Erkunden der wichtigsten Konzepte eines RAG-Workflows
Das Abrufen von Augmented Generation (RAG) ist eine Technik, die große Sprachmodelle effektiver macht, indem sie mit Ihren eigenen benutzerdefinierten Daten verbunden werden. Der RAG-Workflow folgt einem einfachen vierstufigen Prozess, wie im Diagramm dargestellt:
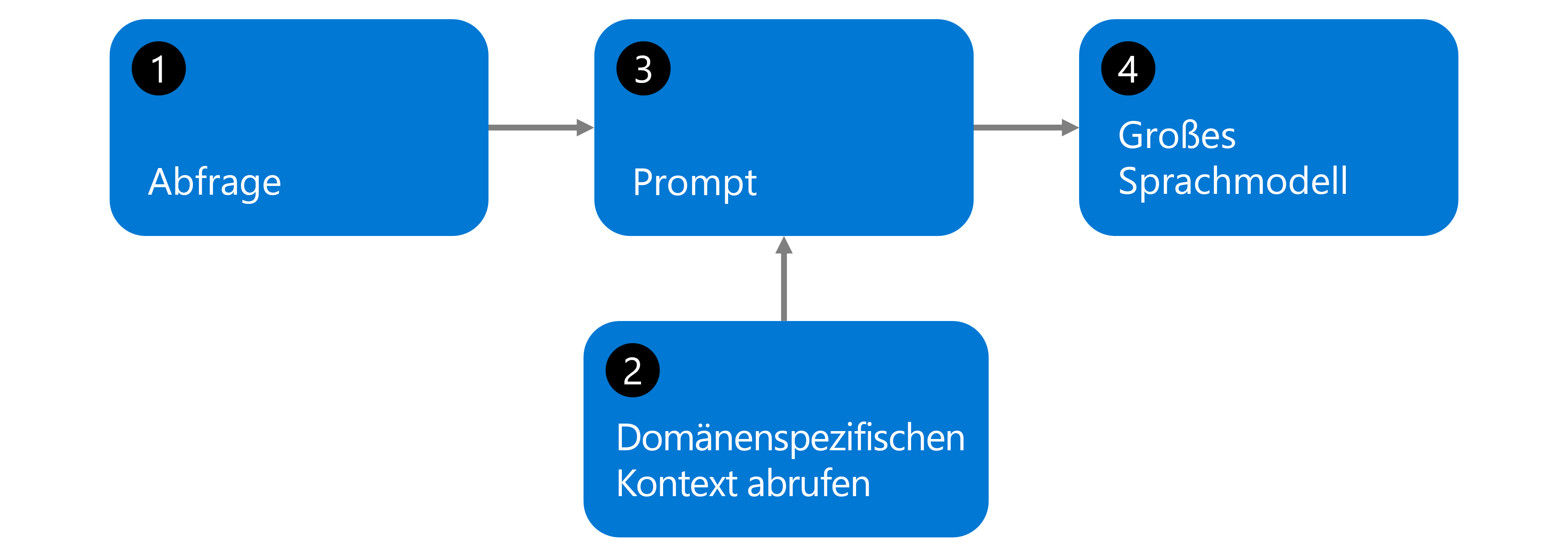 Diagramm: Retrieval Augmented Generation-Workflow
Diagramm: Retrieval Augmented Generation-Workflow
Benutzerabfrage: Ein Benutzer stellt eine Frage, die die Basis-LLM allein nicht genau beantworten kann, da er keinen Zugriff auf Ihre spezifischen Dokumente, aktuellen Informationen oder proprietären Daten hat.
Durchsuchen Sie Ihre Datenbank: Das System durchsucht Ihre eigene Dokumentsammlung (Unternehmensrichtlinien, Berichte, Handbücher, Datenbanken) - nicht die Schulungsdaten des LLM. Ihre Dokumente wurden zuvor in Einbettungen konvertiert und in einer Vektordatenbank gespeichert. Das System findet die relevantesten Informationen aus Ihren spezifischen Dokumenten.
Kontext zur Eingabeaufforderung hinzufügen: Die relevanten Informationen, die aus Ihren Dokumenten abgerufen wurden, werden mit der ursprünglichen Frage des Benutzers kombiniert, um eine erweiterte Eingabeaufforderung zu erstellen, die dem LLM den spezifischen Kontext bereitstellt, den er benötigt.
LLM generiert Antwort: Das Basissprachenmodell verarbeitet sowohl die ursprüngliche Frage als auch den abgerufenen Kontext aus Ihren Dokumenten, um eine genaue, geerdete Antwort basierend auf Ihren spezifischen Daten zu generieren.
Dieser Prozess überbrückt die Lücke zwischen einem allgemeinen LLM und Ihren spezifischen, privaten oder aktuellen Informationen, sodass Sie genaue Antworten basierend auf Ihren eigenen Dokumenten erhalten können, ohne das gesamte Basismodell neu trainieren zu müssen.
Sehen wir uns an, wann Sie RAG verwenden können, und überprüfen Sie dann die Hauptkomponenten und Konzepte in einem RAG-Workflow.
Grundlegendes zur Verwendung von RAG
Sie können RAG für Chatbots, Suchverbesserungen und Inhaltserstellung und Zusammenfassung verwenden.
Chatbots: RAG hilft Chatbots dabei, genauere Antworten zu liefern, indem sie auf aktuelle Informationen zugreifen. Wenn sie in Kundensupportsysteme integriert sind, können RAG-gestützte Chatbots den Support automatisieren und Kundenfragen mithilfe von up-to-Date-Daten schnell lösen.
Suchverbesserung: Anstatt nur Links und Ausschnitte zurückzugeben, bieten RAG-gestützte Suchmaschinen vollständige, gesprächsartige Antworten. Benutzer erhalten umfassende Antworten, die Informationen aus mehreren Quellen zusammenfassen und es ihnen erleichtern, das zu finden, was sie benötigen.
Erstellung und Zusammenfassung von Inhalten: Erstellen Sie qualitativ hochwertige, faktenbasierte Inhalte mithilfe Ihrer eigenen Datenquellen. RAG ermöglicht es Ihnen, fundierte Artikel zu erstellen, Zusammenfassungen aus langwierigen Dokumenten zu erstellen und Berichte zu entwickeln, die Informationen aus mehreren Quellen synthetisieren.
Erkunden der wichtigsten Konzepte in einem RAG-Workflow
Der RAG-Workflow basiert auf vier wesentlichen Komponenten, die zusammenarbeiten:
- Einbettungen – Konvertieren von Text in mathematische Vektoren, die Bedeutung erfassen
- Vektordatenbanken – Speichern und Organisieren dieser Vektoren für schnelle Suche
- Suchen und Abrufen – Suchen der relevantesten Informationen basierend auf Benutzerabfragen
- Prompt-Erweiterung – Kombinieren von abgerufenen Informationen mit der ursprünglichen Frage
Stellen Sie sich diese Komponenten als Bausteine vor: Einbettungen übersetzen alles in eine gemeinsame Sprache, Vektordatenbanken organisieren diese Informationen, suchen und abrufen, was erforderlich ist, und die Prompterweiterung fügt alles zusammen, damit die KI verwendet werden kann.
Konvertieren Ihrer Dokumente und Abfragen mit Einbettungen
Bevor ein RAG-System relevante Informationen finden kann, muss der gesamte Text aus Ihren Dokumenten und Benutzerabfragen in ein Format konvertiert werden, das einen semantischen Vergleich ermöglicht. Hier spielen Einbettungen eine Rolle.
Ein Einbettungsmodell ist ein spezielles KI-Tool, mit dem Text in numerische Vektoren (Zahlenlisten) konvertiert wird, die die Bedeutung des Texts darstellen. Denken Sie daran als Übersetzer, der Werke und Sätze in eine mathematische Sprache verwandelt, die Computer verstehen und vergleichen können.
Die Dokumenteinbettung, wie im Diagramm dargestellt, ist Teil einer Vorbereitungsphase. Dies erfolgt einmal, um eine Wissensbasis einzurichten. Bevor Ihr RAG-System funktionieren kann, müssen Sie Ihre Dokumente vorbereiten. Ein Einbettungsmodell verwendet alle Ihre Textdokumente und wandelt sie in mathematische Vektoren um, die als Einbettungen bezeichnet werden, die ihre semantische Bedeutung erfassen. Dieser Vorverarbeitungsschritt erstellt eine durchsuchbare Wissensbasis.
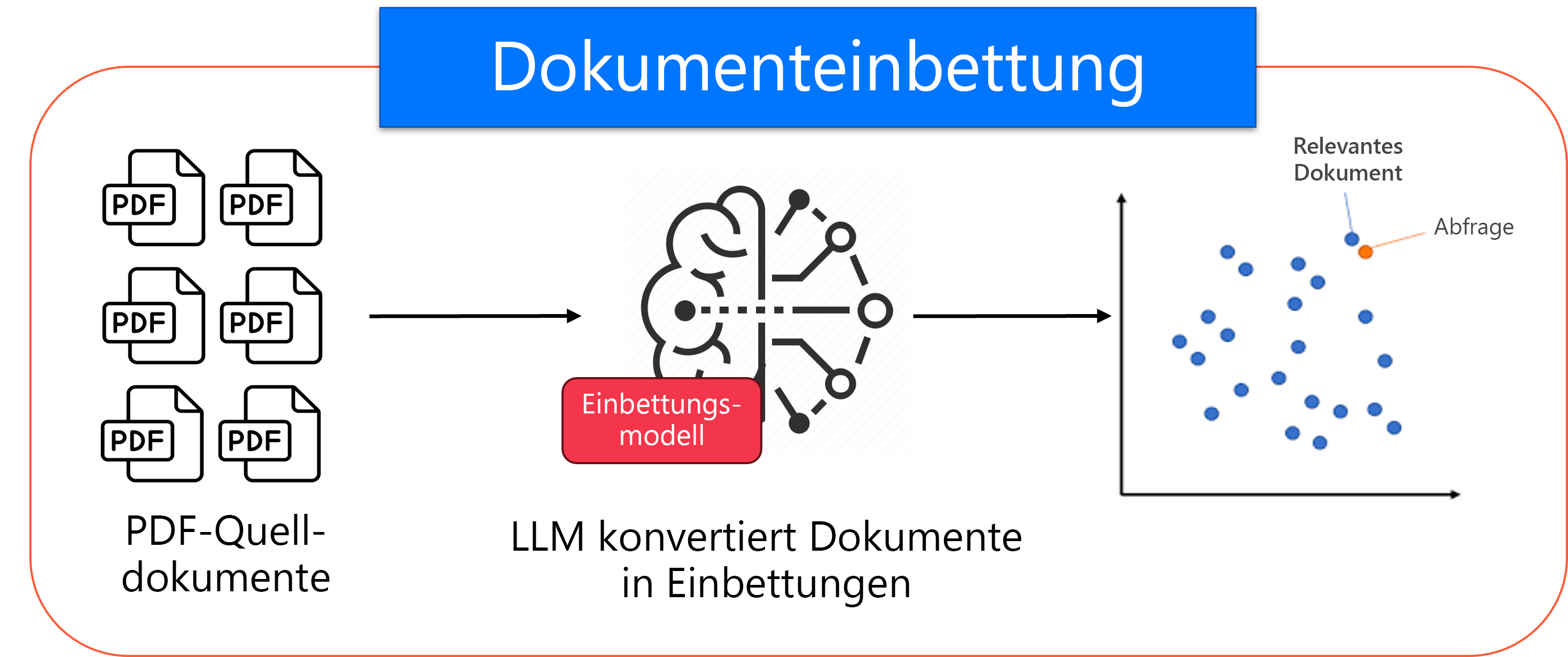 Diagramm: Einbettungsmodell, das Dokumente in Vektoren konvertiert
Diagramm: Einbettungsmodell, das Dokumente in Vektoren konvertiert
Abfrageeinbettung, die im Diagramm angezeigt wird, erfolgt jedes Mal, wenn ein Benutzer eine Frage stellt. Zunächst wird die Frage des Benutzers in eine Einbettung mit demselben Einbettungsmodell konvertiert, das zum Verarbeiten der Dokumente verwendet wurde. Diese Echtzeitkonvertierung bereitet die Abfrage auf den Vergleich mit den vorverarbeiteten Dokumenteinbettungen vor. Erst nachdem die Abfrage eingebettet wurde, kann das System mit der Suche nach relevanten Dokumenten beginnen.
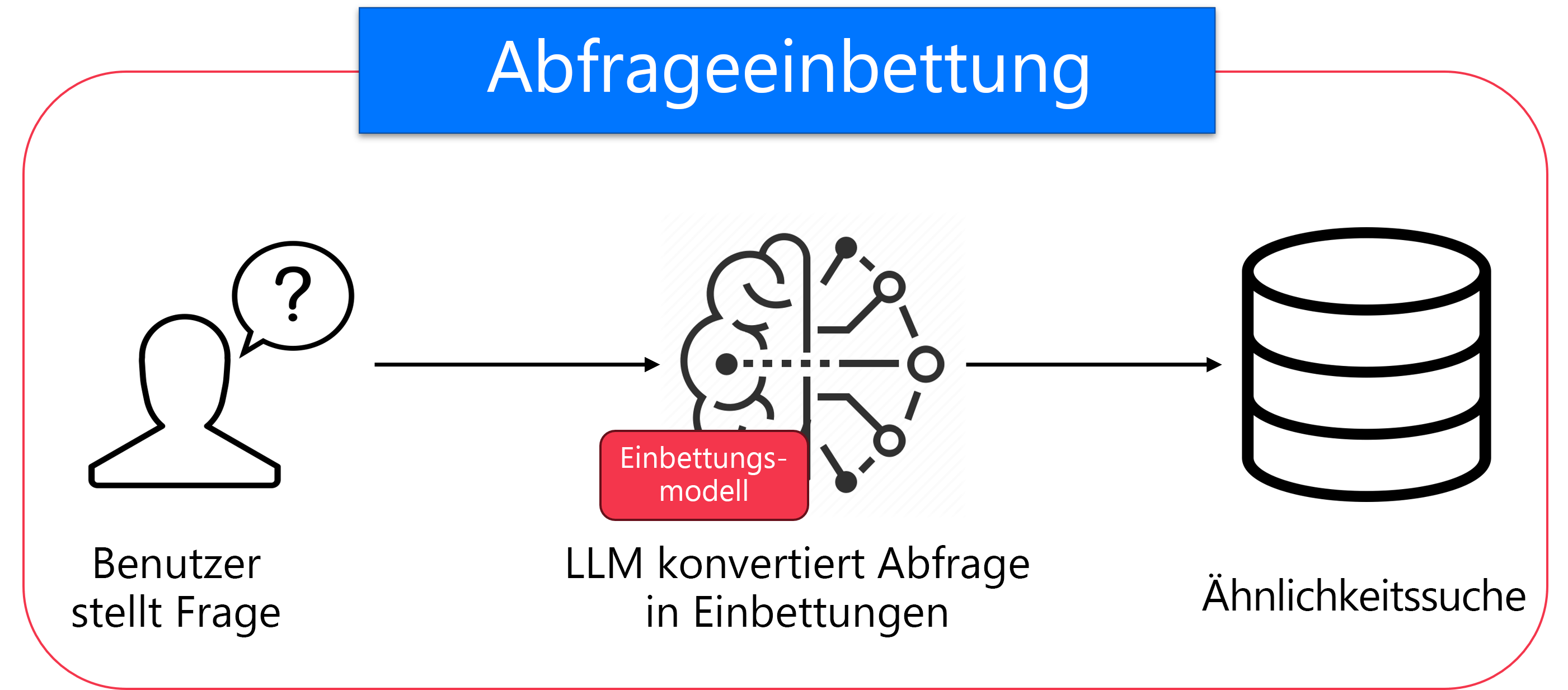 Diagramm: Einbettungsmodell
Diagramm: Einbettungsmodell
Stellen Sie sich die Dokumenteinbettung als die Erstellung Ihrer durchsuchbaren Bibliothek vor, während die Abfrageeinbettung jede Frage in dasselbe Format umwandelt, sodass Sie die richtigen Bücher in dieser Bibliothek finden können. Die Suche beginnt erst , nachdem die Frage übersetzt wurde.
Speichern und Durchsuchen Ihrer Einbettungen mit einem Vektorspeicher
Nachdem Sie Ihre Dokumente in Einbettungen konvertiert haben, müssen Sie sie an einer beliebigen Stelle speichern, die eine schnelle semantische Suche ermöglicht. Eine normale Datenbank würde damit kämpfen, da sie die mathematische Ähnlichkeit zwischen Vektoren nicht effizient vergleichen kann.
Ein Vektorspeicher ist eine spezielle Datenbank, die speziell für das Speichern und Durchsuchen von Einbettungen (diese mathematischen Vektoren, die aus Ihren Dokumenten erstellt wurden) entwickelt wurde. Im Gegensatz zu herkömmlichen Datenbanken, die Text oder Zahlen speichern, sind Vektorspeicher für die schnelle Suche nach ähnlichen Vektoren optimiert, auch wenn es um Millionen von Dokumenten geht.
Sie können Vektorspeicher über Vektordatenbanken, Vektorbibliotheken oder Datenbank-Plug-Ins implementieren.
Der Vektorspeicher ermöglicht die semantische Suche, d. h., sie findet relevante Inhalte basierend auf bedeutungsbezogenen und nicht exakten Schlüsselwortübereinstimmungen. Beispielsweise würde die Suche nach "Abwesenheitszeit" Dokumente zu "Urlaubsrichtlinien" finden, obwohl die genauen Wörter nicht übereinstimmen. Bei der Suche können Sie vor, während oder nach der Abfrage Filter anwenden.
Erweitern der Eingabeaufforderung mit abgerufenen Inhalten
Nach dem Auffinden der relevantesten Dokumente kombiniert das RAG-System diese Informationen mit der ursprünglichen Frage des Benutzers, um eine "erweiterte Eingabeaufforderung" zu erstellen, die dem LLM alles gibt, was es benötigt, um eine genaue Antwort zu liefern.
Der Augmentationsprozess sieht wie folgt aus:
- Beginnen Sie mit der Frage des Benutzers: "Was ist unsere Urlaubsrichtlinie?"
- Hinzufügen eines abgerufenen Kontexts: Einbeziehen relevanter Auszüge aus Ihren HR-Dokumenten
- Erstellen Sie eine erweiterte Eingabeaufforderung: "Basierend auf diesen HR-Richtliniendokumenten: [abgerufene Inhalte], was ist unsere Urlaubsrichtlinie?" Die LLM verfügt jetzt sowohl über die Frage des Benutzers als auch über die spezifischen Informationen, die für die genaue Beantwortung erforderlich sind. Dies wird als "kontextbezogenes Lernen" bezeichnet, da die LLM aus dem kontextbezogenen Kontext der Eingabeaufforderung und nicht aus den ursprünglichen Schulungsdaten lernt.
Im letzten Schritt wird die erweiterte Eingabeaufforderung an das LLM (Large Language Model) gesendet, das eine Antwort basierend auf der Frage und den abgerufenen Informationen generiert. Das LLM kann Zitate der ursprünglichen Quellen enthalten, sodass Benutzer überprüfen können, woher die Informationen stammen.
Der Hauptvorteil der RAG-Workflows besteht darin, dass sie Ihnen genaue, quellgestützte Antworten liefert, ohne das gesamte Sprachmodell für Ihre spezifischen Dokumente neu trainieren zu müssen.
Übersicht über die RAG-Architektur
Der vollständige RAG-Workflow kombiniert alle Komponenten, die wir überprüft haben, zu einem einheitlichen System, das Allzweck-LLMs in fachkundige Assistenten für Ihre spezifische Domäne verwandelt.
Der Schlüsselmechanismus ist kontextbezogenes Lernen – anstatt den LLM umzubilden, stellen Sie relevante Informationen als Kontext in jeder Aufforderung bereit, damit der LLM informierte Antworten ohne permanente Änderung generieren kann.
Erweiterte Implementierungen können Feedbackschleifen enthalten, um Ergebnisse zu verfeinern, wenn die erste Antwort keine Qualitätsschwellenwerte erfüllt.