Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel enthält Anleitungen zum Planen von Clustervolumes, um die Leistungs- und Kapazitätsanforderungen Ihrer Workloads zu erfüllen, einschließlich der Auswahl des Dateisystems, des Resilienztyps und der Größe.
Note
Direkte Speicherplätze unterstützt keinen Dateiserver für die allgemeine Verwendung. Wenn Sie den Dateiserver oder andere generische Dienste auf Storage Spaces Direct ausführen müssen, konfigurieren Sie diese auf den virtuellen Maschinen.
Überblick: Was sind Volumen?
Volumes sind der Ort, an dem Sie die benötigten Dateien ablegen, z. B. VHD- oder VHDX-Dateien für Hyper-V virtuellen Computer. Volumes kombinieren die Laufwerke im Speicherpool, um die Fehlertoleranz, Skalierbarkeit und Leistung von Direkte Speicherplätze, die softwaredefinierte Speichertechnologie hinter Azure Local und Windows Server einzuführen.
Note
Wir verwenden den Begriff "Volume", um sowohl auf das Volume als auch auf den virtuellen Datenträger darunter zu verweisen, einschließlich Funktionen, die von anderen integrierten Windows-Features wie Cluster Shared Volumes (CSV) und ReFS bereitgestellt werden. Das Verständnis dieser Unterschiede auf Implementierungsebene ist nicht erforderlich, um Direkte Speicherplätze erfolgreich zu planen und bereitzustellen.
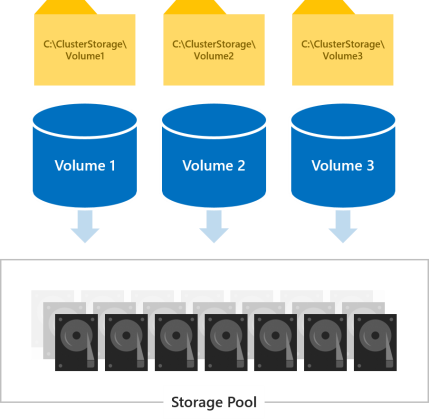
Auf alle Volumes kann gleichzeitig von allen Servern im Cluster zugegriffen werden. Nach der Erstellung werden sie auf allen Servern unter C:\ClusterStorage\ angezeigt.

Auswählen der Anzahl der zu erstellenden Volumes
Die Anzahl der volumes, die Sie erstellen, hängt von der Größe des Pools und der maximalen unterstützten Volumegröße ab, wobei mindestens ein Volume pro Knoten vorhanden ist. Diese Konfiguration ermöglicht es dem Cluster, volume "ownership" (ein Server verarbeitet die Metadaten-Orchestrierung für jedes Volume) gleichmäßig zwischen Servern zu verteilen.
Es wird empfohlen, die Gesamtanzahl der Volumes auf 64 Volumes pro Cluster zu beschränken.
Auswählen des Dateisystems
Wir empfehlen die Verwendung des neuen Resilient File System (ReFS) für Direkte Speicherplätze. ReFS ist das führende Dateisystem, das für die Virtualisierung entwickelt wurde, und bietet viele Vorteile, darunter dramatische Leistungsbeschleunigungen und integrierten Schutz vor Datenbeschädigungen. Es unterstützt fast alle wichtigen NTFS-Funktionen, einschließlich der Datendeduplizierung in Windows Server Version 1709 und höher. Details finden Sie in der ReFS-Featurevergleichstabelle .
Wenn Für Ihre Workload ein Feature erforderlich ist, das ReFS noch nicht unterstützt, können Sie stattdessen NTFS verwenden.
Tip
Volumes mit unterschiedlichen Dateisystemen können im selben Cluster koexistieren.
Auswählen des Resilienztyps
Volumes in Direkte Speicherplätze bieten Resilienz, um vor Hardwareproblemen wie Laufwerks- oder Serverfehlern zu schützen und die kontinuierliche Verfügbarkeit während der serverbasierten Wartung wie z. B. Softwareupdates zu ermöglichen.
Note
Welche Resilienztypen Sie auswählen können, ist unabhängig davon, welche Typen von Laufwerken Sie haben.
Mit zwei Servern
Bei zwei Servern im Cluster können Sie bidirektionale Spiegelung verwenden oder geschachtelte Resilienz verwenden.
Die Zwei-Wege-Spiegelung erstellt und speichert zwei Kopien aller Daten, eine Kopie auf den Laufwerken in jedem Server. Seine Lagereffizienz beträgt 50 Prozent; um 1 TB Daten zu schreiben, benötigen Sie mindestens 2 TB physische Speicherkapazität im Speicherpool. Zwei-Wege-Spiegelung kann jeweils einen Hardwarefehler (ein Server oder Laufwerk) sicher tolerieren.
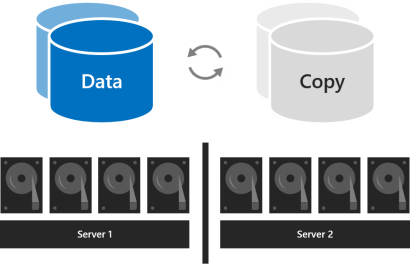
Geschachtelte Resilienz bietet Datenresilienz zwischen Servern mit zweifacher Spiegelung und fügt dann Resilienz innerhalb eines Servers mit zweifacher Spiegelung oder Parität mit Spiegelbeschleunigung hinzu. Nesting bietet Datenresilienz, selbst wenn ein Server neu startet oder nicht verfügbar ist. Die Speichereffizienz beträgt 25 Prozent bei geschachtelter bidirektionaler Spiegelung und rund 35–40 Prozent bei geschachtelter spiegelbeschleunigter Parität. Geschachtelte Resilienz kann zwei Hardwarefehler gleichzeitig sicher tolerieren (zwei Laufwerke oder ein Server und ein Laufwerk auf dem verbleibenden Server). Aufgrund dieser zusätzlichen Datenresilienz empfehlen wir die Verwendung geschachtelter Resilienz für Produktionsbereitstellungen von zwei Serverclustern. Weitere Informationen finden Sie unter "Geschachtelte Resilienz".

Mit drei Servern
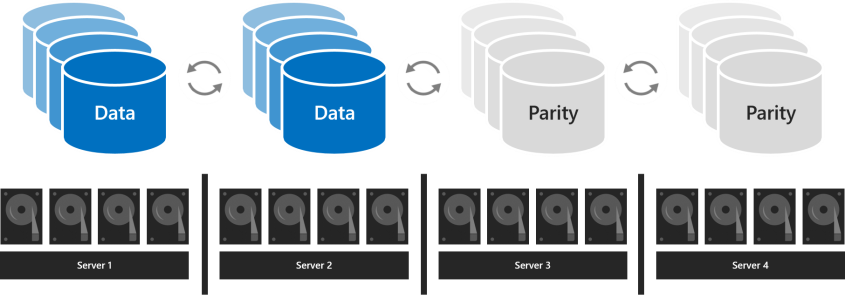
Bei drei Servern sollten Sie die Drei-Wege-Spiegelung verwenden, um die Fehlertoleranz und Leistung zu verbessern. Die Drei-Wege-Spiegelung behält drei Kopien aller Daten bei, eine Kopie auf den Laufwerken auf jedem Server. Die Speichereffizienz beträgt 33,3 Prozent – um 1 TB Daten zu schreiben, benötigen Sie mindestens 3 TB physische Speicherkapazität im Speicherpool. Die Drei-Wege-Spiegelung kann mindestens zwei Hardwareprobleme (Laufwerk oder Server) gleichzeitig sicher tolerieren. Wenn 2 Knoten nicht mehr verfügbar sind, verliert der Speicherpool das Quorum, da 2/3 der Datenträger nicht verfügbar sind und auf die virtuellen Datenträger nicht zugegriffen werden kann. Ein Knoten kann jedoch ausfallen, sowie mindestens ein Datenträger auf einem anderen Knoten kann ausfallen, und die virtuellen Datenträger bleiben online. Wenn Sie beispielsweise einen Server neu starten, wenn plötzlich ein anderes Laufwerk oder ein anderer Server fehlschlägt, bleiben alle Daten sicher und kontinuierlich zugänglich.
Das Diagramm zeigt ein Volume mit der Beschriftung "Daten" und zwei Kopien, die durch kreisförmige Pfeile verbunden sind, wobei jedes Volume mit einem Server verbunden ist, der physische Datenträger enthält.
Mit vier oder mehr Servern
Mit vier oder mehr Servern können Sie für jedes Volume auswählen, ob Sie die dreifache Spiegelung, die duale Parität (häufig als "Erasure Coding" bezeichnet) verwenden oder die beiden mit einer spiegelbeschleunigten Parität kombinieren.
Die duale Parität bietet die gleiche Fehlertoleranz wie die Drei-Wege-Spiegelung, aber mit einer besseren Speichereffizienz. Mit vier Servern beträgt die Speichereffizienz 50,0 Prozent; zum Speichern von 2 TB Daten benötigen Sie 4 TB physische Speicherkapazität im Speicherpool. Dies erhöht sich auf 66,7 Prozent Speichereffizienz mit sieben Servern und steigt weiter bis zu 80,0 Prozent Speichereffizienz an. Der Kompromiss besteht darin, dass die Paritätscodierung rechenintensiver ist, was die Leistung einschränken kann.
Welcher Resilienztyp verwendet werden soll, hängt von den Leistungs- und Kapazitätsanforderungen für Ihre Umgebung ab. Hier ist eine Tabelle, die die Leistung und Speichereffizienz der einzelnen Resilienztypen zusammenfasst.
| Resilienztyp | Kapazitätseffizienz | Speed |
|---|---|---|
| Mirror |

Drei-Wege-Spiegelung: 33 % Bidirektionale Spiegelung: 50% |

Höchste Leistung |
| Spiegelbeschleunigte Parität |

Hängt vom Verhältnis von Spiegelung und Parität ab |

Viel langsamer als Spiegelung, aber bis zu doppelt so schnell wie duale Parität Am besten geeignet für große sequenzielle Schreibvorgänge und Lesevorgänge |
| Dual-parity |

4 Server: 50 % 16 Server: bis zu 80 % |

Höchste E/A-Latenz und CPU-Auslastung bei Schreibvorgängen Am besten geeignet für große sequenzielle Schreibvorgänge und Lesevorgänge |
Wenn leistung am wichtigsten ist
Workloads die strenge Latenzanforderungen aufweisen oder viele gemischte zufällige IOPS benötigen, z. B. SQL Server-Datenbanken oder leistungsempfindliche Hyper-V virtuelle Maschinen, sollten auf Volumes ausgeführt werden, die Spiegelung einsetzen, um die Leistung zu maximieren.
Tip
Die Spiegelung ist schneller als jeder andere Resilienztyp. Wir verwenden spiegelung für fast alle unsere Leistungsbeispiele.
Wenn die Kapazität am wichtigsten ist
Workloads, die selten schreiben, z. B. Data Warehouses oder "Kaltspeicher", sollten auf Volumes ausgeführt werden, die duale Parität verwenden, um die Speichereffizienz zu maximieren. Bestimmte andere Workloads, wie z. B. SoFS (Scale-out File Server, Dateiserver mit horizontaler Skalierung), VDI (Virtual Desktop Infrastructure) oder andere Workloads, die nicht viel zufälligen E/A-Datenverkehr erzeugen und/oder nicht die beste Leistung erfordern, können nach eigenem Ermessen auch duale Parität verwenden. Die Parität erhöht zwangsläufig die CPU-Auslastung und E/A-Latenz, insbesondere bei Schreibvorgängen im Vergleich zur Spiegelung.
Wenn Daten in Massen geschrieben werden
Für Workloads, bei denen es zu großen sequenziellen Schreibvorgängen kommt, z. B. Archivierungs- oder Sicherungsziele, gibt es eine andere Option: Auf einem Volume können Spiegelung und duale Parität gemischt werden. Schreibvorgänge landen zuerst im gespiegelten Teil und werden später dann allmählich in den Paritätsteil verschoben. Dadurch wird die Aufnahme beschleunigt und die Ressourcenauslastung reduziert, wenn große Schreibvorgänge eingehen, indem die rechenintensive Paritätscodierung über einen längeren Zeitraum erfolgen kann. Berücksichtigen Sie beim Dimensionieren der Bereiche, dass die Menge der gleichzeitigen Schreibvorgänge (z. B. eine tägliche Sicherung) bequem in den Spiegelungsbereich passen sollte. Wenn Sie beispielsweise einmal täglich 100 GB erfassen, sollten Sie ggf. Spiegelung für 150 GB bis 200 GB und duale Parität für den Rest verwenden.
Die resultierende Speichereffizienz hängt von den gewählten Proportionen ab.
Tip
Wenn Sie während der Datenerfassung eine abrupte Abnahme der Schreibleistung beobachten, kann dies darauf hindeuten, dass der Spiegelungsbereich nicht groß genug ist oder dass die durch Spiegelung beschleunigte Parität für Ihren Anwendungsfall nicht gut geeignet ist. Wenn beispielsweise die Schreibleistung von 400 MB/s auf 40 MB/s verringert wird, sollten Sie den Spiegelteil erweitern oder auf eine Drei-Wege-Spiegelung wechseln.
Informationen zu Bereitstellungen mit NVMe, SSD und HDD
Bei Bereitstellungen mit zwei Laufwerktypen bieten die schnelleren Laufwerke Zwischenspeicherung, während die langsameren Laufwerke Kapazität bieten. Dies geschieht automatisch – weitere Informationen finden Sie unter Understanding the cache in Direkte Speicherplätze. In solchen Bereitstellungen befinden sich alle Volumes letztendlich auf Laufwerken desselben Typs – den Kapazitätslaufwerken.
Bei Bereitstellungen mit allen drei Typen von Laufwerken bieten nur die schnellsten Laufwerke (NVMe) Caching, während die beiden anderen Arten von Laufwerken (SSD und HDD) die Kapazität bereitstellt. Für jedes Volume können Sie auswählen, ob es sich vollständig auf der SSD-Ebene befindet, ganz auf der HDD-Ebene oder ob sie sich über die beiden erstreckt.
Important
Es wird empfohlen, die SSD-Ebene zu verwenden, um Ihre leistungsempfindlichsten Workloads auf all-Flash zu platzieren.
Auswählen der Volumegröße
Es wird empfohlen, die Größe jedes Volumes in Azure Local auf 64 TB zu beschränken.
Tip
Wenn Sie eine Sicherungslösung verwenden, die auf dem Volumeschattenkopie-Dienst (Volume Shadow Copy Service, VSS) und dem Volsnap-Softwareanbieter basiert – wie bei Dateiserverarbeitsauslastungen üblich – die Volumengröße auf 10 TB zu begrenzen, verbessert die Leistung und Zuverlässigkeit. Sicherungslösungen, die die neuere Hyper-V RCT-API, ReFS-Blockklonierung und die nativen SQL-Sicherungs-APIs verwenden, arbeiten bis zu 32 TB und darüber hinaus effizient.
Footprint
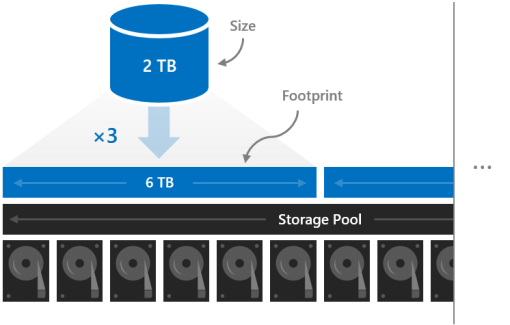
Die Größe eines Volumes bezieht sich auf seine verwendbare Kapazität, die Menge der Daten, die es speichern kann. Dies wird vom Parameter "-Size " des Cmdlets "New-Volume " bereitgestellt und wird dann in der Size-Eigenschaft angezeigt, wenn Sie das Cmdlet "Get-Volume " ausführen.
Die Größe unterscheidet sich vom Speicherplatzbedarf des Volumes, der gesamten physischen Speicherkapazität, die es im Speicherpool belegt. Der Fußabdruck hängt von seinem Resilienztyp ab. Beispielsweise haben Volumes, die Drei-Wege-Spiegelung verwenden, einen dreimal so großen Speicherbedarf.
Der Speicherbedarf Ihrer Volumes muss in den Speicherpool passen.
Reservekapazität
Wenn ein Teil der Kapazität im Speicherpool nicht zugewiesen wird, haben Volumes Speicherplatz für die direkte Reparatur nach Laufwerkfehlern. Dadurch werden Datensicherheit und Leistung verbessert. Wenn genügend Kapazität vorhanden ist, kann durch eine sofortige direkte, parallele Reparatur die vollständige Resilienz von Volumes wiederhergestellt werden, selbst bevor die fehlerhaften Laufwerke ersetzt werden. Dies erfolgt automatisch.
Es wird empfohlen, das Äquivalent eines Kapazitätslaufwerks pro Server, bis zu 4 Laufwerke, zu reservieren. Sie können nach eigenem Ermessen mehr Speicherplatz reservieren, aber diese Mindestempfehlung garantiert, dass eine sofortige direkte, parallele Reparatur nach einem Laufwerkfehler erfolgreich sein kann.

Wenn Sie beispielsweise über 2 Server verfügen und 1 TB Kapazitätslaufwerke verwenden, reservieren Sie 2 x 1 = 2 TB Pool als Reserve. Wenn Sie über 3 Server und 1 TB Kapazitätslaufwerke verfügen, legen Sie 3 x 1 = 3 TB als Reserve bereit. Wenn Sie über 4 oder mehr Server und 1 TB Kapazitätslaufwerke verfügen, sollten Sie 4 x 1 = 4 TB als Reserve reservieren.
Note
In Clustern mit Laufwerken aller drei Typen (NVMe + SSD + HDD) empfehlen wir, das Äquivalent von einer SSD plus einer HDD pro Server zu reservieren, bis zu 4 Laufwerke von jedem.
Beispiel: Kapazitätsplanung
Erwägen Sie einen Vier-Server-Cluster. Jeder Server verfügt über einige Cachelaufwerke plus sechszehn 2 TB Laufwerke für kapazität.
4 servers x 16 drives each x 2 TB each = 128 TB
Von diesen 128 TB im Speicherpool haben wir vier Laufwerke oder insgesamt 8 TB reserviert, damit Reparaturen direkt und ohne Eile durchgeführt werden können, um die Laufwerke nach ihrem Ausfall zu ersetzen. Dies belässt 120 TB physische Speicherkapazität im Pool, mit dem wir Volumes erstellen können.
128 TB – (4 x 2 TB) = 120 TB
Angenommen, wir benötigen unsere Bereitstellung, um einige hochaktive Hyper-V virtuelle Computer zu hosten, aber wir haben auch viel kalten Speicher – ältere Dateien und Sicherungen, die wir aufbewahren müssen. Da wir vier Server haben, erstellen wir vier Volumes.
Lassen Sie uns die virtuellen Computer auf die ersten beiden Volumes "Volume1 " und "Volume2" setzen. Wir wählen ReFS als Dateisystem (für die schnellere Erstellung und Prüfpunkte) und die dreiseitige Spiegelung zur Ausfallsicherheit aus, um die Leistung zu maximieren. Lassen Sie uns den Kaltspeicher auf den anderen beiden Volumes, Volume 3 und Volume 4, platzieren. Wir wählen NTFS als Dateisystem (für die Datendeduplizierung) und die duale Parität zur Resilienz aus, um die Kapazität zu maximieren.
Wir müssen nicht alle Volumes auf die gleiche Größe festlegen, aber aus Gründen der Einfachheit können wir sie beispielsweise alle 12 TB erstellen.
Volume1 und Volume2 belegen jeweils 12 TB x 33,3 Prozent Effizienz = 36 TB physische Speicherkapazität.
Volume3 und Volume4 belegen jeweils 12 TB x 50,0 Prozent Effizienz = 24 TB physische Speicherkapazität.
36 TB + 36 TB + 24 TB + 24 TB = 120 TB
Die vier Volumes passen genau in die Kapazität des physischen Speichers, die in unserem Pool zur Verfügung steht. Perfect!

Tip
Sie müssen nicht sofort alle Volumes erstellen. Sie können Volumes jederzeit erweitern oder später neue Volumes erstellen.
Aus Gründen der Einfachheit verwendet dieses Beispiel dezimale Einheiten (Basis-10), d. h. 1 TB = 1.000.000.000.000 Byte. Speichermengen in Windows werden jedoch in binären Einheiten (Base-2) angezeigt. Jedes Laufwerk mit 2 TB würde beispielsweise in Windows als 1,82 TiB angezeigt. Ebenso würde der 128 TB Speicherpool als 116.41 TiB angezeigt. Dies wird erwartet.
Usage
Siehe Volume-Erstellung.
Nächste Schritte
Weitere Informationen finden Sie auch unter: