Grundlegendes zum Entwicklungslebenszyklus einer LLM-App (Large Language Model)
Bevor Sie wissen, wie Sie mit dem Eingabeaufforderungsfluss arbeiten, untersuchen wir den Entwicklungslebenszyklus einer LLM-Anwendung (Large Language Model).
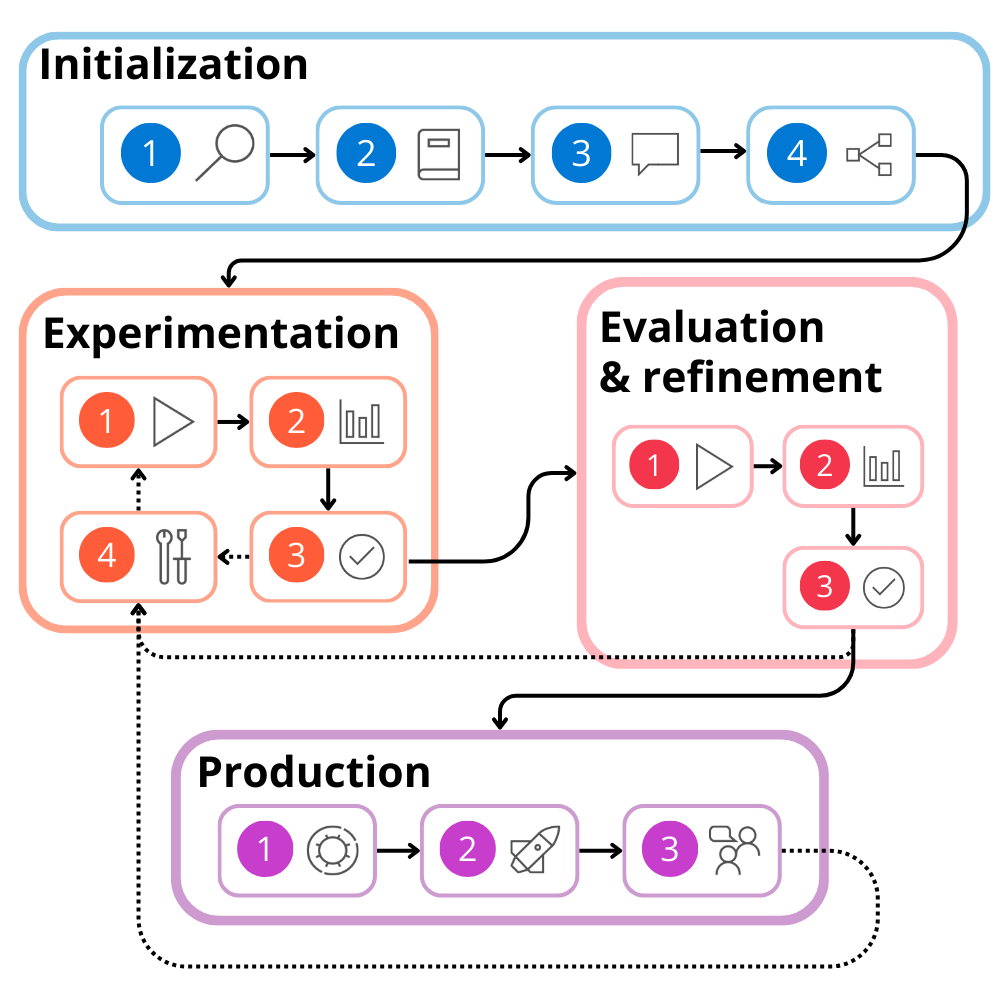
Der Lebenszyklus umfasst die folgenden Phasen:
- Initialisierung: Definieren Sie den Anwendungsfall, und entwerfen Sie die Lösung.
- Experimentierung: Entwickeln Sie einen Fluss und testen Sie mit einem kleinen Dataset.
- Auswertung und Verfeinerung: Bewerten sie den Fluss mit einem größeren Dataset.
- Produktion: Bereitstellen und Überwachen des Flows und der Anwendung.
Sowohl bei der Auswertung als auch bei der Verfeinerung und produktion stellen Sie möglicherweise fest, dass Ihre Lösung verbessert werden muss. Sie können wieder zu Experimenten zurückkehren, in denen Sie Ihren Fluss kontinuierlich entwickeln, bis Sie mit den Ergebnissen zufrieden sind.
Sehen wir uns jede dieser Phasen ausführlicher an.
Initialisierung
Stellen Sie sich vor, Sie möchten eine LLM-Anwendung entwerfen und entwickeln, um Nachrichtenartikel zu klassifizieren. Bevor Sie mit dem Erstellen eines Vorgangs beginnen, müssen Sie definieren, welche Kategorien als Ausgabe verwendet werden sollen. Sie müssen verstehen, wie ein typischer Nachrichtenartikel aussieht, wie Sie den Artikel als Eingabe für Ihre Anwendung präsentieren und wie die Anwendung die gewünschte Ausgabe generiert.
Mit anderen Worten, während der Initialisierung können Sie:

- Definieren des Ziels
- Sammeln eines Beispieldatensatzes
- Erstellen einer einfachen Eingabeaufforderung
- Entwerfen des Flusses
Zum Entwerfen, Entwickeln und Testen einer LLM-Anwendung benötigen Sie ein Beispiel-Dataset, das als Eingabe dient. Ein Beispieldatenset ist eine kleine repräsentative Teilmenge der Daten, die Sie schließlich als Eingabe für Ihre LLM-Anwendung analysieren möchten.
Beim Sammeln oder Erstellen des Beispieldatensatzes sollten Sie die Vielfalt der Daten sicherstellen, um verschiedene Szenarien und Edgefälle abzudecken. Außerdem sollten Sie alle vertraulichen Datenschutzinformationen aus dem Dataset entfernen, um Sicherheitsrisiken zu vermeiden.
Experimentieren
Sie haben ein Beispiel-Dataset von Newsartikeln gesammelt und entschieden, in welche Kategorien die Artikel eingeteilt werden sollen. Sie haben einen Ablauf entwickelt, der einen Nachrichtenartikel als Eingabe verwendet und ein LLM zur Klassifizierung des Artikels nutzt. Um zu testen, ob Ihr Ablauf die erwartete Ausgabe generiert, testen Sie ihn mit Ihrem Beispieldatensatz.
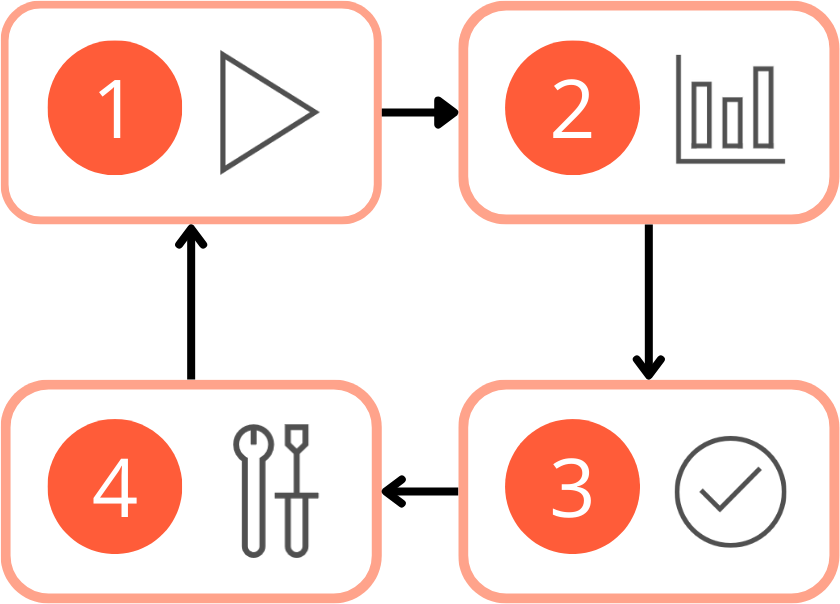
Die Experimentierphase ist ein iterativer Prozess, bei dem Sie (1) den Fluss für ein Beispiel-Dataset ausführen . Anschließend (2) bewerten Sie die Leistung des Prompts. Wenn Sie (3) mit dem Ergebnis zufrieden sind, können Sie mit der Auswertung und Verfeinerung fortfahren . Wenn Sie denken, dass es Verbesserungsmöglichkeiten gibt, können Sie (4) den Fluss ändern, indem Sie die Eingabeaufforderung oder den Fluss selbst ändern .
Auswertung und Verfeinerung
Wenn Sie mit der Ausgabe des Flows zufrieden sind, der Nachrichtenartikel basierend auf dem Beispiel-Dataset klassifiziert, können Sie die Leistung des Flows anhand eines größeren Datasets bewerten.
Indem Sie den Fluss für ein größeres Dataset testen, können Sie auswerten, wie gut die LLM-Anwendung auf neue Daten generalisiert. Bei der Auswertung können Sie potenzielle Engpässe oder Bereiche zur Optimierung oder Verfeinerung identifizieren.
Wenn Sie Ihren Flow bearbeiten, sollten Sie ihn zuerst mit einem kleineren Dataset ausführen, bevor Sie ihn erneut mit einem größeren Dataset ausführen. Wenn Sie Ihren Fluss mit einem kleineren Dataset testen, können Sie schneller auf probleme reagieren.
Sobald Ihre LLM-Anwendung bei der Behandlung verschiedener Szenarien robust und zuverlässig erscheint, können Sie die LLM-Anwendung in die Produktion verschieben.
Produktion
Schließlich ist Ihre Nachrichtenartikelklassifizierungsanwendung für die Produktion bereit.

Während der Produktion:
- Optimieren Sie den Fluss, der eingehende Artikel für Effizienz und Effektivität klassifiziert.
- Bereitstellen Sie Ihren Workflow an einem Endpunkt. Wenn Sie den Endpunkt aufrufen, wird der Ablauf zum Ausführen ausgelöst, und die gewünschte Ausgabe wird generiert.
- Überwachen Sie die Leistung Ihrer Lösung, indem Sie Nutzungsdaten und Endbenutzerfeedback sammeln. Durch Verständnis der Leistung der Anwendung können Sie den Fluss bei Bedarf verbessern.
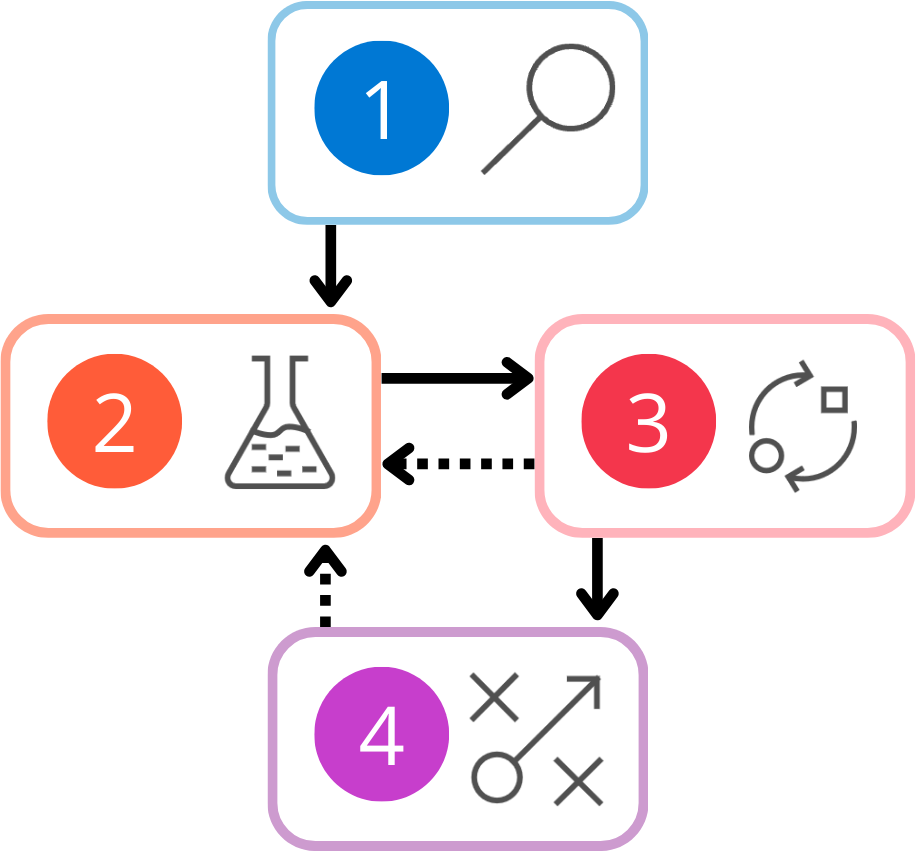
Erkunden des vollständigen Entwicklungslebenszyklus
Nachdem Sie die einzelnen Phasen des Entwicklungslebenszyklus einer LLM-Anwendung verstanden haben, können Sie sich mit der vollständigen Übersicht vertraut machen: