Indexes so schmal wie möglich zu halten. Bei der Auswahl einer oder mehrerer Schlüsselspalten für Ihren gruppierten Index sollten Sie Spalten auswählen, die eindeutig sind oder die viele eindeutige Werte enthalten. Eine weitere Eigenschaft eines guten gruppierten Indexschlüssels sind Datensätze, auf die sequenziell zugegriffen wird, und die häufig zum Sortieren der aus der Tabelle abgerufenen Daten verwendet werden. Wenn Sie den gruppierten Index der Spalte für die Sortierung verwenden, können Sie die Kosten für die Sortierung bei jeder Ausführung der Abfrage vermeiden, da die Daten bereits in der gewünschten Reihenfolge gespeichert sind.
Hinweis
Wenn wir sagen, dass die Tabelle in einer bestimmten Reihenfolge „gespeichert“ wird, beziehen wir uns auf die logische Reihenfolge, nicht auf die physische Reihenfolge auf dem Datenträger. Indizes besitzen Zeiger zwischen Seiten, und die Zeiger helfen, die logische Reihenfolge zu erstellen. Wenn Sie einen Index in der Reihenfolge durchsuchen, folgt SQL Server den Zeigern von Seite zu Seite. Unmittelbar nach dem Erstellen eines Indexes wird dieser höchstwahrscheinlich auch in physischer Reihenfolge auf der Festplatte gespeichert, aber wenn Sie anfangen, Änderungen an den Daten vorzunehmen, und neue Seiten zum Index hinzugefügt werden müssen, geben die Zeiger immer noch die korrekte logische Reihenfolge an, aber die neuen Seiten werden höchstwahrscheinlich nicht in physischer Reihenfolge auf dem Datenträger sein.
Nicht gruppierte Indizes
Nicht gruppierte Indizes sind von den Datenzeilen getrennte Strukturen. Ein nicht gruppierter Index enthält die für den Index definierten Schlüsselwerte sowie einen Zeiger auf die Datenzeile, die den Schlüsselwert enthält. Sie können mithilfe der in SQL Server enthaltenen Spaltenfunktion zusätzliche Nicht-Schlüsselspalten auf der Blattebene des nicht gruppierten Index hinzufügen, um mehr Spalten abzudecken. Sie können mehrere nicht gruppierte Indizes für eine Tabelle erstellen.
Das folgende Beispiel zeigt, wann Sie einen Index hinzufügen oder Spalten zu einem vorhandenen nicht gruppierten Index hinzufügen müssen.

Der Abfrageplan zeigt an, dass für jede Zeile, die über die Indexsuche abgerufen wird, weitere Daten aus dem gruppierten Index (der Tabelle selbst) abgerufen werden müssen. Es gibt einen nicht gruppierten Index, der aber nur die Produktspalte enthält. Wenn Sie die anderen Spalten in der Abfrage zu einem nicht gruppierten Index hinzufügen, können Sie sehen, wie sich der Ausführungsplan ändert, um die Schlüsselsuche zu eliminieren.

Der oben erstellte Index ist ein Beispiel für einen abdeckenden Index. Zusätzlich zur Schlüsselspalte fügen Sie zusätzliche Spalten hinzu, um die Abfrage abzudecken und den Zugriff auf die Tabelle selbst zu vermeiden.
Sowohl nicht gruppierte als auch gruppierte Indizes können als eindeutig definiert werden, d. h. es darf keine Duplikation der Schlüsselwerte geben. Eindeutige Indizes werden automatisch erstellt, wenn Sie eine PRIMARY KEY- oder UNIQUE-Einschränkung für eine Tabelle erstellen.
Dieser Abschnitt konzentriert sich auf B-Strukturindizes in SQL Server, auch als Zeilenspeicherindizes bezeichnet. Die folgende Abbildung stellt die allgemeine Struktur einer B-Struktur dar:
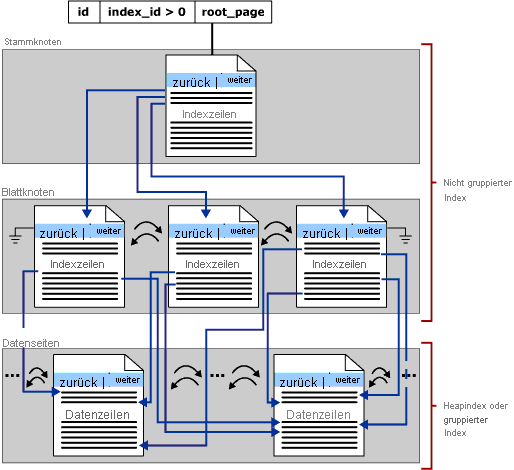
Jede Seite in einer Index-B-Struktur wird als Indexknoten bezeichnet, und der oberste Knoten der B-Struktur wird als Stammknoten bezeichnet. Die untersten Knoten in einem Index werden Blattknoten genannt, und die Sammlung der Blattknoten ist die Blattebene.
Indexdesign ist eine Mischung aus Kunst und Wissenschaft. Ein schmaler Index mit wenigen Spalten in seinem Schlüssel benötigt weniger Zeit für die Aktualisierung und hat einen geringeren Wartungsaufwand; allerdings ist er möglicherweise nicht für so viele Abfragen zu gebrauchen wie ein breiterer Index, der mehr Spalten enthält. Möglicherweise müssen Sie mit verschiedenen Indizierungsansätzen experimentieren, die auf den von den Abfragen Ihrer Anwendung ausgewählten Spalten basieren. Abfrageoptimierer wählen in der Regel das aus, was sie für den besten vorhandenen Index für eine Abfrage halten; das bedeutet jedoch nicht, dass kein besserer Index erstellt werden könnte.
Die korrekte Indizierung einer Datenbank kann eine komplexe Aufgabe sein. Wenn Sie Ihre Indizes für eine Tabelle planen, sollten Sie ein paar grundlegende Prinzipien beachten:
- Grundlegendes zu den Workloads des Systems. Tabellen, die hauptsächlich für Einfügevorgänge verwendet werden, profitieren weniger von zusätzlichen Indizes als Tabellen, die für Data Warehouse-Vorgänge mit hoher Leseaktivität verwendet werden.
- Optimieren Sie Indizes für die am häufigsten ausgeführten Abfragen.
- Wählen Sie geeignete Datentypen für Spalten in Ihren Abfragen aus. Indizes funktionieren am besten mit ganzzahligen Datentypen, eindeutigen Spalten oder Nicht-Null-Spalten.
- Erstellen Sie nicht gruppierte Indizes für Spalten, die häufig in Prädikaten und Join-Klauseln verwendet werden, und halten Sie diese so schmal wie möglich, um den Mehraufwand zu minimieren.
- Berücksichtigen Sie die Datengröße/-menge. Tabellenscans in kleinen Tabellen sind relativ kostengünstig, während Scans in großen Tabellen kostspielig sind.
Eine weitere Option, die SQL Server bietet, ist die Erstellung gefilterter Indizes. Gefilterte Indizes eignen sich ideal für Spalten in großen Tabellen, in denen ein erheblicher Prozentsatz der Zeilen denselben Wert in dieser Spalte hat. Das folgende Beispiel ist eine Mitarbeitertabelle, in der alle Mitarbeitenden gespeichert sind, einschließlich derjenigen, die das Unternehmen verlassen haben oder in den Ruhestand gegangen sind.
CREATE TABLE [HumanResources].[Employee](
[BusinessEntityID] [int] NOT NULL,
[NationalIDNumber] [nvarchar](15) NOT NULL,
[LoginID] [nvarchar](256) NOT NULL,
[OrganizationNode] [hierarchyid] NULL,
[OrganizationLevel] AS ([OrganizationNode].[GetLevel]()),
[JobTitle] [nvarchar](50) NOT NULL,
[BirthDate] [date] NOT NULL,
[MaritalStatus] [nchar](1) NOT NULL,
[Gender] [nchar](1) NOT NULL,
[HireDate] [date] NOT NULL,
[SalariedFlag] [bit] NOT NULL,
[VacationHours] [smallint] NOT NULL,
[SickLeaveHours] [smallint] NOT NULL,
[CurrentFlag] [bit] NOT NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL)
In dieser Tabelle gibt es eine Spalte namens CurrentFlag, die angibt, ob eine mitarbeitende Person derzeit beschäftigt ist. In diesem Beispiel wird der Datentyp bit verwendet, der zwei Werte darstellt: Eins für derzeit beschäftigt und Null für derzeit nicht beschäftigt. Durch Erstellen eines gefilterten Index mit WHERE CurrentFlag = 1 für die Spalte CurrentFlag können Abfragen zu aktuellen Mitarbeitenden effizient durchgeführt werden.
Sie können auch Indizes für Ansichten erstellen, was zu erheblichen Leistungssteigerungen führen kann, wenn Sichten Abfrageelemente wie Aggregationen und/oder Tabellenverknüpfungen enthalten.
Columnstore-Indizes
Columnstore-Indizes bieten eine verbesserte Leistung für Abfragen mit großen Aggregationsworkloads. Ursprünglich für Data Warehouses entwickelt, werden Columnstore-Indizes inzwischen auch für verschiedene andere Workloads eingesetzt, um Probleme mit der Abfrageleistung bei großen Tabellen zu beheben. Wie B-Strukturindizes stellen auch gruppierte Columnstore-Indizes die Tabelle selbst in einer speziellen Form dar, während nicht gruppierte Columnstore-Indizes unabhängig von der Tabelle gespeichert werden. Gruppierte Columnstore-Indizes enthalten standardmäßig alle Spalten einer Tabelle, sind jedoch nicht sortiert.
Nicht gruppierte Columnstore-Indizes werden in der Regel in zwei Szenarien verwendet. Das erste Szenario tritt ein, wenn der Datentyp einer Spalte in einem Columnstore-Index nicht unterstützt wird (z. B. XML, CLR, sql_variant, ntext, Text und Bild). Da ein gruppierter Columnstore-Index immer alle Spalten der Tabelle enthält, ist ein nicht gruppierter Index die einzige Option. Das zweite Szenario betrifft gefilterte Indizes, die in HTAP-Architekturen (Hybrid Transactional Analytic Processing) verwendet werden, bei denen Daten in die Tabelle geladen werden, während gleichzeitig Berichte ausgeführt werden. Das Filtern des Index (in der Regel nach einem Datumsfeld) ermöglicht eine effiziente Einfügung und Berichterstellung.
Columnstore-Indizes speichern jede Spalte unabhängig voneinander und bieten zwei Vorteile: reduzierte E/A-Vorgänge, da nur die erforderlichen Spalten gescannt werden, und eine höhere Komprimierung aufgrund ähnlicher Daten innerhalb der Spalten. Sie eignen sich am besten für analytische Abfragen, die große Datensätze scannen, z. B. Faktentabellen in Data Warehouses. Sie können einen Columnstore-Index mit einem nicht gruppierten B-Strukturindex für die Suche nach Singleton-Werten erweitern.
Diese Indizes profitieren außerdem vom Batchausführungsmodus, bei dem Sätze von Zeilen (in der Regel etwa 900) gleichzeitig statt einzeln verarbeitet werden. Dieser Ansatz reduziert CPU-Anweisungen erheblich.
SELECT SUM(Sales) FROM SalesAmount;
Der Batchmodus kann gegenüber der herkömmlichen Zeilenverarbeitung eine Leistungssteigerung bieten. Während der Batchmodus für Rowstore nicht dieselbe Leseleistung wie ein Columnstore-Index erreicht, können analytische Abfragen doch immer noch eine bis zu 5-fache Leistungssteigerung erfahren.
Ein weiterer Vorteil von Columnstore-Indizes für Data Warehouse-Workloads ist der optimierte Ladepfad für Masseneinfügungen mit 102.400 Zeilen oder mehr. Während 102.400 der Mindestwert ist, der direkt in den Columnstore geladen werden kann, kann jede Sammlung von Zeilen, die sogenannte „Rowgroup“ (Zeilengruppe), bis zu etwa 1.024.000 Zeilen umfassen. Weniger, aber vollere Zeilengruppen machen Ihre SELECT-Abfragen effizienter, da weniger Zeilengruppen gescannt werden müssen, um die angeforderten Datensätze abzurufen. Diese Ladevorgänge finden im Arbeitsspeicher statt und werden direkt in den Index geladen. Bei kleineren Mengen werden die Daten in eine B-Struktur geschrieben, die als Deltaspeicher bezeichnet wird, und asynchron in den Index geladen.
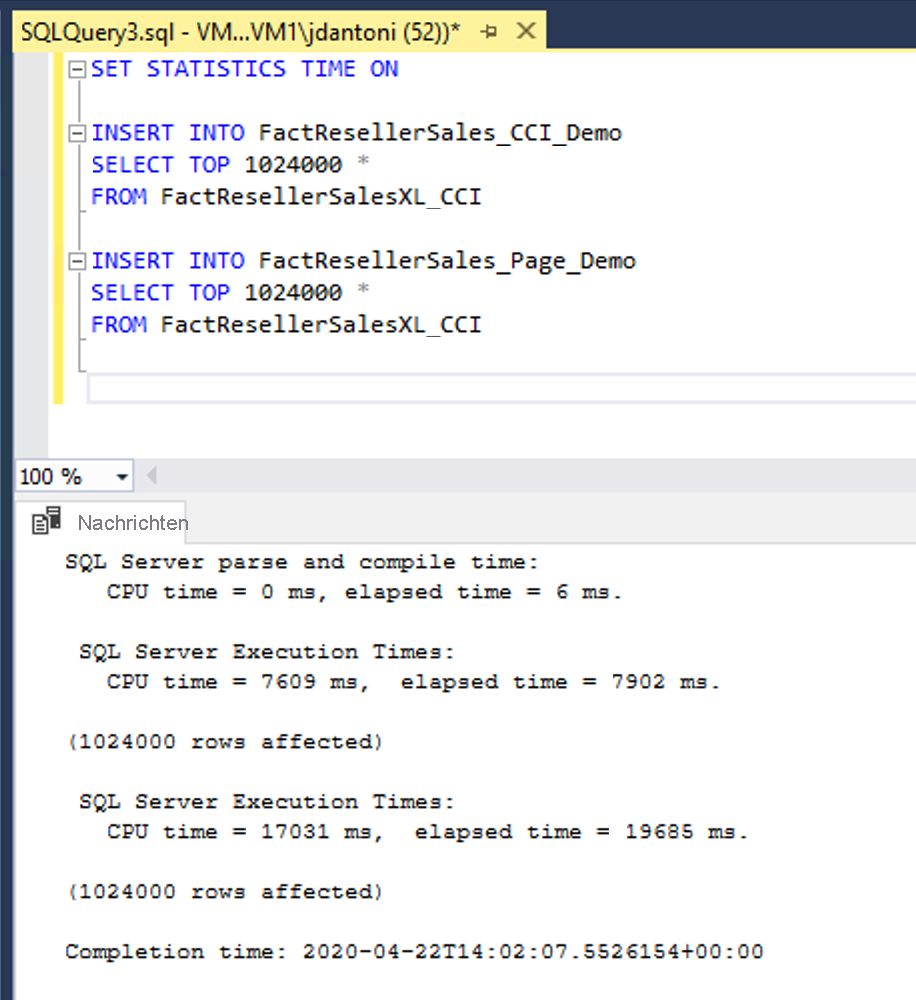
In diesem Beispiel werden dieselben Daten in zwei Tabellen geladen, FactResellerSales_CCI_Demo und FactResellerSales_Page_Demo. Die FactResellerSales_CCI_Demo verfügt über einen gruppierten Spaltenspeicherindex, und die FactResellerSales_Page_Demo verfügt über einen gruppierten B-Strukturindex mit zwei Spalten und ist seitenkomprimiert. Wie Sie sehen können, lädt jede Tabelle 1.024.000 Zeilen aus der FactResellerSalesXL_CCI Tabelle. Wenn SET STATISTICS TIMEON ist, verfolgt SQL Server die verstrichene Zeit der Abfrageausführung. Das Laden der Daten in die Columnstore-Tabelle dauerte etwa 8 Sekunden, während das Laden in die seitenkomprimierte Tabelle fast 20 Sekunden gedauert hat. In diesem Beispiel werden alle Zeilen, die in den Columnstore-Index eingehen, in eine einzige Rowgroup geladen.
Wenn Sie weniger als 102.400 Datenzeilen in einem einzigen Vorgang in einen Columnstore-Index laden, werden diese in eine B-Baumstruktur geladen, die als Deltaspeicher bezeichnet wird. Die Datenbank-Engine verschiebt diese Daten mit einem asynchronen Prozess, dem sogenannten „Tupelverschiebungsvorgang“ (Tuple Mover), in den Columnstore-Index. Offene Deltaspeicher können die Leistung Ihrer Abfragen beeinträchtigen, da das Lesen dieser Datensätze weniger effizient ist als das Lesen aus dem Columnstore. Sie können den Index auch mit der COMPRESS_ALL_ROW_GROUPS Option neu anordnen, um zu erzwingen, dass die Deltaspeicher in den Columnstore-Indizes hinzugefügt und komprimiert werden.