HDInsight-Konfigurationsoptionen
HDInsight umfasst eine Vielzahl von integrierten OSS-Technologien, die sowohl für Streaming- als auch für Batchdatenszenarios verwendet werden können. Hierbei handelt es sich um in Lambdaarchitekturen definierte Begriffe. In diesem Architekturmodell gibt es einen heißen und einen kalten Datenpfad. Der heiße Datenpfad wird in Echtzeit von Geräten, Sensoren oder Anwendungen generiert, und Daten werden nahezu in Echtzeit analysiert. Dies wird häufig als Datenstreaming bezeichnet. Bei einem kalten Datenpfad werden Daten in der Regel aus anderen Datenspeichern in Batches verschoben. Diese werden häufig als Batchdaten bezeichnet.
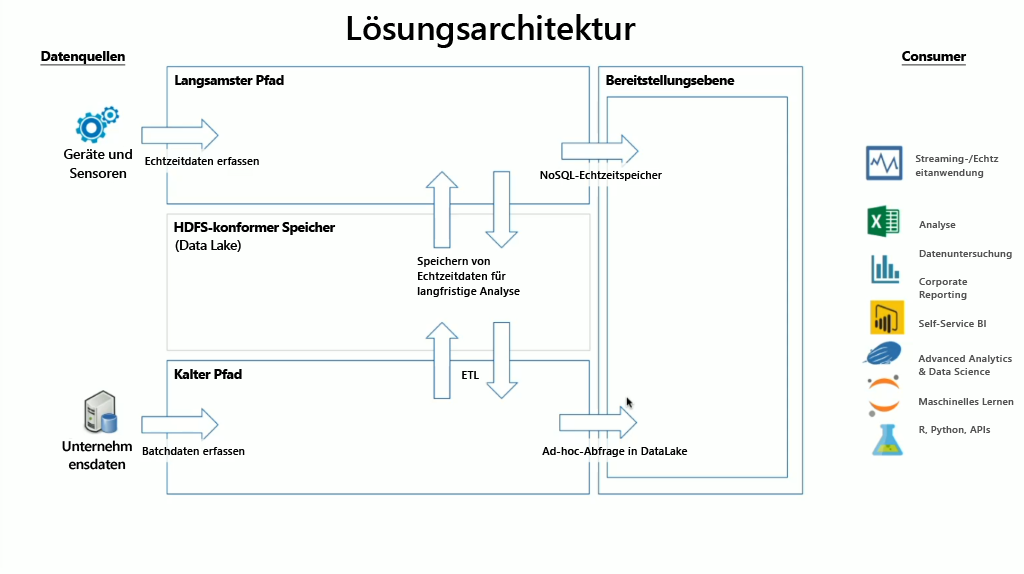
Wenn Sie HDInsight implementieren, werden Daten in einem kompatiblen Hadoop Distributed File System (HDFS) gespeichert. In Azure wird in der Regel Data Lake Gen2 als Datenspeicher verwendet, da dieser Speicher mit HDFS kompatibel ist. Daten aus dem heißen und dem kalten Pfad werden nach der Verarbeitung in einem zentralisierten Datenspeicher namens Data Lake gespeichert. Die Data Lake-Instanz kann in mehrere Depots unterteilt werden, in denen die Daten gespeichert werden und die vom Status der Daten (Zielzone, Transformationszone etc.), den Zugriffsanforderungen (heiß, warm und kalt) und den Unternehmensgruppen definiert werden können. Die Bereitstellungsebene ist das letzte Depot in der Data Lake-Instanz, das Daten in einem Format enthält, das von verschiedenen Consumern genutzt werden kann.
Wichtig ist, dass sich der Computeaspekt von HDInsight mit der Verarbeitung von Streaming- oder Batchdaten beschäftigt und je nach Clustertyp variieren kann, den Sie bei der Bereitstellung eines HDInsight-Clusters auswählen. HDInsight bietet die Dienste in individuellen Clusteroptionen an, die Sie der folgenden Tabelle entnehmen können.
| Clustertyp | Beschreibung |
|---|---|
| Apache Hadoop | Ein Framework, das HDFS und ein einfaches MapReduce-Programmiermodell zum Verarbeiten und Analysieren von Batchdaten nutzt. |
| Apache Spark | Ein Open-Source-Framework für die Parallelverarbeitung, das die arbeitsspeicherinterne Verarbeitung unterstützt, um die Leistung von Anwendungen zur Analyse von Big Data zu steigern. |
| hbase | Eine auf Hadoop basierende NoSQL-Datenbank, die wahlfreien Zugriff und starke Konsistenz für große Mengen unstrukturierter und teilstrukturierter Daten bietet – in einer potenziellen Dimension von Milliarden von Zeilen multipliziert mit Milliarden von Spalten. |
| Interaktive Apache-Abfrage | Arbeitsspeicherinternes Caching für interaktive und schnellere Hive-Abfragen. |
| Apache Kafka | Eine Open Source-Plattform zum Erstellen von Streamingdatenpipelines und -anwendungen. Kafka bietet auch eine Nachrichtenwarteschlangenfunktion, die Ihnen das Veröffentlichen und Abonnieren von Datenströmen ermöglicht. |
Daher ist es wichtig, den richtigen Clustertyp auszuwählen, um dem Geschäftsszenario gerecht zu werden, für das Sie eine Lösung finden möchten. Unabhängig vom ausgewählten Clustertyp werden dem Cluster auch weitere Open-Source-Komponenten hinzugefügt, um zusätzliche Funktionen bereitzustellen. Beispiele:
Hadoop-Verwaltung
HCatalog: eine Tabellen- und Speicherverwaltungsebene für Hadoop
Apache Ambari: vereinfacht die Verwaltung und Überwachung von Apache Hadoop-Clustern
Apache Oozie: ein System zur Planung von Workflows, mit dem Apache Hadoop-Aufträge verwaltet werden können
Apache Hadoop YARN: eine Lösung zur Ressourcenverwaltung und Auftragsplanung/-überwachung
Apache ZooKeeper: ein zentralisierter Dienst zur Verwaltung von Konfigurationsinformationen und Benennungen und zum Bereitstellen von verteilten Synchronisierungen und Gruppendiensten
Datenverarbeitung
Apache Hadoop MapReduce: ein Framework zum unkomplizierten Schreiben von Anwendungen, die große Mengen an Daten verarbeiten
Apache Tez: ein Anwendungsframework zum Verarbeiten von Daten
Apache Hive: erleichtert die Verwaltung von großen Datasets, die in verteilten SQL-Speichern gespeichert sind
Datenanalyse
Apache Pig: bietet eine Abstraktionsebene über MapReduce zum Analysieren von großen Datasets
Apache Phoenix: ermöglicht OLTP und operative Analysen in Hadoop
Apache Mahout: ein Algebra-Framework zum Erstellen eigener Algorithmen
Hinweis
Zum Zeitpunkt der Erstellung dieses Artikels werden Azure Data Lake Gen1 und Azure Blob Storage als Datenspeicherebenen für HDInsight unterstützt. Sie sollten Daten zu Azure Data Lake Gen2 migrieren, da es sich dabei um die empfohlene Speicherplattform für Spark und Hadoop und den Standardspeicher für HBase handelt.