Definieren der Anwendungsfälle und Interoperabilität der Datendeduplizierung
Die Einsparungen durch Datendeduplizierung variieren je nach Datentyp, Datenzusammensetzung, Größe der Volumes und den Dateien, die diese Volumes enthalten. Sie haben die Möglichkeit, die Einsparungen nach Volume zu bewerten, bevor Sie die Deduplizierung aktivieren.
Anwendungsfälle der Datendeduplizierung
In der folgenden Liste finden Sie typische Deduplizierungszenarien und ihre entsprechenden Volumespeicherplatz-Einsparungen:
| Anwendungsfall | Inhalt | Speicherplatzeinsparungen |
|---|---|---|
| Benutzerdokumente | Veröffentlichung oder Freigabe von Gruppeninhalten, Benutzerstammordner und Profilumleitung für den Zugriff auf Offlinedateien | 30 bis 50 Prozent |
| Softwarebereitstellungsfreigaben | Softwarebinärdateien, CAB-Dateien, Symboldateien, Images und Updates | 70 bis 80 Prozent |
| Virtualisierungsbibliotheken | Speicher für virtuelle Festplattendateien (d. h. VHD- und VHDX-Dateien) zur Bereitstellung für Hypervisoren | 80 bis 95 Prozent |
| Allgemeine Dateifreigabe | Mischung aus allen zuvor identifizierten Datentypen | 50 bis 60 Prozent |
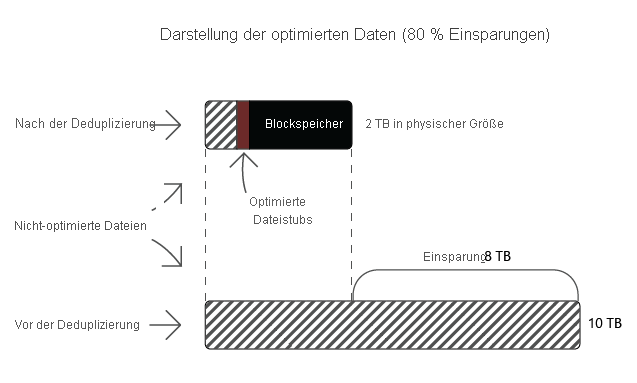
Empfohlene Anwendungsfälle für die Datendeduplizierung
Basierend auf den Einsparungsmöglichkeiten und der typischen Ressourcennutzung in Windows Server werden die Bereitstellungskandidaten für die Deduplizierung als ideal eingestuft, sollten ausgewertet werden oder stellen keine idealen Kandidaten dar.
- Ideale Kandidaten für eine Deduplizierung:
- Ordnerumleitungsserver.
- Virtualisierungsdepot oder Bereitstellungsbibliothek.
- Softwarebereitstellungsfreigaben.
- Microsoft SQL Server- und Microsoft Exchange Server-Sicherungsvolumes.
- Dateien auf freigegebenen Clustervolumes (CSVs) von Dateiservern mit horizontaler Skalierung (SOFS).
- Virtualisierte Sicherungs-VHDs (z. B. Microsoft System Center Data Protection Manager).
- Virtuelle Festplatten (VHDs) in einer virtuellen Desktopinfrastruktur (VDI) – nur persönliche VDIs.
Wichtig
In den meisten VDI-Bereitstellungen ist eine besondere Planung erforderlich, um so genannte Boot-Storms zu berücksichtigen. Dieser Begriff bezieht sich auf die Situation, in der viele Benutzer gleichzeitig versuchen, sich bei Ihrer VDI anzumelden (in der Regel am Anfang eines Geschäftstags). Ein Boot-Storm führt zu einer hohen Auslastung des VDI-Speichersystems und kann bei der ersten Anmeldung zu langen Verzögerungen für VDI-Benutzer führen. Sie können die Auswirkung von Boot-Storms minimieren, indem Sie die Deduplizierung aktivieren. Auf diese Weise werden Blöcke, die beim Starten der VMs aus dem Datenträgerdeduplizierungspeicher gelesen werden, im Arbeitsspeicher zwischengespeichert. Folglich benötigen nachfolgende Lesevorgänge keinen häufigen Zugriff auf die Blöcke auf dem Datenträger, da diese im Cache verfügbar sind.
Sollte anhand des Inhalts überprüft werden:
- Branchenserver.
- Statische Inhaltsanbieter.
- Webserver.
- High Performance Computing (HPC).
Nicht geeignete Kandidaten für eine Deduplizierung:
- Windows Server Update Service (WSUS).
- SQL Server- und Exchange Server-Datenbankvolumes.
Werten Sie das Einsparpotenzial mit dem Tool für die Datendeduplizierungsauswertung aus
Sie können das Tool für die Datendeduplizierungsauswertung (DDPEval.exe) verwenden, um die durch Deduplizierung zu erwartenden Einsparungen auf einem bestimmten Volume zu ermitteln. DDPEval.exe unterstützt die Auswertung lokaler Laufwerke sowie zugeordneter oder nicht zugeordneter Remotefreigaben.
Tipp
Bei der Installation des Deduplizierungsfeatures wird DDPEval.exe automatisch im Verzeichnis „\Windows\System32\“ installiert.
Interoperabilität der Datendeduplizierung
In Windows Server sollten Sie bei der Bereitstellung der Datendeduplizierung die folgenden verwandten Technologien und potenziellen Probleme berücksichtigen:
Windows BranchCache
Sie können den Zugriff auf Daten über das WAN (Wide Area Network) optimieren, indem Sie BranchCache auf Windows-Server- und Windows-Clientbetriebssystemen aktivieren. Beim Kombinieren der beiden Technologien sind alle deduplizierten Dateien bereits indiziert und mit einem Hash versehen, wodurch die Verarbeitung von Datenanforderungen aus einer Zweigstelle beschleunigt wird. Dies ähnelt der Vorabindizierung oder Voraborganisation mittels Hashfunktion eines BranchCache-fähigen Servers.
Hinweis
BranchCache ist ein Feature, das die WAN-Auslastung verringern und das Reaktionsverhalten von Netzwerkanwendungen verbessern kann, wenn Benutzer in Zweigstellen auf Inhalt in einer Zentrale zugreifen. Wenn Sie BranchCache aktivieren, wird eine Kopie des vom Webserver oder Dateiserver abgerufenen Inhalts in der Zweigstelle zwischengespeichert. Wenn ein anderer Client in der Zweigstelle denselben Inhalt anfordert, kann der Client ihn direkt aus dem lokalen Zweigstellennetzwerk herunterladen, anstatt den Inhalt erneut über das WAN aus der Zentrale abrufen zu müssen.
Failovercluster
Failovercluster unterstützen die Datendeduplizierung vollständig. Dies bedeutet, dass für deduplizierte Volumes zwischen den Knoten im Cluster ein geordnetes Failover durchgeführt wird. Dies erfordert jedoch, dass Sie das Datendeduplizierungsfeature auf allen Knoten im Cluster installieren, die an einem Failover beteiligt sind.
FSRM-Kontingente
Sie sollten auf einem für die Deduplizierung aktivierten Volumestammordner zwar keine harte Kontingentgrenze einrichten, können den Ressourcen-Manager für Dateiserver (FSRM) aber verwenden, um in einem solchen Szenario eine weiche Kontingentgrenze festzulegen. Wenn FSRM auf eine deduplizierte Datei stößt, identifiziert er die logische Größe der Datei für Kontingentberechnungen. Folglich wird die Kontingentnutzung (einschließlich aller Kontingentschwellenwerte) nicht geändert, wenn eine Datei durch die Deduplizierung verarbeitet wird. Alle anderen FSRM-Kontingentfunktionen, einschließlich weicher Volumestamm-Kontingentgrenzen und Kontingentgrenzen für Unterordner, funktionieren bei Verwendung der Deduplizierung wie erwartet.
Hinweis
FSRM ist eine Suite von Tools, die Ihnen helfen, die Typ und Menge der auf Ihren Servern gespeicherten Daten zu identifizieren, zu kontrollieren und zu verwalten. Mit FSRM können Sie harte oder weiche Kontingentgrenzen für Ordner und Volumes konfigurieren. Eine feste Kontingentgrenze verhindert, dass Benutzer Dateien speichern, nachdem die Kontingentgrenze erreicht wurde, während eine weiche Kontingentgrenze die Kontingentgrenze nicht erzwingt, sondern eine Benachrichtigung generiert, wenn die Daten auf dem Volume einen Schwellenwert erreichen.
DFS-Replikation
Die Datendeduplizierung ist mit der Replikation des verteilten Dateisystems (Distributed File System, DFS) kompatibel. Das Optimieren oder Deoptimieren einer Datei löst keine Replikation aus, da sich die Datei nicht ändert. DFS-Replikation verwendet Remotedifferenzialkomprimierung (nicht die Blöcke im Blockspeicher) für Einsparungen beim Datenversand über das Netzwerk.