Klonen blockieren
Ein Blockklonvorgang weist das Dateisystem an, einen Bereich von Dateibytes im Auftrag einer Anwendung zu kopieren. Die Zieldatei ist möglicherweise identisch mit der Quelldatei oder unterscheidet sich von der Quelldatei.
Ein Dateisystem verwaltet die Zuordnungen von Clustern und Vergrößerungen und kann die Kopie durch Ändern der virtuellen Clusternummer (VCN) in logische Clusternummer (LCN)-Zuordnungen als kostengünstige Metadatenoperation durchführen, anstatt die zugrunde liegenden Dateidaten zu lesen und zu schreiben. Dadurch kann die Kopie schneller abgeschlossen werden und generiert weniger E/A für den zugrunde liegenden Speicher. Darüber hinaus können mehrere Dateien logische Cluster nach dem Blockklon freigeben, wodurch Kapazität gespart wird, indem identische Cluster nicht mehrmals auf dem Datenträger gespeichert werden.
Durch einen Blockklonvorgang wird die zwischen Dateien bereitgestellte Isolation nicht getrennt. Nach Abschluss eines Blockklons werden Schreibvorgänge in die Quelldatei nicht im Ziel angezeigt oder umgekehrt.
Block cloning ist nur für den ReFS-Dateisystemtyp ab Windows Server 2016 verfügbar. Ab dem Windows 11 Moment 5-Update (KB5034848) und späteren Versionen von Windows-Client- und Windows Server-Builds tritt das Klonen in unterstützten Windows-Kopiervorgängen nativ auf.
Klonen auf ReFS blockieren
ReFS unter Windows Server 2016 implementiert das Klonen von Block cloning, indem logische Cluster (d. h. physische Speicherorte auf einem Volume) aus dem Quellbereich in die Zielregion umgeschrieben werden. Anschließend wird ein Zuweisungs-on-Write-Mechanismus verwendet, um die Isolierung zwischen diesen Regionen sicherzustellen. Die Quell- und Zielregionen befinden sich möglicherweise in denselben oder unterschiedlichen Dateien.
Für diese Implementierung müssen die Anfangs- und Enddateioffsets an Clustergrenzen ausgerichtet werden. In ReFS unter Windows Server 2016 sind Cluster standardmäßig 4 KB groß, können aber optional auf 64 KB festgelegt werden. Die Clustergröße ist ein volumeweiter Parameter, der zur Formatzeit festgelegt ist.
Einschränkungen und Hinweise
- Die Quell- und Zielbereiche müssen an einer Clustergrenze beginnen und enden.
- Die geklonte Region muss kleiner als 4 GB lang sein.
- Der Zielbereich darf nicht über das Ende der Datei hinaus erweitert werden. Falls die Anwendung das Ziel mit geklonten Daten erweitern möchte, müssen sie zuerst SetEndOfFile aufrufen.
- Wenn sich die Quell- und Zielregionen in derselben Datei befinden, dürfen diese nicht überlappen. (Die Anwendung kann fortfahren, indem sie den Blockklonvorgang in mehrere Blockklonen aufteilen kann, die sich nicht mehr überlappen.)
- Die Quell- und Zieldateien müssen sich auf demselben Volume ReFS befinden.
- Die Quell- und Zieldateien müssen dieselbe Integritätsstreams-Einstellung haben (d. a. Integritätsstreams müssen in beiden Dateien aktiviert oder in beiden Dateien deaktiviert sein).
- Hat die Quelldatei eine geringe Datendichte, muss die Zieldatei ebenfalls eine geringe Datendichte aufweisen.
- Der Block-Klonvorgang unterbricht freigegebene opportunistische Sperren (auch bekannt als "Opportunistic Locks der Ebene 2").
- Das ReFS-Volume muss mit Windows Server 2016 formatiert sein, und wenn Windows-Failoverclustering verwendet wird, muss die Clusteringfunktionsebene windows Server 2016 oder höher zur Formatzeit sein.
Beispiel
Angenommen, wir haben zwei Dateien, X und Y, wobei jede Datei aus 3 unterschiedlichen Regionen besteht. Jeder Dateibereich wird in einem bestimmten Bereich des Volumes gespeichert. Das Dateisystem speichert das Wissen, dass auf jeden dieser Volumebereiche in einer Dateiregion verwiesen wird:
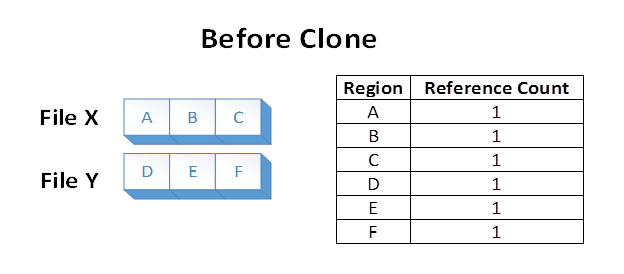
Angenommen, eine Anwendung stellt einen Blockklonvorgang von File X über dateibereiche A und B in Datei Y am Offset aus, in dem E aktuell ist. Der folgende Dateisystemstatus würde dazu führen:
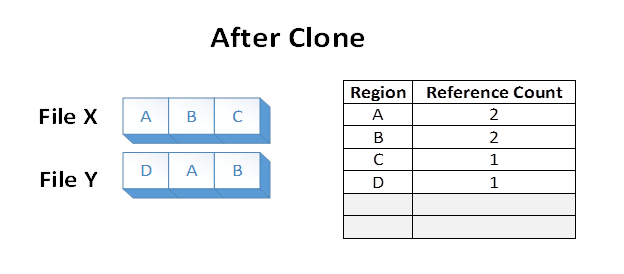
Die Daten in den Regionen A und B wurden effektiv von File X in File Y dupliziert, indem der VCN in LCN-Zuordnungen innerhalb des ReFS-Volumes geändert wurde. Die Datenträgerbereiche A und B wurden nicht gelesen, und die Datenträgerdehnungen sichern die alten Regionen E und F während des Vorgangs überschrieben.
Dateien X und Y teilen jetzt logische Cluster auf dem Datenträger. Dies wird in den in der Tabelle angezeigten Referenzanzahlen wider. Die Freigabe führt zu einem geringeren Volumenkapazitätsverbrauch als wenn Regionen A und B auf dem zugrunde liegenden Volume dupliziert wurden.
Angenommen, die Anwendung überschreibt den Bereich A in Datei X. ReFS erstellt eine duplizierte Kopie von A, die wir jetzt G. ReFS aufrufen, ordnet G. ReFS dann G in File X zu und wendet die Änderung an. Dadurch wird sichergestellt, dass die Isolation zwischen den Dateien beibehalten wird. Referenzanzahlen werden entsprechend aktualisiert:
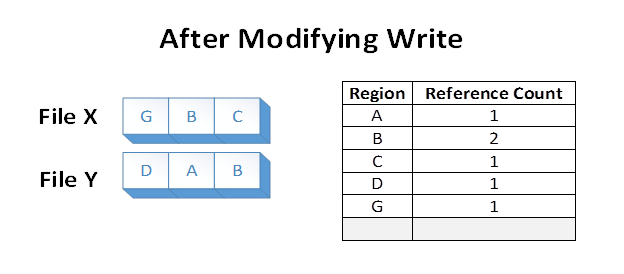
Nach dem Ändern des Schreibvorgangs wird Region B weiterhin auf dem Datenträger freigegeben. Falls Region A größer als ein Cluster wäre, würde nur der geänderte Cluster dupliziert und der verbleibende Teil würde freigegeben.