DML_MULTIHEAD_ATTENTION_OPERATOR_DESC-Struktur (directml.h)
Führt einen Mehrkopf-Aufmerksamkeitsvorgang aus (weitere Informationen finden Sie unter Aufmerksamkeit ist alles, was Sie benötigen). Genauer gesagt, ein Abfrage-, Schlüssel- und Wert-Tensor muss vorhanden sein, unabhängig davon, ob sie gestapelt sind. Wenn beispielsweise StackedQueryKey bereitgestellt wird, müssen sowohl die Abfrage- als auch die Schlüssel-Tensoren NULL sein, da sie bereits in einem gestapelten Layout bereitgestellt werden. Das gleiche gilt für StackedKeyValue und StackedQueryKeyValue. Die gestapelten Tensoren haben immer fünf Dimensionen und werden immer auf der vierten Dimension gestapelt.
Logisch kann der Algorithmus in die folgenden Vorgänge dekompiliert werden (Vorgänge in Klammern sind optional):
[Add Bias to query/key/value] -> GEMM(Query, Transposed(Key)) * Scale -> [Add RelativePositionBias] -> [Add Mask] -> Softmax -> GEMM(SoftmaxResult, Value);
Wichtig
Diese API ist als Teil des eigenständigen weiterverteilbare Pakets DirectML verfügbar (siehe Microsoft.AI.DirectML , Version 1.12 und höher). Siehe auch DirectML-Versionsverlauf.
Syntax
struct DML_MULTIHEAD_ATTENTION_OPERATOR_DESC
{
_Maybenull_ const DML_TENSOR_DESC* QueryTensor;
_Maybenull_ const DML_TENSOR_DESC* KeyTensor;
_Maybenull_ const DML_TENSOR_DESC* ValueTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedQueryKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedKeyValueTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedQueryKeyValueTensor;
_Maybenull_ const DML_TENSOR_DESC* BiasTensor;
_Maybenull_ const DML_TENSOR_DESC* MaskTensor;
_Maybenull_ const DML_TENSOR_DESC* RelativePositionBiasTensor;
_Maybenull_ const DML_TENSOR_DESC* PastKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* PastValueTensor;
const DML_TENSOR_DESC* OutputTensor;
_Maybenull_ const DML_TENSOR_DESC* OutputPresentKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* OutputPresentValueTensor;
FLOAT Scale;
FLOAT MaskFilterValue;
UINT HeadCount;
DML_MULTIHEAD_ATTENTION_MASK_TYPE MaskType;
};
Member
QueryTensor
Typ: _Maybenull_ const DML_TENSOR_DESC*
Abfrage mit Form [batchSize, sequenceLength, hiddenSize], wobei hiddenSize = headCount * headSize. Dieser Tensor schließt sich gegenseitig mit StackedQueryKeyTensor und StackedQueryKeyValueTensor aus. Der Tensor kann auch 4 oder 5 Dimensionen haben, solange die führenden Dimensionen 1 sind.
KeyTensor
Typ: _Maybenull_ const DML_TENSOR_DESC*
Schlüssel mit Form [batchSize, keyValueSequenceLength, hiddenSize], wobei hiddenSize = headCount * headSize. Dieser Tensor schließt sich gegenseitig mit StackedQueryKeyTensor, StackedKeyValueTensor, und StackedQueryKeyValueTensor aus. Der Tensor kann auch 4 oder 5 Dimensionen haben, solange die führenden Dimensionen 1 sind.
ValueTensor
Typ: _Maybenull_ const DML_TENSOR_DESC*
Wert mit Form [batchSize, keyValueSequenceLength, valueHiddenSize], wobei valueHiddenSize = headCount * valueHeadSize. Dieser Tensor schließt sich gegenseitig mit StackedKeyValueTensor, und StackedQueryKeyValueTensor aus. Der Tensor kann auch 4 oder 5 Dimensionen haben, solange die führenden Dimensionen 1 sind.
StackedQueryKeyTensor
Typ: _Maybenull_ const DML_TENSOR_DESC*
Gestapelte Abfrage und Schlüssel mit Form [batchSize, sequenceLength, headCount, 2, headSize]. Dieser Tensor schließt sich gegenseitig mit QueryTensor, KeyTensor, StackedKeyValueTensor, und StackedQueryKeyValueTensor aus.
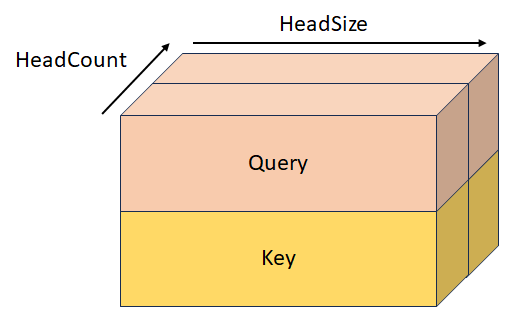
StackedKeyValueTensor
Typ: _Maybenull_ const DML_TENSOR_DESC*
Gestapelte Schlüssel und Wert mit Form [batchSize, keyValueSequenceLength, headCount, 2, headSize]. Dieser Tensor schließt sich gegenseitig mit KeyTensor, ValueTensor, StackedQueryKeyTensor, und StackedQueryKeyValueTensor aus.
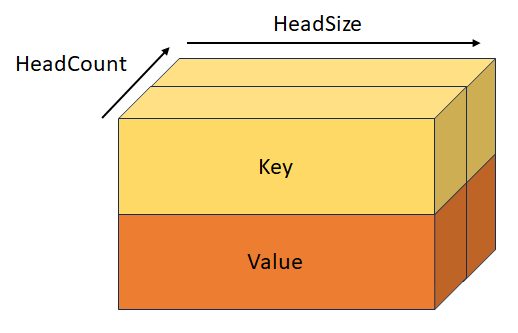
StackedQueryKeyValueTensor
Typ: _Maybenull_ const DML_TENSOR_DESC*
Gestapelte Abfrageschlüssel und Wert mit Form [batchSize, sequenceLength, headCount, 3, headSize]. Dieser Tensor schließt sich gegenseitig mit QueryTensor, KeyTensor, ValueTensor, StackedQueryKeyTensor, und StackedKeyValueTensor aus.
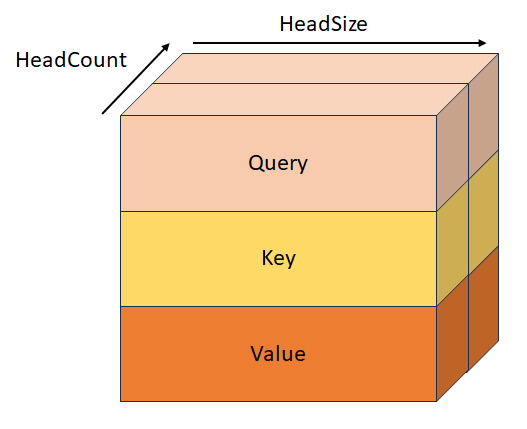
BiasTensor
Typ: _Maybenull_ const DML_TENSOR_DESC*
Dies ist die Voreingenommenheit der Form [hiddenSize + hiddenSize + valueHiddenSize], die vor dem ersten GEMM-Vorgang dem Abfrage/Schlüssel/Wert hinzugefügt wird. Dieser Tensor kann auch 2, 3, 4 oder 5 Dimensionen haben, solange die führenden Dimensionen 1 sind.
MaskTensor
Typ: _Maybenull_ const DML_TENSOR_DESC*
Dies ist die Maske, die bestimmt, welche Elemente ihren Wert nach dem QxK GEMM-Vorgang auf MaskFilterValue festlegen. Das Verhalten dieser Maske hängt vom Wert von MaskType ab und wird nach RelativePositionBiasTensor oder nach dem ersten GEMM-Vorgang angewendet, wenn RelativePositionBiasTensor null ist. Weitere Informationen finden Sie in MaskType.
RelativePositionBiasTensor
Typ: _Maybenull_ const DML_TENSOR_DESC*
Dies ist die Verzerrung, die dem Ergebnis des ersten GEMM-Vorgangs hinzugefügt wird.
PastKeyTensor
Typ: _Maybenull_ const DML_TENSOR_DESC*
Schlüssel-Tensor aus der vorherigen Iteration mit Form [batchSize, headCount, pastSequenceLength, headSize]. Wenn dieser Tensor nicht null ist, wird er mit dem Schlüssel-Tensor verkettet, was zu einem Tensor der Form [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize] führt.
PastValueTensor
Typ: _Maybenull_ const DML_TENSOR_DESC*
Wert-Tensor aus der vorherigen Iteration mit Form [batchSize, headCount, pastSequenceLength, headSize]. Wenn dieser Tensor nicht null ist, wird er mit dem ValueDescverkettet, was zu einem Tensor der Form [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize] führt.
OutputTensor
Typ: const DML_TENSOR_DESC*
Ausgabe, von Form [batchSize, sequenceLength, valueHiddenSize].
OutputPresentKeyTensor
Typ: _Maybenull_ const DML_TENSOR_DESC*
Gegenwärtiger Zustand für Kreuzaufmerksamkeitsschlüssel, mit Form [batchSize, headCount, keyValueSequenceLength, headSize] oder gegenwärtiger Zustand für Selbstaufmerksamkeit mit Form [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize]. Er enthält entweder den Inhalt des Schlüssel-Tensors oder den Inhalt des verketteten PastKey + Key-Tensors, der an die nächste Iteration übergeben werden soll.
OutputPresentValueTensor
Typ: _Maybenull_ const DML_TENSOR_DESC*
Gegenwärtiger Zustand für Kreuzaufmerksamkeitswerts, mit Form [batchSize, headCount, keyValueSequenceLength, headSize] oder gegenwärtiger Zustand für Selbstaufmerksamkeit mit Form [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize]. Er enthält entweder den Inhalt des Wert-Tensors oder den Inhalt des verketteten PastValue + Wert-Tensors, der an die nächste Iteration übergeben werden soll.
Scale
Typ: FLOAT
Skalieren Sie, um das Ergebnis des QxK GEMM-Vorgangs zu multiplizieren, aber vor dem Softmax-Vorgang. Dieser Wert ist in der Regel 1/sqrt(headSize).
MaskFilterValue
Typ: FLOAT
Wert, der dem Ergebnis des QxK GEMM-Vorgangs zu den Positionen hinzugefügt wird, die die Maske als Abstandselemente definiert hat. Dieser Wert sollte eine sehr große negative Zahl sein (in der Regel -10000,0f).
HeadCount
Typ: UINT
Anzahl der Aufmerksamkeitsköpfe.
MaskType
Typ: DML_MULTIHEAD_ATTENTION_MASK_TYPE
Beschreibt das Verhalten von MaskTensor.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_BOOLEAN. Wenn die Maske einen Wert von 0 enthält, wird MaskFilterValue hinzugefügt. Wenn es jedoch einen Wert von 1 enthält, wird nichts hinzugefügt.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_SEQUENCE_LENGTH. Das Format der Form [1, batchSize]enthält die Sequenzlängen des nicht gefüllten Bereichs für jeden Batch, und alle Elemente nach der Sequenzlänge erhalten ihren Wert auf MaskFilterValue festgelegt.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_SEQUENCE_END_START. Die Formmaske [2, batchSize] enthält das Ende (exklusiv) und die Startindizes (einschließlich) des nicht geblockten Bereichs, und alle Elemente außerhalb des Bereichs erhalten ihren Wert auf MaskFilterValue festgelegt.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_QUERY_SEQUENCE_LENGTH_START_END. Die Formmaske [batchSize * 3 + 2] hat die folgenden Werte: [keyLength[0], ..., keyLength[batchSize - 1], queryStart[0], ..., queryStart[batchSize - 1], queryEnd[batchSize - 1], keyStart[0], ..., keyStart[batchSize - 1], keyEnd[batchSize - 1]]:
Verfügbarkeit
Dieser Operator wurde in DML_FEATURE_LEVEL_6_1 eingeführt.
Tensor-Einschränkungen
BiasTensor, KeyTensor, OutputPresentKeyTensor, OutputPresentValueTensor, OutputTensor, PastKeyTensor, PastValueTensor, QueryTensor, RelativePositionBiasTensor, StackedKeyValueTensor, StackedQueryKeyTensor, StackedQueryKeyValueTensor, and ValueTensor muss den gleichen DataType haben.
Tensor-Unterstützung
| Tensor | Variante | Unterstützte Dimensionsanzahl | Unterstützte Datentypen |
|---|---|---|---|
| QueryTensor | Optionale Eingabe | 3 bis 5 | FLOAT32, FLOAT16 |
| KeyTensor | Optionale Eingabe | 3 bis 5 | FLOAT32, FLOAT16 |
| ValueTensor | Optionale Eingabe | 3 bis 5 | FLOAT32, FLOAT16 |
| StackedQueryKeyTensor | Optionale Eingabe | 5 | FLOAT32, FLOAT16 |
| StackedKeyValueTensor | Optionale Eingabe | 5 | FLOAT32, FLOAT16 |
| StackedQueryKeyValueTensor | Optionale Eingabe | 5 | FLOAT32, FLOAT16 |
| BiasTensor | Optionale Eingabe | 1 bis 5 | FLOAT32, FLOAT16 |
| MaskTensor | Optionale Eingabe | 1 bis 5 | INT32 |
| RelativePositionBiasTensor | Optionale Eingabe | 4 bis 5 | FLOAT32, FLOAT16 |
| PastKeyTensor | Optionale Eingabe | 4 bis 5 | FLOAT32, FLOAT16 |
| PastValueTensor | Optionale Eingabe | 4 bis 5 | FLOAT32, FLOAT16 |
| OutputTensor | Output | 3 bis 5 | FLOAT32, FLOAT16 |
| OutputPresentKeyTensor | Optionale Ausgabe | 4 bis 5 | FLOAT32, FLOAT16 |
| OutputPresentValueTensor | Optionale Ausgabe | 4 bis 5 | FLOAT32, FLOAT16 |
Anforderungen
| Übergeordnet | directml.h |
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für