Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Du kannst eine Notfallwiederherstellung für die Remotedesktopdienste-Bereitstellung (Remote Desktop Services, RDS) einrichten, indem du mehrere Rechenzentren in Azure nutzt. Im Gegensatz zu einer standardmäßigen hoch verfügbaren RDS-Bereitstellung (wie in der Architektur der Remotedesktopdienste beschrieben), bei der Rechenzentren in einer einzigen Azure-Region (z.B. „Europa, Westen“) genutzt werden, verwendet eine georedundante Bereitstellung mehrere Rechenzentren in mehreren geografischen Regionen. Dadurch wird die Verfügbarkeit der gesamten Bereitstellung erhöht: Es kann passieren, dass ein Azure-Rechenzentrum nicht mehr verfügbar ist, aber dass mehrere Regionen gleichzeitig ausfallen, ist höchst unwahrscheinlich. Durch Bereitstellung einer georedundanten RDS-Architektur kannst du ein Failover aktivieren, falls eine komplette Region vollständig ausfallen sollte.
Mit der unten stehenden Anleitung kannst du die Microsoft Azure-Infrastrukturdienste und die Remotedesktopdienste nutzen, um über das Microsoft SPLA-Programm (Service Provider License Agreement) georedundante Desktophostingdienste und Abonnentenzugriffslizenzen (Subscriber Access Licenses, SALs) auf mehreren Mandanten bereitzustellen. Du kannst die Schritte auch nutzen, um über erweiterte Rechte für RDS-Benutzer-CALs durch Software Assurance einen georedundanten Hostingdienst für deine eigenen Mitarbeiter zu erstellen.
Logische Architektur für Hochverfügbarkeit – in einzelnen oder mehreren Regionen
Die folgende Abbildung zeigt die Architektur für eine hoch verfügbare Bereitstellung in einer einzelnen Azure-Region:
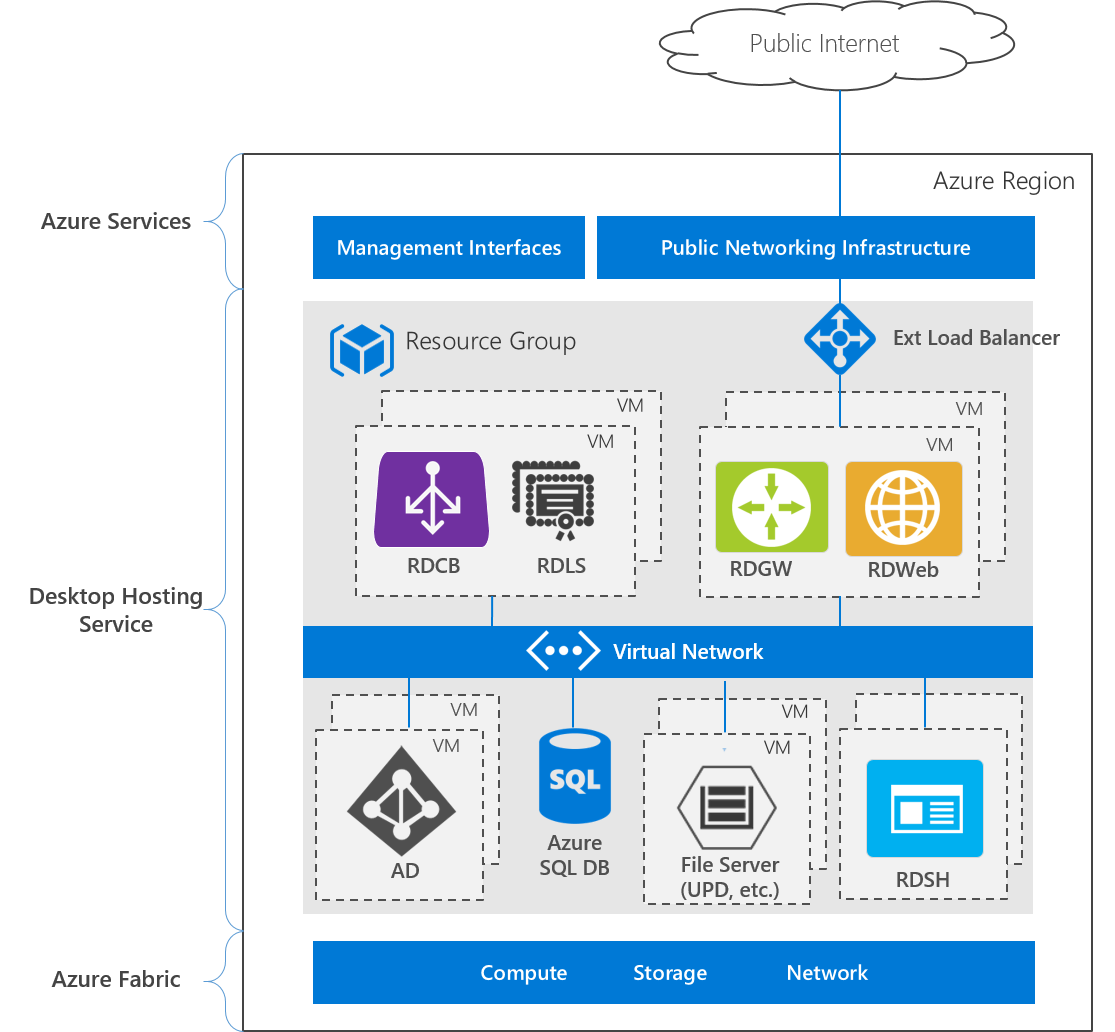
Die Bereitstellung besteht aus drei Ebenen:
- Azure-Dienste: die Azure-Verwaltungsschnittstellen, einschließlich Azure-Portal und APIs, sowie öffentliche Netzwerkdienste wie DNS und öffentliche IP-Adressen.
- Desktophostingdienste: virtuelle Computer, Netzwerke, Speicher, Azure-Dienste und Windows Server-Rollendienste.
- Azure Fabric: Windows Server-Betriebssysteme mit Hyper-V-Rolle, die zum Virtualisieren von physischen Servern, Speichereinheiten, Netzwerkswitches und Routern verwendet werden. Mit Azure Fabric kannst du VMs, Netzwerke, Speicher und Anwendungen unabhängig von der zugrunde liegenden Hardware erstellen.
Im Vergleich dazu zeigt die folgende Abbildung die Architektur für eine Bereitstellung mit mehreren Azure-Rechenzentren:
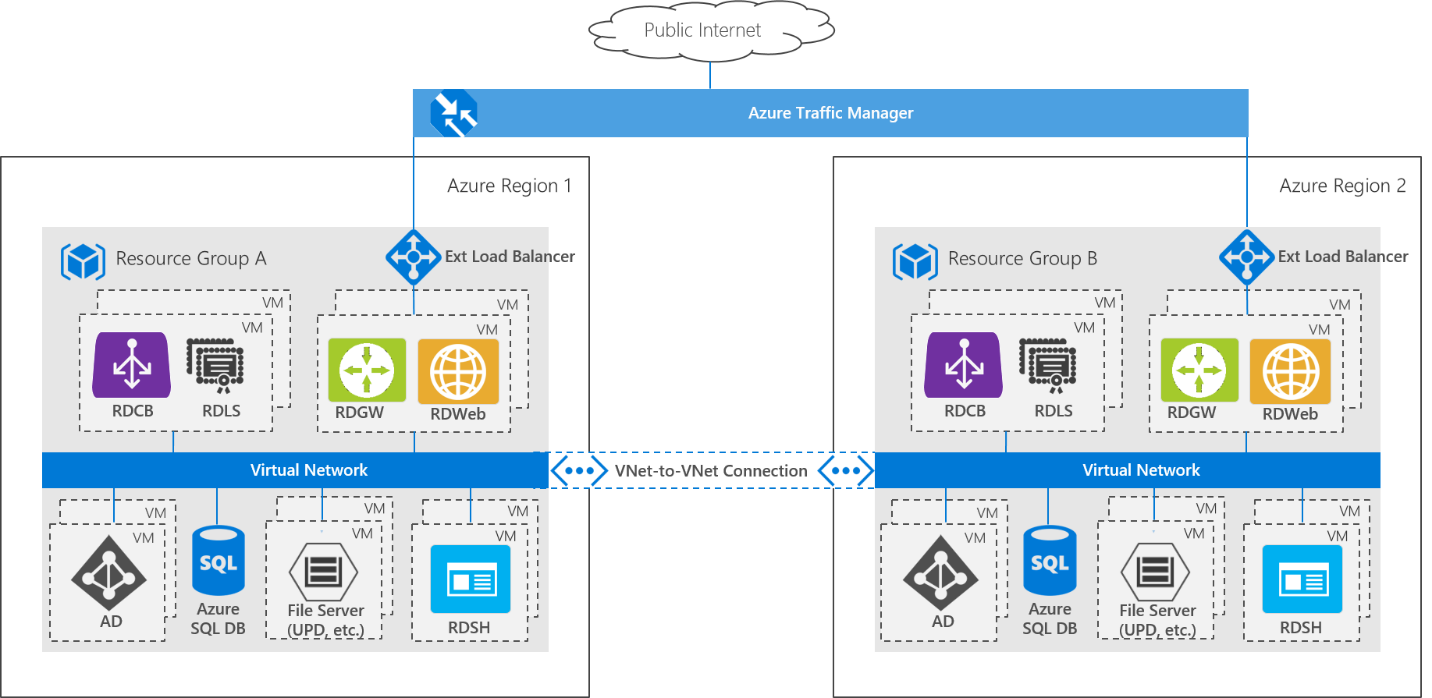
Die gesamte RDS-Bereitstellung wird in einer zweiten Azure-Region repliziert, sodass eine georedundante Bereitstellung entsteht. Diese Architektur verwendet ein Aktiv-Passiv-Modell, bei dem nur jeweils eine RDS-Bereitstellung ausgeführt wird. Eine VNET-to-VNET-Verbindung ermöglicht die Kommunikation zwischen den beiden Umgebungen. Die RDS-Bereitstellungen basieren auf einer einzelnen Active Directory-Gesamtstruktur bzw. -Domäne, und die AD-Server führen die Replikation zwischen den beiden Bereitstellungen aus. Das bedeutet, dass Benutzer sich mit den gleichen Anmeldeinformationen bei beiden Bereitstellungen anmelden können. Benutzereinstellungen und Daten auf Benutzerprofil-Datenträgern (User Profile Disks, UPDs) werden auf einem aus zwei Knoten bestehenden Scale-Out-Dateiclusterserver (Scale-Out File Server, SOFS) mit direkten Speicherplätzen gespeichert. In der zweiten (passiven) Region wird ein zweiter, identischer Cluster mit direkten Speicherplätzen bereitgestellt, und die Benutzerprofile werden mithilfe von Speicherreplikaten von der aktiven in die passive Bereitstellung repliziert. Endbenutzer werden mithilfe von Azure Traffic Manager an diejenige Bereitstellung weitergeleitet, die gerade aktiv ist. Aus Perspektive der Endbenutzer greifen diese über eine einzelne URL auf die Bereitstellung zu und erfahren nicht, welche Region sie letztendlich nutzen.
Sie könnten eine nicht hoch verfügbare RDS-Bereitstellung in jeder Region erstellen, aber wenn selbst eine einzelne VM in einer Region neu gestartet wird, tritt ein Failover auf, wodurch die Wahrscheinlichkeit erhöht wird, dass Failover mit den damit verbundenen Leistungseinbußen auftreten.
Bereitstellungsschritte
Erstelle die folgenden Ressourcen in Azure, um eine georedundante RDS-Bereitstellung mit mehreren Rechenzentren aufzubauen:
Zwei Ressourcengruppen in zwei separaten Azure-Regionen. Beispielsweise RG A (die aktive Bereitstellung, RG bedeutet „Ressourcengruppe“) und RG B (die passive Bereitstellung).
Eine hoch verfügbare Active Directory-Bereitstellung in RG A. Du kannst die Vorlage Create an new AD Domain with 2 Domain Controllers (Neue AD-Domäne mit zwei Domänencontrollern erstellen) verwenden, um die Bereitstellung zu erstellen.
Eine hoch verfügbare RDS-Bereitstellung in RG A. Verwende die Vorlage RDS farm deployment using existing active directory (Bereitstellung einer RDS-Farm über eine vorhandene Active Directory-Instanz), um die grundlegende RDS-Bereitstellung zu erstellen. Befolge dann die Anweisungen in Remote Desktop Services – hohe Verfügbarkeit, um die anderen RDS-Komponenten im Hinblick auf Hochverfügbarkeit zu konfigurieren.
Ein VNET in RG B: Stelle sicher, dass du einen Adressraum verwendest, der sich nicht mit der Bereitstellung in RG A überschneidet.
Eine VNet-zu-VNet-Verbindung zwischen den beiden Ressourcengruppen.
Zwei virtuelle AD-Computer in einer Verfügbarkeitsgruppe in RG B: Stelle sicher, dass die VM-Namen sich von den AD-VMs in RG A unterscheiden. Stelle zwei Windows Server 2016-VMs in einer einzelnen Verfügbarkeitsgruppe bereit, installiere die Active Directory Domain Services-Rolle, und stufe die VMs dann zum Domänencontroller in der in Schritt 1 erstellten Domäne hoch.
Eine zweite hoch verfügbare RDS-Bereitstellung in RG B.
- Verwende erneut die Vorlage RDS farm deployment using existing active directory (Bereitstellung einer RDS-Farm über eine vorhandene Active Directory-Instanz), nimm aber diesmal die folgenden Änderungen vor. (Um die Vorlage anzupassen, wähle sie im Katalog aus, und klicke auf In Azure bereitstellen und dann auf Vorlage bearbeiten.)
Ändere den Adressraum der privaten IP-Adresse des DNS-Servers so, dass er dem VNET in RG B entspricht.
Suche in Variablen nach „dnsServerPrivateIp“. Bearbeite die Standardadresse (10.0.0.4) so, dass sie dem im VNET in RG B definierten Adressraum entspricht.
Bearbeite die Computernamen, sodass keine Konflikte mit den Namen in der Bereitstellung in RG A entstehen.
Suchen Sie die virtuellen Computer im Abschnitt "Ressourcen " der Vorlage. Ändern Sie das Feld "computerName " unter "osProfile". Beispielsweise kann "Gateway" zu "gateway-b" werden; "[concat('rdsh-', copyIndex())]" kann zu "[concat('rdsh-b-', copyIndex())]" werden, und "broker" kann zu "broker-b" werden.
(Du kannst die Namen der VMs auch nach dem Ausführen der Vorlage manuell ändern.)
- Verwende wie in Schritt 3 oben die Informationen in Remote Desktop Services – hohe Verfügbarkeit, um die anderen RDS-Komponenten im Hinblick auf Hochverfügbarkeit zu konfigurieren.
- Verwende erneut die Vorlage RDS farm deployment using existing active directory (Bereitstellung einer RDS-Farm über eine vorhandene Active Directory-Instanz), nimm aber diesmal die folgenden Änderungen vor. (Um die Vorlage anzupassen, wähle sie im Katalog aus, und klicke auf In Azure bereitstellen und dann auf Vorlage bearbeiten.)
Ein Scale-Out-Dateiserver mit direkten Speicherplätzen und Speicherreplikaten über die beiden Bereitstellungen hinweg. Verwenden Sie das PowerShell-Skript , um die Vorlage in den Ressourcengruppen bereitzustellen.
Note
Du kannst den Speicher auch manuell bereitstellen (anstatt das PowerShell-Skript und eine Vorlage zu verwenden):
- Stelle einen Scale-Out-Dateiserver mit direkten Speicherplätzen und zwei Knoten in RG A bereit, um die Benutzerprofil-Datenträger (User Profile Disks, UPDs) zu speichern.
- Stelle einen zweiten, identischen Scale-Out-Dateiserver mit direkten Speicherplätzen in RG B bereit, und stelle sicher, dass in jedem Cluster die gleiche Menge an Speicherplatz verwendet wird.
- Richte ein Speicherreplikat mit asynchroner Replikation zwischen beiden ein.
Aktivieren von UPDs
Das Speicherreplikat repliziert Daten aus einem Quellvolume (das der primären bzw. aktiven Bereitstellung zugeordnet ist) in ein Zielvolume (das der sekundären bzw. passiven Bereitstellung zugeordnet ist). Programmbedingt wird der Zielcluster als online (kein Zugriff) angezeigt. Das Speicherreplikat hebt die Bereitstellung der Zielvolumes und der zugehörigen Laufwerkbuchstaben oder Bereitstellungspunkte auf. Das bedeutet, dass die Aktivierung von UPDs für die sekundäre Bereitstellung durch Angabe des Dateifreigabepfad nicht funktioniert, weil das Volume nicht eingebunden ist.
Möchtest du mehr über das Verwalten der Replikation erfahren? Dann lies den Artikel Cluster-zu-Cluster-Speicherreplikation.
Führe zum Aktivieren von UPDs in beiden Bereitstellungen folgende Schritte aus:
Führen Sie das CmdletSet-RDSessionCollectionConfiguration aus, um die Benutzerprofildatenträger für die primäre (aktive) Bereitstellung zu aktivieren. Geben Sie einen Pfad zur Dateifreigabe auf dem Quellvolume an (die Sie in Schritt 7 in den Bereitstellungsschritten erstellt haben).
Kehre die Richtung des Speicherreplikats um, sodass das Zielvolume zum Quellvolume wird (dadurch wird das Volume eingebunden, und die sekundäre Bereitstellung kann darauf zugreifen). Dazu können Sie das Cmdlet Set-SRPartnership ausführen. Beispiel:
Set-SRPartnership -NewSourceComputerName "cluster-b-s2d-c" -SourceRGName "cluster-b-s2d-c" -DestinationComputerName "cluster-a-s2d-c" -DestinationRGName "cluster-a-s2d-c"Aktiviere die Benutzerprofil-Datenträger in der sekundären (passiven) Bereitstellung. Führe die gleichen Aktionen aus wie für die primäre Bereitstellung in Schritt 1.
Kehre die Richtung des Speicherreplikats erneut um, sodass das ursprüngliche Quellvolume wieder zum Quellvolume in der Speicherreplikat-Partnerschaft wird. Nun kann die primäre Bereitstellung auf die Dateifreigabe zugreifen. Beispiel:
Set-SRPartnership -NewSourceComputerName "cluster-a-s2d-c" -SourceRGName "cluster-a-s2d-c" -DestinationComputerName "cluster-b-s2d-c" -DestinationRGName "cluster-b-s2d-c"
Azure Traffic Manager
Erstelle ein Azure Traffic Manager-Profil, und wähle die Routingmethode Priorität aus. Lege die beiden Endpunkte auf die öffentlichen IP-Adressen jeder Bereitstellung fest. Ändern Sie unter "Konfiguration" das Protokoll in HTTPS (anstelle von HTTP) und den Port zu 443 (anstelle von 80). Lege die DNS-Gültigkeitsdauer auf einen für deine Failoveranforderungen geeigneten Wert fest.
Beachte, dass Endpunkte bei GET-Anforderungen „200 OK“ zurückgeben müssen, um von Traffic Manager als „fehlerfrei“ markiert zu werden. Das aus den RDS-Vorlagen erstellte publicIP-Objekt funktioniert. Füge jedoch keinen Pfadzusatz hinzu. Stattdessen kannst du Endbenutzern die Traffic Manager-URL mit angefügtem „/RDWeb“ zur Verfügung stellen, z. B.: http://deployment.trafficmanager.net/RDWeb.
Durch Bereitstellung von Azure Traffic Manager mit der prioritätsbasierten Routingmethode verhinderst du, dass Endbenutzer auf die passive Bereitstellung zugreifen, während die aktive Bereitstellung funktionsfähig ist. Wenn Endbenutzer auf die passive Bereitstellung zugreifen und die Richtung des Speicherreplikats nicht zum Failover geändert wurde, reagiert die Benutzeranmeldung nicht, weil die Bereitstellung erfolglos versucht, auf dem passiven Cluster mit direkten Speicherplätzen auf die Dateifreigabe zuzugreifen. Letztendlich erhält der Benutzer ein temporäres Profil.
Aufheben der Zuordnung von VMs zum Einsparen von Ressourcen
Nachdem du beide Bereitstellungen konfiguriert hast, kannst du optional die sekundäre RDS-Infrastruktur und die sekundären RDSH-VMs herunterfahren und die Zuordnung aufheben, um die Kosten für diese VMs zu sparen. Die Scale-Out-Dateiserver mit direkten Speicherplätzen und die AD-Server-VMs müssen in der sekundären bzw. passiven Bereitstellung immer ausgeführt werden, um die Synchronisierung von Benutzerkonto und Benutzerprofil zu ermöglichen.
Wenn ein Failover auftritt, musst du die VMs, deren Zuordnung aufgehoben wurde, starten. Diese Bereitstellungskonfiguration ist kostengünstiger, benötigt aber mehr Zeit für ein Failover. Bei einem schwerwiegenden Ausfall der aktiven Umgebung musst du die passive Bereitstellung manuell starten oder benötigst ein Automatisierungsskript, das den Ausfall erkennt und die passive Bereitstellung automatisch startet. In beiden Fällen kann es mehrere Minuten dauern, bis die passive Bereitstellung ausgeführt wird und Benutzern für die Anmeldung zur Verfügung steht. Dadurch können Ausfallzeiten für den Dienst entstehen. Die Länge dieser Ausfallzeit hängt davon ab, wie lange es dauert, die RDS-Infrastruktur und die RDSH-VMs neu zu starten (in der Regel zwei bis vier Minuten, wenn die VMs nicht seriell, sondern parallel gestartet werden) und den passiven Cluster online zu schalten (dies wiederum hängt von der Größe des Clusters ab – in der Regel sind bei einem Cluster mit zwei Knoten und zwei Datenträgern pro Knoten zwei bis vier Minuten zu veranschlagen).
Active Directory
Die Active Directory-Server in den Bereitstellungen sind Replikate innerhalb der gleichen Gesamtstruktur bzw. Domäne. Active Directory verfügt über ein integriertes Synchronisierungsprotokoll, um die vier Domänencontroller zu synchronisieren. Es können jedoch Verzögerungen auftreten. Wenn also ein neuer Benutzer zu einem AD-Server hinzugefügt wird, kann es eine Weile dauern, bis dieser auf allen AD-Servern in beiden Bereitstellungen repliziert ist. Benutzer sollten daher nicht sofort versuchen, sich anzumelden, nachdem sie der Domäne hinzugefügt wurden.
RD-Lizenzserver
Stelle eine RD-Lizenz pro Benutzer für jeden benannten Benutzer bereit, der für den Zugriff auf die georedundante Bereitstellung autorisiert ist. Verteile die CALs pro Benutzer gleichmäßig auf die beiden RD-Lizenzserver in der aktiven Bereitstellung. Dupliziere diese CALs dann auf die beiden RD-Lizenzserver in der passiven Bereitstellung. Da die CALs zwischen der aktiven und der passiven Bereitstellung dupliziert sind, kann zu jedem Zeitpunkt nur eine Bereitstellung aktiv sein, mit der Benutzer eine Verbindung herstellen. Andernfalls besteht ein Verstoß gegen die Lizenzvereinbarung.
Bildverwaltung
Beim Aktualisieren von RDSH-Images zum Bereitstellen von Softwareupdates oder neuen Anwendungen musst du die RDSH-Sammlungen in jeder Bereitstellung separat aktualisieren, um ein einheitliches Benutzererlebnis in beiden Bereitstellungen beizubehalten. Du kannst die Vorlage Update RDSH collection (RDSH-Sammlung aktualisieren) verwenden, beachte aber, dass die RDS-Infrastruktur-VMs und RDSH-VMs der passiven Bereitstellung ausgeführt werden müssen, damit die Vorlage ausgeführt werden kann.
Failover
Im Fall der Aktiv-Passiv-Bereitstellung ist es für ein Failover erforderlich, die VMs der sekundären Bereitstellung zu starten. Du kannst dies manuell oder mit einem Automatisierungsskript durchführen. Sollte ein schwerwiegender Ausfall des Scale-Out-Dateiservers mit direkten Speicherplätzen eintreten, ändere die Richtung der Speicherreplikat-Partnerschaft, sodass das Zielvolume zum Quellvolume wird. Beispiel:
Set-SRPartnership -NewSourceComputerName "cluster-b-s2d-c" -SourceRGName "cluster-b-s2d-c" -DestinationComputerName "cluster-a-s2d-c" -DestinationRGName "cluster-a-s2d-c"
Mehr dazu erfährst du im Artikel Cluster-zu-Cluster-Speicherreplikation.
Azure Traffic Manager erkennt automatisch, dass die primäre Bereitstellung ausgefallen und die sekundäre Bereitstellung fehlerfrei ist (wenn die RD-Gateway-VMs in RG B gestartet wurden), und leitet den Benutzerdatenverkehr an die sekundäre Bereitstellung weiter. Benutzer können die gleiche Traffic Manager-URL verwenden, um weiter an ihren Remoteressourcen zu arbeiten, und profitieren von einem konsistenten Benutzererlebnis. Beachte, dass der DNS-Clientcache den Datensatz während der in der Azure Traffic Manager-Konfiguration festgelegten Gültigkeitsdauer nicht aktualisiert.
Testen des Failovers
In einer Speicherreplikat-Partnerschaft kann immer nur ein Volume (die Quelle) aktiv sein. Das bedeutet Folgendes: Wenn du die Richtung der Speicherreplikat-Partnerschaft änderst, wird das Volume in der primären Bereitstellung (RG A) zum Ziel der Replikation und wird daher ausgeblendet. Daher haben Benutzer, die eine Verbindung mit RG A herstellen, keinen Zugriff mehr auf ihre Benutzerprofil-Datenträger, die auf dem Scale-Out-Dateiserver in RG A gespeichert sind.
So testest du das Failover und ermöglichst Benutzern weiterhin die Anmeldung:
Starte die Infrastruktur-VMs und die RDSH-VMs in RG B.
Ändere die Richtung der Speicherreplikat-Partnerschaft („cluster-b-s2d-c“ wird zum Quellvolume).
Deaktiviere den Endpunkt von RG A im Azure Traffic Manager-Profil, um Azure Traffic Manager zu zwingen, Datenverkehr an RG B weiterzuleiten. Alternativ dazu kannst du auch ein PowerShell-Skript verwenden:
Disable-AzureRmTrafficManagerEndpoint -Name publicIpA -Type AzureEndpoints -ProfileName MyTrafficManagerProfile -ResourceGroupName RGA -Force
RG B ist jetzt die aktive primäre Bereitstellung. So wechselst du wieder zu RG A als primäre Bereitstellung:
Ändere die Richtung der Speicherreplikat-Partnerschaft („cluster-a-s2d-c“ wird zum Quellvolume):
Set-SRPartnership -NewSourceComputerName "cluster-a-s2d-c" -SourceRGName "cluster-a-s2d-c" -DestinationComputerName "cluster-b-s2d-c" -DestinationRGName "cluster-b-s2d-c"Aktiviere den Endpunkt von RG A erneut im Azure Traffic Manager-Profil:
Enable-AzureRmTrafficManagerEndpoint -Name publicIpA -Type AzureEndpoints -ProfileName MyTrafficManagerProfile -ResourceGroupName RGA
Überlegungen zu lokalen Bereitstellungen
Zwar kannst du bei einer lokalen Bereitstellung nicht die in diesem Artikel erwähnten Azure-Schnellstartvorlagen verwenden, aber du kannst alle Infrastrukturrollen manuell implementieren. In einer lokalen Bereitstellung, bei der die Kosten nicht durch die Azure-Nutzung bestimmt werden, solltest du ein Aktiv-Aktiv-Modell in Betracht ziehen, um ein schnelleres Failover zu erreichen.
Du kannst Azure Traffic Manager mit lokalen Endpunkten verwenden, aber dafür ist ein Azure-Abonnement erforderlich. Alternativ dazu kannst du für das Domain Name System, das für Endbenutzer bereitgestellt wird, auch einen CNAME-Eintrag zur Verfügung stellen, der Benutzer einfach an die primäre Bereitstellung weiterleitet. Ändere bei einem Failover den DNS-CNAME-Eintrag so, dass die Weiterleitung an die sekundäre Bereitstellung erfolgt. Auf diese Weise benötigen Endbenutzer nur eine einzige URL – genau wie bei Azure Traffic Manager –, die sie an die geeignete Bereitstellung weiterleitet.
Wenn du ein Modell mit Weiterleitung zwischen lokaler Umgebung und Azure-Standort erstellen möchtest, ziehe die Verwendung von Azure Site Recovery in Betracht.