Übung: Auswählen des Machine-Learning-Algorithmus, um einen erfolgreichen Raketenstart vorherzusagen
Sie haben ausgewählt, welche Spalten verwendet werden sollen, um vorherzusagen, ob eine Rakete bei bestimmten Wetterbedingungen gestartet würde. Nun müssen Sie auswählen, welcher Algorithmus verwendet werden soll, um das Modell zu erstellen. Denken Sie an den Spickzettel für Azure Machine Learning-Algorithmen.
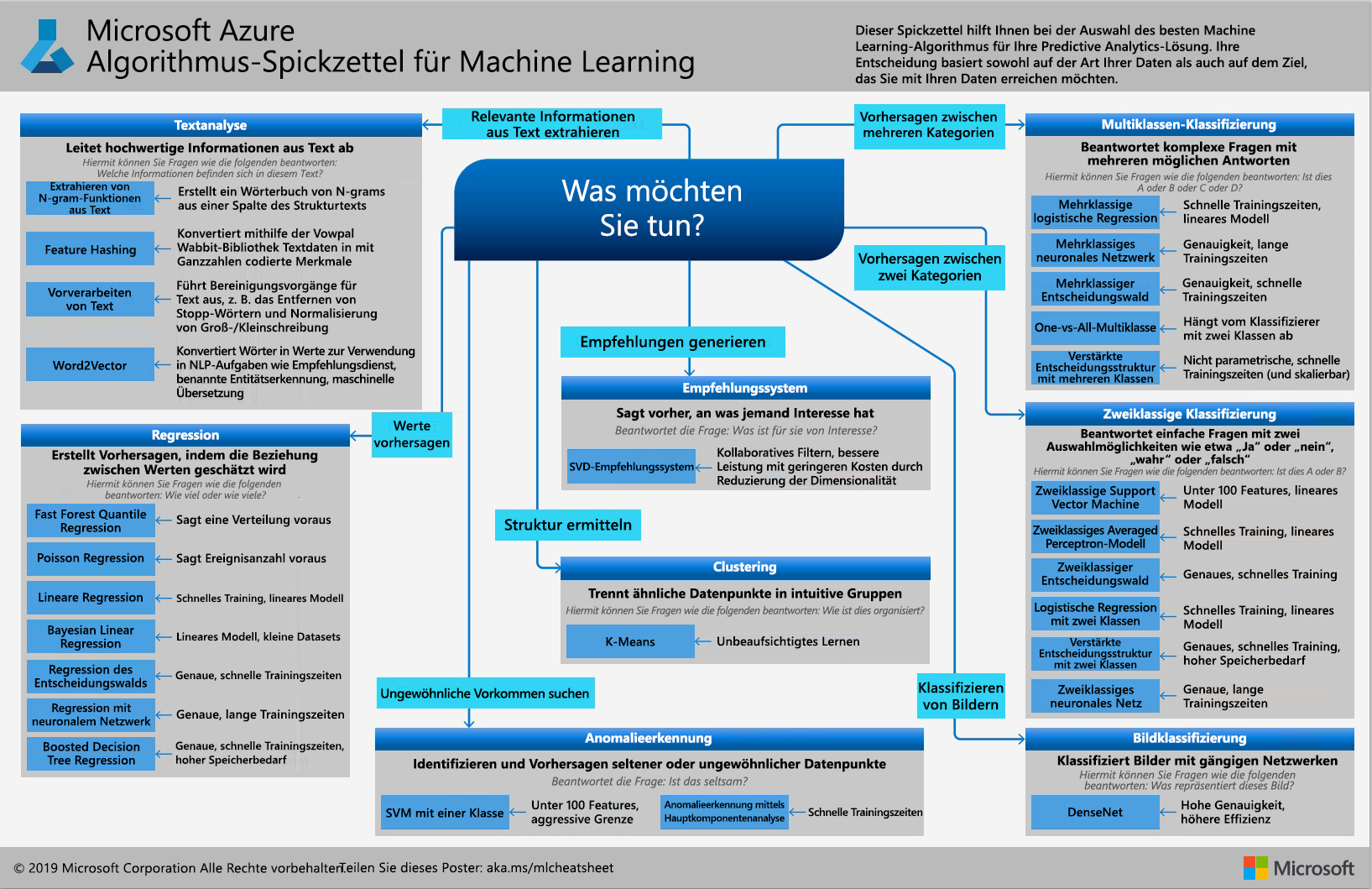
Denken Sie an Ihre Frage: Lässt sich vorhersagen, ob ein Start bei bestimmten Wetterbedingungen wahrscheinlich ist? Auf diese Frage gibt es zwei mögliche Antworten. Eine Rakete wird entweder gestartet oder nicht gestartet – „yes“ oder „no“. Diese Frage wird als Zweiklassen-Klassifizierungsproblem bezeichnet.
Innerhalb dieser Algorithmuskategorie gibt es viele spezifische Algorithmen, aus denen Sie auswählen können. In diesem Fall probieren wir eine Zweiklassen-Entscheidungsstruktur aus. Durch die Visualisierung der Ergebnisse einer Entscheidungsstruktur erhalten Sie Einblicke, anhand derer Sie künftig Daten sammeln, bereinigen und bearbeiten können.
Erstellen eines Machine Learning-Modells in Python
Wenn Sie scikit-learn verwenden, lässt sich das für diese Übung benötigte Machine Learning-Modell leicht erstellen. Fügen Sie diesen Code in Visual Studio Code in eine andere Zelle ein:
# Create decision tree classifier
tree_model = DecisionTreeClassifier(random_state=0,max_depth=5)
Sehen wir uns die Dokumentation für die Entscheidungsstrukturklassifizierung an. Es wird erläutert, wie wichtig die beiden hier angegebenen Parameter sind: random_state und max_depth.
Der Parameter random_state wird für die meisten Algorithmen für maschinelles Lernen verwendet. Er steuert die Zufälligkeit des Algorithmus. Wenn Sie diesen Schätzer verwenden, um die Daten in die zu trainierenden und die zu testenden Daten aufzuteilen, legt der hier angegebene Seed die Zufälligkeit dieser Aufteilung fest. Die nächste Lektion enthält weitere Informationen zur Datenaufteilung.
Parameter max_depth ist ein strukturspezifischer Parameter, mit dem Sie den Ausgabebereich des Modells festlegen können. In diesem Fall ist es nicht wirklich informativ, jede mögliche Wahrscheinlichkeit einer bestimmten Wetterlage zu kennen und zu wissen, wie sie sich auf die Wahrscheinlichkeit eines Raketenstarts auswirken könnte. Die Tiefe wird auf fünf begrenzt, um die gewonnenen Erkenntnisse auf das zu begrenzen, was für das Ergebnis am relevantesten ist.
Weitere Untersuchung
Wenn Sie möchten, können Sie versuchen, dieses Modul in diesem Zustand abzuschließen. Danach können Sie die Parameterwerte ändern, um zu sehen, welche neuen Erkenntnisse Sie möglicherweise finden.