Visualisieren von Daten mit Spark
Eine der intuitivsten Möglichkeiten, die Ergebnisse von Abfragen zu analysieren, ist die Visualisierung in Diagrammen. Notizbücher in Azure Synapse Analytics bieten einige grundlegende Diagrammfunktionen auf der Benutzeroberfläche, und wenn diese Funktionalität nicht die benötigten Funktionen bereitstellt, können Sie eine der vielen Python-Grafikbibliotheken verwenden, um Datenvisualisierungen im Notizbuch zu erstellen und anzuzeigen.
Verwenden integrierter Notebookdiagramme
Wenn Sie einen Dataframe anzeigen oder eine SQL-Abfrage in einem Spark-Notizbuch in Azure Synapse Analytics ausführen, werden die Ergebnisse unter der Codezelle angezeigt. Standardmäßig werden die Ergebnisse als Tabelle dargestellt, aber Sie können die Ergebnisansicht auch in ein Diagramm ändern und die Diagrammeigenschaften verwenden, um die Darstellung der Daten im Diagramm anzupassen, wie hier gezeigt:
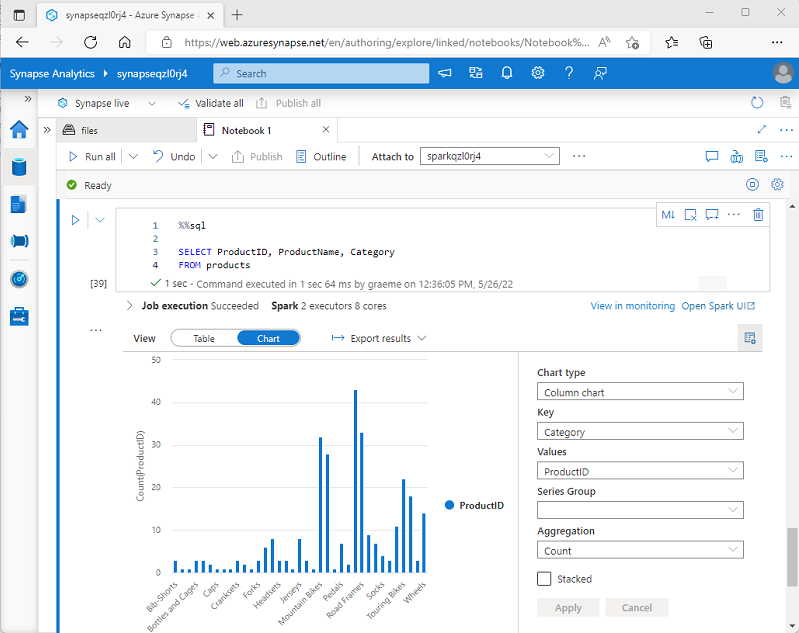
Die integrierte Diagrammfunktion in Notizbüchern ist nützlich, wenn Sie mit Ergebnissen einer Abfrage arbeiten, die keine vorhandenen Gruppierungen oder Aggregationen enthalten, und Sie die Daten visuell schnell zusammenfassen möchten. Wenn Sie mehr Kontrolle darüber haben möchten, wie die Daten formatiert sind, oder wenn Sie Werte anzeigen möchten, die Sie bereits in einer Abfrage aggregiert haben, sollten Sie ein Grafikpaket zum Erstellen eigener Visualisierungen in Betracht ziehen.
Verwenden von Grafikpaketen im Code
Es gibt viele Grafikpakete, mit denen Sie Datenvisualisierungen im Code erstellen können. Insbesondere unterstützt Python eine große Auswahl an Paketen; die meisten von ihnen basieren auf der Basis-Matplotlib-Bibliothek . Die Ausgabe einer Grafikbibliothek kann in einem Notebook gerendert werden, sodass es einfach ist, Code zur Erfassung und Bearbeitung von Daten mit Inline-Datenvisualisierungen und Markdownzellen für Kommentare zu kombinieren.
Sie könnten z. B. den folgenden PySpark-Code verwenden, um Daten aus den hypothetischen Produktdaten zu aggregieren, die zuvor in diesem Modul untersucht wurden, und Matplotlib verwenden, um ein Diagramm aus den aggregierten Daten zu erstellen.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
Die Matplotlib-Bibliothek erfordert, dass sich Daten in einem Pandas-Datenframe und nicht in einem Spark-Datenframe befinden, sodass die toPandas-Methode verwendet wird, um sie zu konvertieren. Der Code erstellt dann eine Abbildung mit einer bestimmten Größe und zeichnet ein Balkendiagramm mit einer benutzerdefinierten Eigenschaftskonfiguration, bevor er den resultierenden Plot anzeigt.
Das durch den Code erzeugte Diagramm würde ähnlich wie die folgende Abbildung aussehen:
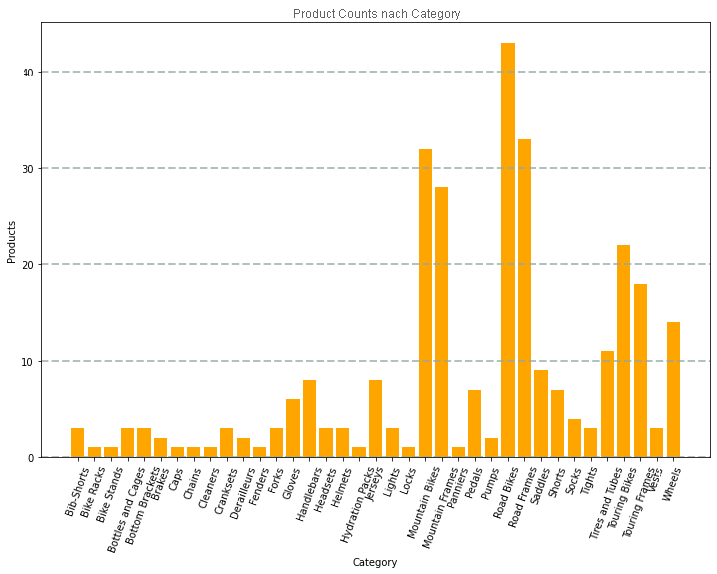
Sie können die Matplotlib-Bibliothek verwenden, um viele Arten von Diagrammen zu erstellen; oder wenn bevorzugt, können Sie andere Bibliotheken wie Seaborn verwenden, um hoch angepasste Diagramme zu erstellen.