Erkennen von problematischen Abfragen
Der typische Ansatz von DBAs zur Problembehandlung bei der Abfrageleistung umfasst zunächst die Identifizierung der problematischen Abfrage, in der Regel die meisten Systemressourcen und das anschließende Abrufen des Ausführungsplans. Es gibt zwei Hauptszenarien. Ein Szenario besteht darin, dass die Abfrage konsistent schlecht ausgeführt wird. Dies kann auf verschiedene Probleme zurückzuführen sein, z. B. Hardwareressourceneinschränkungen (obwohl sich dies in der Regel nicht auf eine einzelne Abfrage auswirkt, die isoliert ausgeführt wird), eine suboptimale Abfragestruktur, Datenbankkompatibilitätseinstellungen,fehlende Indizes oder eine schlechte Planauswahl durch die abrageoptimierende Person. Das zweite Szenario besteht darin, dass die Abfrage eine gute Leistung für einige Ausführungen aufweist, für andere wiederum jedoch nicht. Diese Inkonsistenz kann durch Faktoren wie Datenverzerrungen in einer parametrisierten Abfrage verursacht werden, die für einige Ausführungen einen effizienten Plan und für andere einen schlechten Plan hat. Weitere häufige Faktoren sind Blockierungen, bei denen eine Abfrage auf den Abschluss einer anderen Abfrage wartet, um Zugriff auf eine Tabelle zu erhalten, oder Hardwarekonflikte.
Sehen wir uns jedes dieser Szenarien ausführlicher an.
Hardwareeinschränkungen
Hardwareeinschränkungen manifestieren sich in der Regel nicht während einzelner Abfrageausführungen, sondern werden unter Produktionslast offensichtlich, wenn CPU-Threads und Arbeitsspeicher begrenzt sind. CPU-Konsistenz kann erkannt werden, indem der Leistungsüberwachungsindikator „% Prozessorzeit“ beobachtet wird, der die CPU-Auslastung des Servers misst. In SQL Server können SOS_SCHEDULER_YIELD- und CXPACKET-Wartetypen den CPU-Druck angeben. Eine schlechte Leistung des Speichersystems kann sogar optimierte einzelne Abfrageausführungen verlangsamen. Die Speicherleistung wird am besten auf Betriebssystemebene mithilfe der Leistungsüberwachungszählern Disk Seconds/Read und Disk Seconds/Write nachverfolgt, was die Abschlusszeiten des E/A-Vorgangs misst. SQL Server protokolliert eine schlechte Speicherleistung, wenn eine E/A länger als 15 Sekunden dauert. Hohe PAGEIOLATCH_SH-Wartezeiten in SQL Server können auf Speicherleistungsprobleme hinweisen. Die Hardwareleistung wird in der Regel frühzeitig im Problembehandlungsprozess aufgrund der einfachen Bewertung ausgewertet.
Die meisten Probleme mit der Datenbankleistung sind auf suboptimale Abfragemuster zurückzuführen, die die Hardware übermäßig belasten können. Die meisten Probleme mit der Datenbankleistung sind auf suboptimale Abfragemuster zurückzuführen, die die Hardware übermäßig belasten können. Es wird empfohlen, suboptimale Abfragen zu behandeln und zu optimieren, bevor Hardwareprobleme behoben werden. Als Nächstes betrachten wir die Abfrageoptimierung.
Nicht optimale Abfrageentwürfe
Relationale Datenbanken eignen sich am besten zum Ausführen von satzbasierten Vorgängen, die Daten (INSERT, UPDATE, DELETEund SELECT) in Sätzen bearbeiten und entweder einen einzelnen Wert oder ein Resultset erzeugen. Die Alternative ist die zeilenbasierte Verarbeitung mit Cursorn oder While-Schleifen, deren Kosten linear mit der Anzahl der betroffenen Zeilen steigen – eine problematische Skalierung bei wachsenden Datenmengen.
Das Erkennen einer nicht optimalen Verwendung von zeilenbasierten Vorgängen mit Cursors oder WHILE-Schleifen ist zwar wichtig, es gibt jedoch weitere Antimuster in SQL Server, die Sie ebenfalls erkennen sollten. Tabellenwertfunktionen (TVFs), insbesondere TVFs mit mehreren Anweisungen, verursachten problematische Ausführungsplanmuster vor SQL Server 2017. Fachkräfte in der Entwicklung verwenden häufig TVFs mit mehreren Anweisungen, um mehrere Abfragen in einer einzelnen Funktion auszuführen und Ergebnisse in einer einzelnen Tabelle zu aggregieren. Die Verwendung von TVFs kann jedoch zu Leistungsstrafen führen.
SQL Server verfügt über zwei Arten von TVFs: Inlineanweisungen und mehrere Anweisungen. Inline-TVFs werden wie Ansichten behandelt, während TVFs mit mehreren Anweisungen während der Abfrageverarbeitung wie Tabellen behandelt werden. Da TVFs dynamisch sind und statistiken fehlen, verwendet SQL Server eine feste Zeilenanzahl für die Schätzung der Kosten des Abfrageplans. Dies kann für die Anzahl kleiner Zeilen in Ordnung sein, aber ineffizient für Tausende oder Millionen von Zeilen.
Ein weiteres Antimuster stellt die Verwendung von Skalarfunktionen dar, da diese zu ähnlichen Schätz- und Ausführungsproblemen führen. Microsoft hat mit der intelligenten Abfrageverarbeitung unter den Kompatibilitätsgraden 140 und 150 die Leistung erheblich verbessert.
SARGability
Der Begriff SARGable in relationalen Datenbanken bezieht sich auf ein Prädikat (WHERE-Klausel), das formatiert ist, um einen Index zur Beschleunigung der Abfrageausführung zu verwenden. Prädikate, die das richtige Format aufweisen, werden als Suchargumente bezeichnet, auf Englisch „Search Arguments“ oder SARGs. Bei Verwendung eines SARG in SQL Server wertet der Optimierer die Verwendung eines nicht gruppierten Indexes für die Spalte aus, auf die im SARG eines SEEK-Vorgangs verwiesen wird, anstatt den gesamten Index oder die Tabelle zu scannen, um einen Wert abzurufen.
Das Vorhandensein einer SARG garantiert nicht die Verwendung eines Indexes für eine SEEK. Die Kalkulationsalgorithmen des Optimierers könnten dennoch feststellen, dass der Index zu teuer ist, insbesondere, wenn ein SARG auf einen großen Prozentsatz von Zeilen in einer Tabelle verweist. Fehlt ein SARG, so wird der Optimierer den SEEK-Vorgang für einen nicht gruppierten Index nicht einmal in Erwägung ziehen.
Beispiele für nicht-SARGable Ausdrücke sind solche mit einer LIKE-Klausel, die einen Wildcard am Anfang der Zeichenfolge verwenden, z. B. WHERE lastName LIKE '%SMITH%'. Andere nicht-SARGable Prädikate treten auf, wenn Funktionen in einer Spalte verwendet werden, z. B. WHERE CONVERT(CHAR(10), CreateDate,121) = '2020-03-22'. Diese Abfragen können in der Regel über die Ausführungspläne für Index- oder Tabellenscans ermittelt werden, in denen andernfalls ein SEEK-Vorgang erfolgen würde.
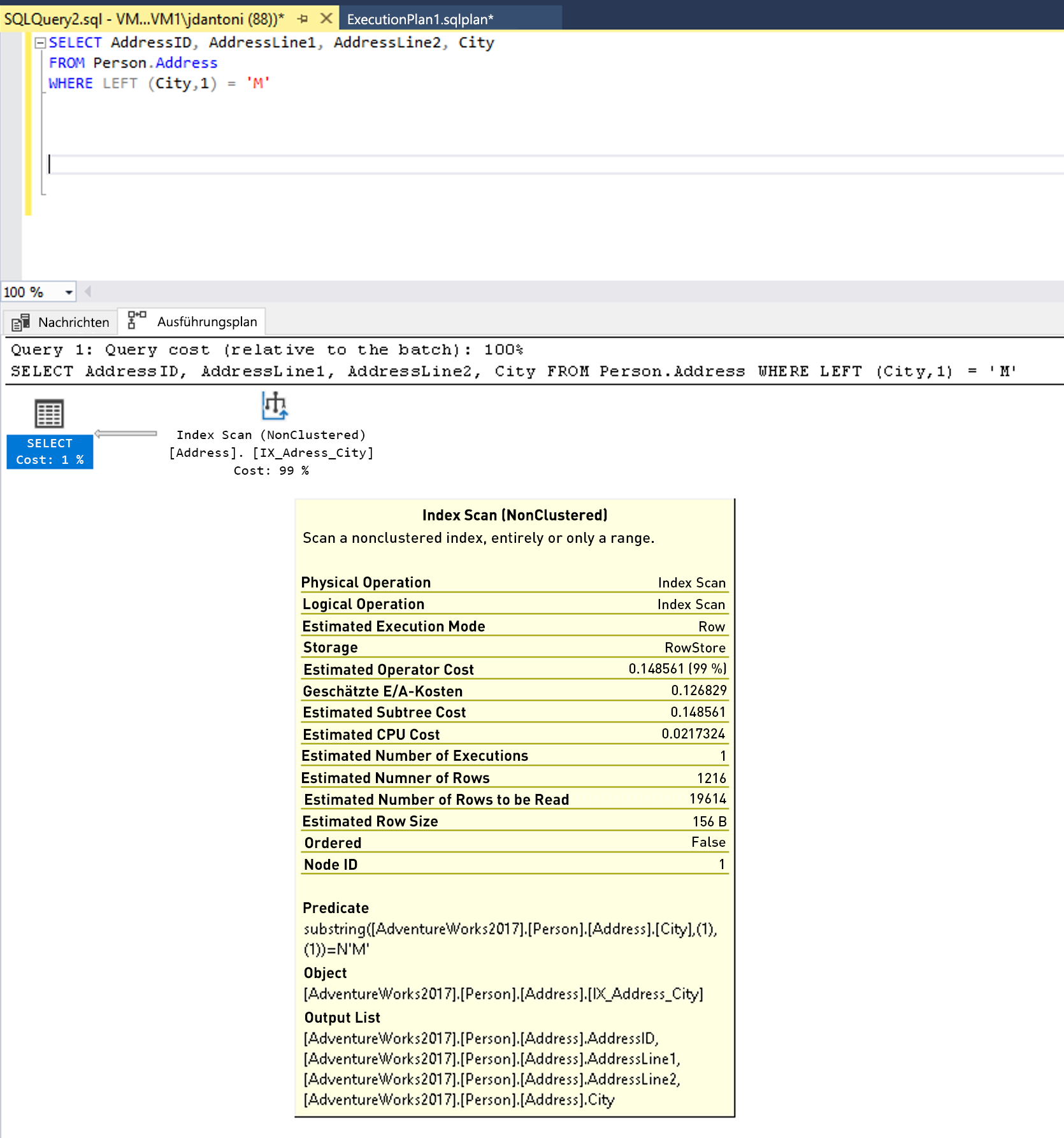
Es gibt einen Index in der Spalte "Ort ", die in der WHERE Klausel der Abfrage verwendet wird und während sie in diesem Ausführungsplan oben verwendet wird, sehen Sie, dass der Index gescannt wird, was bedeutet, dass der gesamte Index gelesen wird. Die LEFT-Funktion im Prädikat bewirkt, dass dieser Ausdruck nicht SARG-tauglich ist. Der Optimierer verwendet bei der Auswertung keinen Indexsuchoperator für den Index der Spalte City.
Diese Abfrage könnte so geschrieben werden, dass sie ein SARG-taugliches Prädikat verwendet. Der Optimierer wertet dann einen SEEK-Vorgang für den Index der Spalte City aus. Bei einem Index Seek-Vorgang würde in diesem Fall eine kleinere Anzahl von Zeilen gelesen.
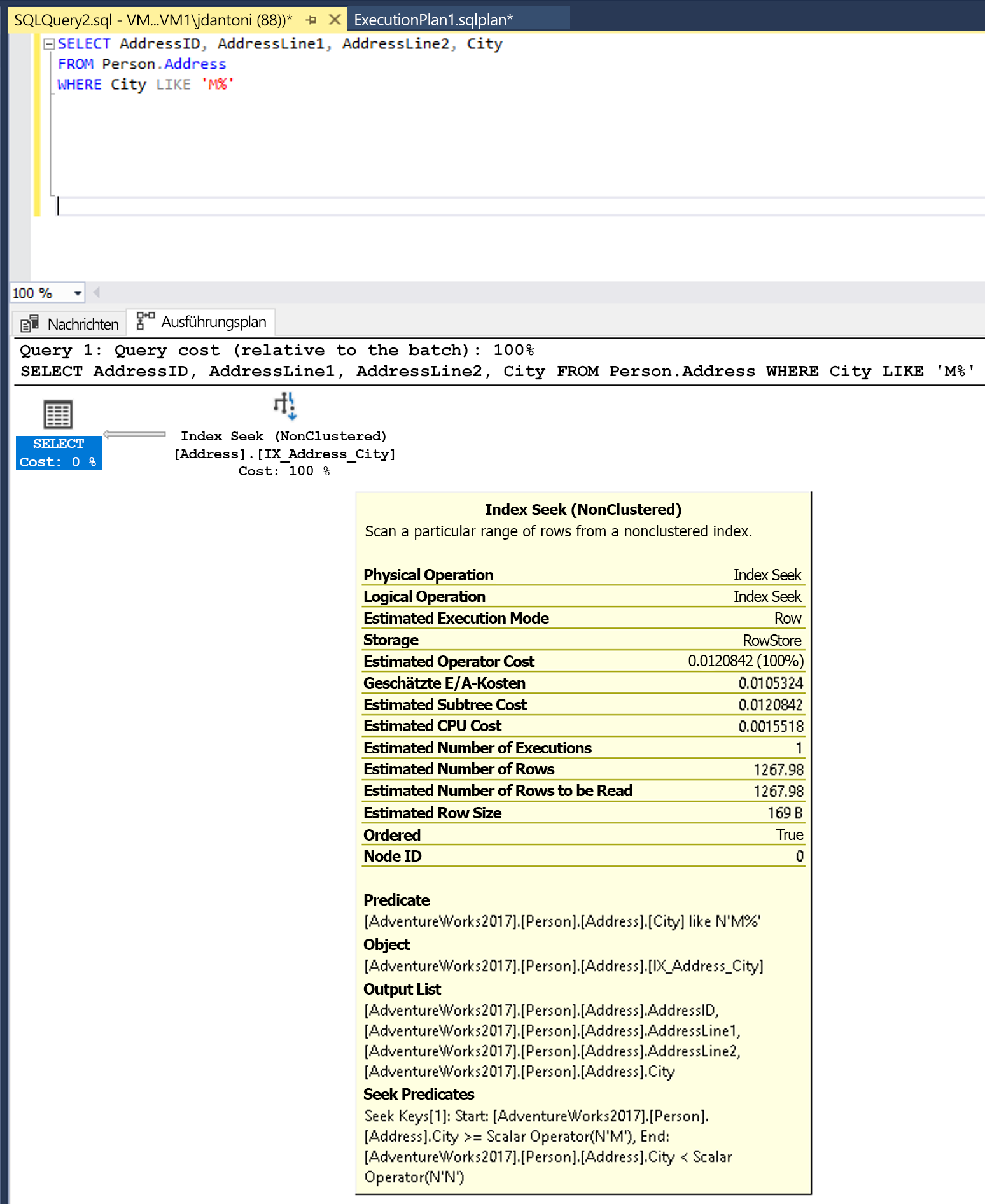
Ändern der LEFT Funktion in ein LIKE Ergebnis in einer Indexsuche.
Hinweis
In diesem Beispiel steht links vom LIKE-Schlüsselwort kein Platzhalter, weshalb nach Städten gesucht wird, die mit M beginnen. Wäre M „zweiseitig“ oder ein Platzhalter (‘%M% oder ‘%M’), wäre es nicht SARG-tauglich. Es wird erwartet, dass der Suchvorgang 1,267 Zeilen zurückgibt, mit anderen Worten ca. 15 Prozent der Schätzung für die Abfrage mit dem nicht SARG-tauglichen Prädikat.
Bei anderen Antimustern in der Datenbankentwicklung werden Datenbanken als Dienst, nicht als Datenspeicher verwendet. Die Verwendung einer Datenbank zum Konvertieren von Daten in JSON, zum Bearbeiten von Zeichenfolgen oder zum Ausführen komplexer Berechnungen kann zu einer übermäßigen CPU-Auslastung und erhöhter Latenz führen. Abfragen, die versuchen, alle Datensätze abzurufen, und dann Berechnungen in der Datenbank ausführen, können übermäßig viele E/A-Vorgänge und eine zu hohe CPU-Auslastung nach sich ziehen. Im Idealfall sollten Sie die Datenbank für Datenzugriffsvorgänge und optimierte Datenbankkonstrukte wie Aggregationen verwenden.
Fehlende Indizes
Die häufigsten Leistungsprobleme, denen Fachkräfte für die Datenbankverwaltung begegnen, sind auf das Fehlen nützlicher Indizes zurückzuführen. Dieser Mangel bewirkt, dass die Engine weitaus mehr Seiten liest, als dies für die Rückgabe der Abfrageergebnisse erforderlich wäre. Indizes verbrauchen zwar Ressourcen (was sich auf die Schreibleistung auswirkt und Speicherplatz beansprucht), doch ihre Leistungsvorteile überwiegen oft die zusätzlichen Ressourcenkosten. Ausführungspläne können mit diesen Leistungsproblemen mit dem Abfrageoperator Clustered Index Scan oder einer Kombination aus Nonclustered Index Seek und Key Lookup, identifiziert werden, was auf fehlende Spalten in einem vorhandenen Index hinweist.
Das Datenbankmodul hilft, indem fehlende Indizes in Ausführungsplänen gemeldet werden. Die Namen und Details der empfohlenen Indizes sind über eine dynamische Verwaltungssicht sys.dm_db_missing_index_details verfügbar. Andere DMVs wie sys.dm_db_index_usage_stats und sys.dm_db_index_operational_stats heben die Verwendung vorhandener Indizes hervor.
Das Ablegen eines nicht verwendeten Indexes kann sinnvoll sein. Fehlende Index-DMVs und Planwarnungen sollten Ausgangspunkte für die Optimierung von Abfragen sein. Es ist entscheidend, wichtige Abfragen zu verstehen und Indizes zu erstellen, um diese zu unterstützen. Das Erstellen aller fehlenden Indizes, ohne sie im Kontext auszuwerten, wird nicht empfohlen.
Fehlende und veraltete Statistiken
Das Verständnis der Bedeutung von Spalten- und Indexstatistiken für den Abfrageoptimierer ist von entscheidender Bedeutung. Es ist auch wichtig, Bedingungen zu erkennen, die zu veralteten Statistiken führen können, und zu wissen, wie sich dieses Problem in SQL Server äußern kann. Bei Azure SQL-Angeboten ist die automatische Statistikaktualisierung standardmäßig auf EIN festgelegt. Vor SQL Server 2016 war das Standardverhalten der automatischen Statistikaktualisierung, dass Statistiken erst aktualisiert wurden, wenn die Anzahl der Spaltenänderungen im Index ungefähr 20 Prozent der Anzahl der Tabellenzeilen betrug. Dieses Verhalten kann zu erheblichen Datenänderungen führen, die die Abfrageleistung ändern, ohne die Statistiken zu aktualisieren, was zu suboptimalen Plänen auf der Grundlage veralteter Statistiken führt.
Vor SQL Server 2016 konnte das Ablaufverfolgungsflag 2371 verwendet werden, um die erforderliche Anzahl von Änderungen an einem dynamischen Wert zu ändern, sodass mit zunehmender Größe Ihrer Tabelle der Prozentsatz der Zeilenänderungen, die erforderlich waren, um eine Statistikaktualisierung auszulösen, abnahm. In neueren Versionen von SQL Server, Azure SQL-Datenbank und Azure SQL Managed Instance wird dieses Verhalten standardmäßig unterstützt. Die dynamische Verwaltungsfunktion sys.dm_db_stats_properties zeigt die letzte Aktualisierung der Statistiken und die Anzahl der seit dem letzten Update vorgenommenen Änderungen an, sodass Sie schnell Statistiken identifizieren können, die möglicherweise manuelle Updates benötigen.
Schlechte Entscheidungen des Optimierers
Während der Abfrageoptimierer die meisten Abfragen optimieren kann, gibt es einige Grenzfälle, in denen der kostenbasierte Optimierer wichtige Entscheidungen treffen kann, die nicht vollständig verständlich sind. Es gibt viele Möglichkeiten, diesem Problem zu begegnen, z. B. mit Abfragehinweisen, Ablaufverfolgungsflags, dem Erzwingen von Ausführungsplänen sowie anderen Anpassungen, um einen stabilen und optimalen Abfrageplan zu erreichen. Microsoft hat ein Supportteam, das Ihnen in solchen Szenarios bei der Problembehandlung helfen kann.
Im folgenden Beispiel aus der AdventureWorks2017-Datenbank wird ein Abfragehinweis verwendet, um dem Datenbankoptimierer mitzuteilen, dass immer ein Stadtname von Seattle verwendet wird. Dieser Hinweis garantiert zwar nicht die Verwendung des besten Ausführungsplans für alle Städtewerte, ist aber vorhersagbar. Der Wert „Seattle“ für @city_name wird nur während der Optimierung verwendet. Während der Ausführung wird der tatsächliche Wert ((‘Ascheim’)) verwendet.
DECLARE @city_name nvarchar(30) = 'Ascheim',
@postal_code nvarchar(15) = 86171;
SELECT *
FROM Person.Address
WHERE City = @city_name
AND PostalCode = @postal_code
OPTION (OPTIMIZE FOR (@city_name = 'Seattle');
Wie im Beispiel gezeigt, verwendet die Abfrage einen Hinweis (die OPTION-Klausel), um den Optimierer anzuweisen, den Ausführungsplan mit einem bestimmten Variablenwert zu erstellen.
Parameterermittlung
SQL Server speichert Abfrageausführungspläne für die spätere Verwendung zwischen. Da der Abruf des Ausführungsplans auf dem Hashwert einer Abfrage basiert, muss der Abfragetext bei jeder Ausführung mit der Abfrage des zu verwendenden zwischengespeicherten Plans identisch sein. Viele Entwickler verwenden Parameter, die, wie im folgenden Beispiel gezeigt, durch gespeicherte Prozeduren übergeben werden, um mehrere Werte in einer Abfrage zu unterstützen:
CREATE PROC GetAccountID (@Param INT)
AS
<other statements in procedure>
SELECT accountid FROM CustomerSales WHERE sales > @Param;
<other statements in procedure>
RETURN;
-- Call the procedure:
EXEC GetAccountID 42;
Abfragen können auch mithilfe der Prozedur sp_executesqlexplizit parametrisiert werden. Allerdings erfolgt die explizite Parametrisierung einzelner Abfragen in der Regel über die Anwendung in Form einer PREPARE- oder EXECUTE-Anweisung (je nach API). Wenn die Datenbank-Engine diese Abfrage zum ersten Mal ausführt, optimiert sie die Abfrage auf Basis des Anfangswerts des Parameters, in diesem Fall „42“. Dieses als Parameter Sniffing bezeichnete Verhalten ermöglicht, dass die Gesamtworkload der Abfragenkompilierung auf dem Server reduziert wird. Wenn eine entsprechende Datenschiefe vorliegt, kann die Abfrageleistung stark schwanken.
In einer Tabelle mit 10 Millionen Datensätzen, in der 99 Prozent der Datensätze die ID „1“ und das übrige 1 Prozent eindeutige Zahlen aufweisen, basiert die Leistung z. B. auf der ID, die ursprünglich zur Abfrageoptimierung verwendet wurde. Diese stark schwankende Leistung ist ein Hinweis auf Datenschiefe und kein inhärentes Problem der Parameterermittlung. Das Verhalten ist eher ein recht häufiges Leistungsproblem, das Sie kennen sollten. Sie sollten sich auch mit den Optionen für die Problembehebung vertraut machen. Dieses Problem lässt sich zwar mit verschiedenen Methoden lösen, diese sind jedoch alle mit Vor- und Nachteilen verbunden:
- Verwenden Sie den
RECOMPILEHinweis in Ihrer Abfrage oder dieWITH RECOMPILEAusführungsoption in Ihren gespeicherten Prozeduren. Der Hinweis bewirkt, dass die Abfrage oder Prozedur bei jeder Ausführung neu kompiliert wird. Dies erhöht zwar die CPU-Auslastung auf dem Server, dafür wird jedoch immer der aktuelle Parameterwert verwendet. - Sie können den
OPTIMIZE FOR UNKNOWNAbfragehinweis verwenden. Er bewirkt, dass der Abfrageoptimierer kein Parameter Sniffing durchführt und den Wert mit dem Spaltendatenhistogramm vergleicht. Mit dieser Option erzielen Sie nicht den bestmöglichen, dafür jedoch einen konsistenten Ausführungsplan. - Schreiben Sie Ihre Prozedur oder Ihre Abfragen neu, indem Sie Logik zu den Parameterwerten hinzufügen, um RECOMPILE nur für bekannte problematische Parameter auszuführen. Wenn der SalesPersonID-Parameter im folgenden Beispiel NULL ist, wird die Abfrage mit
OPTION (RECOMPILE)ausgeführt.
CREATE OR ALTER PROCEDURE GetSalesInfo (@SalesPersonID INT = NULL)
AS
DECLARE @Recompile BIT = 0
, @SQLString NVARCHAR(500)
SELECT @SQLString = N'SELECT SalesOrderId, OrderDate FROM Sales.SalesOrderHeader WHERE SalesPersonID = @SalesPersonID'
IF @SalesPersonID IS NULL
BEGIN
SET @Recompile = 1
END
IF @Recompile = 1
BEGIN
SET @SQLString = @SQLString + N' OPTION(RECOMPILE)'
END
EXEC sp_executesql @SQLString
,N'@SalesPersonID INT'
,@SalesPersonID = @SalesPersonID
GO
Das obige Beispiel stellt zwar eine gute Lösung dar, erfordert aber einen relativ großen Entwicklungsaufwand und ein solides Verständnis Ihrer Datenverteilung. Es erfordert Wartung, da sich die Daten ändern.