Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: SQL Server
Dieser Artikel enthält Verfahren zum Diagnostizieren und Beheben von Problemen, die durch eine hohe CPU-Auslastung auf einem Computer verursacht werden, auf dem Microsoft SQL Server ausgeführt wird. Obwohl es viele mögliche Ursachen für eine hohe CPU-Auslastung in SQL Server gibt, sind die folgenden die häufigsten Ursachen:
- Hohe logische Lesevorgänge, die durch Tabellen- oder Indexscans aufgrund der folgenden Bedingungen verursacht werden:
- Veraltete Statistiken
- Fehlende Indizes
- Probleme mit parameterabhängigen Plänen (PSP)
- Schlecht entworfene Abfragen
- Zunehmende Arbeitsauslastung
Sie können die folgenden Schritte durchführen, um Probleme mit hoher CPU-Auslastung in SQL Server zu beheben.
Schritt 1: Überprüfen Sie, ob SQL Server eine hohe CPU-Auslastung verursacht
Verwenden Sie eines der folgenden Tools, um zu überprüfen, ob der SQL Server-Prozess tatsächlich zu einer hohen CPU-Auslastung beiträgt:
Task-Manager: Überprüfen Sie auf der Registerkarte Prozesse, ob der Spaltenwert CPU für SQL Server Windows NT-64 Bit nahezu 100 Prozent beträgt.
Leistungs- und Ressourcenmonitor (perfmon)
- Zähler:
Process/%User Time,% Privileged Time - Instanz: sqlservr
- Zähler:
Sie können das folgende PowerShell-Skript verwenden, um die Indikatordaten über einen Zeitraum von 60 Sekunden zu erfassen:
$serverName = $env:COMPUTERNAME $Counters = @( ("\\$serverName" + "\Process(sqlservr*)\% User Time"), ("\\$serverName" + "\Process(sqlservr*)\% Privileged Time") ) Get-Counter -Counter $Counters -MaxSamples 30 | ForEach { $_.CounterSamples | ForEach { [pscustomobject]@{ TimeStamp = $_.TimeStamp Path = $_.Path Value = ([Math]::Round($_.CookedValue, 3)) } Start-Sleep -s 2 } }Wenn
% User Timedie Prozessorzeit konsistent größer als 90 % ist (% Benutzerzeit ist die Summe der Prozessorzeit für jeden Prozessor, der Maximalwert beträgt 100 % * (kein CPUs)), verursacht der SQL Server-Prozess eine hohe CPU-Auslastung. Wenn% Privileged timejedoch durchgängig mehr als 90 Prozent beträgt, tragen Ihre Antiviren-Software, andere Treiber oder eine andere Betriebssystemkomponente auf dem Computer zu einer hohen CPU-Auslastung bei. Sie sollten mit Ihrem Systemadministrator zusammenarbeiten, um die Grundursache dieses Verhaltens zu analysieren.Leistungsdashboard: Klicken Sie in SQL Server Management Studio mit der rechten Maustaste auf< SQLServerInstance>, und wählen Sie das Berichtsstandardbericht-Leistungsdashboard>> aus.
Das Dashboard veranschaulicht ein Diagramm mit dem Titel "System CPU-Auslastung " mit einem Balkendiagramm. Die dunklere Farbe gibt die CPU-Auslastung des SQL Server-Moduls an, während die hellere Farbe die cpu-Auslastung des gesamten Betriebssystems darstellt (siehe Legende im Diagramm zur Referenz). Wählen Sie die Schaltfläche "Zirkelaktualisierung" oder "F5 " aus, um die aktualisierte Auslastung anzuzeigen.
Schritt 2: Identifizieren Sie die Abfragen, die zur CPU-Auslastung beitragen
Wenn der Sqlservr.exe Prozess bei weitem eine hohe CPU-Auslastung verursacht, ist der häufigste Grund SQL-Server-Abfragen, die Tabellen- oder Indexscans ausführen, gefolgt von Sortier- und Hash-Operationen sowie von Schleifen (geschachtelter Schleifenoperator oder WHILE (T-SQL)). Um eine Vorstellung davon zu bekommen, wie viel CPU die Abfragen derzeit im Verhältnis zur gesamten CPU-Kapazität verbrauchen, führen Sie die folgende Anweisung aus:
DECLARE @init_sum_cpu_time int,
@utilizedCpuCount int
--get CPU count used by SQL Server
SELECT @utilizedCpuCount = COUNT( * )
FROM sys.dm_os_schedulers
WHERE status = 'VISIBLE ONLINE'
--calculate the CPU usage by queries OVER a 5 sec interval
SELECT @init_sum_cpu_time = SUM(cpu_time) FROM sys.dm_exec_requests
WAITFOR DELAY '00:00:05'
SELECT CONVERT(DECIMAL(5,2), ((SUM(cpu_time) - @init_sum_cpu_time) / (@utilizedCpuCount * 5000.00)) * 100) AS [CPU from Queries as Percent of Total CPU Capacity]
FROM sys.dm_exec_requests
Führen Sie die folgende Anweisung aus, um die Abfragen zu identifizieren, die derzeit für hohe CPU-Aktivitäten verantwortlich sind:
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
Wenn die CPU im Moment nicht durch Abfragen belastet wird, können Sie die folgende Anweisung ausführen, um nach historischen, CPU-gebundenen Abfragen zu suchen:
SELECT TOP 10 qs.last_execution_time, st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs.total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
Schritt 3: Aktualisieren Sie die Statistiken
Nachdem Sie die Abfragen mit der höchsten CPU-Auslastung identifiziert haben, aktualisieren Sie die Statistiken der Tabellen, die von diesen Abfragen verwendet werden. Sie können die gespeicherte Systemprozedur sp_updatestats verwenden, um die Statistiken aller benutzerdefinierten und internen Tabellen in der aktuellen Datenbank zu aktualisieren. Zum Beispiel:
exec sp_updatestats
Notiz
Die gespeicherte Systemprozedur sp_updatestats führt UPDATE STATISTICS für alle benutzerdefinierten und internen Tabellen in der aktuellen Datenbank aus. Achten Sie bei der regelmäßigen Wartung darauf, dass die Statistiken immer auf dem neuesten Stand sind. Nutzen Sie Lösungen wie Adaptive Index Defrag, um die Indexdefragmentierung und das Aktualisieren der Statistiken für eine oder mehrere Datenbanken automatisch zu verwalten. Diese Vorgehensweise entscheidet unter anderem anhand des Fragmentierungsgrads automatisch, ob ein Index neu erstellt oder neu organisiert wird, und aktualisiert Statistiken mit einem linearen Schwellenwert.
Weitere Informationen zu sp_updatestats finden Sie unter sp_updatestats.
Wenn SQL Server immer noch übermäßig viel CPU-Kapazität verbraucht, fahren Sie mit dem nächsten Schritt fort.
Schritt 4: Fügen Sie fehlende Indizes hinzu
Fehlende Indizes können zu langsamer ausgeführten Abfragen und einer hohen CPU-Auslastung führen. Sie können fehlende Indizes identifizieren und welche erstellen, um diese Auswirkungen auf die Leistung zu verbessern.
Führen Sie die folgende Abfrage aus, um Abfragen zu identifizieren, die eine hohe CPU-Auslastung verursachen und in deren Abfrageplan mindestens ein Index fehlt:
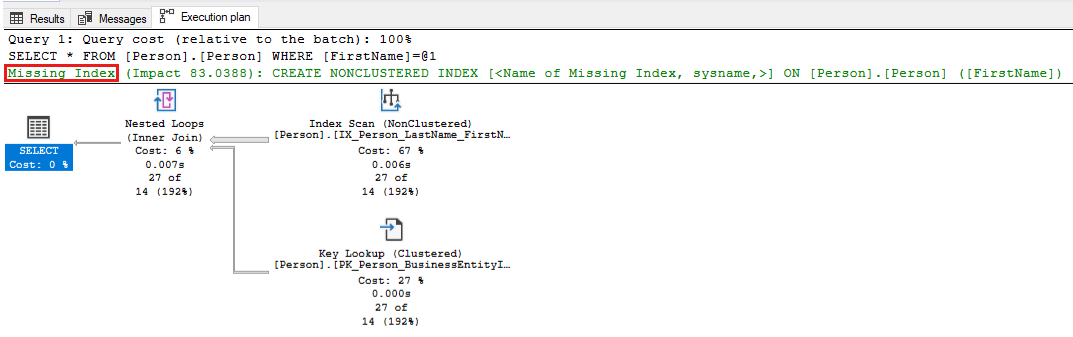
-- Captures the Total CPU time spent by a query along with the query plan and total executions SELECT qs_cpu.total_worker_time / 1000 AS total_cpu_time_ms, q.[text], p.query_plan, qs_cpu.execution_count, q.dbid, q.objectid, q.encrypted AS text_encrypted FROM (SELECT TOP 500 qs.plan_handle, qs.total_worker_time, qs.execution_count FROM sys.dm_exec_query_stats qs ORDER BY qs.total_worker_time DESC) AS qs_cpu CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q CROSS APPLY sys.dm_exec_query_plan(plan_handle) p WHERE p.query_plan.exist('declare namespace qplan = "http://schemas.microsoft.com/sqlserver/2004/07/showplan"; //qplan:MissingIndexes')=1Überprüfen Sie die Ausführungspläne für die identifizierten Abfragen, und optimieren Sie die Abfrage, indem Sie die erforderlichen Änderungen vornehmen. Der folgende Screenshot zeigt ein Beispiel, in dem SQL Server auf einen fehlenden Index für Ihre Abfrage hinweist. Klicken Sie mit der rechten Maustaste auf den Teil des Abfrageplans, wo der fehlende Index erwähnt wird, und wählen Sie dann Details zum fehlenden Index aus, um den Index in einem anderen Fenster in SQL Server Management Studio zu erstellen.
Verwenden Sie die folgende Abfrage, um nach fehlenden Indizes zu suchen und alle empfohlenen Indizes anzuwenden, für deren Verbesserungspotenziale hohe Werte angegeben werden. Beginnen Sie mit den ersten 5 oder 10 Empfehlungen aus der Ausgabe, für die die improvement_measure-Werte am höchsten sind. Diese Indizes haben die größten positiven Auswirkungen auf die Leistung. Entscheiden Sie, ob Sie diese Indizes anwenden möchten, und stellen Sie sicher, dass Leistungstests für die Anwendung durchgeführt werden. Setzen Sie dann ggf. weitere Empfehlungen zu fehlenden Indizes um, bis die Anwendung die gewünschten Leistungsergebnisse erzielt. Weitere Informationen zu diesem Thema finden Sie unter Optimieren nicht gruppierter Indizes mit Vorschlägen zu fehlenden Indizes.
SELECT CONVERT(VARCHAR(30), GETDATE(), 126) AS runtime, mig.index_group_handle, mid.index_handle, CONVERT(DECIMAL(28, 1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)) AS improvement_measure, 'CREATE INDEX missing_index_' + CONVERT(VARCHAR, mig.index_group_handle) + '_' + CONVERT(VARCHAR, mid.index_handle) + ' ON ' + mid.statement + ' (' + ISNULL(mid.equality_columns, '') + CASE WHEN mid.equality_columns IS NOT NULL AND mid.inequality_columns IS NOT NULL THEN ',' ELSE '' END + ISNULL(mid.inequality_columns, '') + ')' + ISNULL(' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement, migs.*, mid.database_id, mid.[object_id] FROM sys.dm_db_missing_index_groups mig INNER JOIN sys.dm_db_missing_index_group_stats migs ON migs.group_handle = mig.index_group_handle INNER JOIN sys.dm_db_missing_index_details mid ON mig.index_handle = mid.index_handle WHERE CONVERT (DECIMAL (28, 1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)) > 10 ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC

Schritt 5: Untersuchen und beheben Sie parameterabhängige Probleme
Sie können den Befehl DBCC FREEPROCCACHE verwenden, um den Cache frei zu planen, und überprüfen, ob dadurch das Problem der hohen CPU-Auslastung behoben wird. Wenn das Problem dadurch behoben ist, ist dies ein Hinweis auf ein parametersensitives Problem (PSP, auch bekannt als „Parameter-Schnüffel-Problem“).
Notiz
Wenn Sie DBCC FREEPROCCACHE ohne Parameter verwenden, werden alle kompilierten Pläne aus dem Plancache entfernt. Dies führt dazu, dass neue Abfrageausführungen erneut kompiliert werden, was zu einer einmaligen längeren Dauer für jede neue Abfrage führt. Der beste Ansatz besteht darin, mit DBCC FREEPROCCACHE ( plan_handle | sql_handle ) zu ermitteln, welche Abfrage das Problem verursachen kann, und diese einzelne(n) Abfrage(n) dann zu beheben.
Zur Entschärfung der parametersensitiven Probleme können Sie die folgenden Methoden verwenden. Jede Methode ist mit Vor- und Nachteilen verbunden.
Verwenden Sie den RECOMPILE-Abfragehinweis. Sie können einer oder mehreren der in
RECOMPILEidentifizierten Abfragen mit hoher CPU einen -Abfragehinweis hinzufügen. Dieser Hinweis trägt dazu bei, den leichten Anstieg der CPU-Auslastung der Kompilierung durch eine bessere Leistung für jede Abfrageausführung auszugleichen. Weitere Informationen finden Sie unter Parameter- und Ausführungsplanwiederverwendung, Parametersensitivität und RECOMPILE-Abfragehinweis.Hier ist ein Beispiel dafür, wie Sie diesen Hinweis auf Ihre Abfrage anwenden können.
SELECT * FROM Person.Person WHERE LastName = 'Wood' OPTION (RECOMPILE)Verwenden Sie den OPTIMIZE FOR-Abfragehinweis, um den tatsächlichen Parameterwert mit einem häufiger vorkommenden Parameterwert zu überschreiben, der die meisten Werte in den Daten abdeckt. Diese Option erfordert ein vollständiges Verständnis der optimalen Parameterwerte und zugehörigen Planmerkmale. Hier ist ein Beispiel für die Verwendung dieses Hinweises in Ihrer Abfrage.
DECLARE @LastName Name = 'Frintu' SELECT FirstName, LastName FROM Person.Person WHERE LastName = @LastName OPTION (OPTIMIZE FOR (@LastName = 'Wood'))Verwenden Sie den OPTIMIZE FOR UNKNOWN-Abfragehinweis, um den tatsächlichen Parameterwert mit dem Mittelwert des Dichtevektors zu überschreiben. Sie können dies auch tun, indem Sie die eingehenden Parameterwerte in lokalen Variablen erfassen und dann die lokalen Variablen innerhalb der Prädikate verwenden, anstatt die Parameter selbst zu verwenden. Für diesen Fix kann die durchschnittliche Dichte ausreichen, um eine akzeptable Leistung zu bieten.
Verwenden Sie den DISABLE_PARAMETER_SNIFFING-Abfragehinweis, um das „Erschnüffeln“ von Parametern vollständig zu deaktivieren. Hier ist ein Beispiel für die Verwendung in einer Abfrage:
SELECT * FROM Person.Address WHERE City = 'SEATTLE' AND PostalCode = 98104 OPTION (USE HINT ('DISABLE_PARAMETER_SNIFFING'))Verwenden Sie den KEEPFIXED PLAN-Abfragehinweis, um erneute Kompilierungen im Cache zu verhindern. Bei dieser Problemumgehung wird davon ausgegangen, dass der allgemeine, „hinreichend gute“ Plan der Plan ist, der sich bereits im Cache befindet. Sie können auch automatische Statistikaktualisierungen deaktivieren, um die Wahrscheinlichkeit zu verringern, dass der gute Plan entfernt und ein neuer schlechter Plan kompiliert wird.
Verwenden Sie den Befehl DBCC FREEPROCCACHE als temporäre Lösung, bis der Anwendungscode korrigiert ist. Sie können den Befehl
DBCC FREEPROCCACHE (plan_handle)verwenden, um nur denjenigen Plan zu entfernen, der das Problem verursacht. Um beispielsweise Abfragepläne zu finden, die auf diePerson.Person-Tabelle in AdventureWorks verweisen, können Sie diese Abfrage verwenden, um den Abfragehandle zu finden. Anschließend können Sie den spezifischen Abfrageplan aus dem Cache freigeben, indem Sie den in der zweiten Spalte der Abfrageergebnisse erstelltenDBCC FREEPROCCACHE (plan_handle)verwenden.SELECT text, 'DBCC FREEPROCCACHE (0x' + CONVERT(VARCHAR (512), plan_handle, 2) + ')' AS dbcc_freeproc_command FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_query_plan(plan_handle) CROSS APPLY sys.dm_exec_sql_text(plan_handle) WHERE text LIKE '%person.person%'
Schritt 6: Untersuchen und beheben Sie Probleme mit der SARGability
Ein Prädikat in einer Abfrage gilt als SARGable (Search ARGument-fähig), wenn SQL Server-Engine mithilfe einer Indexsuche die Ausführung der Abfrage beschleunigen kann. Viele Abfragedesigns verhindern SARGability und führen zu Tabellen- oder Indexüberprüfungen sowie hoher CPU-Auslastung. Betrachten Sie die folgende Abfrage für die AdventureWorks-Datenbank, in der jede ProductNumber abgerufen werden muss und jeweils die Funktion SUBSTRING() darauf angewendet werden muss, bevor sie mit einem Zeichenfolgenliteralwert verglichen wird. Wie Sie sehen können, müssen Sie zuerst alle Zeilen der Tabelle abrufen und dann die Funktion anwenden, bevor Sie einen Vergleich durchführen können. Das Abrufen aller Zeilen aus der Tabelle bedeutet eine Tabellen- oder Indexüberprüfung, die zu einer höheren CPU-Auslastung führt.
SELECT ProductID, Name, ProductNumber
FROM [Production].[Product]
WHERE SUBSTRING(ProductNumber, 0, 4) = 'HN-'
Das Anwenden einer beliebigen Funktion oder Berechnung auf die Spalte(n) im Suchprädikat macht die Abfrage im Allgemeinen nicht SARGable und führt zu einer höheren CPU-Auslastung. Lösungen umfassen normalerweise das Umschreiben der Abfragen auf kreative Weise, um sie SARGable zu machen. Eine mögliche Lösung für dieses Beispiel ist dieses Umschreiben, bei der die Funktion aus dem Abfrageprädikat entfernt wird, eine andere Spalte durchsucht wird und dieselben Ergebnisse erzielt werden:
SELECT ProductID, Name, ProductNumber
FROM [Production].[Product]
WHERE Name LIKE 'Hex%'
Hier ist ein weiteres Beispiel, bei dem ein Vertriebsleiter 10 % Verkaufsprovision für große Bestellungen vergeben möchte und sehen möchte, welche Aufträge Provisionen von mehr als 300 $ haben werden. Hier ist die logische, aber nicht SARGierbare Möglichkeit, dies zu tun.
SELECT DISTINCT SalesOrderID, UnitPrice, UnitPrice * 0.10 [10% Commission]
FROM [Sales].[SalesOrderDetail]
WHERE UnitPrice * 0.10 > 300
Dies ist eine mögliche weniger intuitive, aber SARGierbare Neuschreibung der Abfrage, bei der die Berechnung auf die andere Seite des Prädikats verschoben wird.
SELECT DISTINCT SalesOrderID, UnitPrice, UnitPrice * 0.10 [10% Commission]
FROM [Sales].[SalesOrderDetail]
WHERE UnitPrice > 300/0.10
SARGierbarkeit gilt nicht für WHERE-Ausdrücke, sondern auch für Ausdrucke mit JOINs, HAVING, GROUP BY und ORDER BY. Häufig auftretende Fälle, wo SARGierbarkeit in Abfragen verhindert wird, betreffen die Funktionen CONVERT(), CAST(), ISNULL(), COALESCE(), wenn sie in WHERE- oder JOIN-Ausdrücken verwendet werden, was zum Durchsuchen von Spalten führt. In den Fällen, in denen es um die Konvertierung von Datentypen geht (CONVERT oder CAST), kann die Lösung darin bestehen, sicherzustellen, dass Sie dieselben Datentypen vergleichen. Hier ist ein Beispiel, wo in einem T1.ProdID die Spalte INT explizit in den Datentyp JOIN konvertiert wird. Die Konvertierung verbietet die Verwendung eines Indexes in der Verknüpfungsspalte. Das gleiche Problem tritt bei der impliziten Konvertierung auf, bei der die Datentypen unterschiedlich sind und SQL Server einen von ihnen konvertiert, um die Verknüpfung auszuführen.
SELECT T1.ProdID, T1.ProdDesc
FROM T1 JOIN T2
ON CONVERT(int, T1.ProdID) = T2.ProductID
WHERE t2.ProductID BETWEEN 200 AND 300
Um eine Durchsuchung der Tabelle T1 zu vermeiden, können Sie den zugrundeliegenden Datentyp der Spalte ProdID nach entsprechender Planung und Gestaltung ändern und dann die beiden Spalten ohne Verwendung der Konvertierungsfunktion ON T1.ProdID = T2.ProductID verknüpfen.
Eine andere Lösung besteht darin, in T1 eine berechnete Spalte zu erstellen, in der die gleiche Funktion CONVERT() verwendet wird, und dann einen Index dafür zu erstellen. Dadurch kann der Abfrageoptimierer diesen Index verwenden, ohne dass Sie die Abfrage ändern müssen.
ALTER TABLE dbo.T1 ADD IntProdID AS CONVERT (INT, ProdID);
CREATE INDEX IndProdID_int ON dbo.T1 (IntProdID);
In einigen Fällen können Abfragen nicht einfach umgeschrieben werden, um SARGierbarkeit zu ermöglichen. Überprüfen Sie in diesen Fällen, ob eine berechnete Spalte mit einem zugehörigen Index dazu beitragen kann. Sonst müssen Sie halt die Abfrage so beibehalten, wie sie war, aber in dem Bewusstsein, dass sie zu Szenarien mit höherer CPU führen kann.
Schritt 7: Deaktivieren Sie umfangreiche Ablaufverfolgung
Prüfen Sie, ob SQL Trace oder XEvent-Ablaufverfolgung die Leistung von SQL Server beeinträchtigt und eine hohe CPU-Auslastung verursacht. Die Verwendung der folgenden Ereignisse kann z. B. zu einer hohen CPU-Auslastung führen, wenn Sie eine schwere SQL Server-Aktivität nachverfolgen:
- Abfrageplan XML-Ereignisse (
query_plan_profile,query_post_compilation_showplan,query_post_execution_plan_profile,query_post_execution_showplan)query_pre_execution_showplan - Ereignisse auf Anweisungsebene (
sql_statement_completed,sql_statement_starting,sp_statement_starting,sp_statement_completed) - Anmelde- und Abmeldeereignisse (
login,process_login_finish,login_event,logout) - Sperrereignisse (
lock_acquired,lock_cancel,lock_released) - Warteereignisse (
wait_info,wait_info_external) - SQL-Überwachungsereignisse (abhängig von der überwachten Gruppe und SQL Server-Aktivitäten in dieser Gruppe)
Führen Sie die folgenden Abfragen aus, um aktive XEvent- oder Serverablaufverfolgungen zu identifizieren:
PRINT '--Profiler trace summary--'
SELECT traceid, property, CONVERT(VARCHAR(1024), value) AS value FROM::fn_trace_getinfo(
default)
GO
PRINT '--Trace event details--'
SELECT trace_id,
status,
CASE WHEN row_number = 1 THEN path ELSE NULL end AS path,
CASE WHEN row_number = 1 THEN max_size ELSE NULL end AS max_size,
CASE WHEN row_number = 1 THEN start_time ELSE NULL end AS start_time,
CASE WHEN row_number = 1 THEN stop_time ELSE NULL end AS stop_time,
max_files,
is_rowset,
is_rollover,
is_shutdown,
is_default,
buffer_count,
buffer_size,
last_event_time,
event_count,
trace_event_id,
trace_event_name,
trace_column_id,
trace_column_name,
expensive_event
FROM
(SELECT t.id AS trace_id,
row_number() over(PARTITION BY t.id order by te.trace_event_id, tc.trace_column_id) AS row_number,
t.status,
t.path,
t.max_size,
t.start_time,
t.stop_time,
t.max_files,
t.is_rowset,
t.is_rollover,
t.is_shutdown,
t.is_default,
t.buffer_count,
t.buffer_size,
t.last_event_time,
t.event_count,
te.trace_event_id,
te.name AS trace_event_name,
tc.trace_column_id,
tc.name AS trace_column_name,
CASE WHEN te.trace_event_id in (23, 24, 40, 41, 44, 45, 51, 52, 54, 68, 96, 97, 98, 113, 114, 122, 146, 180) THEN CAST(1 as bit) ELSE CAST(0 AS BIT) END AS expensive_event FROM sys.traces t CROSS APPLY::fn_trace_geteventinfo(t.id) AS e JOIN sys.trace_events te ON te.trace_event_id = e.eventid JOIN sys.trace_columns tc ON e.columnid = trace_column_id) AS x
GO
PRINT '--XEvent Session Details--'
SELECT sess.NAME 'session_name', event_name, xe_event_name, trace_event_id,
CASE WHEN xemap.trace_event_id IN(23, 24, 40, 41, 44, 45, 51, 52, 54, 68, 96, 97, 98, 113, 114, 122, 146, 180)
THEN Cast(1 AS BIT)
ELSE Cast(0 AS BIT)
END AS expensive_event
FROM sys.dm_xe_sessions sess
JOIN sys.dm_xe_session_events evt
ON sess.address = evt.event_session_address
INNER JOIN sys.trace_xe_event_map xemap
ON evt.event_name = xemap.xe_event_name
GO
Schritt 8: Beheben der hohen CPU-Auslastung durch Spinlock-Contention
Informationen zum Beheben allgemeiner CPU-Auslastung durch Spinlock-Inhalte finden Sie in den folgenden Abschnitten.
SOS_CACHESTORE Spinlockkonflikt
Wenn ihre SQL Server-Instanz einen starken SOS_CACHESTORE Spinlockinhalt aufweist oder Sie feststellen, dass Ihre Abfragepläne häufig in nicht geplanten Abfrageworkloads entfernt werden, lesen Sie den folgenden Artikel und aktivieren Sie das Ablaufverfolgungskennzeichnung T174 mithilfe des DBCC TRACEON (174, -1) Befehls:
Wenn der Zustand mit hoher CPU-Auslastung durch die Verwendung von T174 behoben werden kann, aktivieren Sie dies als Startparameter mit dem Konfigurations-Manager von SQL Server.
Zufällig hohe CPU-Auslastung aufgrund von SOS_BLOCKALLOCPARTIALLIST Spinlock-Contention auf Großspeichercomputern
Wenn Ihre SQL Server-Instanz zufällig hohe CPU-Auslastung aufgrund von SOS_BLOCKALLOCPARTIALLIST Spinlock-Inhalten aufweist, empfehlen wir, kumulatives Update 21 für SQL Server 2019 anzuwenden. Weitere Informationen zum Beheben des Problems finden Sie unter Fehlerreferenz 2410400 und DBCC DROPCLEANBUFFERS , die temporäre Entschärfung bieten.
Hohe CPU-Auslastung aufgrund des Spinlockkonflikts auf XVB_list auf High-End-Computern
Wenn Ihre SQL Server-Instanz ein hohes CPU-Szenario verursacht, das XVB_LIST durch Spinlock-Konsistenz auf Hochkonfigurationscomputern verursacht wird (High-End-Systeme mit einer großen Anzahl von Prozessoren der neueren Generation (CPUs)), aktivieren Sie das Ablaufverfolgungskennzeichnung TF8102 zusammen mit TF8101.
Notiz
Eine hohe CPU-Auslastung kann sich aus spinlock-Inhalten bei vielen anderen Spinlocktypen ergeben. Weitere Informationen zu Spinlocks finden Sie unter Diagnose und Auflösung von Spinlock-Inhalten auf SQL Server.
Schritt 9: Überprüfen Ihrer Energieplaneinstellungen auf Betriebssystemebene
SQL Server-Arbeitslasten können zu einer verringerten Leistung führen und eine hohe CPU auf dem System verursachen, wenn Windows mit dem Standardmäßigen Leistungsplan "Ausgeglichen" konfiguriert ist. Die Einstellung des ausgewogenen Energieplans kann die CPU-Taktgeschwindigkeit verringern, um Energie zu sparen. Beispielsweise kann ein Prozessor mit 3,00 GHz auf 1,2 GHz gedrosselt werden. Daher können Arbeitslasten, die normalerweise etwa 30 %% der CPU-Leistung verbrauchen, aufgrund der reduzierten Taktgeschwindigkeit bis zu 100 %% Auslastung erreichen. Um eine konsistente und optimale Leistung für rechenintensive SQL Server-Workloads zu gewährleisten, empfehlen wir, das System für die Verwendung des Leistungsplans mit hoher Leistung zu konfigurieren. Diese Einstellung stellt sicher, dass die CPU mit der vollen Nenngeschwindigkeit arbeitet, was dazu beiträgt, Leistungsengpässe zu vermeiden. Weitere Informationen finden Sie unter "Langsame Leistung" unter Windows Server bei Verwendung des Leistungsplans "Ausgeglichen".
Schritt 10: Konfigurieren Des virtuellen Computers
Wenn Sie eine virtuelle Maschine verwenden, stellen Sie sicher, dass Sie ihr nicht zu viel CPU bereitstellen und dass sie korrekt konfiguriert ist. Weitere Informationen finden Sie unter Beheben von Leistungsproblemen mit virtuellen ESX-/ESXi-Computern (2001003).
Schritt 11: Skalieren des Systems zur Verwendung weiterer CPUs
Wenn einzelne Abfrageinstanzen wenig CPU-Kapazität verwenden, aber die Gesamtarbeitsauslastung aller Abfragen zusammen eine hohe CPU-Auslastung verursacht, sollten Sie eine Skalierung Ihres Computers erwägen, indem Sie weitere CPUs hinzufügen. Verwenden Sie die folgende Abfrage, um die Anzahl der Abfragen zu ermitteln, die einen bestimmten Schwellenwert für die durchschnittliche und maximale CPU-Auslastung pro Ausführung überschritten haben und viele Male auf dem System ausgeführt wurden (stellen Sie sicher, dass Sie die Werte der beiden Variablen entsprechend Ihrer Umgebung ändern):
-- Shows queries where Max and average CPU time exceeds 200 ms and executed more than 1000 times
DECLARE @cputime_threshold_microsec INT = 200*1000
DECLARE @execution_count INT = 1000
SELECT qs.total_worker_time/1000 total_cpu_time_ms,
qs.max_worker_time/1000 max_cpu_time_ms,
(qs.total_worker_time/1000)/execution_count average_cpu_time_ms,
qs.execution_count,
q.[text]
FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
WHERE (qs.total_worker_time/execution_count > @cputime_threshold_microsec
OR qs.max_worker_time > @cputime_threshold_microsec )
AND execution_count > @execution_count
ORDER BY qs.total_worker_time DESC
Siehe auch
- Hohe CPU- oder Speicherzuteilungen können bei Abfragen auftreten, die eine optimierte geschachtelte Schleife oder Batchsortierreihenfolge verwenden.
- Empfohlene Updates und Konfigurationsoptionen für SQL Server mit leistungsstarken Workloads
- Empfohlene Updates und Konfigurationsoptionen für SQL Server 2017 und 2016 mit leistungsstarken Workloads