Binäre Klassifizierung
Tip
Weitere Details finden Sie auf der Registerkarte "Text und Bilder ".
Klassifizierung, wie Regression, ist eine überwachte Maschinelle Lerntechnik; und folgt daher dem gleichen iterativen Prozess der Schulung, Validierung und Auswertung von Modellen. Anstatt numerische Werte wie ein Regressionsmodell zu berechnen, berechnen die Algorithmen, die zum Trainieren von Klassifizierungsmodellen verwendet werden , Wahrscheinlichkeitswerte für die Klassenzuweisung und die Auswertungsmetriken, die zum Bewerten der Modellleistung verwendet werden, vergleichen die vorhergesagten Klassen mit den tatsächlichen Klassen.
Binäre Klassifizierungsalgorithmen werden verwendet, um ein Modell zu trainieren, das eine von zwei möglichen Bezeichnungen für eine einzelne Klasse vorhersagt. Im Wesentlichen wird wahr oder falsch vorhergesagt. In den meisten realen Szenarien bestehen die Datenbeobachtungen, die verwendet werden, um das Modell zu trainieren und zu validieren, aus mehreren Featurewerten (x) und einem y-Wert , der entweder 1 oder 0 ist.
Beispiel : binäre Klassifizierung
Um zu verstehen, wie die binäre Klassifizierung funktioniert, sehen wir uns ein vereinfachtes Beispiel an, das ein einzelnes Feature (x) verwendet, um vorherzusagen, ob die Bezeichnung y 1 oder 0 ist. In diesem Beispiel verwenden wir den Blutzuckerspiegel eines Patienten, um vorherzusagen, ob der Patient Diabetes hat oder nicht. Hier sind die Daten, mit denen wir das Modell trainieren:

|

|
|---|---|
| Blutzucker (x) | Zuckerkrank? (y) |
| 67 | 0 |
| 103 | 1 |
| 114 | 1 |
| 72 | 0 |
| 116 | 1 |
| 65 | 0 |
Schulung eines binären Klassifizierungsmodells
Um das Modell zu trainieren, verwenden wir einen Algorithmus, um die Schulungsdaten an eine Funktion anzupassen, die die Wahrscheinlichkeit der Klassenbeschriftung berechnet, die wahr ist (mit anderen Worten, dass der Patient Diabetes hat). Die Wahrscheinlichkeit wird als Wert zwischen 0,0 und 1,0 gemessen, sodass die Gesamtwahrscheinlichkeit für alle möglichen Klassen 1,0 beträgt. Wenn beispielsweise die Wahrscheinlichkeit eines Patienten mit Diabetes 0,7 beträgt, dann gibt es eine entsprechende Wahrscheinlichkeit von 0,3, dass der Patient nicht diabetisch ist.
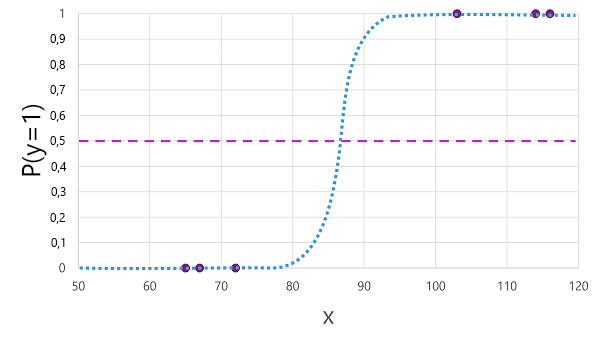
Es gibt viele Algorithmen, die für die binäre Klassifizierung verwendet werden können, z. B. logistische Regression, die eine Sigmoidfunktion (S-förmige) Funktion mit Werten zwischen 0,0 und 1,0 ableiten kann, wie folgt:
Hinweis
Trotz seines Namens wird in der maschinellen Learning-Logistikregression zur Klassifizierung verwendet, nicht für Regression. Der wichtigste Punkt ist die logistikische Natur der Funktion, die eine S-förmige Kurve zwischen einem unteren und oberen Wert beschreibt (0,0 und 1,0 bei Verwendung für binäre Klassifizierung).
Die vom Algorithmus erzeugte Funktion beschreibt die Wahrscheinlichkeit, dass y wahr (y=1) für einen bestimmten Wert von x ist. Mathematisch können Sie die Funktion wie folgt ausdrücken:
f(x) = P(y=1 | x)
Für drei der sechs Beobachtungen in den Schulungsdaten wissen wir, dass y definitiv wahr ist, also die Wahrscheinlichkeit für diese Beobachtungen, dass y= 1 1 ist, und für die anderen drei, wir wissen, dass y definitiv falsch ist, also die Wahrscheinlichkeit, dass y=1 0,0 ist. Die S-förmige Kurve beschreibt die Wahrscheinlichkeitsverteilung, sodass das Zeichnen eines X-Werts in der Linie die entsprechende Wahrscheinlichkeit identifiziert, dass y1 ist.
Das Diagramm enthält auch eine horizontale Linie, um den Schwellenwert anzugeben, bei dem ein modellbasiertes Modell wahr (1) oder falsch (0) vorhersagen wird. Der Schwellenwert liegt am Mittelpunkt für y (P(y) = 0,5). Für alle Werte an diesem oder obigen Punkt wird das Modell "true " (1) vorhersagen; während für alle Werte unter diesem Punkt falsch (0) vorhergesagt wird. Beispielsweise würde die Funktion für einen Patienten mit einem Blutzuckerspiegel von 90 einen Wahrscheinlichkeitswert von 0,9 ergeben. Da 0,9 höher als der Schwellenwert von 0,5 ist, würde das Modell wahr (1) vorhersagen - mit anderen Worten, der Patient wird vorhergesagt, Diabetes zu haben.
Auswerten eines binären Klassifizierungsmodells
Wie bei der Regression halten Sie beim Trainieren eines binären Klassifizierungsmodells eine zufällige Teilmenge von Daten zurück, mit der das trainierte Modell überprüft werden soll. Nehmen wir an, wir haben die folgenden Daten zurückgehalten, um unsere Diabetesklassifizierung zu überprüfen:
| Blutzucker (x) | Zuckerkrank? (y) |
|---|---|
| 66 | 0 |
| 107 | 1 |
| 112 | 1 |
| 71 | 0 |
| 87 | 1 |
| 89 | 1 |
Das Anwenden der Logistikfunktion, die wir zuvor auf die x-Werte abgeleitet haben, führt zur folgenden Zeichnung.

Basierend darauf, ob die von der Funktion berechnete Wahrscheinlichkeit über oder unter dem Schwellenwert liegt, generiert das Modell für jede Beobachtung eine vorhergesagte Beschriftung von 1 oder 0. Anschließend können wir die vorhergesagten Klassenbeschriftungen (ŷ) mit den tatsächlichen Klassenbeschriftungen (y) vergleichen, wie hier gezeigt:
| Blutzucker (x) | Tatsächliche Diabetesdiagnose (y) | Vorhergesagte Diabetesdiagnose (ŷ) |
|---|---|---|
| 66 | 0 | 0 |
| 107 | 1 | 1 |
| 112 | 1 | 1 |
| 71 | 0 | 0 |
| 87 | 1 | 0 |
| 89 | 1 | 1 |
Metriken zur Bewertung der binären Klassifizierung
Der erste Schritt bei der Berechnung von Auswertungsmetriken für ein binäres Klassifizierungsmodell besteht in der Regel darin, eine Matrix der Anzahl der korrekten und falschen Vorhersagen für jede mögliche Klassenbeschriftung zu erstellen:
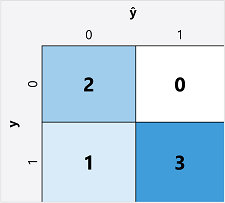
Diese Visualisierung wird als Verwirrungsmatrix bezeichnet und zeigt die Vorhersagesummen an, wobei:
- ŷ=0 und y=0: True Negatives (TN)
- ŷ=1 und y=0: False Positives (FP)
- ŷ=0 und y=1: Falsch negative Ergebnisse (FN)
- ŷ=1 und y=1: Wahr positive Ergebnisse (TP)
Die Anordnung der Verwirrungsmatrix ist so, dass korrekte (true) Vorhersagen in einer diagonalen Linie von oben links nach unten rechts angezeigt werden. Häufig wird die Farbintensität verwendet, um die Anzahl der Vorhersagen in jeder Zelle anzugeben, sodass ein schneller Blick auf ein Modell, das gut vorhergesagt wird, einen tief schattierten diagonalen Trend erkennen sollte.
Genauigkeit
Die einfachste Metrik, die Sie aus der Verwirrungsmatrix berechnen können, ist Genauigkeit – der Anteil der Vorhersagen, die das Modell richtig abgerufen hat. Die Genauigkeit wird wie folgt berechnet:
(TN+TP) ÷ (TN+FN+FP+TP)
Im Falle unseres Diabetesbeispiels lautet die Berechnung:
(2+3) ÷ (2+1+0+3)
= 5 ÷ 6
= 0.83
Für unsere Validierungsdaten lieferte das Diabetesklassifizierungsmodell also in 83 % der Fälle korrekte Vorhersagen.
Die Genauigkeit mag anfänglich wie eine gute Metrik aussehen, um ein Modell auszuwerten, aber berücksichtigen Sie dies. Angenommen, 11% der Bevölkerung hat Diabetes. Sie könnten ein Modell erstellen, das immer 0 vorhersagt, und es würde eine Genauigkeit von 89%erzielen, obwohl es keinen echten Versuch macht, zwischen Patienten zu unterscheiden, indem sie ihre Merkmale auswerten. Was wir wirklich brauchen, ist ein tieferes Verständnis dafür, wie das Modell bei der Vorhersage von 1 für positive Fälle und 0 für negative Fälle ausgeführt wird.
Abruf
Rückruf ist eine Metrik, die den Anteil positiver Fälle misst, die das Modell richtig identifiziert hat. Mit anderen Worten, im Vergleich zur Anzahl der Patienten, die Diabetes haben , wie viele hat das Modell Diabetes vorhergesagt ?
Die Rückrufformel lautet:
TP ÷ (TP+FN)
Für unser Diabetesbeispiel:
3 ÷ (3+1)
= 3 ÷ 4
= 0.75
Unser Modell hat also 75 % der Patient*inen mit Diabetes richtig als Diabetiker*innen identifiziert.
Präzision
Präzision ist eine ähnliche Metrik wie Recall, misst jedoch den Anteil der vorhergesagten positiven Fälle, bei denen das tatsächliche Label positiv ist. Mit anderen Worten, welchen Anteil der Vom Modell vorhergesagten Patienten haben Diabetes tatsächlich ?
Die Formel für Genauigkeit lautet:
TP ÷ (TP+FP)
Für unser Diabetesbeispiel:
3 ÷ (3+0)
= 3 ÷ 3
= 1.0
Also haben 100% der Patienten, die von unserem Modell vorhergesagt wurden, tatsächlich Diabetes.
F1-Score
F1-Score ist eine Gesamtmetrik, die Abruf und Präzision kombiniert. Die Formel für den F1-Score lautet:
(2 x Genauigkeit x Rückruf) ÷ (Genauigkeit + Rückruf)
Für unser Diabetesbeispiel:
(2 x 1,0 x 0,75) ÷ (1,0 + 0,75)
= 1,5 ÷ 1,75
= 0,86
Fläche unter der Kurve (AUC)
Ein weiterer Name für den Rückruf ist die wahre positive Rate (TPR), und es gibt eine entsprechende Metrik, die als falsch positive Rate (FPR) bezeichnet wird, die als FP÷(FP+TN) berechnet wird. Wir wissen bereits, dass der TPR für unser Modell bei Verwendung eines Schwellenwerts von 0,5 0,75 beträgt und wir die Formel für FPR verwenden können, um einen Wert von 0÷2 = 0 zu berechnen.
Natürlich, wenn wir den Schwellenwert ändern würden, über dem das Modell „true“ (1) vorhersagt, würde es die Anzahl positiver und negativer Vorhersagen beeinflussen und somit die TPR- und FPR-Metriken ändern. Diese Metriken werden häufig verwendet, um ein Modell auszuwerten, indem eine empfangene Operator-Merkmalskurve (ROC) dargestellt wird, die die TPR und FPR für jeden möglichen Schwellenwert zwischen 0,0 und 1,0 vergleicht:
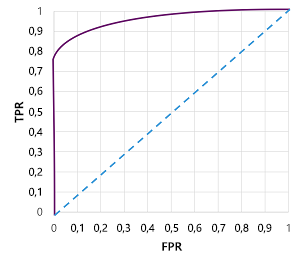
Die ROC-Kurve für ein perfektes Modell würde an der TPR-Achse links gerade nach oben und dann über die FPR-Achse oben verlaufen. Da der Plotbereich für die Kurve 1x1 misst, wäre der Bereich unter dieser perfekten Kurve 1,0 (was bedeutet, dass das Modell in 100 % der Fälle richtig ist). Im Gegensatz dazu stellt eine diagonale Linie von unten links nach oben rechts die Ergebnisse dar, die durch zufälliges Erraten einer binären Beschriftung erreicht werden würden; Erzeugen eines Bereichs unter der Kurve von 0,5. Mit anderen Worten: Bei zwei möglichen Klassenbezeichnungen ist vernünftigerweise davon auszugehen, dass diese in 50 % der Fälle korrekt erraten werden.
Im Falle unseres Diabetesmodells wird die oben genannte Kurve erzeugt, und die Fläche unter der Kurve (AUC) ist 0,875. Da die AUC höher als 0,5 ist, können wir abschließen, dass das Modell besser vorhersagen kann, ob ein Patient Diabetes hat oder nicht, als zufällig erraten.