Merkmale und Lebenszyklus von Incidents
- 4 Minuten
Wie Sie in der letzten Einheit gelernt haben, ist ein Vorfall eine Dienstunterbrechung, die sich auf Ihre Kunden und Endbenutzer auswirkt. Incidents gibt es in vielen Formen, von Leistungseinbußen, welche die Benutzenden frustrieren („langsam ist das neue down“), bis hin zu Systemabstürzen, die den Dienst oder die Website für eine gewisse Zeit komplett unzugänglich machen.
Merkmale eines Vorfalls
Vorfälle sind in der Regel unerwartet und scheinen zum ungünstigsten Zeitpunkt zu passieren, wie zum Beispiel um 2:00 Uhr nachts oder wenn Sie tief in ein wichtiges Projekt eingetaucht sind. Aus diesem Grund werden Vorfälle häufig gefürchtet und vermieden, auch an dem Punkt, an dem Die Menschen manchmal die Bedeutung eines Vorfalls herunterspielen. Der innere Druck ist in einer Organisation manchmal so groß, dass die Versuchung besteht, eine Störung falsch darzustellen oder nicht zu melden, aus Angst vor Repressalien.
Zumindest erstellen Vorfälle ungeplante Arbeit, und da Sie die meiste Zeit mit geplanter Arbeit verbringen, mit einer guten Vorstellung davon, was Sie tun sollen, denken Sie wahrscheinlich an Vorfälle als schlechte Dinge. Es gibt jedoch eine andere Möglichkeit, dies zu betrachten: Vorfälle sind wirklich Investitionen* bei der Bereitstellung des Werts, den Sie für Endbenutzer bereitstellen möchten. Unabhängig von der Ursache des Vorfalls oder des Umfangs der Auswirkungen haben alle Vorfälle eine gemeinsame Sache: Sie können wertvolle Lernerfahrungen bieten.
Sie sollten Vorfälle als Impuls Ihrer Systeme betrachten. Sie erzählen Ihnen mehr über das System, als Sie es zuvor verstanden haben, und dass Wissen eine gute Sache ist. Wenn Sie eine starke Grundlage für die Überwachung haben und mehr darüber wissen, was in Ihrem System passiert, wird es zwangsläufig mehr Warnungen und Vorfälle und Möglichkeiten zur Reaktion generieren. Zumindest sagen Ihnen Vorfälle, was gerade passiert, und erhöhen so Ihr betriebliches Bewusstsein. In einem früheren Modul zur Überwachung haben wir vorgeschlagen, dass dies ein wichtiger Vorläufer der Zuverlässigkeitsarbeit war.
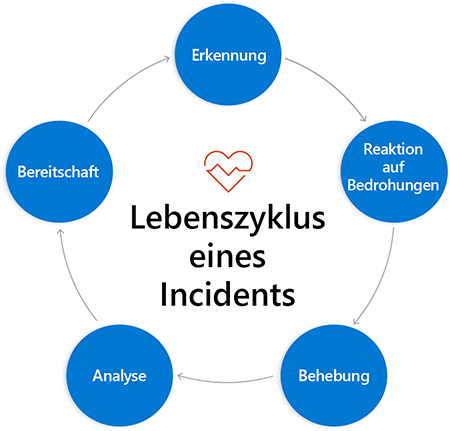
Lebenszyklus eines Vorfalls
Wenn Sie den Status Ihres Vorfallreaktionsteams auf "Elite/High Performer" erhöhen möchten, müssen Sie sich über die Idee einer Dienstunterbrechung oder eines Vorfalls als einfache lineare Zeitachse hinausschauen und sie aus zyklischer Sicht angehen.
Sie können den Lebenszyklus eines Vorfalls in unterschiedliche Phasen unterteilen, die logisch nacheinander in einem Zyklus folgen, der wieder zum Anfang zurückkehrt. Jedes Mal, wenn Sie diesen Zyklus umgehen (und sie werden dies mehrmals tun), wenn Sie ihn richtig behandeln, ist es möglich, mit einem größeren Einblick in Ihre Systeme zum Anfang zurückzukehren. Mit einer absichtlichen Arbeit können Sie auch besser darauf vorbereitet sein, schnell und effektiv zu reagieren, wenn ein Vorfall das nächste Mal auftritt.
Phasen eines Vorfalls
Die einzelnen Phasen des Vorfallreaktionsprozesses unterscheiden sich je nach verwendeten Modell etwas anders. Für dieses Modul gibt es fünf Phasen, die Sie beim Reagieren auf einen Vorfall durchlaufen:
- Erkennung: In dieser Phase kommt das Überwachungswissen aus einem vorherigen Modul in diesem Lernpfad ins Spiel. Ihre Überwachungstools sammeln die Informationen aus Protokollen, analysieren diese Informationen gemäß den von Ihnen konfigurierten kundenorientierten Zielen und senden Ihnen umsetzbare Warnungen, um Sie darüber zu informieren, dass menschliche Eingriffe erforderlich sind.
- Antwort: Diese Phase geschieht, nachdem Sie und Ihr Team diese Benachrichtigung erhalten haben. Wir werden in diesem Modul ausführlich in diese Phase eintauchen, sodass es in nur einem Moment noch viel mehr zu dieser Idee geben wird.
- Behebung: In dieser Phase stellen Sie die Systeme auf normale Funktionen zurück. Wie Sie dies tun, hängt von der Ursache der Dienstunterbrechung ab. Die Funktion und Verfügbarkeit des Diensts für Ihre Kunden wiederherzustellen, ist die oberste Priorität. Ihr Auftrag wird jedoch nicht beendet, sobald dies abgeschlossen ist.
- Analyse: Um einen dauerhaften Wert von Vorfällen zu erhalten, müssen Sie von ihnen lernen. Diese Phase ist der Prozess des Sammelns der Informationen darüber, was passiert ist und wann während des Vorfalls und sehen, was Sie daraus lernen können, indem Sie die richtigen Fragen stellen. Es gibt ein gesamtes Modul zum Lernen von Fehlern, das diese Phase behandelt.
- Bereitschaft: Sie sollten die in der Analysephase gelernten Erkenntnisse in Ihre Betriebspraxis integrieren. Wenn es Aktionselemente gibt, die dazu beitragen würden, in Zukunft einen ähnlichen Ausfall zu verhindern, wären sie auch Teil dieser Phase.
Bevor Sie einen Plan für die Reaktion auf Vorfälle erstellen, müssen Sie die Merkmale und den Wert von Vorfällen verstehen und mit den Phasen des Vorfalllebenszyklus vertraut sein. Der nächste Schritt besteht darin, sicherzustellen, dass Ihre Reaktionsstrategie auf einer soliden Grundlage basiert.