Convolutional Neural Networks
Hinweis
Weitere Details finden Sie auf der Registerkarte "Text und Bilder ".
Die Möglichkeit, Filter zum Anwenden von Effekten auf Bilder zu nutzen, ist nützlich bei Bildverarbeitungsaufgaben, wie man sie mit Bildbearbeitungssoftware machen könnte. Das Ziel der Computervision ist es jedoch oft, bedeutungs- oder zumindest umsetzbare Erkenntnisse aus Bildern zu extrahieren; dies erfordert die Erstellung von Machine Learning-Modellen, die geschult sind, um Features basierend auf großen Mengen vorhandener Bilder zu erkennen.
Tipp
In dieser Lektion wird davon ausgegangen, dass Sie mit den Grundlegenden Prinzipien des maschinellen Lernens vertraut sind und dass Sie über konzeptionelle Kenntnisse von Deep Learning mit neuralen Netzwerken verfügen. Wenn Sie noch keine Erfahrung mit maschinellem Lernen haben, sollten Sie die das Modul Einführung in das maschinelle Lernen in Microsoft Learn abschließen.
Eine der am häufigsten verwendeten Machine Learning-Modellarchitekturen für Computervisionen ist ein konvolutionales neurales Netzwerk (CNN), eine Art deep Learning-Architektur. CNNs verwenden Filter, um numerische Featurezuordnungen aus Bildern zu extrahieren und dann die Featurewerte in ein Deep Learning-Modell zu übertragen, um eine Bezeichnungsvorhersage zu generieren. In einem Bildklassifizierungsszenario stellt die Bezeichnung z. B. das Hauptthema des Bilds dar (was ist das also ein Bild von?). Sie können ein CNN-Modell mit Bildern verschiedener Arten von Obst (z. B. Apfel, Bananen und Orange) trainieren, damit das vorhergesagte Etikett die Art von Obst in einem bestimmten Bild ist.
Während des Schulungsvorgangs für einen CNN werden Filterkerne zunächst mithilfe von zufällig generierten Gewichtungswerten definiert. Wenn der Trainingsprozess voranschreitet, werden die Modellvorhersagen anhand bekannter Bezeichnungswerte ausgewertet, und die Filtergewichte werden angepasst, um die Genauigkeit zu verbessern. Schließlich verwendet das trainierte Fruchtbildklassifizierungsmodell die Filtergewichte, die am besten die Merkmale extrahieren, die bei der Identifizierung verschiedener Obstsorten helfen.
Das folgende Diagramm veranschaulicht, wie ein CNN für ein Bildklassifizierungsmodell funktioniert:
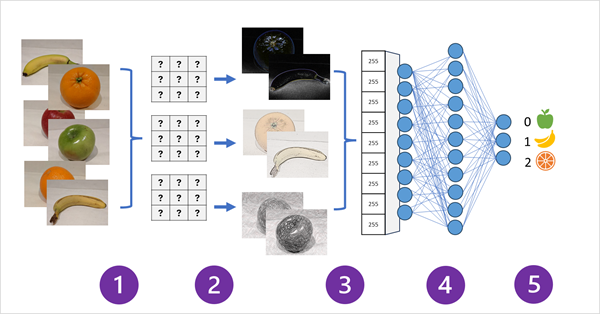
- Bilder mit bekannten Etiketten (z. B. 0: Apfel, 1: Bananen oder 2: Orange) werden in das Netzwerk eingespeist, um das Modell zu trainieren.
- Eine oder mehrere Ebenen von Filtern werden verwendet, um Merkmale aus jedem Bild zu extrahieren, während es durch das Netzwerk geleitet wird. Die Filterkerne beginnen mit zufällig zugewiesenen Gewichtungen und generieren Arrays numerischer Werte, die als Featurezuordnungen bezeichnet werden. Zusätzliche Ebenen können die Featurezuordnungen zusammenlegen oder verkleinern, um kleinere Arrays zu erstellen, die die von den Filtern extrahierten wichtigsten visuellen Optionen hervorheben.
- Die Merkmalszuordnungen werden in ein einzelnes dimensionales Array mit Merkmalswerten abgeflacht.
- Die Featurewerte werden in ein vollständig verbundenes neurales Netzwerk eingespeist.
- Die Ausgabeschicht des neuralen Netzwerks verwendet eine Softmax - oder ähnliche Funktion, um ein Ergebnis zu erzeugen, das einen Wahrscheinlichkeitswert für jede mögliche Klasse enthält, z. B. [0,2, 0,5, 0,3].
Während der Schulung werden die Ausgabewahrscheinlichkeiten mit der tatsächlichen Klassenbeschriftung verglichen , z. B. sollte ein Bild einer Banane (Klasse 1) den Wert [0,0, 1,0, 0,0] aufweisen. Der Unterschied zwischen den vorhergesagten und tatsächlichen Klassenergebnissen wird verwendet, um den Verlust im Modell zu berechnen, und die Gewichte im vollständig verbundenen neuralen Netzwerk und die Filterkerne in den Featureextraktionsschichten werden geändert, um den Verlust zu verringern.
Der Trainingsprozess wiederholt sich über mehrere Epochen , bis eine optimale Reihe von Gewichten gelernt wurde. Anschließend werden die Gewichtungen gespeichert, und das Modell kann verwendet werden, um Bezeichnungen für neue Bilder vorherzusagen, für die die Bezeichnung unbekannt ist.
Hinweis
CNN-Architekturen enthalten in der Regel mehrere konvolutionale Filterebenen und zusätzliche Ebenen, um die Größe von Featurezuordnungen zu verringern, die extrahierten Werte einzuschränken und andernfalls die Featurewerte zu bearbeiten. Diese Ebenen wurden in diesem vereinfachten Beispiel weggelassen, um sich auf das Schlüsselkonzept zu konzentrieren, d. h., dass Filter verwendet werden, um numerische Features aus Bildern zu extrahieren, die dann in einem neuralen Netzwerk verwendet werden, um Bildbeschriftungen vorherzusagen.