Erkunden der Datenklassifizierung
Vertrauliche Daten, die in Microsoft SQL Server, Azure SQL-Datenbank oder azure SQL Managed Instance gespeichert sind, sollten innerhalb der Datenbank klassifiziert werden. Diese Klassifizierung hilft Benutzern und Anwendungen, die Vertraulichkeit der gespeicherten Daten zu verstehen.
Die Datenklassifizierung erfolgt auf Spaltenbasis. Eine einzelne Tabelle kann Spalten als öffentlich, vertraulich oder streng vertraulich klassifiziert haben.
Zunächst wurde die Datenklassifizierung in SQL Server Management Studio eingeführt, wobei erweiterte Eigenschaften von Objekten zum Speichern von Klassifizierungsinformationen verwendet wurden. Ab SQL Server 2019 werden diese Metadaten in einer Katalogansicht gespeichert, die sys.sensitivity_classifications aufgerufen wird. Dieses Feature wird auch von Der Azure SQL-Datenbank und der von Azure SQL verwalteten Instanz unterstützt.
Das Azure-Portal bietet einen Verwaltungsbereich für die Datenklassifizierung Ihrer Azure SQL-Datenbank. Sie können auf dieses Feature zugreifen, indem Sie im Abschnitt "Sicherheit" des Hauptblatts für Ihre Azure SQL-Datenbank die Option "Data Discovery & Classification" auswählen.

Sowohl im Azure-Portal als auch im SQL Server Management Studio können Sie die Datenklassifizierung konfigurieren. Das Klassifizierungsmodul überprüft Ihre Datenbank, um Spalten mit Namen zu identifizieren, die vorschlagen, dass sie vertrauliche Informationen enthalten. Beispielsweise würde eine Spalte mit dem Namen "E-Mail" automatisch als vertrauliche persönliche Informationen gekennzeichnet.

Im Beispiel werden fünf Spalten für die Klassifizierung empfohlen. Die Eigenschaften "Informationstyp " und "Vertraulichkeitsbezeichnung " scheinen mit dem Spaltennamen und dem allgemeinen Zweck konsistent zu sein. Da die Empfehlungen jedoch auf dem Spaltennamen basieren, würde eine Spalte mit dem Namen "Spalte1 ", die E-Mail-Adressen enthält, nicht als vertrauliche persönliche Informationen empfohlen.
Spalten können auch mithilfe des Vertraulichkeits-Assistenten in SQL Server Management Studio oder mithilfe des ADD SENSITIVITY CLASSFICATION T-SQL-Befehls wie folgt klassifiziert werden.
ADD SENSITIVITY CLASSIFICATION TO
[Application].[People].[EmailAddress]
WITH (LABEL='PII', INFORMATION_TYPE='Email')
GO
Die Klassifizierung von Daten ermöglicht es Ihnen, die Sensitivität von Daten innerhalb der Datenbank leicht zu identifizieren. Wenn Sie wissen, welche Spalten vertrauliche Daten enthalten, können Sie einfachere Audits durchführen und leichter erkennen, welche Spalten für die Datenverschlüsselung geeignet sind. Die Klassifizierung ermöglicht es anderen Mitarbeitern innerhalb des Unternehmens, bessere Entscheidungen darüber zu treffen, wie die in der Datenbank verfügbaren Daten behandelt werden.
Anpassen der Klassifizierungstaxonomie
Data Discovery & Classification ist Teil von Microsoft Defender für Cloud. Sie können die Taxonomie von Vertraulichkeitsbezeichnungen anpassen und eine Reihe von Klassifizierungsregeln speziell für Ihre Umgebung definieren.
Sie können Vertraulichkeitsbezeichnungen im Rahmen der Richtlinienverwaltung erstellen und verwalten, indem Sie auf dem Hauptblatt für Ihre Azure SQL-Datenbank-Instanz Datenermittlung und -klassifizierung und dann Konfigurieren auswählen.
Auf der Seite "Informationsschutz " können Sie Bezeichnungen definieren, bewerten und mit einer Reihe von Informationstypen verknüpfen.
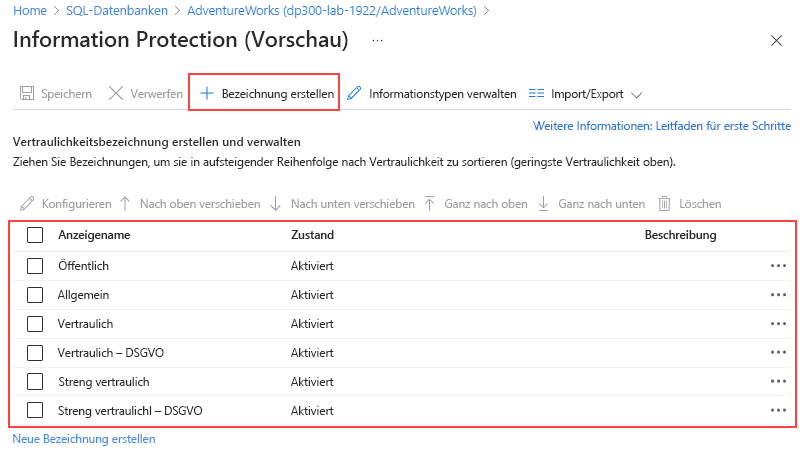
Nachdem Sie die Muster definiert haben, werden sie automatisch zur Ermittlungslogik hinzugefügt, um diese Art von Daten in Ihren Datenbanken zu identifizieren und sofort verfügbar zu sein.
Hinweis
Nur Benutzer mit Administratorrechten in der Stammverwaltungsgruppe der Organisation können Vertraulichkeitsbezeichnungen erstellen und verwalten.