Übung – Daten konsolidieren
Ihre Aufgabe für diese Übung besteht darin, aus zwei Datasets ein neues Prozess-Mining-Projekt zu erstellen.
In dieser Übung überprüfen Sie die Daten, stellen sicher, dass die erforderlichen Felder in den Datasets enthalten sind, ermitteln die übereinstimmenden Spalten zwischen den Datasets, laden Sie Datasets hoch, und führen die Datasets anschließend basierend auf den übereinstimmenden Spalten zusammen.
Ziele
Ihre Lernziele für diese Übung sind:
Daten überprüfen und vorbereiten
Erstellen Sie den Prozess und laden Sie Daten aus mehreren Quellen.
Datasets basierend auf übereinstimmenden Spalten zusammenführen
Attribute zuordnen
Erforderliche Felder
Damit Prozess-Mining Ihre Ereignisprotokolle analysieren kann, benötigen Sie die folgenden Felder: Case ID, Activity und Event Start.
Daten vorbereiten und laden
Sie erhalten zwei Datasets im XLSX-Format. Sie möchten die Daten überprüfen, sicherstellen, dass alle erforderlichen Felder in den Datasets enthalten sind, die übereinstimmenden Spalten identifizieren und dann den Prozess erstellen.
Wesentliche Schritte: Daten vorbereiten und laden
Versuchen Sie, die folgenden wesentlichen Schritte auszuführen, um diese Übung abzuschließen. Wenn Sie nicht weiterkommen, gehen Sie zum Abschnitt mit der schrittweisen Anleitung, und folgen Sie stattdessen diesen Anweisungen.
Öffnen Sie die Dateien, und überprüfen Sie das Dataset.
Konvertieren Sie die Daten bei Bedarf in ein leicht lesbares Format.
Überprüfen Sie, ob alle erforderlichen Spalten in den Datasets enthalten sind.
Identifizieren Sie die übereinstimmenden Spalten zwischen den Datasets.
Speichern Sie Datasets als CSV-Dateien.
Erstellen Sie den Prozess, und laden Sie die Datasets hoch.
Schrittweise Anleitung: Daten vorbereiten und laden
Dieser Abschnitt enthält ausführlichere Anleitungen zu den vorhergehenden wesentlichen Schritten.
Aufgabe: Datasets überprüfen und übereinstimmende Spalten identifizieren
Ihre erste Aufgabe besteht darin, Datasets zu überprüfen und übereinstimmende Spalten zu identifizieren, indem Sie die folgenden Schritte ausführen:
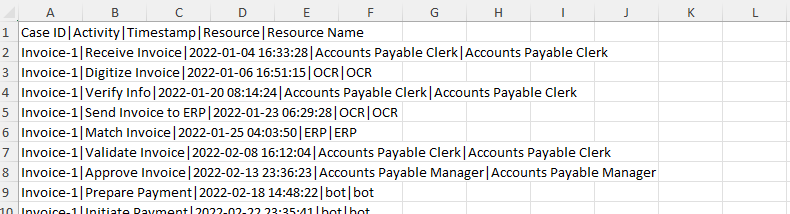
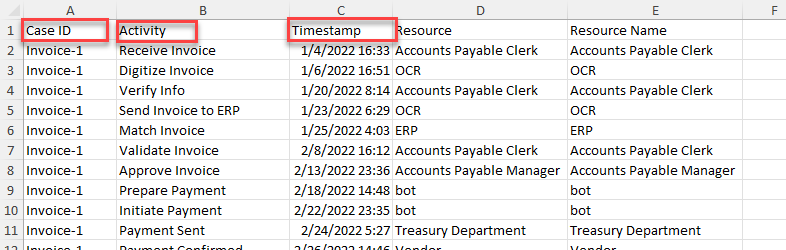
Suchen und öffnen Sie die Datei AP_EV_LAB_Combine_log.xlsx.
Die Daten in der Datei sollten dem nächsten Bild ähneln.
Hinweis
Die Daten sind durch einen senkrechten Strich (|) getrennt, was das Lesen erschwert. Verwenden Sie die Excel-Funktion Text in Spalten, um das Lesen der Daten einfacher zu gestalten.
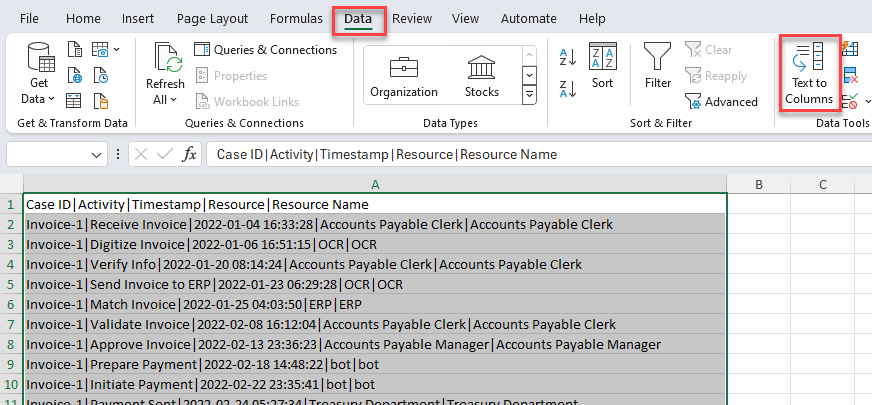
Wählen Sie die Registerkarte Daten aus.
Alle Daten für jede Zeile befinden sich in einer Zelle. Wählen Sie alle Zeilen, einschließlich der Kopfzeile, und dann die Schaltfläche Text in Spalten aus.
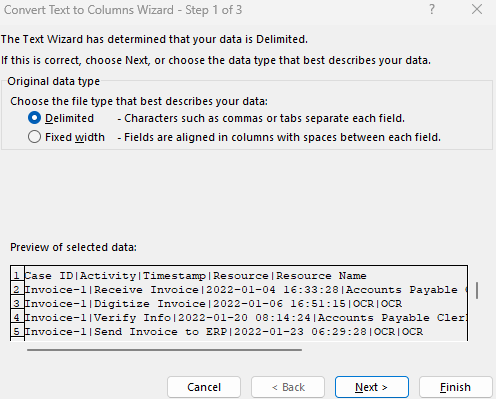
Wählen Sie Getrennt und dann Weiter aus.
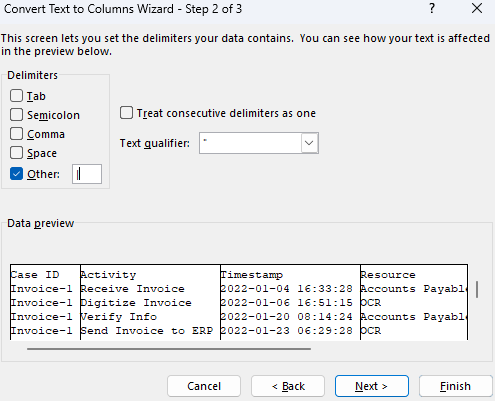
Wählen Sie Andere aus, geben Sie ein vertikales Strichzeichen (|) ein, und wählen Sie dann Weiter aus.
Wählen Sie Fertig stellen aus.
Die Daten sollten nun leichter zu lesen sein.
Überprüfen Sie, ob die erforderlichen Felder vorhanden sind.
Identifizieren Sie andere Felder, die Sie möglicherweise für das Prozess-Mining zuordnen möchten. Wählen Sie Fertig stellen aus.
Sie können sich Notizen zu den Feldern machen, die Sie verwenden möchten. Wählen Sie Datei > Speichern unter aus, nachdem Sie die Daten überprüft haben.
Speichern Sie die Datei als Standard-CSV, und geben Sie ihr anschließend einen aussagekräftigen Namen.

Schließen Sie die Datei.
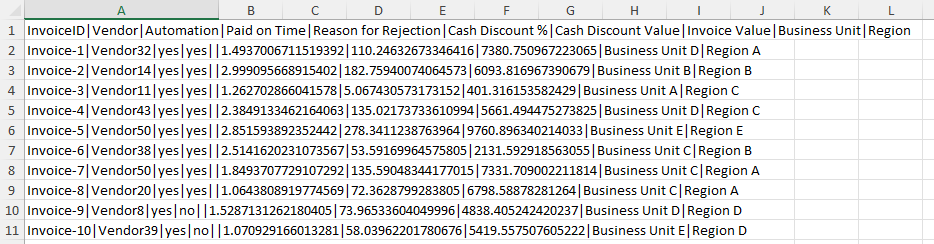
Bereiten Sie das zweite Dataset vor, indem Sie die Datei „AP_EV_LAB_Combine_attr.xlsx“ suchen und öffnen.
Die Daten in der Datei sollten dem nächsten Bild ähneln.
Hinweis
Die Daten sind durch einen senkrechten Strich (|) getrennt, was das Lesen erschwert. Verwenden Sie die Excel-Funktion Text in Spalten, um das Lesen der Daten einfacher zu gestalten.
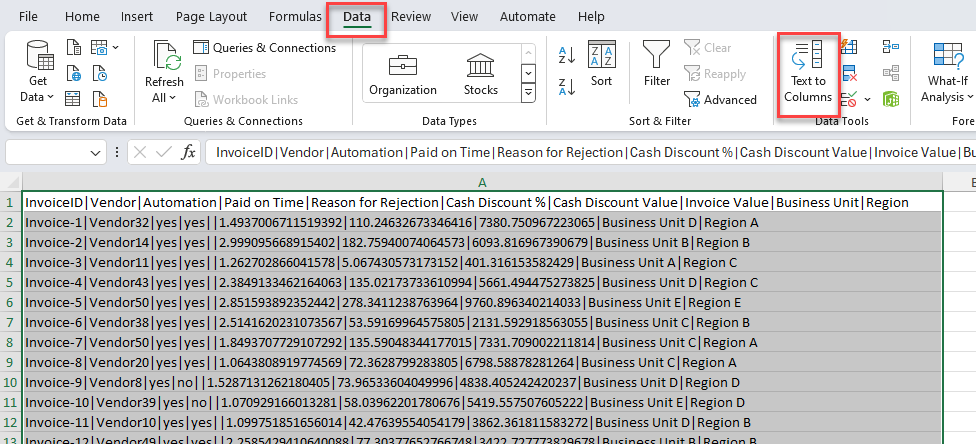
Wählen Sie die Registerkarte Daten aus.
Alle Daten für jede Zeile befinden sich in einer Zelle. Wählen Sie alle Zeilen, einschließlich der Kopfzeile, und dann die Schaltfläche Text in Spalten aus.
Wählen Sie Getrennt und dann Weiter aus.
Wählen Sie Andere aus, geben Sie ein vertikales Strichzeichen (|) ein, und wählen Sie dann Weiter aus.
Wählen Sie Fertig stellen aus.
Die Daten sollten nun leichter zu lesen sein.
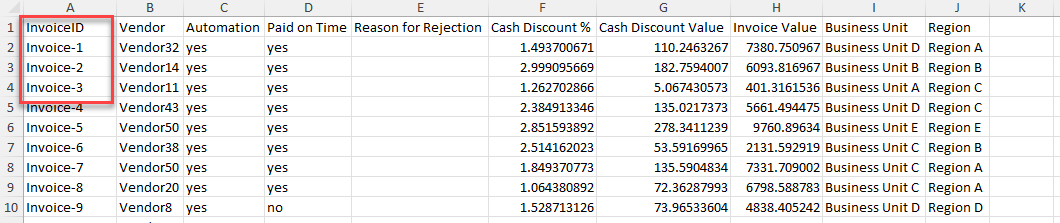
Alle erforderlichen Felder sind bereits in der ersten Datei vorhanden. Suchen Sie die Spalten, die beide Datasets gemeinsam haben.
Beachten Sie, dass InvoiceID und Case ID aus dem ersten Dataset übereinstimmen. Verwenden Sie diese Spalten als übereinstimmende Spalten.
Identifizieren Sie andere Felder, die Sie für das Prozess-Mining zuordnen möchten.
Sie können sich Notizen zu den Feldern machen, die Sie verwenden möchten. Wählen Sie Datei > Speichern unter aus, nachdem Sie die Daten überprüft haben.
Speichern Sie die Datei als CSV, und geben Sie ihr anschließend einen aussagekräftigen Namen.

Schließen Sie die Datei.










Aufgabe: Prozess erstellen und Daten laden
Führen Sie die folgenden Schritte aus, um den Prozess zu erstellen und die Daten zu laden:
Navigieren Sie zu Microsoft Power Automate, und wählen Sie die richtige Umgebung aus.
Wählen Sie im linken Bereich Prozess-Mining und dann + Hier beginnen aus.
Geben Sie Zusammengeführte Datasets als Prozessname ein, wählen Sie Daten importieren als Datenquelle, wählen Sie Datenfluss und dann Weiter aus.
Wählen Sie Überspringen aus, wenn das System Sie auffordert, einen Power BI-Arbeitsbereich hinzuzufügen.
Wählen Sie Text/CSV als Datenquelle aus.
Wählen Sie Datei hochladen und dann die Schaltfläche Durchsuchen aus.
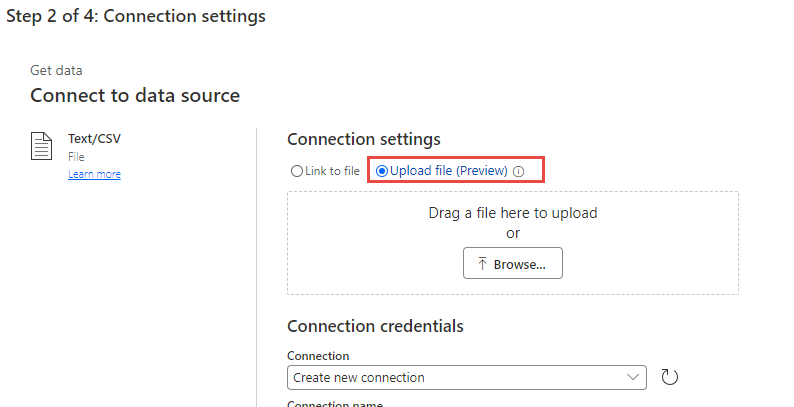
Wählen Sie die erste CSV-Datei, die Sie erstellt haben, und dann Öffnen aus.
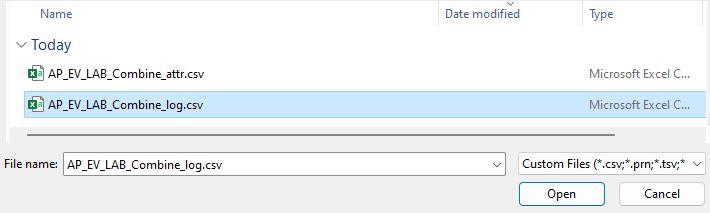
Wenn Sie nicht angemeldet sind, wählen Sie die Schaltfläche Anmelden aus, und geben Sie Ihre Anmeldeinformationen ein.
Wählen Sie Weiter aus.
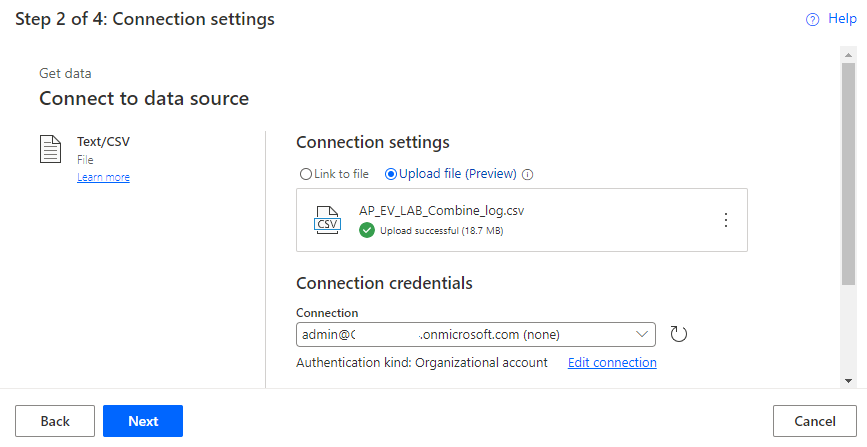
Es sollte nun eine Vorschau der Daten angezeigt werden. Wählen Sie Weiter aus.
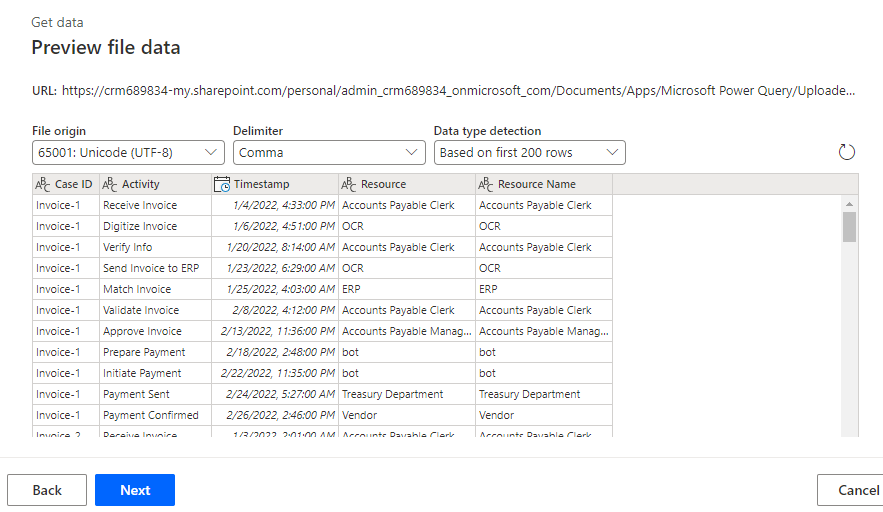
Das System sollte Sie zur Transformationsphase weiterleiten.
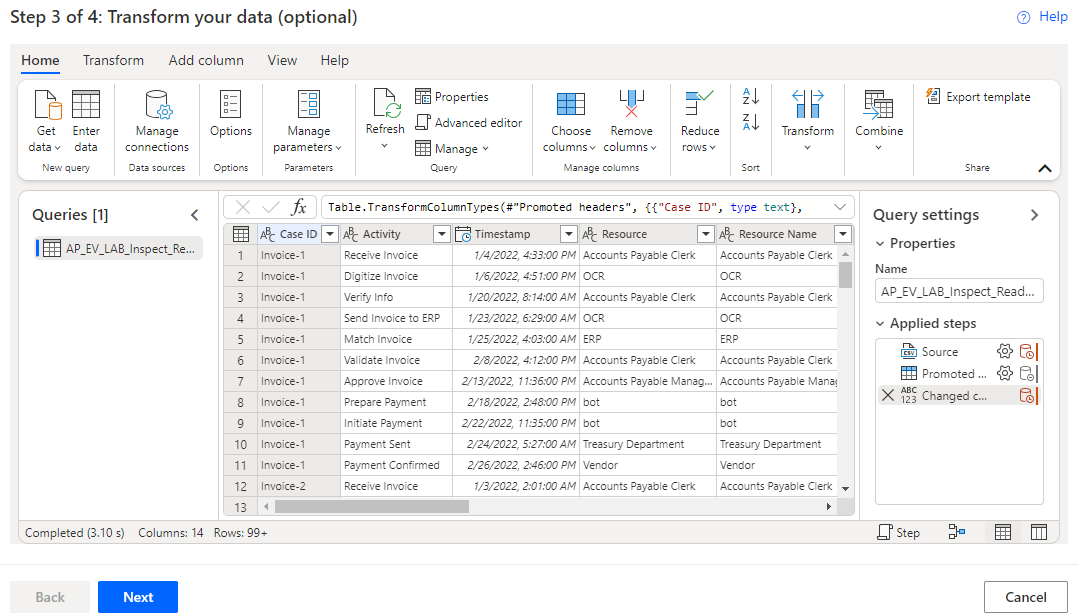
Wählen Sie zum laden des zweiten Datasets die Option Daten abrufen und dann Text/CSV aus.
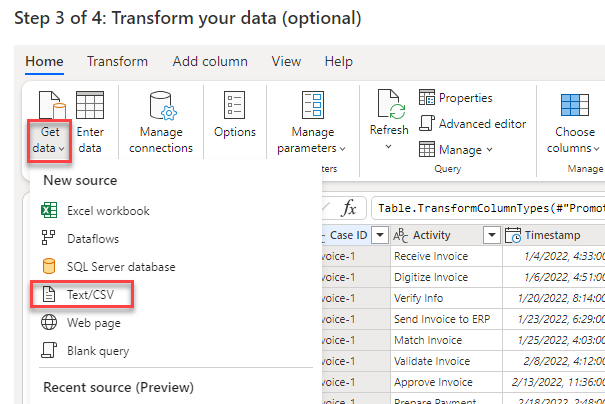
Wählen Sie Datei hochladen und dann die Schaltfläche Durchsuchen aus.
Wählen Sie die zweite CSV-Datei, die Sie erstellt haben, und dann Öffnen aus.
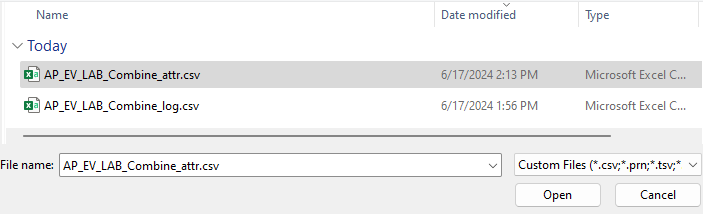
Wählen Sie Weiter aus.
Es sollte nun eine Vorschau der Daten angezeigt werden. Wählen Sie Erstellen aus.











Es sollten nun zwei Tabellen geladen sein.

Datasets zusammenführen
Nachdem Sie alle Datasets erfolgreich geladen haben, können Sie sie nun zu einer neuen, konsolidierten Tabelle zusammenführen. In diese neue Tabelle sind Daten aus beiden geladenen Datasets integriert.
Wesentliche Schritte: Datasets zusammenführen
Versuchen Sie, die folgenden wesentlichen Schritte auszuführen, um diese Übung abzuschließen. Wenn Sie nicht weiterkommen, gehen Sie zum Abschnitt mit der schrittweisen Anleitung, und folgen Sie stattdessen diesen Anweisungen.
Verwenden Sie die Funktion Abfragen als neue Abfrage zusammenführen von Power Query, um die beiden Datasets in einer neuen Tabelle zusammenzuführen.
Wählen Sie die linke und rechte Zusammenführungstabelle aus.
Wählen Sie die richtigen übereinstimmenden Spalten zwischen den beiden Tabellen aus.
Stellen Sie sicher, dass Sie die Daten mit einem linken äußeren Join zusammenführen.
Klappen Sie die Tabelle auf.
Schließen Sie doppelte Spalten aus.
Benennen Sie die Tabelle um.
Aktivieren Sie die Ladefunktionen für die Tabelle, die Sie laden möchten, und deaktivieren Sie anschließend die Ladefunktionen für die anderen beiden Tabellen.
Ordnen Sie die Daten zu.
Speichern Sie den Prozess.
Schrittweise: Datasets zusammenführen
Dieser Abschnitt enthält ausführlichere Anleitungen zu den vorhergehenden wesentlichen Schritten.
Aufgabe: Datensätze und Karte zusammenführen
Führen Sie die folgenden Schritte aus, um die Datensätze und die Karte zusammenzuführen:
Wählen Sie das Dropdownmenü Abfragen zusammenführen und dann Abfragen als neue Abfrage zusammenführen aus.
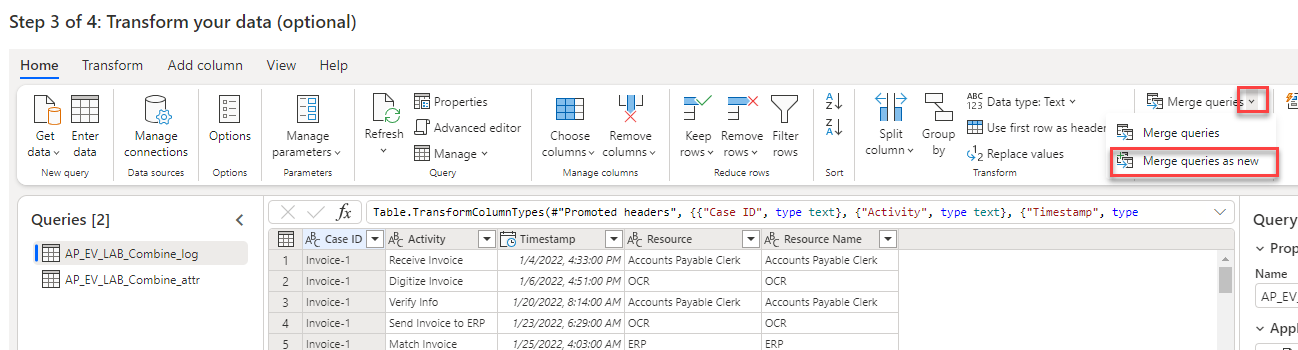
Wählen Sie die erste Tabelle, die Sie für Linke Tabelle zum Zusammenführen erstellt haben, und dann Case ID als übereinstimmende Spalte.
Wählen Sie die zweite Tabelle, die Sie für Rechte Tabelle zum Zusammenführen erstellt haben, und dann InvoiceID als übereinstimmende Spalte aus.
Wählen Sie Linker äußerer Join als Art des Joins und dann OK aus.
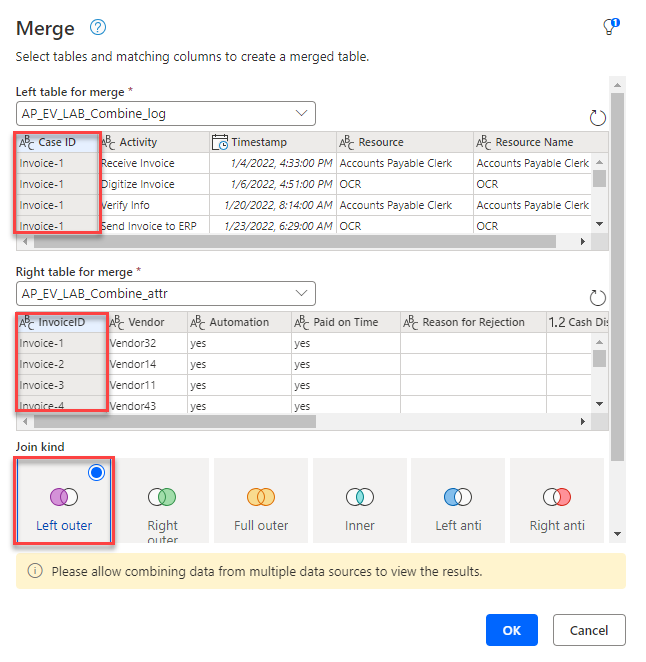
Es sollte die folgende Fehlermeldung angezeigt werden: „Die Auswertung wurde abgebrochen, da beim Kombinieren von Daten aus mehreren Quellen Daten von einer Quelle zur anderen weitergegeben werden können.“ Klicken Sie auf „Weiter“, wenn Sie mit der Möglichkeit der Offenlegung von Daten einverstanden sind.“ Wählen Sie Weiter aus.

Die zweite Tabelle sollte jetzt als eine Spalte angezeigt werden. Erweitern Sie die Tabelle, und wählen Sie die Spalten aus, die Sie hinzufügen möchten. Suchen Sie die zweite Tabellenspalte, und wählen Sie dann das Symbol Erweitern aus.
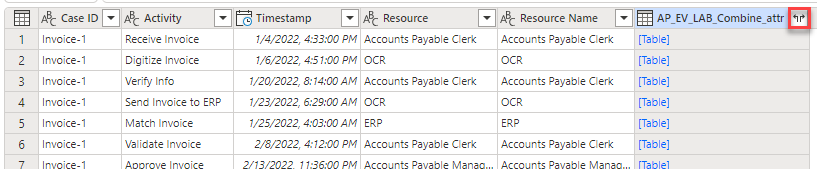
Hinweis
Wählen Sie nun die Spalten aus, die Sie einbeziehen möchten. Da die Zusammenführungstabelle nicht mehrere Spalten mit den Werten enthalten soll, sollten Sie Spalten auswählen, die für diese Tabelle eindeutig sind.
Deaktivieren Sie das Kontrollkästchen InvoiceID, und wählen Sie OK aus.
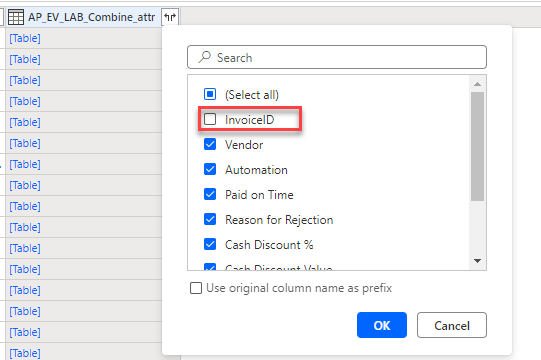
Die Tabelle „Merge“ sollte nun der folgenden Abbildung ähneln.
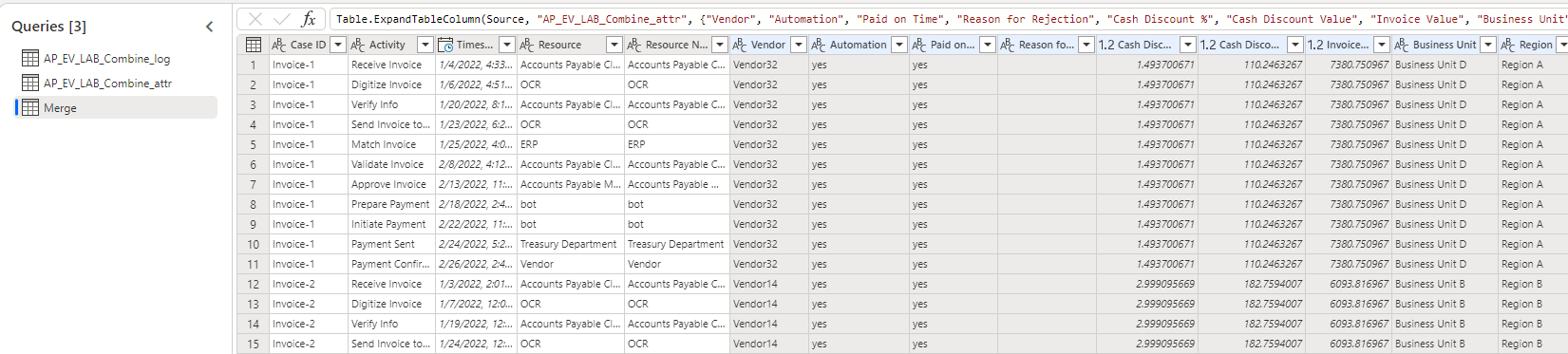
Klicken Sie mit der rechten Maustaste auf die Tabelle Merge, und wählen Sie dann Umbenennen aus.
Benennen Sie die Tabelle in Merged_log_attr um.
Die Ladefunktion ist standardmäßig in allen drei Tabellen aktiviert. Da Sie nur die Tabelle „Merge“ laden möchten, klicken Sie mit der rechten Maustaste auf die erste Tabelle, und wählen Sie dann Laden aktivieren aus. Diese Aktion deaktiviert die Ladefunktion für die erste Tabelle.
Klicken Sie mit der rechten Maustaste auf die zweite Tabelle, und wählen Sie dann Laden aktivieren aus. Diese Aktion deaktiviert die Ladefunktion für die zweite Tabelle.
Der Name der Tabellen mit deaktivierter Ladefunktion sollte in Kursivschrift angezeigt werden.
Wählen Sie Weiter aus.
Das System sollte Sie zur Zuordnungsphase weiterleiten. Zunächst ordnen Sie die erforderlichen Felder zu, wie in der folgenden Tabelle gezeigt.
Attributname Attributtyp Attributdatentyp Case ID Case ID Text Activity Activity Text Timestamp Event Start Datum/Uhrzeit 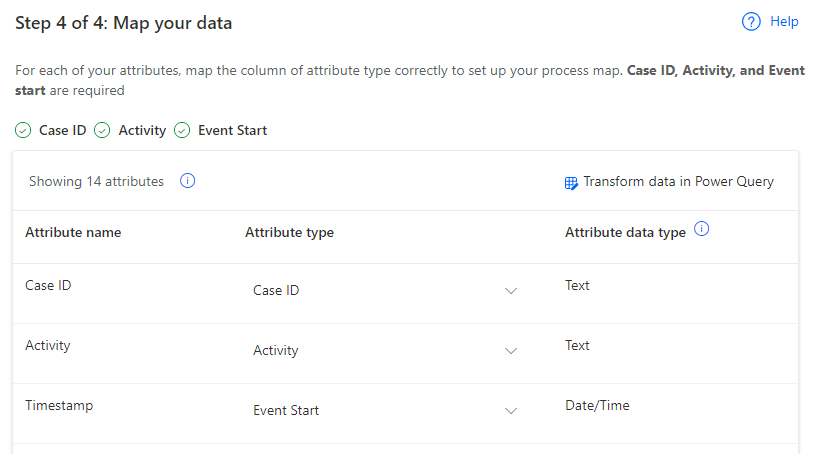
Ordnen Sie alle anderen Felder zu, die Sie einbeziehen möchten. Ordnen Sie für diese Übung alle Felder zu.
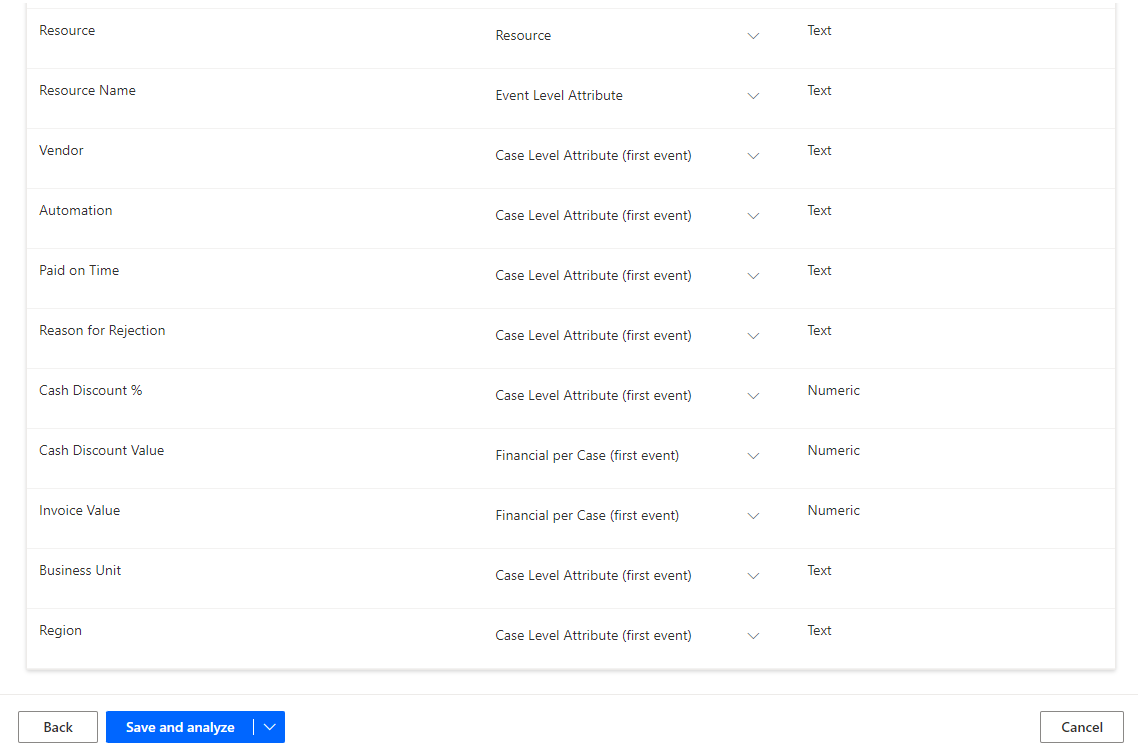
Ordnen Sie die restlichen Felder zu, wie in der folgenden Tabelle gezeigt.
Attributname Attributtyp Attributdatentyp Resource Resource Text Resource Name Event Level Attribute Text Vendor Case Level Attribute (first event) Text Automation Case Level Attribute (first event) Text Paid on Time Case Level Attribute (first event) Text Reason for Rejection Case Level Attribute (first event) Text Cash Discount % Case Level Attribute (first event) Numerisch Cash Discount Value Financial per Case (first event) Numerisch Invoice Value Financial per Case (first event) Numerisch Business Unit Case Level Attribute (first event) Text Region Case Level Attribute (first event) Text Wählen Sie Speichern und analysieren aus, nachdem Sie die Felder zugeordnet haben.
Warten, bis Analyse abgeschlossen ist. Dieser Prozess kann einige Minuten dauern.









Nach Abschluss der Analyse sollte die Prozessübersicht der folgenden Abbildung ähneln.
