Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Eine hochverfügbare geoverteilte Topologie bietet Folgendes:
- Beseitigung eines einzelnen Fehlerpunkts: Mit Failover-Funktionen können Sie eine hochverfügbare AD FS-Infrastruktur erreichen, auch wenn eines der Rechenzentren in einem Teil der Welt ausfällt.
- Verbesserte Leistung: Sie können die vorgeschlagene Bereitstellung verwenden, um eine leistungsfähige AD FS-Infrastruktur bereitzustellen.
AD FS kann für ein hochverfügbares, geografisch verteiltes Szenario konfiguriert werden. Im folgenden Leitfaden wird eine Übersicht über AD FS mit SQL Always on-Verfügbarkeitsgruppen erläutert und Bereitstellungsüberlegungen und Anleitungen bereitgestellt.
Übersicht – AlwaysOn-Verfügbarkeitsgruppen
Weitere Informationen zu AlwaysOn-Verfügbarkeitsgruppen finden Sie unter Übersicht über AlwaysOn-Verfügbarkeitsgruppen (SQL Server)
Aus Sicht der Knoten einer AD FS-SQL Server-Farm ersetzt die Always On-Verfügbarkeitsgruppe die einzelne SQL Server-Instanz als Richtlinien-/Artefaktdatenbank. Der Verfügbarkeitsgruppenlistener ist das, was der Client (der AD FS-Sicherheitstokendienst) verwendet, um eine Verbindung zu SQL herzustellen. Das folgende Diagramm zeigt eine AD FS SQL Server-Farm mit AlwaysOn-Verfügbarkeitsgruppe.
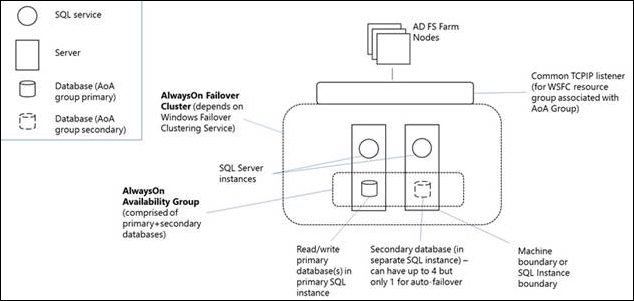
Eine Always On Availability Group (AG) ist eine oder mehrere Benutzerdatenbanken, die zusammen fehlschlagen. Eine Verfügbarkeitsgruppe besteht aus einem primären Verfügbarkeitsreplikat und einem bis vier sekundären Replikaten, die über die protokollbasierte Verschiebung von SQL Server-Daten für den Datenschutz verwaltet werden, ohne dass gemeinsam genutzter Speicher erforderlich ist. Jedes Replikat wird von einer Instanz von SQL Server auf einem anderen Knoten des WSFC gehostet. Die Verfügbarkeitsgruppe und ein entsprechender virtueller Netzwerkname werden als Ressourcen im WSFC-Cluster registriert.
Ein Verfügbarkeitsgruppenlistener auf dem Knoten des primären Replikats antwortet auf eingehende Clientanforderungen, um eine Verbindung mit dem Namen des virtuellen Netzwerks herzustellen, und basierend auf Attributen in der Verbindungszeichenfolge leitet er jede Anforderung an die entsprechende SQL Server-Instanz weiter. Im Falle eines Failovers wird WSFC genutzt, um anstelle der Übertragung des Besitzes freigegebener physischer Ressourcen auf einen anderen Knoten ein sekundäres Replikat in einer anderen SQL Server-Instanz so neu zu konfigurieren, dass es zum primären Replikat der Verfügbarkeitsgruppe wird. Die virtuelle Netzwerknamenressource der Verfügbarkeitsgruppe wird dann auf diese Instanz übertragen. Zu einem bestimmten Zeitpunkt kann nur eine einzelne SQL Server-Instanz das primäre Replikat der Datenbanken einer Verfügbarkeitsgruppe hosten, alle zugehörigen sekundären Replikate müssen sich jeweils in einer separaten Instanz befinden, und jede Instanz muss sich auf separaten physischen Knoten befinden.
Hinweis
Wenn Computer auf Azure ausgeführt werden, richten Sie die virtuellen Azure-Computer ein, um die Listenerkonfiguration für die Kommunikation mit AlwaysOn-Verfügbarkeitsgruppen zu aktivieren. Weitere Informationen finden Sie unter Virtuellen Maschinen: SQL Always On Listener.
Weitere Übersicht über AlwaysOn-Verfügbarkeitsgruppen finden Sie unter Übersicht über AlwaysOn-Verfügbarkeitsgruppen (SQL Server).
Hinweis
Wenn die Organisation Failover über mehrere Rechenzentren erfordert, empfiehlt es sich, eine Artefaktdatenbank in jedem Rechenzentrum zu erstellen sowie einen Hintergrundcache zu aktivieren, der die Latenz während der Anforderungsverarbeitung verringert. Befolgen Sie die Anweisungen, um dies in Feinabstimmung von SQL und Reduzierung der Latenz zu tun.
Bereitstellungsleitfaden
- Ziehen Sie die geeignete Datenbank für die Erreichung der Ziele der AD FS-Bereitstellung in Betracht. AD FS verwendet eine Datenbank zum Speichern der Konfiguration und in einigen Fällen Transaktionsdaten im Zusammenhang mit dem Verbunddienst. Sie können AD FS-Software verwenden, um entweder die interne Windows-Datenbank (WID) oder Microsoft SQL Server 2008 oder höher auszuwählen, um die Daten im Verbunddienst zu speichern. In der folgenden Tabelle werden die Unterschiede zwischen unterstützten Features zwischen einer WID- und SQL-Datenbank beschrieben.
| Kategorie | Merkmal | Unterstützt durch WID | Unterstützt von SQL |
|---|---|---|---|
| AD FS-Funktionen | Bereitstellung einer Verbundserverfarm | Ja | Ja |
| AD FS-Funktionen | SAML-Artefaktauflösung. Hinweis: Dies ist für SAML-Anwendungen nicht üblich. | Nein | Ja |
| AD FS-Funktionen | Token-Replay-Erkennung für den SAML-/WS-Verbund. Hinweis: Nur erforderlich, wenn AD FS Token von externen IDPs empfängt. Dies ist nicht erforderlich, wenn AD FS nicht als Verbundpartner fungiert. | Nein | Ja |
| Datenbankfunktionen | Grundlegende Datenbankredundanz mithilfe von Pull-Replikation, bei der ein oder mehrere Server, die eine schreibgeschützte Kopie der Datenbank hosten, Änderungen anfordern, die auf einem Quellserver vorgenommen wurden, der eine Lese-/Schreibkopie der Datenbank hostet. | Nein | Nein |
| Datenbankfunktionen | Datenbankredundanz mithilfe von Lösungen für hohe Verfügbarkeit, z. B. Clustering oder Spiegelung (auf Datenbankebene) | Nein | Ja |
| Zusätzliche Features | OAuth Authcode-Szenario | Ja | Ja |
Wenn Sie eine große Organisation mit mehr als 100 Vertrauensstellungen sind, die sowohl ihren internen Benutzern als auch externen Benutzern den Zugriff auf Verbundanwendungen oder -dienste mit einmaligem Anmelden ermöglichen müssen, ist SQL die empfohlene Option.
Wenn Sie eine Organisation mit 100 oder weniger konfigurierten Vertrauensstellungen sind, stellt WID Daten- und Verbunddienstredundanz bereit (wobei jeder Verbundserver Änderungen an anderen Verbundservern in derselben Farm repliziert). WID unterstützt weder die Erkennung der Token-Wiedergabe noch die Artefaktauflösung und hat einen Grenzwert von 30 Verbundservern. Weitere Informationen zur Planung Ihrer Bereitstellung finden Sie hier.
SQL Server Hochverfügbarkeitslösungen
Wenn Sie SQL Server als AD FS-Konfigurationsdatenbank verwenden, können Sie georedundanz für Ihre AD FS-Farm mithilfe der SQL Server-Replikation einrichten. Georedundanz repliziert Daten zwischen zwei geografisch entfernten Standorten, sodass Anwendungen von einem Standort zu einem anderen wechseln können. Auf diese Weise können Sie im Falle des Ausfalls eines Standorts weiterhin alle Konfigurationsdaten am zweiten Standort zur Verfügung haben. Wenn SQL die entsprechende Datenbank für Ihre Bereitstellungsziele ist, fahren Sie mit diesem Bereitstellungshandbuch fort.
Dieser Leitfaden führt Sie durch die folgenden Schritte:
- Bereitstellen von AD FS
- Konfigurieren von AD FS für die Verwendung von AlwaysOn-Verfügbarkeitsgruppen
- Installieren der Rolle „Failoverclustering“
- Ausführen von Clusterüberprüfungstests
- Aktivieren von AlwaysOn-Verfügbarkeitsgruppen
- Sichern von AD FS-Datenbanken
- Erstellen von AlwaysOn-Verfügbarkeitsgruppen
- Hinzufügen von Datenbanken auf dem zweiten Knoten
- Hinzufügen eines Verfügbarkeitsreplikats zu einer Verfügbarkeitsgruppe
- Aktualisieren der SQL-Verbindungszeichenfolge
Bereitstellen von AD FS
Hinweis
Wenn Computer auf Azure ausgeführt werden, müssen die virtuellen Computer auf eine bestimmte Weise konfiguriert werden, damit der Listener mit der AlwaysOn-Verfügbarkeitsgruppe kommunizieren kann. Informationen zur Konfiguration finden Sie unter Konfigurieren eines Lastenausgleichs für eine Verfügbarkeitsgruppe auf virtuellen Azure SQL Server-Computern
In diesem Bereitstellungshandbuch wird eine zwei Knotenfarm mit zwei SQL-Servern als Beispiel angezeigt. Um AD FS bereitzustellen, folgen Sie den folgenden anfänglichen Links, um den AD FS-Rollendienst zu installieren. Zum Konfigurieren einer AlwaysOn-Verfügbarkeitsgruppe werden zusätzliche Schritte für die Rolle ausgeführt.
- Hinzufügen eines Computers zu einer Domäne
- Registrieren eines SSL-Zertifikats für AD FS
- Installieren des AD FS-Rollendiensts
Konfigurieren von AD FS für die Verwendung einer AlwaysOn-Verfügbarkeitsgruppe
Das Konfigurieren einer AD FS-Farm mit AlwaysOn-Verfügbarkeitsgruppen erfordert eine geringfügige Änderung des AD FS-Bereitstellungsverfahrens. Stellen Sie sicher, dass jede Serverinstanz dieselbe Version von SQL ausführt. Eine vollständige Liste der Voraussetzungen, Einschränkungen und Empfehlungen für AlwaysOn-Verfügbarkeitsgruppen finden Sie hier.
- Die Datenbanken, die Sie sichern möchten, müssen erstellt werden, bevor die AlwaysOn-Verfügbarkeitsgruppen konfiguriert werden können. AD FS erstellt seine Datenbanken als Teil der Einrichtung und Erstkonfiguration des ersten Verbunddienstknotens einer neuen AD FS SQL Server-Farm. Geben Sie den Datenbankhostnamen für die vorhandene Farm mit SQL Server an. Im Rahmen der AD FS-Konfiguration müssen Sie eine SQL-Verbindungszeichenfolge angeben. Daher müssen Sie die erste AD FS-Farm so konfigurieren, dass eine direkte Verbindung mit einer SQL-Instanz hergestellt wird (dies ist nur temporär). Spezifische Anleitungen zum Konfigurieren einer AD FS-Farm, einschließlich der Konfiguration eines AD FS-Farmknotens mit einer SQL Server-Verbindungszeichenfolge, finden Sie unter Konfigurieren eines Verbundservers.
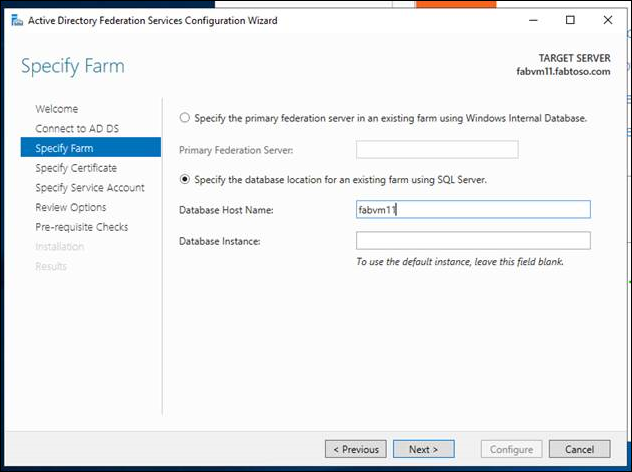
- Überprüfen Sie die Verbindung mit der Datenbank mithilfe von SSMS, und stellen Sie dann eine Verbindung mit dem Zieldatenbankhostnamen her. Wenn Sie der Verbundfarm einen weiteren Knoten hinzufügen, stellen Sie eine Verbindung mit der Zieldatenbank her.
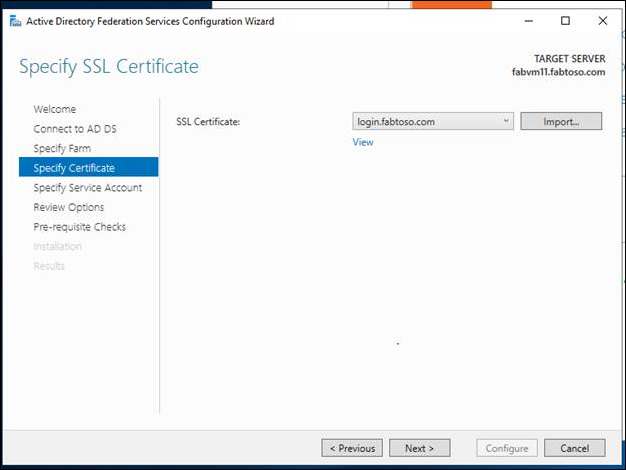
- Geben Sie das SSL-Zertifikat für die AD FS-Farm an.
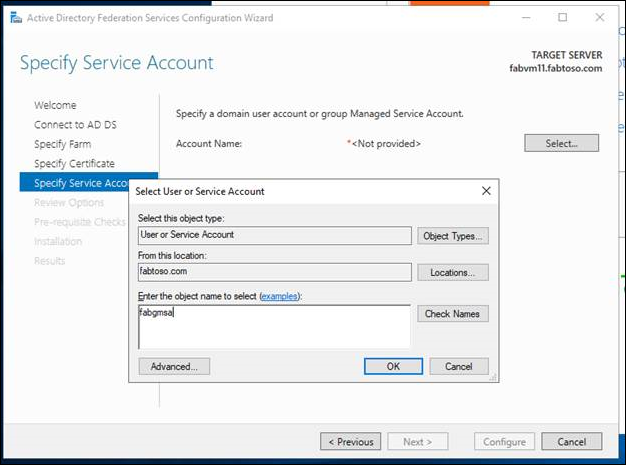
- Verbinden Sie die Farm mit einem Dienstkonto oder einem gruppenverwalteten Dienstkonto (Group Managed Service Account, gMSA).
- Schließen Sie die AD FS-Farmkonfiguration und -installation ab.
Hinweis
SQL Server muss unter einem Domänenkonto für die Installation von AlwaysOn-Verfügbarkeitsgruppen ausgeführt werden. Standardmäßig wird sie als lokales System ausgeführt.
Installieren der Rolle „Failoverclustering“
Die Rolle „Windows Server-Failovercluster“ ermöglicht das Failoverclustering.
- Starten Sie Server-Manager.
- Wählen Sie im Menü "Verwalten" die Option "Rollen und Features hinzufügen" aus.
- Wählen Sie auf der Seite "Vor Beginn" die Option "Weiter" aus.
- Wählen Sie auf der Seite "Installationstyp auswählen" die Option "Rollenbasierte oder featurebasierte Installation" und dann "Weiter" aus.
- Wählen Sie auf der Seite "Zielserver auswählen" den SQL-Server aus, auf dem Sie das Feature installieren möchten, und wählen Sie dann "Weiter" aus.
- Wählen Sie auf der Seite "Serverrollen auswählen" die Option "Weiter" aus.
- Aktivieren Sie auf der Seite „Features auswählen“ das Kontrollkästchen „Failoverclustering“.
- Wählen Sie auf der Seite "Installationsauswahl bestätigen" die Option "Installieren" aus. Das Failoverclustering-Feature erfordert keinen Neustart des Servers.
- Wenn die Installation abgeschlossen ist, wählen Sie "Schließen" aus.
- Wiederholen Sie diesen Vorgang auf jedem Server, den Sie als Failoverclusterknoten hinzufügen möchten.
Ausführen von Clusterüberprüfungstests
- Starten Sie den Failovercluster-Manager auf einem Computer, auf dem die Failovercluster-Verwaltungstools aus den Remoteserver-Verwaltungstools installiert sind, oder auf einem Server, auf dem Sie das Failoverclustering-Feature installiert haben. Um dies auf einem Server durchzuführen, starten Sie den Server-Manager, und wählen Sie dann im Menü "Extras" den Failovercluster-Manager aus.
- Wählen Sie im Bereich "Failovercluster-Manager" unter "Verwaltung" die Option "Konfiguration überprüfen" aus.
- Wählen Sie auf der Seite "Vor Beginn" die Option "Weiter" aus.
- Geben Sie auf der Seite "Server auswählen" oder auf der Seite "Cluster auswählen" im Feld "Namen eingeben" den NetBIOS-Namen oder den vollqualifizierten Domänennamen eines Servers ein, den Sie als Failoverclusterknoten hinzufügen möchten, und wählen Sie dann "Hinzufügen" aus. Wiederholen Sie diesen Schritt für alle weiteren Server, die Sie hinzufügen möchten. Wenn Sie mehrere Server gleichzeitig hinzufügen möchten, trennen Sie die Namen durch ein Komma oder Semikolon. Geben Sie beispielsweise die Namen im Format server1.contoso.com server2.contoso.com ein. Wenn Sie fertig sind, wählen Sie "Weiter" aus.
- Wählen Sie auf der Seite "Testoptionen" die Option "Alle Tests ausführen" aus (empfohlen), und wählen Sie dann "Weiter" aus.
- Wählen Sie auf der Bestätigungsseite "Weiter" aus. Auf der Seite zur Ausführung der Überprüfung wird der Status der aktiven Tests angezeigt.
- Führen Sie auf der Seite "Zusammenfassung" eine der folgenden Aktionen aus:
- Wenn die Ergebnisse angeben, dass die Tests erfolgreich abgeschlossen wurden und die Konfiguration für das Clustering geeignet ist und Sie den Cluster sofort erstellen möchten, stellen Sie sicher, dass das Kontrollkästchen "Cluster jetzt mit überprüften Knoten erstellen" aktiviert ist, und wählen Sie dann "Fertig stellen" aus. Fahren Sie dann mit Schritt 4 des Erstellens der Failoverclusterprozedur fort.
- Wenn die Ergebnisse darauf hinweisen, dass Warnungen oder Fehler aufgetreten sind, wählen Sie "Bericht anzeigen" aus, um die Details anzuzeigen und zu bestimmen, welche Probleme korrigiert werden müssen. Beachten Sie, dass eine Warnung für einen bestimmten Überprüfungstest darauf hinweist, dass dieser Aspekt des Failoverclusters unterstützt werden kann, aber möglicherweise nicht die empfohlenen bewährten Methoden erfüllt.
Hinweis
Wenn Sie eine Warnung für den Test "Validierung der persistenten Reservierung von Storage Spaces" erhalten, lesen Sie den Blogbeitrag Windows-Failovercluster-Validierungswarnung zeigt an, dass Ihre Datenträger die persistenten Reservierungen für Speicherplätze nicht unterstützen für weitere Informationen. Weitere Informationen zu Hardwareüberprüfungstests finden Sie unter Überprüfen der Hardware für einen Failovercluster.
Failover-Cluster erstellen
Um diesen Schritt abzuschließen, stellen Sie sicher, dass das Benutzerkonto, mit dem Sie sich anmelden, den Anforderungen entspricht, die im Abschnitt "Voraussetzungen überprüfen" dieses Themas beschrieben sind.
- Starten Sie Server-Manager.
- Wählen Sie im Menü "Werkzeuge" die Option "Failovercluster-Manager" aus.
- Wählen Sie im Bereich "Failovercluster-Manager" unter "Verwaltung" die Option "Cluster erstellen" aus. Der Clustererstellungs-Assistent wird geöffnet.
- Wählen Sie auf der Seite "Vor Beginn" die Option "Weiter" aus.
- Wenn die Seite "Server auswählen" angezeigt wird, geben Sie im Feld "Namen eingeben" den NetBIOS-Namen oder den vollqualifizierten Domänennamen eines Servers ein, den Sie als Failoverclusterknoten hinzufügen möchten, und wählen Sie dann "Hinzufügen" aus. Wiederholen Sie diesen Schritt für alle weiteren Server, die Sie hinzufügen möchten. Wenn Sie mehrere Server gleichzeitig hinzufügen möchten, trennen Sie die Namen durch ein Komma oder Semikolon. Geben Sie beispielsweise die Namen im Format server1.contoso.com ein; server2.contoso.com. Wenn Sie fertig sind, wählen Sie "Weiter" aus.
Hinweis
Wenn Sie sich entschieden haben, den Cluster unmittelbar nach dem Ausführen der Überprüfung im Konfigurationsprüfungsverfahren zu erstellen, wird die Seite "Server auswählen" nicht angezeigt. Die überprüften Knoten werden automatisch dem Assistenten zum Erstellen von Clustern hinzugefügt, sodass Sie sie nicht erneut eingeben müssen.
- Wenn Sie die Überprüfung zuvor übersprungen haben, wird die Seite "Überprüfungswarnung" angezeigt. Es wird dringend empfohlen, die Clustervalidierung auszuführen. Nur Cluster, die alle Validierungstests bestehen, werden von Microsoft unterstützt. Um die Überprüfungstests auszuführen, wählen Sie "Ja" und dann "Weiter" aus. Führen Sie den Konfigurationsüberprüfungs-Assistenten wie unter Überprüfen der Konfiguration beschrieben aus.
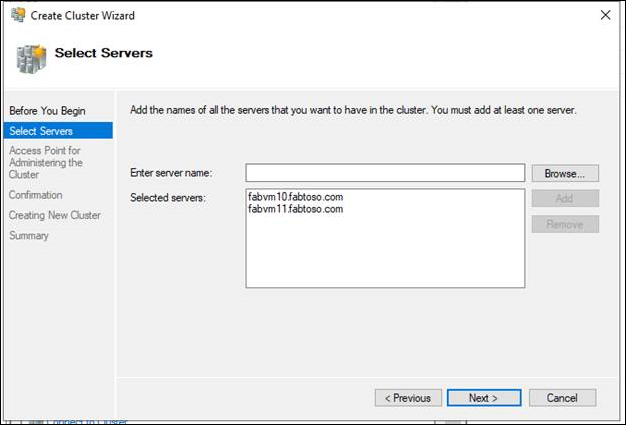
- Führen Sie auf der Seite "Access Point for Administering the Cluster" die folgenden Schritte aus:
- Geben Sie im Feld "Clustername" den Namen ein, den Sie zum Verwalten des Clusters verwenden möchten. Bevor Sie vorgehen, lesen Sie die folgenden Informationen:
- Während der Clustererstellung wird dieser Name als Clustercomputerobjekt (auch als Clusternamenobjekt oder CNO bezeichnet) in AD DS registriert. Wenn Sie einen NetBIOS-Namen für den Cluster angeben, wird der CNO an derselben Stelle erstellt, an der sich die Computerobjekte für die Clusterknoten befinden. Dies kann entweder der Standardcontainer "Computer" oder eine OU sein.
- Wenn Sie einen anderen Speicherort für das Clusternamenobjekt (CNO) angeben möchten, können Sie den Distinguished Name einer Organisationseinheit in das Feld „Clustername“ eingeben. Beispiel: CN=ClusterName, OU=Clusters, DC=Contoso, DC=com.
- Wenn ein Domänenadministrator den CNO in einer anderen Organisationseinheit als derjenigen, in der sich die Clusterknoten befinden, vorkonfiguriert hat, geben Sie den vom Domänenadministrator bereitgestellten distinguished name an.
- Wenn der Server nicht über einen für DHCP konfigurierten Netzwerkadapter verfügt, müssen Sie mindestens eine statische IP-Adresse für den Failovercluster konfigurieren. Aktivieren Sie das Kontrollkästchen neben den jeweiligen Netzwerkadaptern, die Sie für die Clusterverwaltung verwenden möchten. Wählen Sie das Feld "Adresse" neben einem ausgewählten Netzwerk aus, und geben Sie dann die IP-Adresse ein, die Sie dem Cluster zuweisen möchten. Diese IP-Adresse (oder Adressen) wird dem Clusternamen im Dns (Domain Name System) zugeordnet.
- Wenn Sie fertig sind, wählen Sie "Weiter" aus.
- Überprüfen Sie auf der Bestätigungsseite die Einstellungen. Standardmäßig ist das Kontrollkästchen "Alle berechtigten Speicher zum Cluster hinzufügen" aktiviert. Deaktivieren Sie dieses Kontrollkästchen, wenn Sie eine der folgenden Aktionen ausführen möchten:
- Sie möchten den Speicher später konfigurieren.
- Sie planen, gruppierte Speicherplätze über den Failovercluster-Manager oder die Failover-Clustering-Windows-PowerShell-Cmdlets zu erstellen und haben noch keine Speicherplätze in Datei- und Speicherdiensten erstellt. Weitere Informationen finden Sie unter Deploy Clustered Storage Spaces.
- Wählen Sie "Weiter" aus, um den Failovercluster zu erstellen.
- Vergewissern Sie sich auf der Seite "Zusammenfassung", dass der Failovercluster erfolgreich erstellt wurde. Wenn Warnungen oder Fehler aufgetreten sind, zeigen Sie die Zusammenfassungsausgabe an, oder wählen Sie "Bericht anzeigen" aus, um den vollständigen Bericht anzuzeigen. Wählen Sie Fertig stellenaus.
- Um zu bestätigen, dass der Cluster erstellt wurde, überprüfen Sie, ob der Clustername unter Failovercluster-Manager in der Navigationsstruktur aufgeführt ist. Sie können den Clusternamen erweitern und dann Elemente unter Knoten, Speicher oder Netzwerke auswählen, um die zugehörigen Ressourcen anzuzeigen. Beachten Sie, dass es einige Zeit dauern kann, bis der Clustername erfolgreich in DNS repliziert wurde. Wenn Sie nach erfolgreicher DNS-Registrierung und -Replikation alle Server im Server-Manager auswählen, sollte der Clustername als Server mit dem Status "Verwaltbarkeit" von "Online" aufgeführt werden.
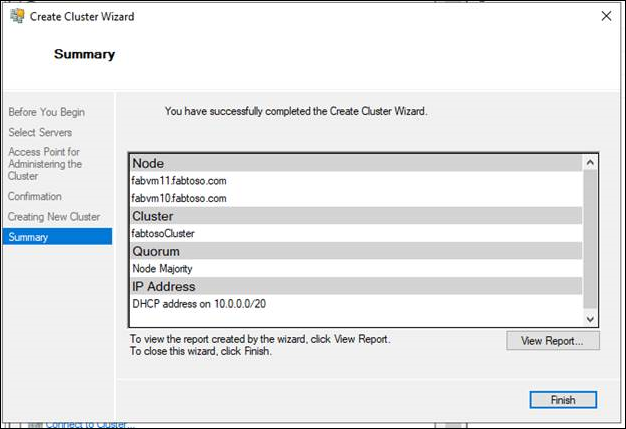
Aktivieren von Always On-Verfügbarkeitsgruppen mit SQL Server Configuration Manager
- Stellen Sie eine Verbindung mit dem WSFC-Knoten (Windows Server Failover Cluster) her, auf dem die SQL Server-Instanz gehostet wird, auf der Sie Always On-Verfügbarkeitsgruppen aktivieren möchten.
- Zeigen Sie im Startmenü auf "Alle Programme", zeigen Sie auf Microsoft SQL Server, zeigen Sie auf "Konfigurationstools", und klicken Sie auf "SQL Server Configuration Manager".
- Klicken Sie in SQL Server Configuration Manager auf SQL Server Services, klicken Sie mit der rechten Maustaste auf SQL Server (
<instance name>), wobei<instance name>es sich um den Namen einer lokalen Serverinstanz handelt, für die Sie AlwaysOn-Verfügbarkeitsgruppen aktivieren möchten, und klicken Sie auf "Eigenschaften". - Wählen Sie die Registerkarte „Hochverfügbarkeit mit Always On“ aus.
- Stellen Sie sicher, dass das Windows-Failoverclusternamenfeld den Namen des lokalen Failoverclusters enthält. Wenn dieses Feld leer ist, unterstützt diese Serverinstanz derzeit keine AlwaysOn-Verfügbarkeitsgruppen. Entweder ist der lokale Computer kein Clusterknoten, der WSFC-Cluster wurde heruntergefahren, oder diese Edition von SQL Server, die AlwaysOn-Verfügbarkeitsgruppen nicht unterstützt.
- Aktivieren Sie das Kontrollkästchen "AlwaysOn-Verfügbarkeitsgruppen aktivieren", und klicken Sie auf "OK". SQL Server -Konfigurations-Manager speichert die Änderung. Dann müssen Sie den SQL Server -Dienst manuell neu starten. Dies ermöglicht die Auswahl einer für die Geschäftsanforderungen optimalen Neustartzeit. Wenn der SQL Server-Dienst neu gestartet wird, wird Always On aktiviert, und die IsHadrEnabled-Servereigenschaft wird auf 1 festgelegt.
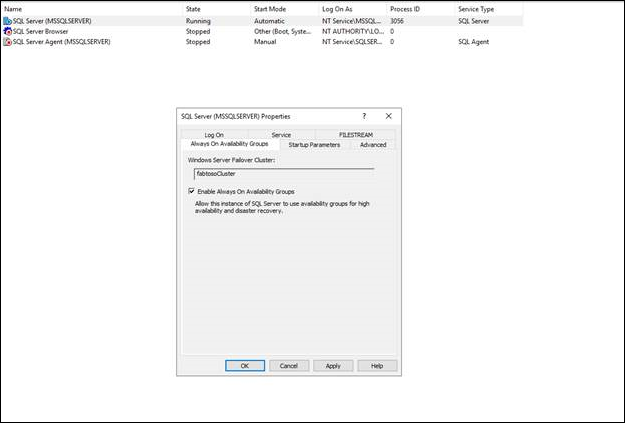
Sichern von AD FS-Datenbanken
Sichern Sie die AD FS-Konfigurations- und Artefaktdatenbanken mit den vollständigen Transaktionsprotokollen. Platzieren Sie die Sicherung im ausgewählten Ziel. Sichern Sie die AD FS-Artefakt- und Konfigurationsdatenbanken.
- Wählen Sie zum Erstellen „Aufgaben“ > „Sicherung“ > „Vollständig“ > „Zu Sicherungsdatei hinzufügen“ > „OK“ aus.
Neue Verfügbarkeitsgruppe erstellen
- Stellen Sie im Objekt-Explorer eine Verbindung mit der Serverinstanz her, die das primäre Replikat hostet.
- Erweitern Sie den Knoten „Hochverfügbarkeit mit Always On“ und den Knoten „Verfügbarkeitsgruppen“.
- Um den Assistenten für neue Verfügbarkeitsgruppen zu starten, wählen Sie den Befehl "Assistent für neue Verfügbarkeitsgruppen" aus.
- Wenn Sie den Assistenten zum ersten Mal ausführen, wird eine Einführungsseite angezeigt. Um diese Seite in Zukunft zu umgehen, können Sie auf "Diese Seite nicht mehr anzeigen" klicken. Klicken Sie nach dem Lesen dieser Seite auf "Weiter".
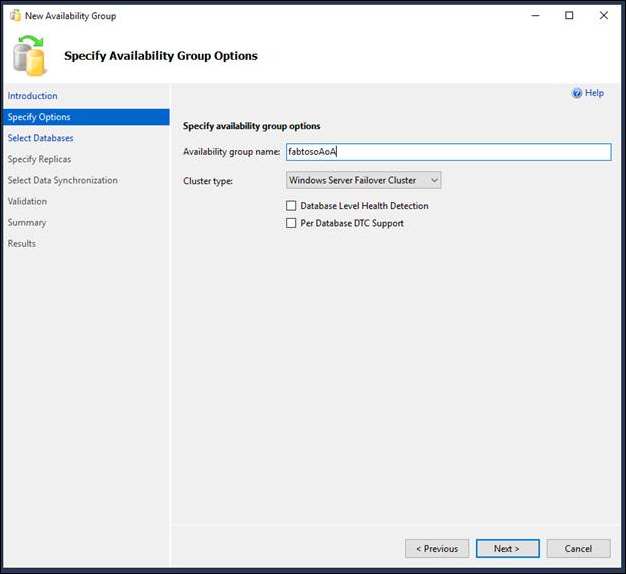
- Geben Sie auf der Seite "Verfügbarkeitsgruppenoptionen angeben" den Namen der neuen Verfügbarkeitsgruppe in das Feld "Name der Verfügbarkeitsgruppe" ein. Dieser Name muss ein gültiger SQL Server-Bezeichner sein, der auf dem Cluster und in der Domäne als Ganzes eindeutig ist. Die maximale Länge eines Verfügbarkeitsgruppennamens beträgt 128 Zeichen. e
- Geben Sie als nächstes den Clustertyp an. Die möglichen Clustertypen hängen von der SQL Server-Version und dem Betriebssystem ab. Wählen Sie entweder WSFC, EXTERNAL oder NONE aus. Ausführliche Informationen finden Sie auf der Seite " Verfügbarkeitsgruppenname angeben "
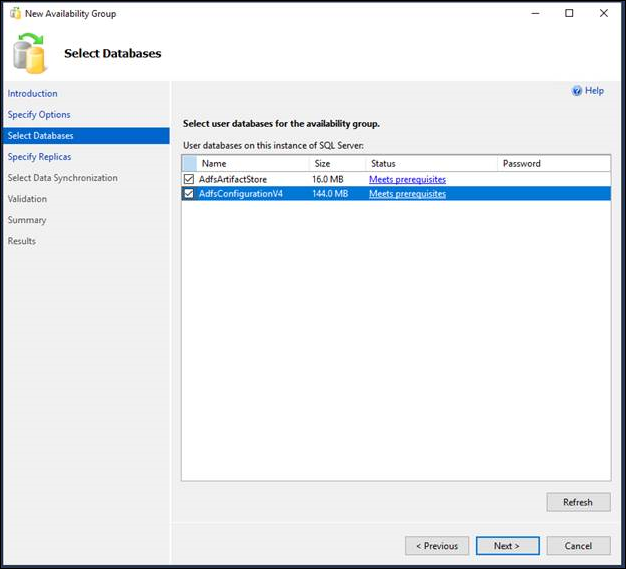
- Auf der Seite "Datenbanken auswählen" listet das Raster Benutzerdatenbanken auf der verbundenen Serverinstanz auf, die berechtigt sind, die Verfügbarkeitsdatenbanken zu werden. Wählen Sie eine oder mehrere der aufgelisteten Datenbanken aus, um diese in der Verfügbarkeitsgruppe zu verwenden. Diese Datenbanken sind zunächst die ersten primären Datenbanken. Für jede aufgelistete Datenbank zeigt die Spalte "Größe" die Datenbankgröße an, sofern bekannt. Die Spalte "Status" gibt an, ob eine bestimmte Datenbank die Voraussetzungen für Verfügbarkeitsdatenbanken erfüllt. Wenn die Voraussetzungen nicht erfüllt sind, gibt eine kurze Statusbeschreibung den Grund an, warum die Datenbank nicht zulässig ist; Wenn es z. B. nicht das vollständige Wiederherstellungsmodell verwendet. Klicken Sie auf die Statusbeschreibung, um weitere Informationen zu erhalten. Wenn Sie eine Datenbank so ändern, dass sie berechtigt ist, klicken Sie auf "Aktualisieren", um das Datenbankraster zu aktualisieren. Wenn die Datenbank einen Datenbankmasterschlüssel enthält, geben Sie das Kennwort für den Datenbankmasterschlüssel in der Spalte "Kennwort" ein.
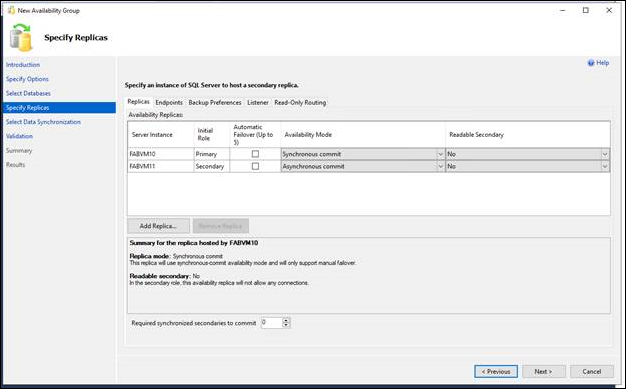
8.Geben Sie auf der Seite "Replikate angeben" ein oder mehrere Replikate für die neue Verfügbarkeitsgruppe an und konfigurieren sie. Diese Seite enthält vier Registerkarten. In der folgenden Tabelle werden diese Registerkarten eingeführt. Weitere Informationen finden Sie im Thema Seite „Replikate angeben“ (Assistent für neue Verfügbarkeitsgruppen/Assistent zum Hinzufügen von Replikaten).
| Registerkarte | Kurzbeschreibung |
|---|---|
| Replikate | Verwenden Sie diese Registerkarte, um jede Instanz von SQL Server anzugeben, die ein sekundäres Replikat hosten soll. Beachten Sie, dass die Serverinstanz, mit der Sie derzeit verbunden sind, das primäre Replikat hosten muss. |
| Endpunkte | Verwenden Sie diese Registerkarte, um vorhandene Endpunkte für die Datenbankspiegelung zu überprüfen, und wenn dieser Endpunkt auf einer Serverinstanz fehlt, deren Dienstkonten die Windows-Authentifizierung verwenden, um den Endpunkt automatisch zu erstellen. |
| Sicherungseinstellungen | Verwenden Sie diese Registerkarte, um Ihre Sicherungseinstellung für die Verfügbarkeitsgruppe als Ganzes und Ihre Sicherungsprioritäten für die einzelnen Verfügbarkeitsreplikate anzugeben. |
| Zuhörer | Verwenden Sie diese Registerkarte, um einen Verfügbarkeitsgruppenlistener zu erstellen. Standardmäßig erstellt der Assistent keinen Listener. |
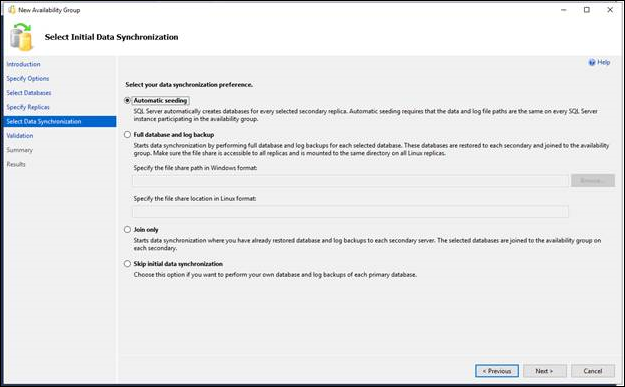
- Wählen Sie auf der Seite "Ursprüngliche Datensynchronisierung auswählen" aus, wie Ihre neuen sekundären Datenbanken erstellt und der Verfügbarkeitsgruppe hinzugefügt werden sollen. Wählen Sie eine der folgenden Optionen aus:
- Automatisches Seeding
- SQL Server erstellt die sekundären Replikate für jede Datenbank in der Gruppe automatisch. Automatisches Seeding erfordert, dass die Pfade für Daten- und Protokolldateien für jede SQL Server-Instanz der Gruppe identisch sind. Verfügbar auf SQL Server 2016 (13.x) und höher. Siehe "AlwaysOn-Verfügbarkeitsgruppen automatisch initialisieren".
- Vollständige Datenbank- und Protokollsicherung
- Wählen Sie diese Option aus, wenn Ihre Umgebung die Anforderungen für das automatische Starten der anfänglichen Datensynchronisierung erfüllt (weitere Informationen finden Sie weiter oben in diesem Thema unter "Voraussetzungen", "Einschränkungen" und "Empfehlungen"). Wenn Sie „Vollständig“ auswählen, sichert der Assistent nach der Erstellung der Verfügbarkeitsgruppe alle primären Datenbanken und ihre Transaktionsprotokolle auf einer Netzwerkfreigabe, und er stellt die Sicherungen auf allen Serverinstanzen, die ein sekundäres Replikat hosten, wieder her. Der Assistent verknüpft anschließend alle sekundären Datenbanken mit der Verfügbarkeitsgruppe. Geben Sie im Feld „Geben Sie einen freigegebenen Netzwerkpfad an, auf den alle Replikate Zugriff haben“ eine Sicherungsfreigabe an, für die alle Serverinstanzen, die Replikate hosten, Lese-/Schreibzugriff besitzen. Weitere Informationen finden Sie weiter oben in diesem Thema unter "Voraussetzungen". Im Validierungsschritt führt der Assistent Tests durch, um sicherzustellen, dass die angegebene Netzwerkadresse gültig ist. Durch den Test wird eine Datenbank mit dem Namen „BackupLocDb_“ gefolgt von einer GUID auf dem primären Replikat erstellt, und es wird eine Sicherung an der angegebenen Netzwerkadresse durchgeführt. Anschließend wird diese auf dem sekundären Replikat wiederherstellt. Sie können diese Datenbank, den zugehörigen Sicherungsverlauf und die Sicherungsdatei löschen, falls der Assistent sie nicht löschen konnte.
- Nur verknüpfen
- Wenn Sie sekundäre Datenbanken auf den Serverinstanzen, die die sekundären Replikate hosten, manuell vorbereitet haben, können Sie diese Option aktivieren. Der Assistent verknüpft die vorhandenen sekundären Datenbanken mit der Verfügbarkeitsgruppe.
- Ursprüngliche Datensynchronisierung überspringen
- Aktivieren Sie diese Option, wenn Sie eigene Datenbank- und Protokollsicherungen der primären Datenbanken verwenden möchten. Weitere Informationen finden Sie unter Starten der Datenbewegung auf einer Always On Sekundärdatenbank (SQL Server).
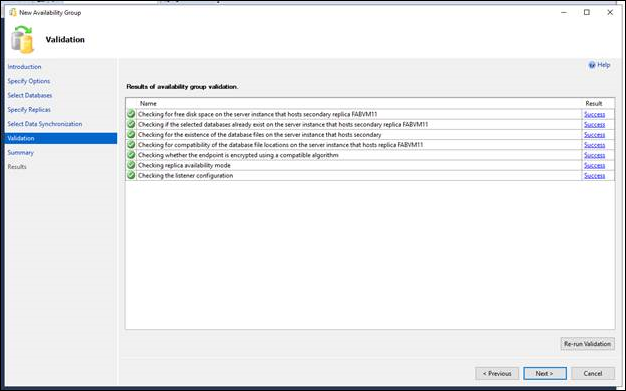
Auf der Seite "Überprüfung" wird überprüft, ob die Werte, die Sie in diesem Wizard angegeben haben, den Anforderungen des Wizards für neue Verfügbarkeitsgruppen entsprechen. Wenn Sie eine Änderung vornehmen möchten, klicken Sie auf "Zurück", um zu einer früheren Assistentenseite zurückzukehren, um einen oder mehrere Werte zu ändern. Klicken Sie auf "Weiter", um zur Seite "Überprüfung" zurückzukehren, und klicken Sie auf "Überprüfung erneut ausführen".
Überprüfen Sie auf der Seite "Zusammenfassung" Ihre Auswahlmöglichkeiten für die neue Verfügbarkeitsgruppe. Um eine Änderung vorzunehmen, klicken Sie auf "Zurück", um zur relevanten Seite zurückzukehren. Nachdem Sie die Änderung vorgenommen haben, klicken Sie auf "Weiter", um zur Seite "Zusammenfassung" zurückzukehren.
Hinweis
Wenn das SQL Server-Dienstkonto einer Serverinstanz, die ein neues Verfügbarkeitsreplikat hosten wird, noch nicht als Anmeldung vorhanden ist, muss der Assistent für neue Verfügbarkeitsgruppen die Anmeldung erstellen. Auf der Seite „Zusammenfassung“ des Assistenten werden die Informationen für den zu erstellenden Anmeldenamen angezeigt. Wenn Sie auf "Fertig stellen" klicken, erstellt der Assistent diese Anmeldung für das SQL Server-Dienstkonto und gewährt die Anmeldeberechtigung CONNECT. Wenn Sie mit Ihren Auswahlen zufrieden sind, klicken Sie optional auf "Skript", um ein Skript mit den Schritten zu erstellen, die der Assistent ausführt. Klicken Sie dann auf "Fertig stellen", um die neue Verfügbarkeitsgruppe zu erstellen und zu konfigurieren.
- Auf der Seite "Fortschritt" werden der Fortschritt der Schritte zum Erstellen der Verfügbarkeitsgruppe angezeigt (Konfigurieren von Endpunkten, Erstellen der Verfügbarkeitsgruppe und Verknüpfen des sekundären Replikats zur Gruppe).
- Nach Abschluss dieser Schritte zeigt die Seite "Ergebnisse" das Ergebnis der einzelnen Schritte an. Wenn all diese Schritte erfolgreich sind, ist die neue Verfügbarkeitsgruppe vollständig konfiguriert. Wenn einer der Schritte zu einem Fehler führt, müssen Sie die Konfiguration möglicherweise manuell abschließen oder einen Assistenten für den fehlerhaften Schritt ausführen. Wenn Sie Informationen zur Ursache eines bestimmten Fehlers erhalten möchten, klicken Sie in der Spalte "Ergebnis" auf den zugeordneten Link "Fehler". Klicken Sie nach Abschluss des Assistenten auf „Schließen“, um den Assistenten zu beenden.
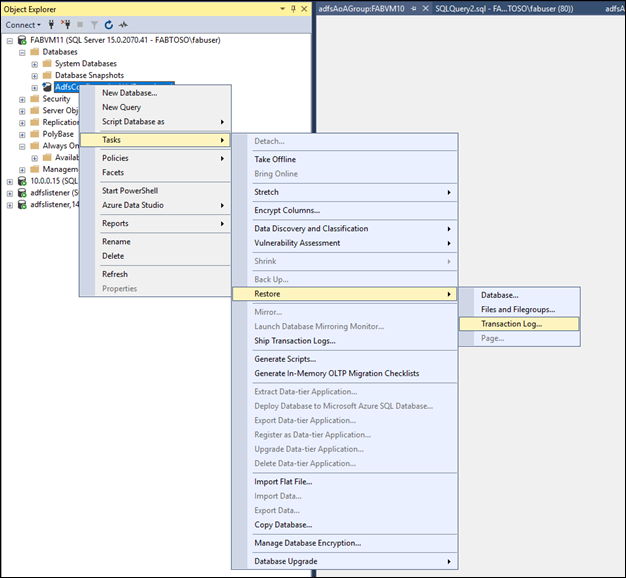
Hinzufügen von Datenbanken auf sekundären Knoten
Stellen Sie die Artefaktdatenbank über die Benutzeroberfläche auf dem sekundären Knoten mithilfe der erstellten Sicherungsdateien wieder her.
Stellen Sie die Datenbank in einem NON-RECOVERY Zustand wieder her.
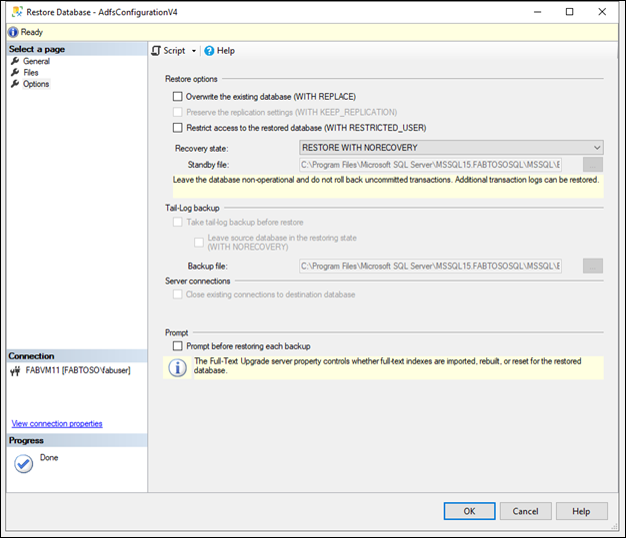
Wiederholen Sie den Vorgang, um die Konfigurationsdatenbank wiederherzustellen.
Hinzufügen eines Verfügbarkeitsreplikats zu einer Verfügbarkeitsgruppe
- Stellen Sie im Objekt-Explorer eine Verbindung mit der Serverinstanz her, die das sekundäre Replikat hostet, und klicken Sie auf den Servernamen, um die Serverstruktur zu erweitern.
- Erweitern Sie den Knoten „Hochverfügbarkeit mit Always On“ und den Knoten „Verfügbarkeitsgruppen“.
- Wählen Sie die Verfügbarkeitsgruppe des sekundären Replikats aus, mit dem Sie verbunden sind.
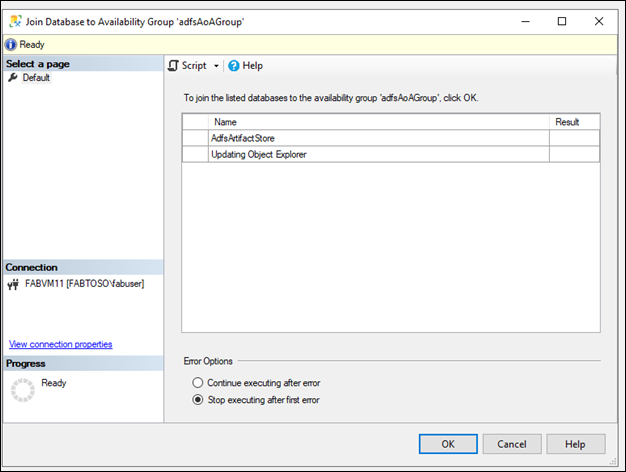
- Klicken Sie mit der rechten Maustaste auf das sekundäre Replikat, und klicken Sie auf "Zur Verfügbarkeitsgruppe beitreten".
- Das Dialogfeld „Replikat mit Verfügbarkeitsgruppe verknüpfen“ wird geöffnet.
- Klicken Sie auf „OK“, um das sekundäre Replikat mit der Verfügbarkeitsgruppe zu verknüpfen.
Aktualisieren der SQL-Verbindungszeichenfolge
Verwenden Sie schließlich PowerShell, um die AD FS-Eigenschaften zu bearbeiten, um die SQL-Verbindungszeichenfolge zu aktualisieren, um die DNS-Adresse des Listeners der AlwaysOn-Verfügbarkeitsgruppe zu verwenden. Führen Sie die Konfigurationsdatenbankänderung für jeden Knoten aus, und starten Sie den AD FS-Dienst auf allen AD FS-Knoten neu. Der anfängliche Katalogwert ändert sich je nach Farmversion.
PS:\>$temp= Get-WmiObject -namespace root/ADFS -class SecurityTokenService
PS:\>$temp.ConfigurationdatabaseConnectionstring=”data source=<SQLCluster\SQLInstance>; initial catalog=adfsconfiguration;integrated security=true”
PS:\>$temp.put()
PS:\> Set-AdfsProperties –artifactdbconnection ”Data source=<SQLCluster\SQLInstance >;Initial Catalog=AdfsArtifactStore;Integrated Security=True”