Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Notiz
Informationen zum Automatisieren der manuellen Analyse, die in diesem Artikel beschrieben wird, finden Sie unter Verwenden von AGDiag zum Diagnostizieren von Integritätsereignissen für Verfügbarkeitsgruppen.
Dieser Artikel enthält Schritte zur Problembehandlung, mit denen Sie ermitteln können, warum Ihre Verfügbarkeitsgruppe fehlgeschlagen ist.
Auswirkungen von Always On-Integritätsproblemen oder Failover
Always On implementiert eine robuste Integritätsüberwachung über verschiedene Mechanismen, um die Integrität der Microsoft SQL Server-Instanz sicherzustellen, die das primäre Replikat, den zugrunde liegenden Cluster und die Systemintegrität hostet. Die Produktionsarbeitsauslastung wird momentan unterbrochen, wenn ein Windows-Cluster oder Always On-Integritätsproblem identifiziert wird.
Wenn eine Integritätsbedingung erkannt wird, tritt in der Regel die folgende Abfolge von Ereignissen auf. Während dieser Problembehandlung werden Integritätsereignisse in Bezug auf die folgenden Ereignisse erwähnt:
Verfügbarkeitsgruppenreplikate und Datenbanken wechseln von der primären Rolle zur Auflösung der Rolle.
Verfügbarkeitsgruppendatenbanken wechseln in den Offlinemodus und sind nicht mehr zugänglich.
Windows-Cluster kennzeichnet die gruppierte Verfügbarkeitsressource als fehlgeschlagen.
Windows Cluster versucht, die Verfügbarkeitsgruppenrolle wieder online zu schalten (im ursprünglichen oder automatischen Failoverpartnerreplikat).
Die Verfügbarkeitsgruppenrolle wird erfolgreich online bereitgestellt, wenn erkannt wird, dass sie durch alwaysOn und Windows Cluster-Integritätsüberwachung fehlerfrei ist.
Bei erfolgreicher Ausführung wechseln die Verfügbarkeitsgruppenreplikate und Datenbanken zur primären Rolle und die Verfügbarkeitsgruppendatenbanken online und können von Ihrer Anwendung zugänglich sein.
Anwendungen können nicht auf die Verfügbarkeitsgruppendatenbanken zugreifen.
Wenn eine Integritätsbedingung erkannt wird, wechseln das Verfügbarkeitsgruppenreplikat und die Datenbanken zur Auflösungsrolle, und die Verfügbarkeitsgruppendatenbanken werden offline geschaltet. Nachdem das Replikat in der primären Rolle (auf dem ursprünglichen Replikatserver oder dem Failoverpartnerreplikatserver) online bereitgestellt wurde, wechseln replikate und Datenbanken erneut in die Onlineversion. Während das Replikat und die Datenbanken aufgelöst und offline sind, schlagen alle Anwendungen, die versuchen, auf diese Verfügbarkeitsgruppendatenbanken zuzugreifen, fehl und generieren eine Meldung "Fehler 983": Unable to access availability database.... Dieser Fehler wird auch im Microsoft SQL Server-Fehlerprotokoll aufgezeichnet, wenn SQL Server zum Aufzeichnen fehlgeschlagener Anmeldeversuche konfiguriert ist:
Logon Error: 983, Severity: 14, State: 1.
Logon Unable to access availability database '<databasename>' because the database replica is not in the PRIMARY or SECONDARY role. Connections to an availability database is permitted only when the database replica is in the PRIMARY or SECONDARY role. Try the operation again later.
Der Zeitraum, in dem sich die Verfügbarkeitsgruppe in der Rolle "Auflösen" befindet, bevor sie in der primären Rolle wieder online ist, dauert in der Regel nur ein paar Sekunden oder sogar weniger als eine Sekunde.
Identifizieren und Diagnostizieren von Integritätsereignissen für AlwaysOn-Verfügbarkeitsgruppen oder Failover
1. Identifizieren von AlwaysOn-Gesundheitstrends
Möglicherweise untersuchen Sie ein einzelnes Always On-Integritätsereignis, oder es gibt einen aktuellen oder anhaltenden Trend von Gesundheitsproblemen, die die Produktion unterbrechen. Die folgenden Fragen können Ihnen helfen, aktuelle Änderungen in Ihrer Produktionsumgebung einzugrenzen und zu korrelieren, die sich möglicherweise auf diese Gesundheitsprobleme beziehen:
- Wann wurde der Trend "Always On" oder "Clusterintegrität" gestartet?
- Treten die Gesundheitsereignisse an einem bestimmten Tag auf?
- Treten die Gesundheitsereignisse zu einer bestimmten Tageszeit auf?
- Treten die Gesundheitsereignisse an einem bestimmten Tag oder einer bestimmten Woche des Monats auf?
Wenn Sie einen Trend erkennen, überprüfen Sie die geplante Wartung auf dem System (das Hostsystem in einer virtuellen Umgebung), ETL-Batches und andere Aufträge, die mit diesen Integritätsereignissen korrelieren können. Wenn es sich bei dem System um einen virtuellen Computer handelt, untersuchen Sie das Hostsystem auf Änderungen, die möglicherweise zum Zeitpunkt der Ausfälle eingeführt wurden.
Erwägen Sie gebuchte Ad-hoc-Produktionsworkloads, die mit der Zeit der Integritätsprobleme korrelieren können (z. B. wenn sich Benutzer zum ersten Mal am System anmelden oder nachdem Benutzer von einem Mittagessen zurückkehren).
Notiz
Dies ist ein guter Zeitpunkt, um einen Plan zum Sammeln von Leistungsdaten in der gesamten Woche und im Monat zu berücksichtigen. Um besser zu verstehen, wann das System am stärksten ist, können Sie Windows-Leistungsindikatoren wie Processor Information::% Processor Time, Memory::Available MBytesund MSSQLServer:SQL Statistics::Batch Requests/sec.
2. Überprüfen des Clusterprotokolls
Das Windows Cluster-Protokoll ist das umfassendste Protokoll, das verwendet werden kann, um die Art des Always On- oder Clusterintegritätsereignisses sowie die erkannte Integritätsbedingung zu identifizieren, die das Ereignis verursacht hat. Führen Sie die folgenden Schritte aus, um das Clusterprotokoll zu generieren und zu öffnen:
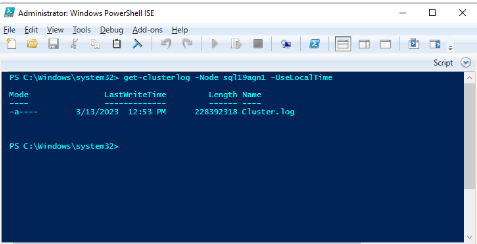
Verwenden Sie Windows PowerShell, um das Windows Cluster-Protokoll auf dem Clusterknoten zu generieren, auf dem das primäre Replikat zum Zeitpunkt des Integritätsereignisses gehostet wird. Führen Sie beispielsweise das folgende Cmdlet in einem PowerShell-Fenster mit erhöhten Rechten aus, indem Sie "sql19agn1" als SQL Server-basierten Servernamen verwenden:
get-clusterlog -Node sql19agn1 -UseLocalTime
Notiz
Standardmäßig wird die Protokolldatei in %WINDIR%\cluster\reports erstellt.
3. Suchen des Integritätsereignisses im Clusterprotokoll
Always On verwendet mehrere Integritätsüberwachungsmechanismen, um die Verfügbarkeitsgruppenintegrität zu überwachen. Zusätzlich zu einem Windows Cluster-Integritätsereignis (in dem Windows Cluster ein Integritätsproblem zwischen den Clusterknoten erkennt), verfügt Always On über vier verschiedene Arten von Integritätsprüfungen:
- Der SQL Server-Dienst wird nicht ausgeführt.
- Timeout für SQL Server-Lease
- Timeout für sql Server-Integritätsüberprüfung
- Ein internes SQL Server-Integritätsproblem
Sie können eines dieser AlwaysOn-spezifischen Integritätsereignisse finden, indem Sie das Clusterprotokoll nach der Zeichenfolge [hadrag] Resource Alive result 0durchsuchen. Diese Zeichenfolge wird im Clusterprotokoll gespeichert, wenn eines dieser Ereignisse erkannt wird. Zum Beispiel:
00001334.00002ef4::2019/06/24-18:24:36.153 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
Sie können ein Tool verwenden, um alle Integritätsereignisse im Clusterprotokoll zu finden, damit Sie einen zusammenfassenden Bericht über Always On-Integritätsprobleme generieren können. Dies kann hilfreich sein, um chronologische Trends zu identifizieren und zu bestimmen, ob ein bestimmter Always On-Integritätszustand wiederholt wird. Der folgende Screenshot zeigt, wie Sie einen Text-Editor (NotePad++, in diesem Fall) verwenden, um alle Zeilen im Clusterprotokoll zu finden, die die [hadrag] Resource Alive result 0 Zeichenfolge enthalten:

Identifizieren und Beheben des Integritätsproblems, das das Failover ausgelöst hat
Um die Integritätsprobleme im Clusterprotokoll des primären Replikats zu identifizieren, vergleichen Sie sie mit den in den folgenden Abschnitten beschriebenen Problemen. Häufige Gründe für das AG-Failover sind:
- Clusterintegritätsereignis
- SQL Server-Dienst ist ausgefallen (ein Always On-Integritätsereignis)
- Timeout für leasen (ein Always On-Integritätsereignis)
- Timeout der Integritätsprüfung (ein Always On-Integritätsereignis)
- SQL Server-Integrität (ein Always On-Integritätsereignis)
Clusterintegritätsereignisse
Microsoft Windows Cluster überwacht den Status der Mitgliedsserver im Cluster. Wenn ein Integritätsproblem erkannt wird, wird möglicherweise ein Clusterelementserver aus dem Cluster entfernt. Außerdem werden die Clusterressourcen (einschließlich der Verfügbarkeitsgruppenrolle, die auf dem entfernten Clustermitgliedsserver gehostet wird) in das Failover-Partnerreplikat der Verfügbarkeitsgruppe verschoben, wenn sie für automatisches Failover konfiguriert ist.
Problembeschreibung
Hier ist ein Beispiel für ein Clusterintegritätsereignis im Clusterprotokoll. Um es zu finden, können Sie suchen Lost quorum oder Cluster service has terminated weil entweder während der Änderung der Verfügbarkeitsgruppenrolle oder während des Failovers vorhanden sein können.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: Lost quorum (1)
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: goingAway: 0, core.IsServiceShutdown: 0
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925)
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [NETFT] Cluster Service preterminate succeeded.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925), executing OnStop
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM]: Shutting down, so unloading the cluster database.
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM] Shutting down, so unloading the cluster database (waitForLock: false).
000019cc.000019d0::2022/12/15-14:26:02.654 WARN [RHS] Cluster service has terminated. Cluster.Service.Running.Event got signaled.
Eine weitere Möglichkeit, dieses Ereignis zu identifizieren, besteht darin, das Windows-Systemereignisprotokoll zu durchsuchen:
Critical SQL19AGN1.CSSSQL 1135 Microsoft-Windows-FailoverClusterin Node Mgr NT AUTHORITY\SYSTEM Cluster node 'SQL19AGN2' was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Critical SQL19AGN1.CSSSQL 1177 Microsoft-Windows-FailoverClusterin Quorum Manager NT AUTHORITY\SYSTEM The Cluster service is shutting down because quorum was lost. This could be due to the loss of network connectivity between some or all nodes in the cluster, or a failover of the witness disk. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Diagnostizieren eines Clusterintegritätsereignisses
Die Fehler im Windows-Ereignisprotokoll (Ereignisse 1135 und 1177) deuten darauf hin, dass die Netzwerkkonnektivität eine Ursache für das Ereignis ist. Dies ist der häufigste Grund, warum ein Clusterintegritätsproblem erkannt wird. Das folgende Beispiel zeigt, dass andere Clustermitgliedsserver nicht mit diesem Server kommunizieren konnten, der das primäre Replikat der Verfügbarkeitsgruppe hostet und dass dieses Problem das Entfernen des Clusterknotens aus dem Cluster ausgelöst hat:
00000fe4.00001edc::2022/12/14-22:44:36.870 INFO [NODE] Node 1: New join with n3: stage: 'Attempt Initial Connection' status (10060) reason: 'Failed to connect to remote endpoint <endpoint address>'
00000fe4.00001620::2022/12/15-14:26:02.050 INFO [IM] got event: Remote endpoint <endpoint address> unreachable from <endpoint address>
00000fe4.00001620::2022/12/15-14:26:02.050 WARN [NDP] All routes for route (virtual) local <local address> to remote <remote address> are down
00000fe4.0000179c::2022/12/15-14:26:02.053 WARN [NODE] Node 1: Connection to Node 2 is broken. Reason GracefulClose(1226)' because of 'channel to remote endpoint <endpoint address> is closed'
Sie können das Clusterprotokoll nach Nachweisen eines Verbindungsfehlers mit dem Knoten durchsuchen. Suchen Sie von der Position im Clusterprotokoll, an der Sie gefunden haben Lost quorum, rückwärts nach Zeichenfolgen wie Failed to connect to remote endpoint, , unreachableund is broken.
Lösung
Stellen Sie sicher, dass die Clusterintegritätsüberwachung für die Hostumgebung geeignet ist. Weitere Informationen zu SQL Server AlwaysOn-Verfügbarkeitsgruppen, die in Microsoft Azure gehostet werden, finden Sie in der Übersicht über den Windows Server-Failovercluster – SQL Server auf Azure-VMs.
Wenn dies erforderlich ist, wenden Sie sich an den Microsoft Windows High Availability-Support, um einen Supportvorfall zu öffnen.
SQL Server-Dienst ist ausgefallen: Ein Always On-Integritätsereignis
Die Always On-Integritätsüberwachung kann erkennen, ob der SQL Server-Dienst, der das primäre Replikat der Verfügbarkeitsgruppe hostt, nicht mehr ausgeführt wird.
Problembeschreibung
Hier ist ein Beispiel für den Clusterprotokollbericht für die Verfügbarkeitsgruppenrolle "ag", die einen Fehler angibt, da QueryServiceStatusEx eine Prozess-ID 0zurückgegeben wurde:
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] QueryServiceStatusEx returned a process id 0
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] SQL server service is not alive
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] Resource Alive result 0.
00001898.0000185c::2023/02/27-13:27:41.121 WARN [RHS] Resource ag IsAlive has indicated failure.
Diagnose von Ereignissen zum Herunterfahren des SQL-Diensts
Überprüfen Sie das Windows-Systemereignisprotokoll und das SQL Server-Fehlerprotokoll auf ein unerwartetes Herunterfahren von SQL Server.
Wenn SQL Server durch ein System heruntergefahren oder ein administratives Herunterfahren beendet wurde, wird der folgende Eintrag im SQL Server-Fehlerprotokoll angezeigt:
2023-03-10 09:38:46.73 spid9s SQL Server is terminating in response to a 'stop' request from Service Control Manager. This is an informational message only. No user action is required.
Das Windows-Systemereignisprotokoll würde den folgenden Fehlereintrag anzeigen:
Information 3/10/2023 9:41:06 AM Service Control Manager 7036 None The SQL Server (MSSQLSERVER) service entered the stopped state.
Das Windows-Systemereignisprotokoll zeigt den folgenden Fehlereintrag an, wenn SQL Server unerwartet heruntergefahren wird:
Error 3/10/2023 8:37:46 AM Service Control Manager 7034 None The SQL Server (MSSQLSERVER) service terminated unexpectedly. It has done this 1 time(s).
Überprüfen Sie das Ende des SQL Server-Fehlerprotokolls auf Hinweise. Wenn das Fehlerprotokoll abrupt beendet wird, bedeutet dies, dass es durch Kraft heruntergefahren wurde. Wenn SQL Server beispielsweise mithilfe des Task-Managers beendet wurde, würde der SQL Server-Fehlerbericht keine Informationen zu internen Problemen offenlegen, die dazu führen könnten, dass der Prozess heruntergefahren wurde.
Lösung
Stellen Sie sicher, dass autorisierte Datenbank- und Systemadministratoren Zugriff auf das System haben, um unerwartete Beendigungen des SQL Server-Diensts zu minimieren. Nachdem Sie die Ereignisprotokolle untersucht haben, untersuchen Sie, warum ein Dienst unerwartet beendet werden musste.
Wenn ein internes SQL Server-Integritätsproblem dazu führte, dass SQL Server unerwartet beendet wurde, gibt es möglicherweise Hinweise auf eine mögliche schwerwiegende Ausnahme (einschließlich einer Speicherabbild-Diagnosedatei, die generiert wird) am Ende des SQL-Fehlerprotokolls. Überprüfen Sie die Hinweise, und ergreifen Sie die erforderlichen Maßnahmen. Wenn Sie eine Speicherabbilddatei finden, wenden Sie sich an die Unterstützung von Microsoft SQL Server, und stellen Sie das SQL Server-Fehlerprotokoll und den Inhalt der Abbilddatei zur weiteren Untersuchung bereit.
Timeout des Leases: Ein AlwaysOn-Integritätsereignis
Always On verwendet einen "Lease"-Mechanismus, um den Status des Computers zu überwachen, auf dem SQL Server installiert ist. Der Standardmäßige Leasetimeout beträgt 20 Sekunden.
Problembeschreibung
Hier ist eine Beispielausgabe eines Always On-Lease-Timeouts aus dem Clusterprotokoll. Sie können diese Zeichenfolgen durchsuchen, um ein Leasetimeout im Clusterprotokoll zu finden.
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Availability Group lease is no longer valid
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:35:57.0, 98.068572, 509227008.000000, 0.000395, 0.000350 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:7.0, 12.314941, 451817472.000000, 0.000278, 0.000266 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:17.0, 17.270742, 416096256.000000, 0.000376, 0.000292 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:27.0, 38.399895, 416301056.000000, 0.000446, 0.000304 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:37.0, 100.000000, 417517568.000000, 0.001292, 0.000666
Weitere Informationen zum Timeout des Lease-Timeouts finden Sie im Abschnitt "Lease Mechanism" in den Richtlinien für Lease,Cluster und Integritätsprüfungstimeouts für AlwaysOn-Verfügbarkeitsgruppen.
Diagnose und Auflösung von Always On-Lease-Timeoutereignissen
Es gibt zwei Hauptprobleme, mit denen ein Leasetimeout ausgelöst werden kann:
SQL Server-Speicherabbild: Wenn SQL Server bestimmte interne Integritätsereignisse erkennt, z. B. eine Zugriffsverletzung, eine Assertion oder ein Scheduler-Deadlock, wird eine Diagnoseabbilddatei (MDMP) im SQL Server \LOG-Ordner generiert. Der Prozess zum Generieren eines Speicherabbilds hält die SQL Server-Ausführung für einen kurzen Zeitraum an. In diesem Zeitraum kann der Leasemechanismus fehlende Dienstantwort erkennen und Aktionen auslösen. Weitere Informationen finden Sie unter "Auswirkungen der Dumpgenerierung".
Ein systemweites Leistungsproblem: Ein Leasetimeout weist nicht unbedingt auf ein SQL Server-Integritätsproblem hin. Stattdessen könnte es auf ein systemweites Integritätsproblem hinweisen, das sich auch auf die Integrität des SQL Server-basierten Servers auswirkt.
- Hohe CPU-Auslastung auf dem System (nahe 100%).
- Nicht genügend Arbeitsspeicher – geringer virtueller Arbeitsspeicher und/oder eines der Prozesse wird ausgelagert.
- WSFC wird aufgrund eines Quorumverlusts offline
- VM-Drosselung wirkt sich auf die Leistung aus und verursacht den Ablauf des Leases.
Lösung
Ausführliche Schritte zur Problembehandlung finden Sie unter MSSQLSERVER_19407. Dies sind die beiden am häufigsten auftretenden Probleme:
1. SQL Serverabbilddateidiagnose
SQL Server erkennt möglicherweise ein internes Integritätsproblem, z. B. eine Zugriffsverletzung, Assertion oder deadlocked Scheduler. In diesem Fall generiert das Programm eine Miniabbilddatei (MDMP) im SQL Server \LOG-Ordner des SQL Server-Prozesses zur Diagnose. Der SQL Server-Prozess wird mehrere Sekunden lang fixiert, während die Miniabbilddatei auf den Datenträger geschrieben wird. Während dieser Zeit befinden sich alle Threads innerhalb des SQL Server-Prozesses in einem fixierten Zustand, der den Leasethread enthält, der von der Always On-Integritätsüberwachung überwacht wird. Daher erkennt Always On möglicherweise ein Leasetimeout.
**Dump thread - spid = 0, EC = 0x0000000000000000
***Stack Dump being sent to C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\LOG\SQLDump0001.txt
* *******************************************************************************
*
* BEGIN STACK DUMP:
* 11/02/14 21:21:10 spid 1920
*
* Deadlocked Schedulers
*
* *******************************************************************************
* -------------------------------------------------------------------------------
* Short Stack Dump
Stack Signature for the dump is 0x00000000000002BA
Error: 19407, Severity: 16, State: 1.
The lease between availability group 'ag' and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
Um dieses Problem zu beheben, muss die Speicherabbilddateidiagnose für die Ursache untersucht werden. Erwägen Sie die Kontaktaufnahme mit der Microsoft SQL Server-Unterstützung, um den SQL Server-Fehlerprotokoll und Denkdateiinhalt zur weiteren Untersuchung bereitzustellen.
2. Hohe CPU-Auslastung oder ein anderes Systemleistungsproblem
Ein Leasetimeout weist auf ein Leistungsproblem hin, das sich auf das gesamte System auswirkt, einschließlich SQL Server. Um das Systemproblem zu diagnostizieren, meldet always On health diagnostics performance monitor data in the cluster log and includes the lease timeout event. Die Leistungsdaten umfassen ca. 50 Sekunden, die bis zum Timeoutereignis des Leases führen, was die CPU-Auslastung, den freien Arbeitsspeicher und die Datenträgerlatenz meldet.
Hier ist ein Beispiel für die gemeldeten Leistungsdaten, die ein Leasetimeout im Clusterprotokoll zeigen. In dieser Beispielausgabe kann eine hohe allgemeine CPU-Auslastung im Zusammenhang mit dem Leasetimeout stehen.
00000f90.000015c0::2020/08/07-14:16:41.378 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00000f90.000015c0::2020/08/07-14:16:41.382 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:20.0, 83.266073, 31700828160.000000, 0.018094, 0.015752
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:30.0, 93.653224, 31697063936.000000, 0.038590, 0.026897
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:40.0, 94.270691, 31696265216.000000, 0.166000, 0.038962
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:50.0, 90.272016, 31695409152.000000, 0.215141, 0.106084
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:16:1.0, 99.991336, 31695892480.000000, 0.046983, 0.035440
Wenn die Leistungsdaten eine hohe CPU-Auslastung, eine geringe Arbeitsspeicherbedingung oder eine hohe Datenträgerlatenz zum Zeitpunkt eines Leasetimeouts aufweisen, beginnen Sie mit der Erfassung Leistungsmonitor Daten für den ganzen Tag im primären Replikat, um diese Symptome zu untersuchen. Durch die Erfassung von Leistungsüberwachungsdaten über einen längeren Zeitraum können Sie Baseline- und Höchstwerte für diese Ressourcen besser identifizieren und Änderungen dieser Ressourcen überwachen, wenn ein Leasetimeout auftritt. Berücksichtigen Sie beim Sammeln dieser Daten, ob bestimmte geplante oder Ad-hoc-Workloads in SQL Server vorhanden sind, die mit der Zeit dieser Ressourcenprobleme und Integritätsereignisse korrelieren.
Sie sollten auch Indikatoren erfassen, die den gleichen Systemressourceneinsatz melden, einschließlich der folgenden:
Processor Information::% Processor TimeMemory::Available MBytesLogical Disk::Avg. Disk sec/ReadLogical Disk::Avg. Disk sec/WriteLogical Disk::Avg. Disk Read Queue LengthLogical Disk::Avg. Disk Write Queue LengthMSSQLServer:SQL Statistics::Batch Requests/sec
Timeout des Integritätschecks: Ein AlwaysOn-Integritätsereignis
Always On verwendet einen Integritätsprüfungsmechanismus, um die Integrität von SQL Server und die Möglichkeit für Clientanwendungen, eine Verbindung herzustellen, zu überwachen.
Problembeschreibung
Wenn ein Verfügbarkeitsgruppenreplikat in die primäre Rolle wechselt, stellt die Always On-Integritätsüberwachung eine lokale ODBC-Verbindung mit der SQL Server-Instanz her. Wenn SQL Server nicht innerhalb des Zeitraums reagiert, der für die Integritätsprüfung der Verfügbarkeitsgruppe festgelegt ist (Standard ist 30 Sekunden), wird ein Timeout für die Integritätsprüfung ausgelöst, wenn SQL Server nicht innerhalb des Zeitraums reagiert, der für die Integritätsprüfung festgelegt ist. In diesem Fall wechselt die Verfügbarkeitsgruppe von der primären Rolle zur Auflösungsrolle und initiiert failover, wenn dies konfiguriert ist.
Weitere Informationen zu Timeouts für die Integritätsprüfung finden Sie im Abschnitt "Timeout-Vorgang zur Integritätsprüfung" in den Mechaniken und Richtlinien für Lease-, Cluster- und Integritätsprüfungstimeouts für AlwaysOn-Verfügbarkeitsgruppen.
Hier ist ein Always On-Integritätschecktimeout, wie im Clusterprotokoll angegeben:
0000211c.00002d70::2021/02/24-02:50:01.890 WARN [RES] SQL Server Availability Group: [hadrag] Failed to retrieve data column. Return code -1
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Resource Alive result 0.
0000211c.00002594::2021/02/24-02:50:02.453 WARN [RHS] Resource AG IsAlive has indicated failure.
00001278.00002ed8::2021/02/24-02:50:02.453 INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'AG', gen(0) result 1/0.
Diagnostizieren und Beheben des Timeoutereignisses für Always On-Integritätsüberprüfung
Der folgende Abschnitt hilft Ihnen, die SQL Server-Protokolle für "Brotkrümel"-Ereignisse zu überprüfen, die Sie möglicherweise finden und die mit Always On-Integritätscheck-Timeouts korrelieren, die erkannt und gemeldet werden. Zu den hier überprüften Protokollen gehören das Clusterprotokoll (bei dem das Timeout der Integritätsprüfung bestätigt wird), die system_health erweiterten Ereignisprotokolle und SQL Server-Fehlerprotokolle (beide im ORDNER "SQL Server \LOG ") und das Windows-Systemereignisprotokoll. Verwenden Sie diese und andere Protokolle, um nach korrelierenden Ereignissen zu suchen, die Ihnen dabei helfen können, die Ursache des Timeouts für die Integritätsprüfung zu ermitteln.
1. Überprüfen sie, ob ereignisse, die nicht zur Zeitplanung führen,
Das Timeout des Always On-Integritätschecks wird häufig durch "nicht ertragende" Ereignisse in SQL Server verursacht. Wenn SQL Server erkennt, dass ein Thread für einen Planer nicht zurückgegeben wurde, meldet er, dass ein nicht ertragendes Planerereignis aufgetreten ist. Wenn andere Vorgänge auf demselben Zeitplan angezeigt werden, der keine CPU-Zeit empfängt, ist dies das primäre Zeichen eines nicht ertragenden Zeitplans. Dieses Verhalten kann zu einer verzögerten Ausführung dieser Aufgaben und "Starve"-Workloads führen, die einem bestimmten Zeitplan der CPU-Zeit zugewiesen sind.
Führen Sie die folgenden Schritte aus, um nach Nichtertragungsterminen zu suchen:
Überprüfen Sie die erweiterten SQL Server-Ereignisprotokolle
system_health, um zu ermitteln, ob ein nicht ertragendes Schedulerereignis irgendeiner Art um den Zeitpunkt des Timeouts des Always On-Integritätscheckereignisses gemeldet wurde. Nicht ertragende Ereignisse, die Sie möglicherweise finden, umfassen Folgendes:scheduler_monitor_non_yielding_ring_buffer_recordedscheduler_monitor_non_yielding_iocp_ring_buffer_recordedscheduler_monitor_stalled_dispatcher_ring_buffer_recordedscheduler_monitor_non_yielding_rm_ring_buffer_recorded
Öffnen Sie die Erweiterten Ereignisprotokolle des SQL Server-Systems für den Systemstatus im primären Replikat, um das Timeout des verdächtigen Integritätschecks zu ermitteln.
Wechseln Sie in SQL Server Management Studio (SSMS) zu "Datei > öffnen", und wählen Sie " Erweiterte Ereignisdateien zusammenführen" aus.
Wählen Sie die Schaltfläche Hinzufügen aus.
Navigieren Sie im Dialogfeld "Datei öffnen " zu den Dateien im SQL Server \LOG-Verzeichnis .
Halten Sie ctrl gedrückt, und wählen Sie dann die Dateien aus, deren Namen mit
system_health_xxx.xel.Wählen Sie "OK öffnen">aus.
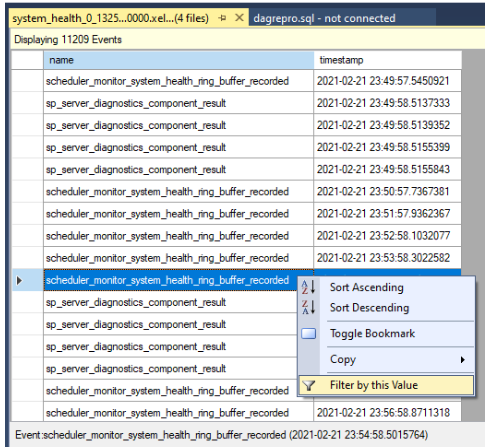
Filtert die Ergebnisse. Klicken Sie mit der rechten Maustaste auf ein Ereignis unter der Namensspalte , und wählen Sie "Nach diesem Wert filtern" aus.
Definieren Sie einen Filter zum Sortieren von Zeilen, in denen die Werte in der Namensspalte enthalten
yieldsind, wie im folgenden Screenshot dargestellt. Dies gibt alle Arten von Nicht-Ertrag-Ereignissen zurück, die möglicherweise in densystem_healthProtokollen aufgezeichnet wurden.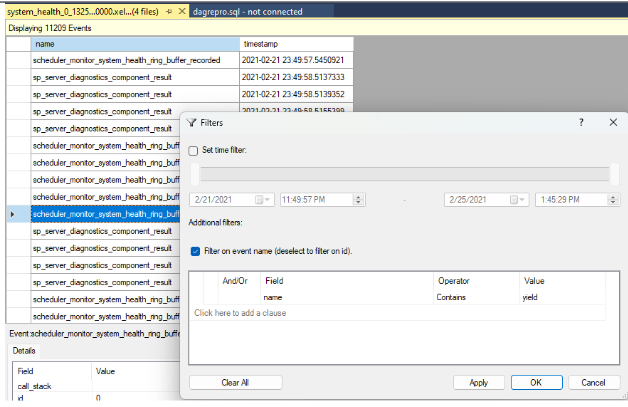
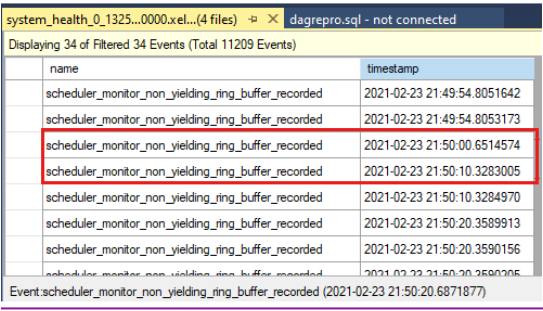
Vergleichen Sie die Zeitstempel, um festzustellen, ob zum Zeitpunkt des Timeouts für die Integritätsprüfung keine Ereignisse vorhanden waren. Dies ist das Timeout der Integritätsprüfung, wie im Clusterprotokoll angegeben:
0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1: [hadrag] Resource Alive result 0.Sie können sehen, dass beim Timeout des Integritätschecks nicht zurückgegebene Ereignisse aufgetreten sind.
Wenn Nichtertragsereignisse erkannt werden, überprüfen Sie die Ursache des Nichtertragungsereignisses. Erwägen Sie, sich an das SQL Server-Supportteam zu wenden, um die ereignisse zu untersuchen, die nicht ertragfrei sind.
2. Überprüfen des SQL Server-Fehlerprotokolls
Überprüfen Sie das SQL Server-Fehlerprotokoll, um Ereignisse zum Zeitpunkt des Timeouts der Integritätsprüfung zu korrelieren. Diese Ereignisse stellen möglicherweise "Brotkrümel" bereit, die weitere Schritte vorschlagen, um die Ursache für die Integritätsprüfungstimeouts festzulegen.
Der folgende Protokolleintrag zeigt beispielsweise, dass im Clusterprotokoll ein Timeout für die Integritätsprüfung aufgetreten ist:
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Resource Alive result 0.
Im SQL Server-Fehlerprotokoll meldet SQL Server innerhalb von Sekunden nach dem Timeout der Integritätsprüfung, dass sie schwere E/A-Latenz erkannt hat:
2021-02-23 20:49:54.64 spid12s SQL Server has encountered 1 occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\DATA\agdb_log.ldf] in database id 12. The OS file handle is 0x0000000000001594. The offset of the latest long I/O is: 0x000030435b0000. The duration of the long I/O is: 26728 ms.
Überprüfen Sie das Systemereignisprotokoll auf mögliche Systemhinweise, die mit dem Timeoutereignis für die Integritätsprüfung zusammenhängen könnten. Wenn Sie das Windows-Systemereignisprotokoll überprüfen, finden Sie möglicherweise ein E/A-Problem, das gleichzeitig für die gleiche Integritätsprüfung gemeldet wird:
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"Reset to device, \Device\<device ID>, was issued."
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"The IO operation at logical block address <block address> for Disk 6 (PDO name: \Device\<device ID>) was retried."
SQL Server-Integrität: Ein AlwaysOn-Integritätsereignis
Always On überwacht verschiedene Arten von SQL Server-Integritätsereignissen. Während es ein primäres Verfügbarkeitsgruppenreplikat hostt, wird SQL Server kontinuierlich sp_server_diagnostics ausgeführt, die über die SQL Server-Integrität mithilfe verschiedener Komponenten berichten. Wenn Integritätsprobleme erkannt werden, sp_server_diagnostics meldet sie einen Fehler für diese bestimmte Komponente und sendet dann die Ergebnisse an den AlwaysOn-Integritätserkennungsprozess zurück. Wenn ein Fehler gemeldet wird, zeigt die Rolle "Verfügbarkeitsgruppe" den Fehlerhaften Zustand und das mögliche Failover an, wenn die Verfügbarkeitsgruppe dafür konfiguriert ist.
Problembeschreibung
Hier ist ein Beispiel für ein SQL Server-Integritätsproblem, wie im Clusterprotokoll gemeldet sp_server_diagnostics . SQL Server meldet einen Fehlerstatus in der Systemkomponente zur Always On-Integritätsüberwachung, und die Verfügbarkeitsgruppe "contoso-ag" wird in einen fehlerhaften Zustand umgestellt.
Notiz
Ein SQL Server-Integritätsproblem generiert einen ähnlichen Bericht zum Timeout des Integritätschecks. Beide Integritätsereignisse melden Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel. Der Unterschied für ein SQL Server-Integritätsereignis besteht darin, dass die SQL Server-Komponente von "Warnung" in "Fehler" geändert wurde.
INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'system' health state has been changed from 'warning' to 'error' at 2019-06-20 15:05:52.330
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Resource Alive result 0.
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
WARN [RHS] Resource contoso-ag IsAlive has indicated failure.
INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'contoso-ag', gen(0) result 1/0.
Diagnose von SQL Server-Integritätsereignissen
Die Art des Von SQL Server-Integrität gemeldeten Integritätsproblems sollte die Richtung der Ursachenanalyse diktieren.
Wenn Sie eine Verfügbarkeitsgruppe bereitstellen, wird diese FAILURE_CONDITION_LEVEL standardmäßig als drei festgelegt. Dadurch wird die Überwachung einiger, aber nicht aller SQL Server-Integritätsprofile aktiviert. Auf der Standardebene löst AlwaysOn ein Integritätsereignis aus, wenn SQL Server zu viele Speicherabbilddateien, einen Schreibzugriffsverstoß oder ein verwaistes Spinlock erzeugt. Wenn Sie die Verfügbarkeitsgruppe auf Ebene 4 oder fünf festlegen, werden die Typen von SQL Server-Integritätsproblemen erweitert, die überwacht werden. Weitere Informationen zur SQL Server-Integritäts-AlwaysOn-Monitore finden Sie unter Konfigurieren einer flexiblen automatischen Failoverrichtlinie für eine Verfügbarkeitsgruppe – SQL Server AlwaysOn.
Führen Sie die folgenden Schritte aus, um das AlwaysOn-spezifische Integritätsproblem zu identifizieren:
Öffnen Sie die erweiterten SQL Server-Diagnoseereignisprotokolle für das primäre Replikat zum Zeitpunkt des auftretenden SQL Server-Integritätsereignisses.
Wechseln Sie in SSMS zu "Datei>öffnen", und wählen Sie dann "Erweiterte Ereignisdateien zusammenführen" aus.
Wählen Sie Hinzufügen.
Navigieren Sie im Dialogfeld "Datei öffnen " zu den Dateien im SQL Server \LOG-Verzeichnis .
Drücken Sie CTRL, wählen Sie die Dateien aus, deren Namen übereinstimmen
<servername>_<instance>_SQLDIAG_xxx.xel, und wählen Sie dann "OK öffnen">aus.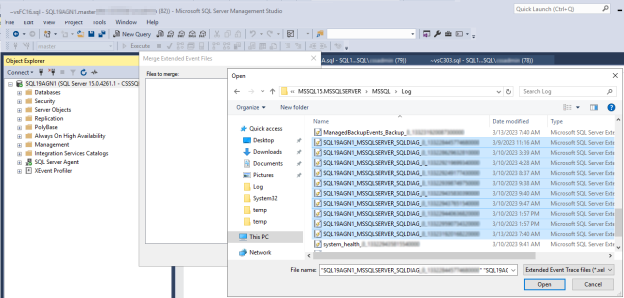
Sie sehen ein neues Fenster mit Registerkartenformat in SSMS, das die erweiterten Ereignisse enthält, wie im folgenden Screenshot gezeigt.
Um ein SQL Server-Integritätsproblem zu untersuchen, suchen Sie den
component_health_resultWert, dessenstate_descWert lauteterror. Hier ist ein Beispiel für ein Systemkomponentenereignis, das einen Fehler zurück zur Always On-Integritätsüberwachung gemeldet hat:
Doppelklicken Sie im unteren Bereich auf die Datenspalte . Dadurch werden die detaillierten Komponentendaten in einem neuen SSMS-Fensterbereich zur Überprüfung geöffnet. Hier sehen Sie, wie die Systemkomponentendaten aussehen:

Beachten Sie, dass die "totalDumprequests=186"-Daten darauf hindeuten, dass auf diesem SQL Server zu viele Speicherabbilddateidiagnoseereignisse generiert wurden. Dies ist der Grund, warum die Systemkomponente einen Fehlerstatus gemeldet hat. Wenn die Always On-Integritätsüberwachung diesen Fehlerstatus empfängt, löst sie ein Integritätsereignis der Verfügbarkeitsgruppe aus. Sie können auch überprüfen, ob keine Schreibzugriffsverletzungen oder verwaisten Spinlocks aus den daten der Systemkomponentendaten erkannt wurden.



Lösung
Je nachdem, welche Art von Problem Sie feststellen, müssen Sie es entsprechend beheben. Da die Konfiguration einer flexiblen automatischen Failoverrichtlinie für eine Verfügbarkeitsgruppe – SQL Server Always On-Artikel erläutert wird, können verschiedene Probleme auftreten, die zu diesem Ergebnis führen. Beispiele:
- Der SQL Server -Dienst ist ausgefallen.
- Leasetimeout.
- Das Verfügbarkeitsreplikat weist einen fehlerhaften Status auf.
- Speicherabbilder, die durch verwaiste Spinlocks, Zugriffsverletzungen oder zu viele Speicherabbilder generiert wurden, die in kurzer Zeit generiert wurden.
- Beständige Zustand außerhalb des Arbeitsspeichers im internen SQL Server-Ressourcenpool.
- Erkennung eines Deadlocks des Schedulers
- Erkennung eines unlösbaren Deadlocks.
Wenn dies erforderlich ist, wenden Sie sich an den SQL Server-Support, um einen Supportvorfall zu öffnen, um weitere Unterstützung bei der Suche nach der Ursache für diese internen SQL Server-Integritätsprobleme zu erhalten.