Definieren von Architektur, Komponenten und Funktionalität der Datendeduplizierung
Die meisten Organisationen und Unternehmen, darunter auch Contoso, müssen sich mit der Verarbeitung und Speicherung einer wachsenden Datenmenge auseinandersetzen. Es gibt zwar Lösungen, mit denen Sie Daten in die Cloud auslagern und archivieren können, aber in vielen Fällen ist es notwendig, sie in lokalen Rechenzentren zu pflegen. Eine effiziente Verwaltung der Speicherung solcher Daten erfordert geeignete Werkzeuge. Bei Verwendung von Windows Server können Sie zu diesem Zweck die Datendeduplizierung nutzen.
Was ist Datendeduplizierung?
Datendeduplizierung ist ein Rollendienst von Windows Server, der Duplikate in Daten identifiziert und entfernt, ohne die Datenintegrität zu beeinträchtigen. Dadurch wird das Ziel erreicht, mehr Daten zu speichern und weniger physischen Speicherplatz zu verwenden.
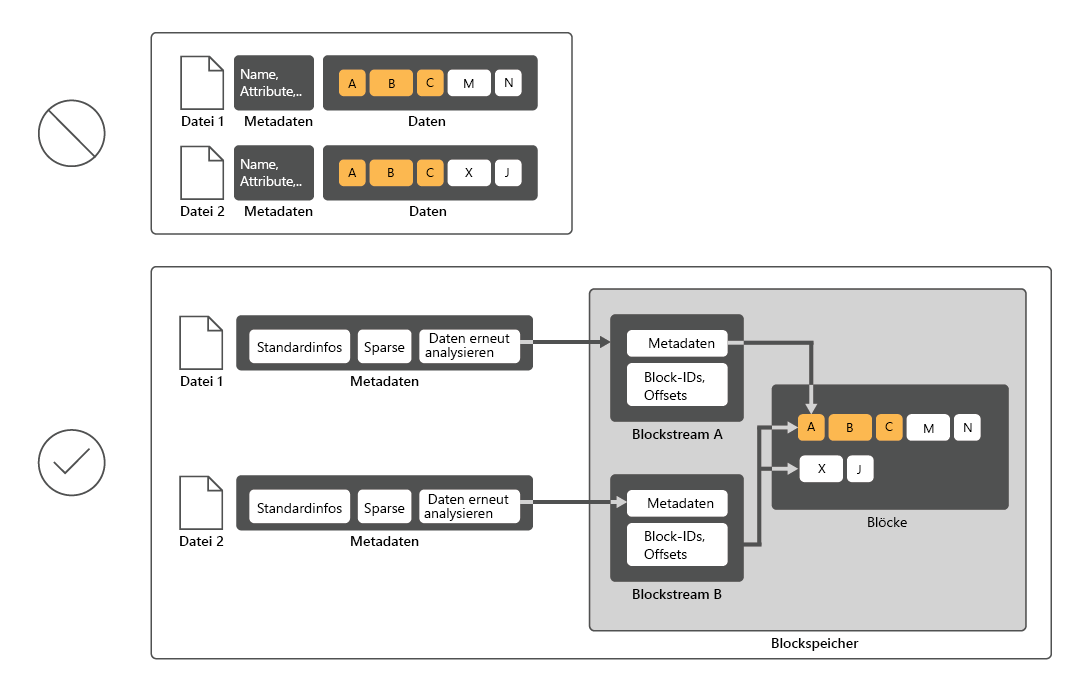
Um die Festplattenauslastung zu reduzieren, scannt die Datendeduplizierung die Dateien, unterteilt sie dann in Blöcke und behält nur eine Kopie jedes Blocks bei. Nach der Deduplizierung sind die Dateien nicht mehr als unabhängige Datenströme gespeichert. Stattdessen ersetzt die Datendeduplizierung die Dateien durch Stubs, die auf Datenblöcke verweisen, die in einem gemeinsamen Blockspeicher gespeichert werden. Der Prozess des Zugriffs auf deduplizierte Daten ist für Benutzer und Apps transparent.
In vielen Fällen erhöht die Datenduplizierung die Gesamtleistung des Datenträgers, da sich mehrere Dateien einen im Arbeitsspeicher zwischengespeicherten Block teilen können. Auf diese Weise wird es möglich, Daten aus diesen Dateien mit weniger Lesevorgängen abzurufen, was die geringe Leistungseinbuße durch das Lesen deduplizierter Dateien kompensiert. Die Datendeduplizierung hat keinen Einfluss auf die Leistung von Schreibvorgängen auf dem Datenträger, da sie auf Daten angewendet wird, die sich bereits auf dem Datenträger befinden.
Was sind die Komponenten der Datendeduplizierung?
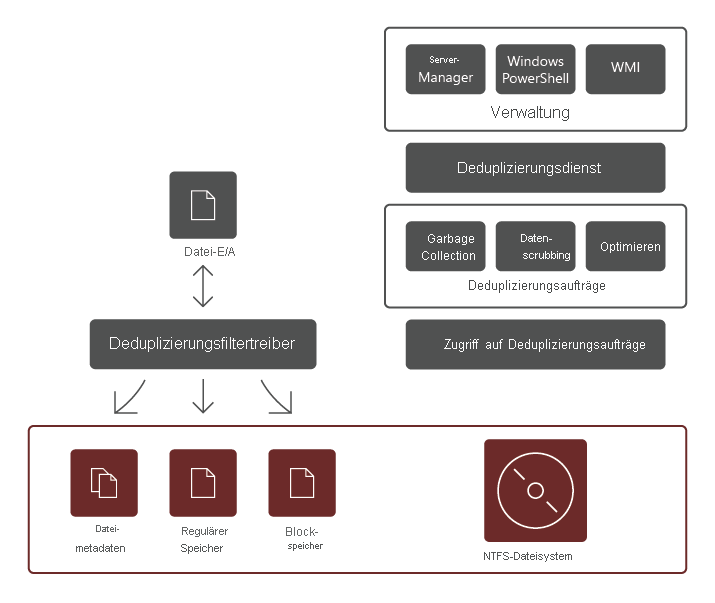
Der Rollendienst „Datendeduplizierung“ besteht aus den folgenden Komponenten:
- Filtertreiber. Diese Komponente leitet Leseanforderungen an die Blöcke um, die Teil der angeforderten Datei sind. Es gibt einen Filtertreiber für jedes Volume.
- Deduplizierungsdienst. Diese Komponente verwaltet die folgenden Aufträge:
- Deduplizierung und Komprimierung. Diese Aufträge verarbeiten Dateien gemäß der Datendeduplizierungsrichtlinie für das Volume. Wenn die Datei nach der ersten Optimierung geändert wird und den Schwellenwert der Datendeduplizierungsrichtlinie für die Optimierung erfüllt, wird die Datei erneut optimiert.
- Garbage Collection (automatische Speicherbereinigung). Mit diesem Auftrag werden gelöschte oder geänderte Daten auf dem Volume verarbeitet, sodass alle Datenblöcke, auf die nicht mehr verwiesen wird, bereinigt werden, um den freien Speicherplatz verfügbar zu machen. Standardmäßig wird die Garbage Collection wöchentlich ausgeführt, Sie können sie aber auch nach dem Löschen vieler Dateien manuell aufrufen.
- Scrubbing (Bereinigung). Dieser Auftrag basiert auf Resilienzfeatures wie Prüfsummenüberprüfung und Metadaten-Konsistenzüberprüfung, um Datenintegritätsprobleme zu identifizieren und nach Möglichkeit automatisch zu beheben.
Hinweis
Aufgrund der zusätzlichen Validierungsfunktionen kann die Deduplizierung frühe Anzeichen von Datenbeschädigungen erkennen und melden.
- Deoptimierung. Dieser Auftrag kehrt die Deduplizierung für alle optimierten Dateien auf dem Volume um. Zu den gängigen Szenarien für die Verwendung dieses Auftragstyps zählen das Beheben von Problemen mit deduplizierten Daten oder die Migration von Daten zu einem anderen System, das die Datendeduplizierung nicht unterstützt.
Hinweis
Vor dem Starten dieses Auftrags sollten Sie das Windows PowerShell-Cmdlet Disable-DedupVolume zum Deaktivieren weiterer Datendeduplizierungsaktivitäten auf einem oder mehreren Volumes verwenden.
Hinweis
Nach der Deaktivierung der Datendeduplizierung verbleibt das Volume im deduplizierten Status, und die vorhandenen deduplizierten Daten bleiben zugänglich. Allerdings beendet der Server die Ausführung von Optimierungsaufträgen für das Volume, und die neuen Daten werden nicht dedupliziert. Anschließend können Sie den Deoptimierungsauftrag verwenden, um die vorhandenen deduplizierten Daten auf einem Volume rückgängig zu machen. Am Ende eines erfolgreichen Deoptimierungsauftrags werden alle Datendeduplizierungs-Metadaten vom Volume gelöscht.
Wichtig
Wenn Sie den Deoptimierungsauftrag verwenden, stellen Sie sicher, dass das Volume, auf dem diese Daten gehostet werden, über genügend freien Speicherplatz verfügt, da alle deduplizierten Dateien wieder ihre ursprüngliche Größe annehmen.
Geltungsbereich der Datendeduplizierung
Die Datendeduplizierung verarbeitet alle Daten auf einem ausgewählten Volume mit wenigen Ausnahmen, z. B.:
- Dateien, die die von Ihnen konfigurierte Deduplizierungsrichtlinie nicht erfüllen.
- Dateien in Ordnern, die Sie explizit aus dem Geltungsbereich der Deduplizierung ausschließen.
- Systemstatusdateien.
- Alternative Datenströme
- Verschlüsselte Dateien.
- Dateien mit erweiterten Attributen.
- Dateien, die kleiner sind als 32 KB.
Hinweis
Ab Windows Server 2019 unterstützt ReFS (Robustes Dateisystem) die Datendeduplizierung für Volumes mit einer Größe von bis zu 64 TB und Dateien mit einer Größe von bis zu 4 TB. Es muss außerdem ein Blockspeicher mit variabler Größe vorhanden sein, der eine optionale Komprimierung beinhaltet, um die Einsparung von Speicherplatz auf dem Datenträger zu maximieren, während die Multithread-Architektur für die Nachbearbeitung die Auswirkungen auf die Leistung auf ein Minimum reduziert.