Arten von ML
Es gibt mehrere Arten von maschinellem Lernen, und Sie müssen den geeigneten Typ anwenden, je nachdem, was Sie vorhersagen möchten. Eine Aufschlüsselung allgemeiner Arten von maschinellem Lernen wird im folgenden Diagramm gezeigt.
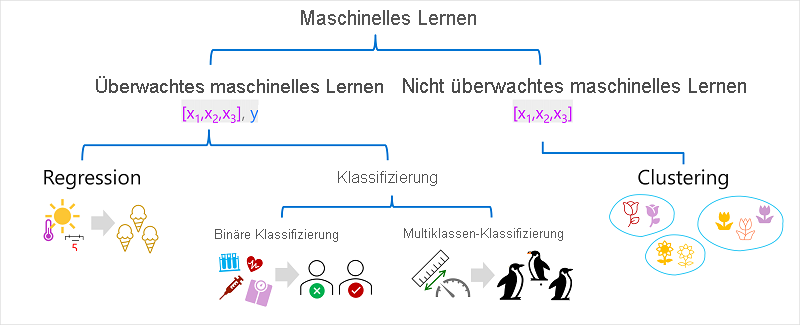
Überwachtes maschinelles Lernen
Überwachtes maschinelles Lernen ist ein allgemeiner Begriff für Machine Learning-Algorithmen, in denen die Schulungsdaten sowohl Featurewerte als auch bekannte Bezeichnungswerte enthalten. Überwachtes maschinelles Lernen wird verwendet, um Modelle zu trainieren, indem eine Beziehung zwischen den Features und Bezeichnungen in früheren Beobachtungen bestimmt wird, sodass unbekannte Bezeichnungen in zukünftigen Fällen für Features vorhergesagt werden können.
Rückentwicklung
Regression ist eine Form des überwachten maschinellen Lernens, in dem die vom Modell vorhergesagte Beschriftung ein numerischer Wert ist. Beispiel:
- Die Anzahl von Eiscremes, die an einem bestimmten Tag verkauft werden, basierend auf der Temperatur, Niederschlag und Windgeschwindigkeit.
- Der Verkaufspreis einer Immobilie basierend auf ihrer Größe in Quadratfuß, der Anzahl der Schlafzimmer, die es enthält, und sozioökonomische Metriken für ihren Standort.
- Die Kraftstoffeffizienz (in Meilen pro Gallone) eines Autos basierend auf seiner Motorgröße, Gewicht, Breite, Höhe und Länge.
Klassifizierung
Klassifizierung ist eine Form des überwachten maschinellen Lernens, in dem die Bezeichnung eine Kategorisierung oder klasse darstellt. Es gibt zwei gängige Klassifizierungsszenarien.
Binäre Klassifizierung
In der binären Klassifizierung bestimmt die Bezeichnung, ob das beobachtete Element eine Instanz einer bestimmten Klasse ist (oder nicht). Oder anders ausgedrückt: Binäre Klassifizierungsmodelle prognostizieren eines von zwei sich gegenseitig ausschließenden Ergebnissen. Beispiel:
- Ob ein Patient aufgrund klinischer Metriken wie Gewicht, Alter, Blutzucker usw. risikobehaftet ist.
- Ob ein Bankkunde einen Kredit basierend auf Einkommen, Kreditgeschichte, Alter und anderen Faktoren nicht zurückzahlen wird.
- Ob ein Mailinglistenkunde positiv auf ein Marketingangebot basierend auf demografischen Attributen und früheren Käufen reagiert.
In all diesen Beispielen prognostiziert das Modell eine binäre wahr falsche/ oder positive/negative Vorhersage für eine einzelne mögliche Klasse.
Mehrklassenklassifizierung
Die Mehrklassenklassifizierung erweitert die binäre Klassifizierung, um eine Bezeichnung vorherzusagen, die eine von mehreren möglichen Klassen darstellt. Beispiel:
- Die Arten eines Pinguins (Adelie, Gentoo oder Chinstrap) basieren auf seinen physikalischen Messungen.
- Das Genre eines Films (Komödie, Horror, Romantik, Abenteuer oder Science Fiction) basierend auf seiner Besetzung, Regie und Budget.
In den meisten Szenarien, die einen bekannten Satz von mehreren Klassen umfassen, wird die Mehrklassenklassifizierung verwendet, um sich gegenseitig ausschließende Bezeichnungen vorherzusagen. Beispielsweise kann ein Pinguin nicht sowohl ein Gentoo als auch ein Adelie sein. Es gibt jedoch auch einige Algorithmen, die Sie verwenden können, um Klassifizierungsmodelle mit mehreren Bezeichnungen zu trainieren, in denen es möglicherweise mehrere gültige Bezeichnungen für eine einzelne Beobachtung gibt. Beispielsweise könnte ein Film potenziell als Science-Fiction und Komödie kategorisiert werden.
Unüberwachtes maschinelles Lernen
Unbeaufsichtigtes maschinelles Lernen umfasst Schulungsmodelle mit Daten, die nur aus Featurewerten ohne bekannte Bezeichnungen bestehen. Nicht überwachte Machine Learning-Algorithmen bestimmen Beziehungen zwischen den Features der Beobachtungen in den Schulungsdaten.
Clusterbildung
Die häufigste Form des nicht überwachten maschinellen Lernens ist Clustering. Ein Clusteringalgorithmus identifiziert Ähnlichkeiten zwischen Beobachtungen basierend auf ihren Features und gruppiert sie in diskrete Cluster. Beispiel:
- Gruppieren Sie ähnliche Blumen anhand ihrer Größe, der Anzahl der Blätter und der Anzahl der Blütenblätter.
- Identifizieren Sie Gruppen ähnlicher Kunden basierend auf demografischen Attributen und Einkaufsverhalten.
In einigen Fällen ähnelt clustering der Klassifizierung von mehreren Klassen; darin kategorisiert es Beobachtungen in diskrete Gruppen. Der Unterschied besteht darin, dass Sie bei verwendung der Klassifizierung bereits die Klassen kennen, zu denen die Beobachtungen in den Schulungsdaten gehören; der Algorithmus funktioniert daher, indem die Beziehung zwischen den Features und der bekannten Klassifizierungsbezeichnung bestimmt wird. Im Clustering gibt es keine zuvor bekannte Clusterbeschriftung, und der Algorithmus gruppiert die Datenbeobachtungen basierend auf der Ähnlichkeit von Features.
In einigen Fällen wird clustering verwendet, um den Satz von Klassen zu bestimmen, die vor dem Trainieren eines Klassifizierungsmodells vorhanden sind. Sie können beispielsweise Clustering verwenden, um Ihre Kunden in Gruppen zu segmentieren, und dann diese Gruppen analysieren, um verschiedene Kundenklassen zu identifizieren und zu kategorisieren (high value - low volume, frequent small purchaser usw.). Sie können dann Ihre Kategorisierungen verwenden, um die Beobachtungen in Ihren Clusteringergebnissen zu kennzeichnen und die bezeichneten Daten zu verwenden, um ein Klassifizierungsmodell zu trainieren, das vorhergesagt wird, zu welcher Kundenkategorie ein neuer Kunde gehören könnte.