Einführung in Azure Database for PostgreSQL
Azure Database for PostgreSQL ist als Version für mehrere Server verfügbar.
Als Datenbankentwickler mit langjähriger Erfahrung beim Ausführen und Verwalten lokaler PostgreSQL-Installationen möchten Sie herausfinden, wie Azure Database for PostgreSQL für Unterstützung und Skalierung der Features dieses Diensts sorgt.
In dieser Lerneinheit erhalten Sie Informationen zu Preisen, Versionsunterstützung, Replikation und zu den Skalierungsoptionen von Azure Database for MySQL.
Azure-Datenbank für PostgreSQL
Der Azure Database for PostgreSQL-Dienst ist eine Implementierung der Communityversion von PostgreSQL. Der Dienst bietet die üblichen Features, die von regulären PostgreSQL-Systemen genutzt werden, einschließlich Unterstützung für räumliche Features und Volltextsuche.
Microsoft hat PostgreSQL für die Azure-Plattform angepasst und für eine enge Verzahnung mit vielen Azure-Diensten gesorgt. Der Azure Database for PostgreSQL-Dienst wird vollständig von Microsoft verwaltet. Microsoft verarbeitet die Updates und Patches für die Software und bietet per SLA eine garantierte Verfügbarkeit von 99,99 Prozent. Das bedeutet, wenn Sie den Dienst verwenden, können Sie sich einfach nur auf die ausgeführten Datenbanken und Anwendungen konzentrieren.
Sie können mehrere Datenbanken in jeder Instanz dieses Diensts bereitstellen.
Tarife
Wenn Sie eine Instanz des Azure Database for PostgreSQL-Diensts erstellen, geben Sie die Compute- und Speicherressourcen an, die Sie zuordnen möchten, indem Sie eine Preisstufe auswählen. Ein Tarif kombiniert die Anzahl virtueller Prozessorkerne, die verfügbare Speichermenge und verschiedene Sicherungsoptionen. Je mehr Ressourcen Sie zuordnen, desto höher werden die Kosten.
Der Azure Database for PostgreSQL-Dienst nutzt Speicher, um Ihre Datenbankdateien, temporären Dateien, Transaktionsprotokolle und Serverprotokolle zu speichern. Sie können optional angeben, dass der verfügbare Speicher erhöht werden soll, wenn Sie sich der aktuellen Kapazität annähern. Wenn Sie diese Option nicht auswählen, werden Server, denen der Speicherplatz ausgeht, weiterhin ausgeführt, sie werden jedoch als schreibgeschützte Server ausgeführt.
Im Azure-Portal sind Tarife in drei Bereiche unterteilt:
- Einfach, das für kleine Systeme und Entwicklungsumgebungen geeignet ist, verfügt jedoch über eine variable E/A-Leistung.
- Allgemeiner Zweck, der vorhersehbare Leistung bietet, bis zu 6000 IOPS, abhängig von der Anzahl der Prozessorkerne und des verfügbaren Speicherplatzes.
- Speicheroptimiert, der bis zu 32 speicheroptimierte virtuelle Prozessorkerne verwendet und auch eine vorhersehbare Leistung von bis zu 6000 IOPS bietet.
Microsoft verfügt auch über eine Option für großen Speicher in der Vorschau, die bis zu 16 TB Speicherplatz bereitstellen und bis zu 20.000 IOPS unterstützen kann.
Sie können die Anzahl Prozessorkerne und den Speicher, den Sie benötigten, genau abstimmen. Sie können Verarbeitungsressourcen hoch- und herunterskalieren, Speicher lässt sich nicht herunterskalieren, nur hochskalieren, und Sie können bei Bedarf zwischen den Tarifen „Universell“ und „Arbeitsspeicheroptimiert“ wechseln, nachdem Sie Ihre Datenbanken erstellt haben. Sie bezahlen nur für das, was Sie tatsächlich nutzen.

Hinweis
Wenn Sie die Anzahl Prozessorkerne ändern, erstellt Azure einen neuen Server mit dieser Computezuordnung. Wenn der Server ausgeführt wird, werden Clientverbindungen auf den neuen Server verlegt. Dieser Wechsel kann bis zu eine Minute dauern. Während dieses Zeitraums können keine neuen Verbindungen hergestellt werden, und für sämtliche ausgeführte Transaktionen wird ein Rollback ausgeführt.
Wenn Sie nur die Speichergröße der Sicherungsoptionen ändern, tritt für Ihre Dienste keine Unterbrechung auf.
Der Tarif und die zugeordneten Verarbeitungsressourcen bestimmen die maximale Anzahl gleichzeitiger Verbindungen, die der Dienst unterstützt. Wenn Sie beispielsweise den Tarif „Universell“ auswählen und 64 virtuelle Kerne zuordnen, unterstützt der Dienst 1.900 gleichzeitige Verbindungen. Der Tarif „Basic“ mit zwei virtuellen Kernen verarbeitet bis zu 100 gleichzeitige Verbindungen. Azure selbst benötigt fünf dieser Verbindungen, um den Server zu überwachen. Wenn Sie die Anzahl der verfügbaren Verbindungen überschreiten, erhalten Clients den Fehler FATAL: Leider sind bereits zu viele Clients vorhanden.
Die Preise variieren. Besuchen Sie die Azure-Datenbank für PostgreSQL-Preisseite , um die neuesten Informationen zu finden.
Serverparameter
In einer lokalen Installation von PostgreSQL legen Sie Serverkonfigurationsparameter in der Datei postgresql.conf fest. Verwenden Sie Azure Database for PostgreSQL, um Konfigurationsparameter über die Seite "Serverparameter " zu ändern. Nicht alle Parameter für eine lokale Installation von PostgreSQL spielen eine Rolle für Azure Database for PostgreSQL, die Seite „Serverparameter“ führt also nur die Parameter auf, die für Azure relevant sind.

Änderungen an parametern, die als "Dynamisch" gekennzeichnet sind, werden sofort wirksam. Für statische Parameter ist ein Serverneustart erforderlich. Sie starten den Server über die Schaltfläche " Neu starten" auf der Seite "Übersicht" im Portal neu:

Hohe Verfügbarkeit
Azure Database for PostgreSQL ist ein Hochverfügbarkeitsdienst. Er enthält integrierte Fehlererkennung und Failovermechanismen. Wenn bei einem Verarbeitungsknoten aufgrund eines Hardware- oder Softwarefehlers eine Verzögerung auftritt, wird ein neuer Knoten eingewechselt, der den Knoten ersetzt. Alle Verbindungen, die diesen Knoten aktuell verwenden, werden getrennt, jedoch automatisch für den neuen Knoten geöffnet. Für alle von dem Knoten, für den ein Fehler aufgetreten ist, durchgeführten Transaktionen, wird ein Rollback ausgeführt. Aus diesem Grund sollten Sie immer sicherstellen, dass Clients so konfiguriert sind, dass Vorgänge, für die ein Fehler auftritt, ermittelt und wiederholt werden.
Unterstützte PostgreSQL-Versionen
Der Azure Database for PostgreSQL-Dienst unterstützt aktuell die Version 11 von PostgreSQL sowie davon ausgehend alle Versionen abwärts bis 9.5. Sie geben an, welche PostgreSQL-Version verwendet werden soll, wenn Sie eine Instanz des Diensts erstellen. Microsoft möchte den Dienst aktualisieren, wenn neue PostgreSQL-Versionen verfügbar werden. Außerdem wird Microsoft für Kompatibilität mit den vorherigen beiden Hauptversionen sorgen.
Azure verwaltet Upgrades für Ihre Datenbanken bei Nebenversionen von PostgreSQL automatisch, nicht jedoch für Hauptversionen. Wenn Sie beispielsweise über eine Datenbank verfügen, die die PostgreSQL-Version 10 verwendet, kann Azure automatisch ein Upgrade für die Datenbank auf Version 10.1 ausführen. Wenn Sie zu Version 11 wechseln möchten, müssen Sie Ihre Daten aus den Datenbanken in der aktuellen Dienstinstanz exportieren, eine neue Instanz des Azure Database for PostgreSQL-Diensts erstellen und Ihre Daten in diese neue Instanz importieren.
Koordinator- und Workerknoten
Daten werden für verschiedene Workerknoten freigegeben und auf ihnen verteilt. Die Abfrage-Engine im Koordinator kann komplexe Abfragen parallelisieren, die Verarbeitung wird dabei zu den geeigneten Workerknoten weitergeleitet. Workerknoten werden entsprechend der Shards ausgewählt, die die Daten enthalten, die verarbeitet werden sollen. Der Koordinator fasst die Ergebnisse der Workerknoten dann zusammen, bevor sie zurück an den Client gesendet werden. Einfachere Abfragen können mithilfe eines einzigen Workerknotens ausgeführt werden. Clients stellen auch eine Verbindung zum Koordinator her und kommunizieren niemals direkt mit einem Workerknoten.
Sie können die Anzahl Workerknoten in Ihrem Dienst je nach Bedarf herunterskalieren und hochskalieren.
Verteilen von Daten
Sie verteilen Daten über Arbeitsknoten, indem Sie verteilte Tabellen erstellen. Eine verteilte Tabelle wird in Shards unterteilt. Jeder Shard wird dann Speicher auf einem Workerknoten zugeordnet. Sie geben an, wie die Daten geteilt werden sollen, indem Sie eine Spalte als Verteilungsspalte definieren. Die Daten werden basierend auf den Werten der Daten in dieser Spalte partitioniert. Wenn Sie eine verteilte Tabelle entwerfen, ist es wichtig, die Verteilungsspalte sorgfältig auszuwählen. Sie sollten eine Spalte mit einer großen Anzahl eindeutiger Werte verwenden, die in der Regel dafür verwendet werden würden, zusammengehörige Datensätze miteinander zu gruppieren. In einer Tabelle für ein E-Commerce-System, in der Informationen zu Kundenaufträgen gespeichert sind, wäre die Kunden-ID beispielsweise eine sinnvolle Verteilungsspalte. Alle Bestellungen für einen bestimmten Kunden sind im selben Shard gespeichert, Bestellungen für alle Kunden sind jedoch über die einzelnen Shards verteilt.
Sie können auch Referenztabellen erstellen. Diese Tabellen enthalten Lookupdaten, z. B. Städtenamen oder Statuscodes. Eine Verweistabelle wird als Ganzes auf jeden einzelnen Workerknoten repliziert. Die Daten in einer Verweistabelle sollten relativ statisch sein, für jede Änderung muss jede Kopie der Tabelle aktualisiert werden.
Schließlich können Sie lokale Tabellen erstellen. Eine lokale Tabelle wird nicht partitioniert, wird jedoch auf dem Koordinatorknoten gespeichert. Verwenden Sie lokale Tabellen, um kleine Tabellen mit Daten zu speichern, für die sehr wahrscheinlich keine Joins erforderlich sind. Beispiele hierfür sind Benutzernamen und deren Anmeldeinformationen.
Replizieren von Daten in Azure Database for PostgreSQL
Schreibgeschützte Replikate sind hilfreich, um Workloads zu verarbeiten, für die viele Lesevorgänge erforderlich sind. Clientverbindungen können für verschiedene Replikate hergestellt werden, was die Auslastung einzelner Instanzen des Diensts abschwächt. Wenn sich Ihre Clients in verschiedenen Regionen der Welt befinden, verwenden Sie die regionsübergreifende Replikation, um Daten näher bei den jeweils zusammengehörigen Clients zu speichern und die Latenz zu senken.
Sie können Replikate auch als Teil eines Notfallplans für die Notfallwiederherstellung verwenden. Wenn der Masterserver nicht mehr verfügbar ist, können Sie möglicherweise dennoch eine Verbindung zu einem Replikat herstellen.
Hinweis
Wenn der Masterserver verloren geht oder gelöscht wird, werden alle schreibgeschützten Replikate stattdessen zu Servern mit Lese-/Schreibzugriff. Diese Server sind dann jedoch unabhängig voneinander. Alle Änderungen, die an den Daten auf einem Server vorgenommen werden, werden also nicht auf die restlichen Server kopiert.
Herstellen eines Replikats
Ein schreibgeschütztes Replikat enthält eine Kopie der Datenbanken, die auf dem Originalserver gespeichert sind. Dieser wird als Masterserver bezeichnet. Sie verwenden das Azure-Portal oder die CLI, um ein Replikat eines Masterservers zu erstellen.

Wenn Sie ein schreibgeschütztes Replikat erstellen, erstellt Azure eine neue Instanz des Azure Database for PostgreSQL-Diensts, und die Datenbanken vom Masterserver werden dann auf den neuen Server kopiert. Das Replikat wird im schreibgeschützten Modus ausgeführt. Für jeden Versuch, die Daten zu ändern, tritt ein Fehler auf.
Replikatverzögerung
Die Replikation erfolgt nicht synchron, und alle an den Daten auf dem Masterserver vorgenommenen Änderungen werden möglicherweise erst nach einer gewissen Zeit für die Replikate angezeigt. Clientanwendungen, die eine Verbindung zu Replikaten herstellen, müssen mit dieser Ebene der letztlichen Konsistenz umgehen können. Mit Azure Monitor können Sie die Zeitverzögerung der Replikation mithilfe der Metriken "Max Lag Across Replicas " und "Replica Lag Lag " nachverfolgen.
Verwaltung und Überwachung
Sie können vertraute Tools wie pgAdmin verwenden, um eine Verbindung mit Azure Database for PostgreSQL herzustellen, um Ihre Datenbanken zu verwalten und zu überwachen. Einige serverorientierte Funktionen, beispielsweise die Durchführung von Serversicherungen und -wiederherstellungen, sind jedoch nicht verfügbar, da der Server von Microsoft verwaltet und gewartet wird.

Azure-Tools für die Überwachung von Azure Database for PostgreSQL
Azure bietet eine umfangreiche Auswahl von Diensten, mit denen Sie die Server- und Datenbankleistung überwachen und Fehler beheben können. Diese Dienste ermöglichen es Ihnen, sich anzusehen, wie PostgreSQL die von Ihnen zugewiesenen Azure-Ressourcen nutzt. Mithilfe dieser Informationen können Sie bewerten, ob Sie Ihr System skalieren müssen, Sie können die Struktur der Tabellen und Indizes in Ihren Datenbanken ändern, und Sie können Runtimestatistiken und andere Ereignisse visualisieren. Zu den verfügbaren Diensten gehören die folgenden:
Azure Monitor. Für Azure Database for PostgreSQL stehen Metriken zur Verfügung, mit denen Sie Elemente wie die CPU-Auslastung und die Speicherauslastung sowie E/A-Raten, die Arbeitsspeicherauslastung, die Anzahl aktiver Verbindungen und die Verzögerung bei der Replikation nachverfolgen können:
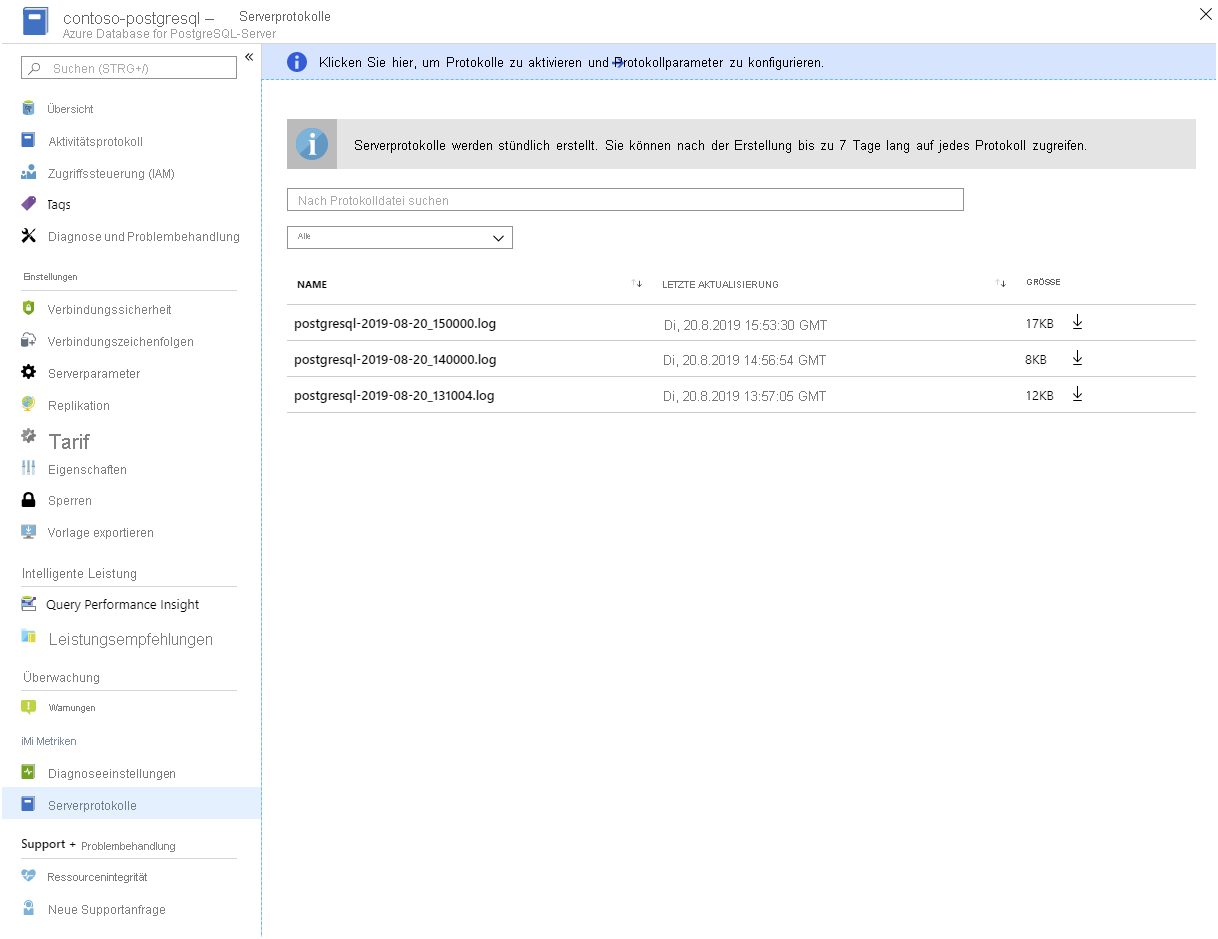
Serverprotokolle. Azure stellt die Protokolle für jeden PostgreSQL-Server für Sie zur Verfügung. Sie können sie über das Azure-Portal herunterladen.
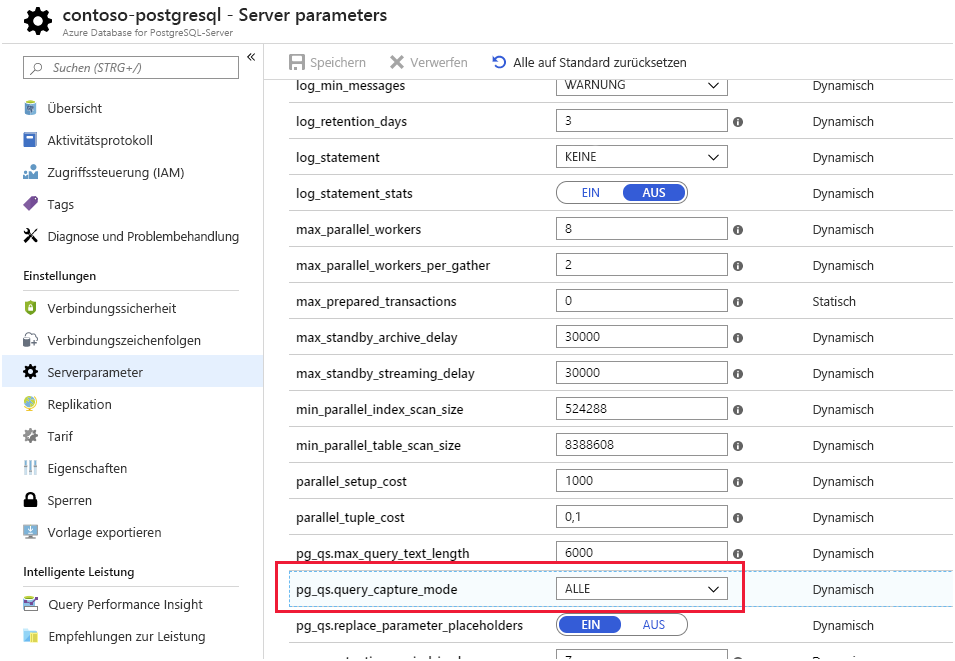
Abfragespeicher und Abfrageleistungserkenntnisse. Die Azure-Datenbank für PostgreSQL speichert Informationen zu den Abfragen, die für Datenbanken auf dem Server ausgeführt werden, und speichert sie in einer Datenbank namens azure_sys im query_store-Schema . Wenn Sie diese Informationen anzeigen möchten, fragen Sie die Ansicht query_store.qs_view ab. Standardmäßig erfasst Azure Database for PostgreSQL keine Abfrageinformationen, da sie einen geringen Aufwand aufzwingt, aber Sie können die Nachverfolgung aktivieren, indem Sie die Servereigenschaft pg_qs.query_capture_mode auf ALL oder TOP festlegen.
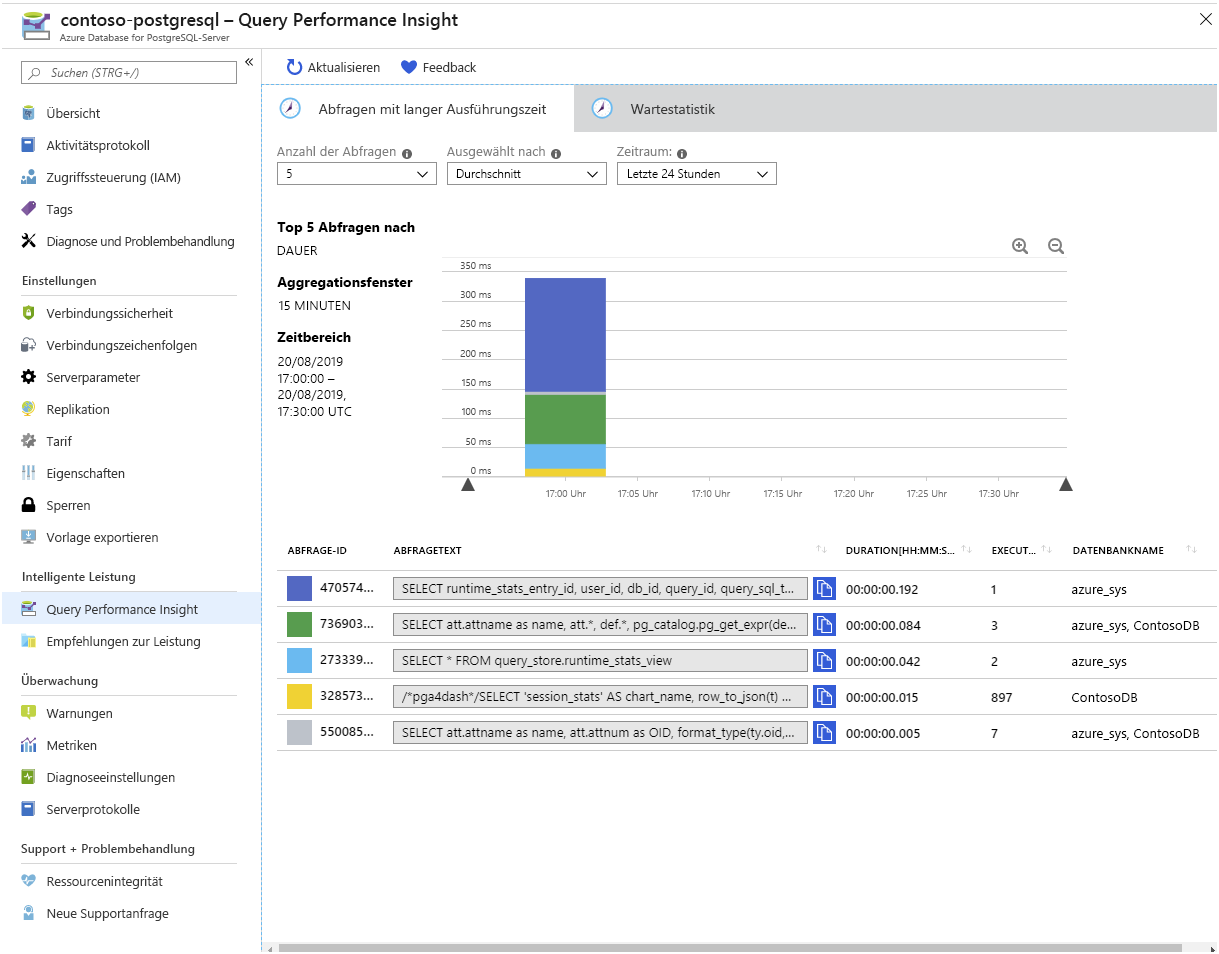
Sie konfigurieren außerdem den Abfragespeicher, sodass Informationen zu Abfragen erfasst werden, für die eine Wartezeit auftritt. Für eine Abfrage kann eine Wartezeit auftreten, wenn eine andere Abfrage eine Sperre für eine Tabelle freigibt, wenn die Abfrage viele E/A-Vorgänge verarbeiten muss oder wenn der Arbeitsspeicher knapp wird. Diese Informationen werden in der Ansicht query_store.runtime_stats_view angezeigt.
Wenn Sie diese Statistiken lieber visualisieren möchten, anstatt SQL-Anweisungen auszuführen, können Sie im Azure-Portal Query Performance Insight verwenden:
Leistungsempfehlungen. Das Hilfsprogramm für Leistungsempfehlungen ist ebenfalls im Azure-Portal verfügbar und untersucht die Abfragen, die von Ihren Anwendungen ausgeführt werden. Außerdem werden die Strukturen in der Datenbank untersucht, und es wird empfohlen, wie Ihre Daten organisiert werden, und ob Sie erwägen sollten, Indizes hinzuzufügen oder zu entfernen.




Client-Konnektivität
Azure Database for PostgreSQL wird hinter einer Firewall ausgeführt. Damit Sie auf Ihren Dienst und Ihre Datenbank zugreifen können, müssen Sie eine Firewallregel für den IP-Adressbereich hinzufügen, in dem Ihre Clients Verbindungen herstellen. Wenn Sie in Azure auf den Dienst zugreifen möchten, z. B. in Form einer Anwendung, die mithilfe von Azure App Service ausgeführt wird, müssen Sie auch den Zugriff auf Azure-Dienste ermöglichen.
Konfigurieren der Firewall
Die einfachste Möglichkeit, die Firewall zu konfigurieren, ist die Verwendung der Verbindungssicherheitseinstellungen für Ihren Dienst im Azure-Portal. Fügen Sie pro Client-IP-Adressbereich eine Regel hinzu. Über diese Seite können Sie außerdem SSL-Verbindungen für Ihren Dienst erzwingen.

Sie klicken auf der Symbolleiste auf " Client-IP hinzufügen ", um die IP-Adresse Ihres Desktopcomputers hinzuzufügen.
Wenn Sie schreibgeschützte Replikate konfiguriert haben, müssen Sie jedem Replikat eine Firewallregel hinzufügen, damit Clients darauf zugreifen können.
Bibliotheken für Clientverbindungen
Wenn Sie Ihre eigenen Clientanwendungen schreiben, müssen Sie die entsprechenden Datenbanktreiber verwenden, um eine Verbindung zu einer PostgreSQL-Datenbank herstellen zu können. Viele dieser Bibliotheken weisen Abhängigkeiten von einer Programmiersprache auf. Sie werden von unabhängigen Drittanbietern verwaltet. Azure Database for PostgreSQL unterstützt Clientbibliotheken für Python, PHP, Node.js, Java, Ruby, Go, C# (.NET), ODBC, C und C++.
Wiederholungslogik für Clients
Wie bereits erwähnt wurde, können einige Ereignisse, z. B. Failover, während der Wiederherstellung von Hochverfügbarkeit sowie während des Hochskalierens von CPU-Ressourcen zu einem kurzen Verbindungsverlust führen. Für alle Transaktionen, die gerade ausgeführt werden, wird ein Rollback ausgeführt. Azure Database for PostgreSQL leitet einen verbundenen Client automatisch an einen Workerknoten weiter, für alle zu diesem Zeitpunkt vom Client durchgeführten Vorgänge tritt jedoch ein Fehler auf. Sie sollten dieses Verhalten als vorübergehende Ausnahme behandeln. Ihr Anwendungscode sollte so vorbereitet werden, dass diese Ausnahmen erfasst und die Ausführung noch mal versucht wird.
In Azure Database for PostgreSQL unterstützte PostgreSQL-Features
Azure Database for PostgreSQL unterstützt die meisten Features, die üblicherweise von PostgreSQL-Datenbanken verwendet werden, es bestehen jedoch einige Ausnahmen. Wenn Sie ein nicht unterstütztes Feature benötigen, müssen Sie Ihre Datenbank und Ihren Anwendungscode entweder so umgestalten, dass diese Abhängigkeit entfernt wird, oder Sie erwägen, PostgreSQL auf einer VM auszuführen. Im letzteren Fall sind Sie für das Verwalten und Warten des Servers verantwortlich.
Unterstützte Erweiterungen in Azure Database for PostgreSQL
Die meisten PostgreSQL-Funktionen sind in Erweiterungen gekapselt. Bei Erweiterungen handelt es sich um Pakete von SQL-Objekten, die auf dem Server gespeichert werden. Sie können mithilfe des CREATE EXTENSION-Befehls in eine Datenbank geladen werden. Azure Database for PostgreSQL bietet aktuell viele häufig verwendete Erweiterungen für Folgendes:
- Datentypen
- Funktionen
- Volltextsuche
- Indizes (bloom, btree_gist und btree_gin)
- Die plpgsql-Sprache
- PostGIS
- Viele Verwaltungsfunktionen
Sie verwenden die Dblink - und postgres_fdw-Pakete , um einen PostgreSQL-Server mit einem anderen zu verbinden. Dies ermöglicht code in einem Server den Zugriff auf in einem anderen Gespeicherte Daten. In Azure Database for PostgreSQL können Sie nur Verbindungen zwischen Servern herstellen, die mithilfe von Azure Database for PostgreSQL erstellt wurden. Sie können keine ausgehenden Verbindungen zu PostgreSQL-Servern herstellen, die an anderer Stelle gehostet werden, z. B. lokal oder auf einer VM.
Hinweis
Die Liste unterstützter Erweiterungen wird aktuell überprüft und kann sich ändern. Mit der folgenden Abfrage erstellen Sie eine Liste der unterstützten Erweiterungen. Beachten Sie, dass Sie keine eigenen benutzerdefinierten Erweiterungen erstellen und sie in Azure Database for PostgreSQL hochladen können:
SELECT * FROM pg_available_extensions;
Azure Database for PostgreSQL enthält die TimescaleDB-Datenbank als optionale Erweiterung. Diese Datenbank enthält zeitorientierte Analysefunktionen und weitere Features, die Zeitreihenworkloads unterstützen. Um diese Datenbank zu verwenden, wählen Sie die OPTION TIMESCALEDB im shared_preload_libraries Serverparameter aus, und starten Sie den Server dann neu.
Sprachunterstützung für gespeicherte Prozeduren und Trigger
Wenn Sie Unterstützung für Sprachen außer plpgsql benötigen, müssen Sie in der Regel Ihre gespeicherte Prozedur kompilieren oder Code separat triggern und die kompilierte Bibliothek auf den Server hochladen. Hauptsächlich aufgrund von Sicherheitsfaktoren ist dies für Azure Database for PostgreSQL nicht möglich. Wenn Ihr Code in anderen Programmiersprachen geschrieben ist, müssen Sie ihn zu plpgsql übertragen.