Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In der vorherigen Phase dieses Tutorials haben wir PyTorch auf Ihrem Computer installiert. Nun verwenden wir es, um unseren Code mit den Daten einzurichten, die wir für unser Modell verwenden.
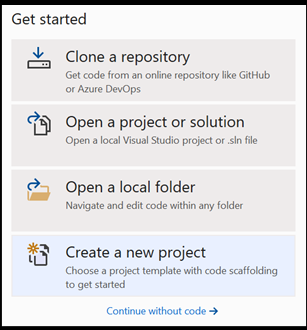
Öffnen Sie ein neues Projekt in Visual Studio.
- Öffnen Sie Visual Studio, und wählen Sie
create a new project.
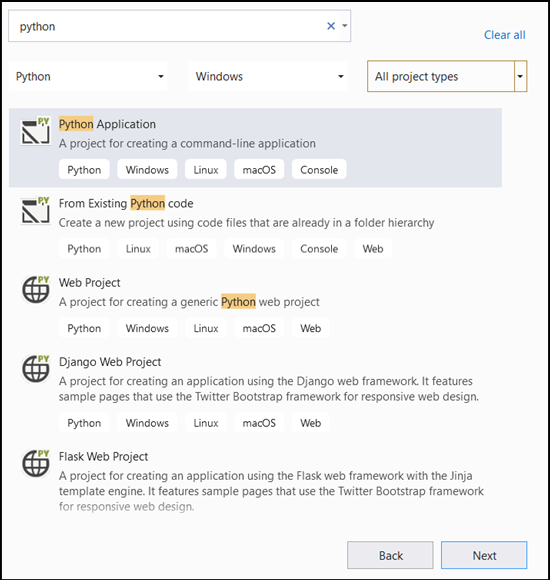
- Geben Sie in der Suchleiste
Pythonein, und wählen SiePython Applicationals Projektvorlage aus.
- Im Konfigurationsfenster:
- Geben Sie dem Projekt einen Namen. Hier nennen wir es DataClassifier.
- Wählen Sie den Speicherort Ihres Projekts aus.
- Wenn Sie VS 2019 verwenden, stellen Sie sicher, dass
Create directory for solutionaktiviert ist. - Wenn Sie VS2017 verwenden, stellen Sie sicher, dass
Place solution and project in the same directorydie Option deaktiviert ist.
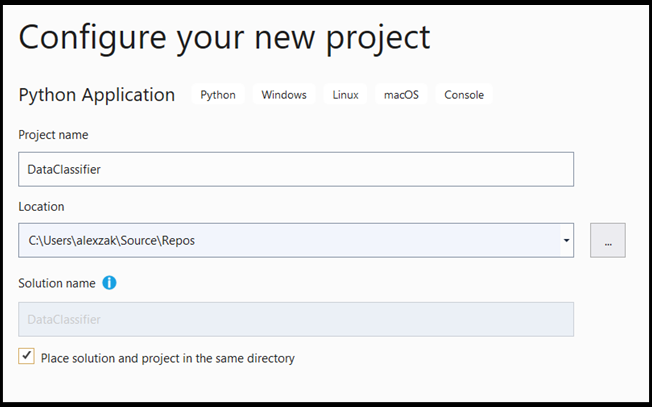
Drücken Sie create , um Ihr Projekt zu erstellen.
Erstellen eines Python-Interpreters
Nun müssen Sie einen neuen Python-Interpreter definieren. Dies muss das PyTorch-Paket enthalten, das Sie vor Kurzem installiert haben.
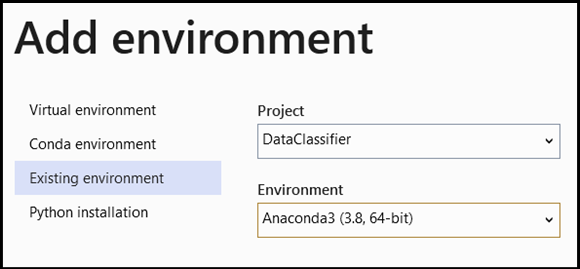
- Navigieren Sie zur Interpreterauswahl, und wählen Sie
Add Environmentaus:

- Wählen Sie im Fenster
Add Environmentdie OptionExisting environmentund dannAnaconda3 (3.6, 64-bit)aus. Dies bezieht das PyTorch-Paket mit ein.
Geben Sie den folgenden Code in die Datei DataClassifier.py ein, um den neuen Python-Interpreter und das PyTorch-Paket zu testen:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
Die Ausgabe sollte ein zufälliger 5x3-Tensor ähnlich dem folgenden sein.
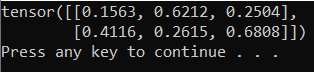
Hinweis
Möchten Sie mehr erfahren? Besuchen Sie die offizielle PyTorch-Website.
Grundlegendes zu den Daten
Wir werden das Modell auf dem Irisblumen-Dataset von Fisher trainieren. Dieses berühmte Dataset enthält 50 Datensätze für jede von drei Irisarten: Iris setosa, Iris virginica und Iris Versicolor.
Es wurden mehrere Versionen des Datasets veröffentlicht. Sie können Iris-Dataset im UCI Machine Learning Repository finden, das Dataset direkt aus der Python Scikit-Learn-Bibliothek importieren oder eine andere Version verwenden, die zuvor veröffentlicht wurde. Informationen zum Dataset „Iris“ finden Sie auf der zugehörigen Wikipedia-Seite.
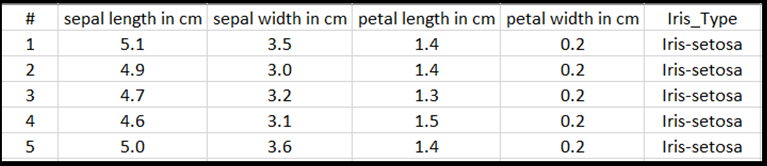
Im Rahmen dieses Tutorials werden Sie das Modell mit tabellarischen Eingabedaten trainieren, indem Sie das Iris-Dataset verwenden, das in eine Excel-Datei exportiert wurde.
Jede Zeile der Excel-Tabelle zeigt vier Merkmale von Irisen an: Sepallänge in cm, Sepalbreite in cm, Petallänge in cm und Petalbreite in cm. Diese Merkmale dienen als Eingabe. Die letzte Spalte enthält den Iristyp im Zusammenhang mit diesen Parametern und stellt die Regressionsausgabe dar. Insgesamt umfasst das Dataset 150 Eingaben von vier Features, die jeweils mit dem relevanten Iristyp übereinstimmen.
Regressionsanalyse untersucht die Beziehung zwischen Eingabevariablen und dem Ergebnis. Basierend auf der Eingabe wird das Modell lernen, den richtigen Ausgabetyp vorherzusagen - einer der drei Iristypen: Iris-setosa, Iris-versicolor, Iris-virginica.
Von Bedeutung
Wenn Sie ein anderes Dataset zum Erstellen Ihres eigenen Modells verwenden möchten, müssen Sie ihre Modelleingabevariablen und die Ausgabe entsprechend Ihrem Szenario angeben.
Laden Sie das Dataset.
Laden Sie das Iris-Dataset im Excel-Format herunter. Sie finden es hier.
Fügen Sie in der Datei
DataClassifier.pyim Ordner Projektmappen-Explorer die folgende Importanweisung hinzu, um Zugriff auf alle benötigten Pakete zu erhalten.
import torch
import pandas as pd
import torch.nn as nn
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
Wie Sie sehen können, verwenden Sie pandas (Python Data Analysis)-Paket zum Laden und Bearbeiten von Daten und Torch.nn-Paketen, das Module und erweiterbare Klassen zum Erstellen neuraler Netzwerke enthält.
- Laden Sie die Daten in den Arbeitsspeicher, und überprüfen Sie die Anzahl der Klassen. Wir erwarten, dass 50 Elemente jedes Iris-Typs angezeigt werden. Stellen Sie sicher, dass Sie den Speicherort des Datasets auf Ihrem PC angeben.
Fügen Sie der Datei DataClassifier.py den folgenden Code hinzu.
# Loading the Data
df = pd.read_excel(r'C:…\Iris_dataset.xlsx')
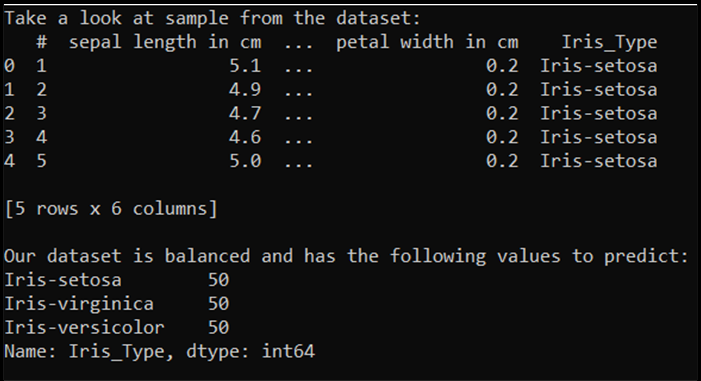
print('Take a look at sample from the dataset:')
print(df.head())
# Let's verify if our data is balanced and what types of species we have
print('\nOur dataset is balanced and has the following values to predict:')
print(df['Iris_Type'].value_counts())
Wenn wir diesen Code ausführen, lautet die erwartete Ausgabe wie folgt:
Um das Dataset verwenden und das Modell trainieren zu können, müssen wir Eingaben und Ausgaben definieren. Die Eingabe umfasst 150 Zeilen mit Features, die Ausgabe ist die Spalte mit der Schwertlilienart. Das neuronale Netzwerk, das wir verwenden, erfordert numerische Variablen, sodass Sie die Ausgabevariable in ein numerisches Format konvertieren.
- Erstellen Sie eine neue Spalte im Dataset, die die Ausgabe in einem numerischen Format darstellt, und definieren Sie eine Regressionseingabe und -ausgabe.
Fügen Sie der Datei DataClassifier.py den folgenden Code hinzu.
# Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
df['IrisType_num'] = df['Iris_Type'] # Create a new column "IrisType_num"
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
# Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones.
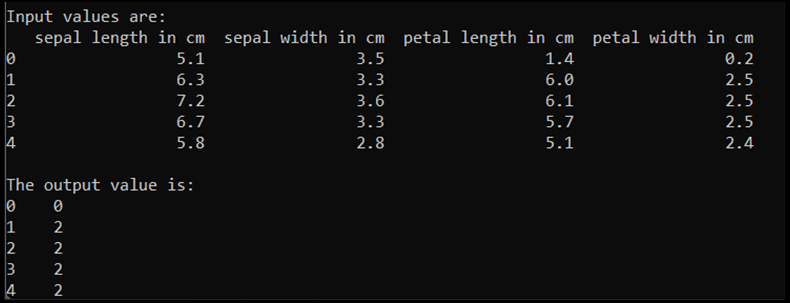
print('\nInput values are:')
print(input.head())
output = df.loc[:, 'IrisType_num'] # Output Y is the last column
print('\nThe output value is:')
print(output.head())
Wenn wir diesen Code ausführen, lautet die erwartete Ausgabe wie folgt:
Um das Modell zu trainieren, müssen wir die Modelleingabe und -ausgabe in das Tensor-Format konvertieren:
- In Tensor konvertieren:
Fügen Sie der Datei DataClassifier.py den folgenden Code hinzu.
# Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
Wenn der Code ausgeführt wird, zeigt die erwartete Ausgabe das Eingabe- und Ausgabeformat wie folgt an:

Es gibt 150 Eingabewerte. Etwa 60 % sind die Trainingsdaten für das Modell. Sie behalten 20% für die Überprüfung und 30% für einen Test bei.
In diesem Lernprogramm wird die Batchgröße für ein Schulungsdatenset als 10 definiert. Es gibt 95 Elemente im Trainingssatz, was bedeutet, dass im Durchschnitt 9 vollständige Batches benötigt werden, um den Trainingssatz einmal zu durchlaufen (eine Epoche). Sie behalten die Batchgröße der Überprüfungs- und Testsätze als 1 bei.
- Teilen Sie die Daten in Trainings-, Validierungs- und Testsätze auf.
Fügen Sie der Datei DataClassifier.py den folgenden Code hinzu.
# Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows*0.3)
validate_split = int(number_rows*0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
# Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
Nächste Schritte
Wenn die Daten einsatzbereit sind, ist es an der Zeit, unser PyTorch-Modell zu trainieren.