Einführung
Azure Cosmos DB ist die vollständig verwaltete NoSQL-Datenbank von Microsoft in Azure. Als NoSQL-Datenbank ist Azure Cosmos DB sowohl nicht relational als auch horizontal oder vertikal skalierbar. Diese Möglichkeit zum Aufskalieren wird durch Hinzufügen weiterer Knoten oder Partitionen zu einem Container erreicht.
Durch diese Möglichkeit zum Aufskalieren können Containern theoretisch auf eine unendliche Größe anwachsen. Wenn ein Container größer wird, kann er auch immer mehr Anforderungen verarbeiten. Er liefert dabei unabhängig von der Größe immer die gleiche Leistung.
Benutzer müssen zum Erreichen dieses Grads an Skalierbarkeit jedoch die speziellen Konzepte und Techniken für die Modellierung und Partitionierung von Daten von Azure Cosmos DB verstehen. Die Benutzer müssen auch die Konzepte von NoSQL-Datenbanken im Allgemeinen verstehen.
Szenario
Angenommen, Sie arbeiten für ein Startup-Unternehmen im Einzelhandelsbereich und entwerfen eine Datenbank zum Verwalten von Onlinebestellungen. Sie arbeiten an einem Vorschlag für einen effizienten Datenbankentwurf unter Verwendung von Azure Cosmos DB for NoSQL. Sie erhalten als Ausgangspunkt ein Entitätsbeziehungsmodell. Sie möchten ein Höchstmaß an Skalierbarkeit, Leistung und Effizienz bieten, und um diese Aufgabenstellung zu erfüllen, müssen die Daten ordnungsgemäß modelliert werden.
Das folgende Entitätsbeziehungsdiagramm (ER-Modell) enthält die Details der neun Entitäten, mit denen Sie arbeiten werden. Das relationale Modell verfügt über neun Entitäten, die jeweils in ihrer eigenen Tabelle enthalten sind.
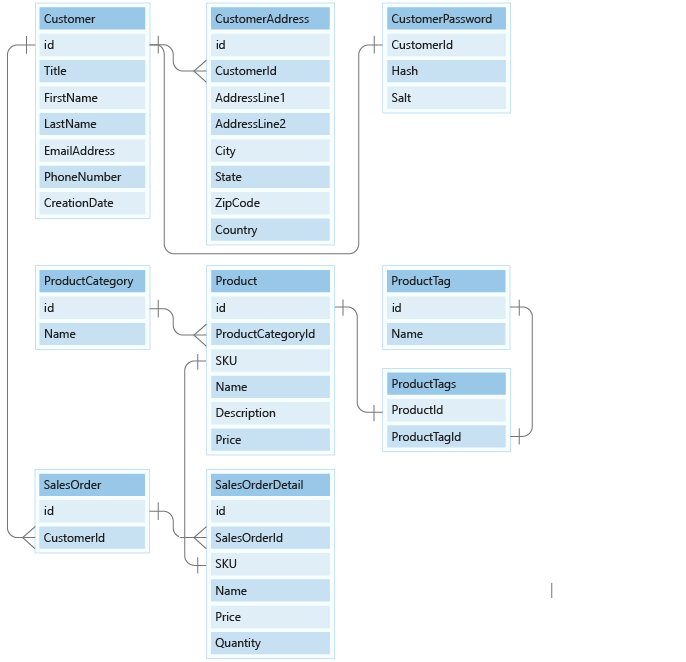
Wie gehen Sie dabei vor?
In diesem Modul wird das vorhandene relationale Datenmodell in eine NoSQL-Datenbank für die E-Commerce-Anwendung umgestaltet. Während dieses Prozesses lernen Sie die folgenden Konzepte kennen:
- Unterschiede zwischen relationalen und NoSQL-Datenbanken: Sie untersuchen einige der Unterschiede zwischen NoSQL-Datenbanken und relationalen Datenbanken und erfahren, warum sie so beschaffen sind.
- Verwenden von Zugriffsmustern für Anwendungsdaten zum Modellieren von Daten: Sie erfahren, wie sich das Lesen und Schreiben von Daten durch eine Anwendung auf die Modellierung einer NoSQL-Datenbank auswirkt.
- Unterscheidung zwischen Einbettung und Verweisen: Sie erfahren, wann Sie Daten in dasselbe Dokument einbetten und wann Sie Daten als separates Dokument speichern sollten.
- Auswählen eines Partitionsschlüssels: Sie lernen wichtige Konzepte kennen, die für die Auswahl des besten Partitionsschlüssels erforderlich sind, um die Möglichkeit zum Aufskalieren zu erhalten und Workloads zu optimieren, die lese- und/oder schreibintensiv sind.
- Modellieren von Nachschlage- oder Verweisdaten: Schließlich erfahren Sie, wie Sie Daten modellieren, die als Nachschlage- oder Verweisdaten für andere Daten verwendet werden.
Was ist das Hauptziel?
Am Ende dieses Moduls verfügen Sie über die erforderlichen Kenntnisse und Fähigkeiten, um Daten für eine NoSQL-Datenbank richtig zu modellieren und zu partitionieren, die unter Azure Cosmos DB bereitgestellt wird (wenn Sie es mit dem Begleitmodul Optimieren Ihrer Datenbank mit erweiterten Modellierungsmustern für Azure Cosmos DB kombinieren).
Nach Abschluss dieses Moduls können Sie folgende Aufgaben durchführen:
- Bestimmen von Zugriffsmustern für Daten
- Anwenden von Datenmodell- und Partitionierungsstrategien zur Unterstützung einer effizienten und skalierbaren NoSQL-Datenbank