Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Szenenverständnis bietet Mixed Reality-Entwicklern eine strukturierte, allgemeine Umgebungsdarstellung, die die Entwicklung für umgebungssensible Anwendungen intuitiv macht. Szenenverständnis ermöglicht dies, indem die Leistungsfähigkeit vorhandener Mixed Reality-Runtimes wie der hochgenauen, aber weniger strukturierten räumlichen Zuordnung und neuen KI-gesteuerten Runtimes kombiniert wird. Durch die Kombination dieser Technologien generiert Scene Understanding Darstellungen von 3D-Umgebungen, die denen ähneln, die Sie möglicherweise in Frameworks wie Unity oder ARKit/ARCore verwendet haben. Der Einstiegspunkt Szenenverständnis beginnt mit einem Szenenbeobachter, der von Ihrer Anwendung aufgerufen wird, um eine neue Szene zu berechnen. Heute kann die Technologie 3 verschiedene, aber verwandte Objektkategorien generieren:
- Vereinfachte wasserdichte Umgebungsgitter, die die planare Raumstruktur ohne Unordnung ableiten
- Ebenenregionen für die Platzierung, die wir Quads nennen
- Ein Momentaufnahme des räumlichen Zuordnungsgitters, das mit den Quads/Watertight-Daten übereinstimmt, die wir anzeigen

Dieses Dokument soll einen Überblick über das Szenario bieten und die Beziehung zwischen Szenenverständnis und räumlicher Zuordnung verdeutlichen. Wenn Sie Szenenverständnis in Aktion sehen möchten, sehen Sie sich unsere Videodemo Entwerfen von Hologrammen – Räumliches Bewusstsein unten an:
Dieses Video stammt aus der HoloLens 2-App "Entwerfen von Hologrammen". Sie können das vollständige Erlebnis hier herunterladen und genießen.
Entwickeln mit Szenenverständnis
In diesem Artikel werden nur die Scene Understanding-Runtime und die Konzepte vorgestellt. Wenn Sie eine Dokumentation zur Entwicklung mit Scene Understanding suchen, interessieren Sie sich möglicherweise für die folgenden Artikel:
Übersicht über das Scene Understanding SDK
Sie können die Scene Understanding-Beispiel-App von der GitHub-Beispielwebsite herunterladen:
Wenn Sie über kein Gerät verfügen und auf Beispielszenen zugreifen möchten, um Scene Understanding auszuprobieren, gibt es Szenen im Beispielobjektordner:
Szenenverständnis - Beispielszenen
SDK
Wenn Sie nach spezifischen Details zur Entwicklung mit Scene Understanding suchen, lesen Sie die Übersichtsdokumentation des Scene Understanding SDK .
Beispiel
Geräteunterstützung
| Feature | HoloLens (1. Generation) | HoloLens 2 | Immersive Headsets |
| Grundlegendes zu Szenen | ❌ | ✔️ | ❌ |
Allgemeine Verwendungsszenarios
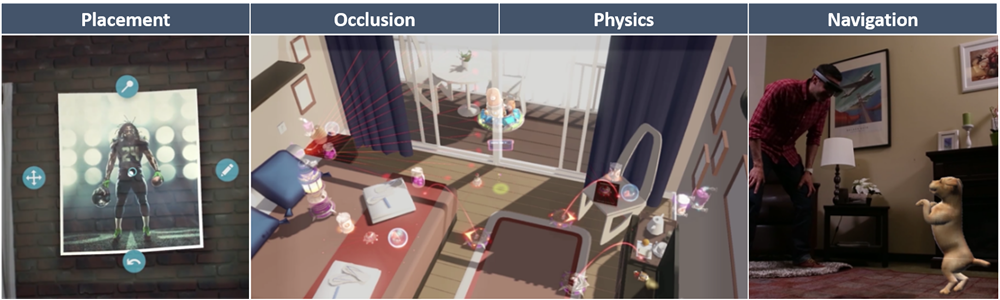
Gängige Szenarien für die Verwendung räumlicher Zuordnungen: Platzierung, Okklusion, Physik und Navigation.
Viele der Kernszenarien für umweltbewusste Anwendungen können sowohl mit räumlicher Zuordnung als auch mit Szenenverständnis behandelt werden. Zu diesen Kernszenarien gehören Platzierung, Okklusion, Physik usw. Ein Hauptunterschied zwischen Szenenverständnis und räumlicher Zuordnung ist ein Kompromiss zwischen maximaler Genauigkeit und Latenz für Struktur und Einfachheit. Wenn Ihre Anwendung eine möglichst geringe Latenz und Gitterdreiecke benötigt, auf die nur Sie zugreifen möchten, verwenden Sie räumliche Zuordnung direkt. Wenn Sie eine verarbeitung auf höherer Ebene durchführen, können Sie den Wechsel zum Scene Understanding-Modell in Erwägung ziehen, da es Ihnen eine Übermenge an Funktionalität bieten sollte. Sie haben immer Zugriff auf die vollständigsten und präzisesten Räumlichen Zuordnungsdaten, die möglich sind, da Szenenverständnis eine Momentaufnahme des räumlichen Zuordnungsgitters als Teil seiner Darstellung bietet.
In den folgenden Abschnitten werden die wichtigsten Räumlichen Zuordnungsszenarien im Kontext des neuen Scene Understanding SDK erneut behandelt.
Platzierung
Szenenverständnis bietet neue Konstrukte zur Vereinfachung von Platzierungsszenarien. Eine Szene kann Primitive namens SceneQuads berechnen, die flache Oberflächen beschreiben, auf denen Hologramme platziert werden können. SceneQuads wurden für die Platzierung entworfen, beschreiben eine 2D-Oberfläche und stellen eine API für die Platzierung auf dieser Oberfläche bereit. Früher musste man bei Verwendung des Dreiecksgitters zum Platzieren alle Bereiche des Quads scannen und lochfüllen/nachbereiten, um gute Positionen für die Objektplatzierung zu identifizieren. Dies ist bei Quads nicht immer erforderlich, da die Scene Understanding-Runtime ableiten kann, welche Viereckbereiche nicht gescannt wurden, und Bereiche, die nicht Teil der Oberfläche sind, ungültig macht.

Image #1 : SceneQuads mit deaktiviertem Rückschluss, Aufnahmeplatzierungsbereiche für gescannte Regionen.

Bild #2 : Quads mit aktiviertem Rückschluss, die Platzierung ist nicht mehr auf gescannte Bereiche beschränkt.
Wenn Ihre Anwendung 2D- oder 3D-Hologramme auf starren Strukturen Ihrer Umgebung platzieren möchte, ist die Einfachheit und Bequemlichkeit von SceneQuads für die Platzierung vorzuziehen, um diese Informationen aus dem Räumlichen Zuordnungsgitter zu berechnen. Weitere Informationen zu diesem Thema finden Sie in der Referenz zum Scene Understanding SDK.
Hinweis Für Legacyplatzierungscode, der vom Räumlichen Zuordnungsgitter abhängig ist, kann das räumliche Zuordnungsgitter zusammen mit SceneQuads berechnet werden, indem die Einstellung EnableWorldMesh festgelegt wird. Wenn die Szenenverständnis-API die Latenzanforderungen Ihrer Anwendung nicht erfüllt, wird empfohlen, weiterhin die Räumliche Zuordnungs-API zu verwenden.
Okklusion
Räumliche Zuordnungsverschlüsse sind nach wie vor die am wenigsten latente Möglichkeit, den Echtzeitzustand der Umgebung zu erfassen. Obwohl dies nützlich sein kann, um Verdeckungen in hoch dynamischen Szenen bereitzustellen, sollten Sie aus mehreren Gründen Das Verständnis von Szenen für Okklusion in Betracht ziehen. Wenn Sie das von Scene Understanding generierte Räumliche Zuordnungsgitter verwenden, können Sie Daten aus der räumlichen Zuordnung anfordern, die nicht im lokalen Cache gespeichert würden und nicht über die Wahrnehmungs-APIs verfügbar sind. Die Verwendung von Räumlicher Zuordnung für Verschlüsse zusammen mit wasserdichten Gittern bietet zusätzlichen Wert, insbesondere die Vervollständigung der nicht abgesäuerten Raumstruktur.
Wenn Ihre Anforderungen die erhöhte Latenz des Szenenverständnisses tolerieren können, sollten Anwendungsentwickler das wasserdichte Gitter "Scene Understanding" und das Räumliche Zuordnungsgitter im Einklang mit planaren Darstellungen verwenden. Dies würde ein "Bestes aus beiden Welten" -Szenario bieten, in dem eine vereinfachte wasserdichte Verdeckung mit einer feineren nichtplanaren Geometrie verknüpft ist, die die realistischsten Okklusionskarten bietet.
Physische Effekte
Szenenverständnis generiert wasserdichte Gitter, die den Raum mit Semantik zerlegen, insbesondere, um viele Einschränkungen der Physik zu beheben, die räumliche Zuordnungsgitter auferlegen. Wasserdichte Strukturen sorgen dafür, dass Physikstrahlen immer treffen, und die semantische Zerlegung ermöglicht eine einfachere Generierung von Navigationsgittern für die Innennavigation. Wie im Abschnitt über Okklusion beschrieben, erzeugt das Erstellen einer Szene mit EnableSceneObjectMeshes und EnableWorldMesh ein möglichst vollständiges Gitternetz. Die wasserdichte Eigenschaft des Umgebungsgitters verhindert, dass Treffertests nicht auf Oberflächen treffen. Die Gitterdaten stellen sicher, dass die Physik mit allen Objekten in der Szene interagiert und nicht nur mit der Raumstruktur.
Navigation
Planare Gitter, die durch die semantische Klasse zerlegt werden, sind ideale Konstrukte für die Navigations- und Pfadplanung, was viele der in der Navigationsübersicht räumliche Zuordnung beschriebenen Probleme erleichtert. Die in der Szene berechneten SceneMesh-Objekte werden nach Oberflächentyp dekomponiert, um sicherzustellen, dass die Nav-Mesh-Generierung auf Oberflächen beschränkt ist, die begehbar sind. Aufgrund der Einfachheit der Bodenstrukturen sind dynamische Nav-Mesh-Generierung in 3D-Engines wie Unity je nach Echtzeitanforderungen erreichbar.
Für die Generierung präziser Navigationsgitter ist derzeit noch eine Nachbearbeitung erforderlich, d. h. Anwendungen müssen weiterhin Okcluder auf den Boden projizieren, um sicherzustellen, dass die Navigation nicht durch Unordnung/Tabellen usw. führt. Die genaueste Möglichkeit, dies zu erreichen, besteht darin, die Weltweiten Gitterdaten zu projizieren, die bereitgestellt werden, wenn die Szene mit dem EnableWorldMesh-Flag berechnet wird.
Visualisierung
Während die Visualisierung räumlicher Zuordnungen für Echtzeitfeedback der Umgebung verwendet werden kann, gibt es viele Szenarien, in denen die Einfachheit planarer und wasserdichter Objekte mehr Leistung oder visuelle Qualität bietet. Schattenprojektion- und Erdungstechniken, die mithilfe der räumlichen Zuordnung beschrieben werden, können ansprechender sein, wenn sie auf die von Quads bereitgestellten planaren Oberflächen oder das planare wasserdichte Gitter projiziert werden. Dies gilt insbesondere für Umgebungen/Szenarien, in denen eine gründliche Vorabüberprüfung nicht optimal ist, da die Szene ableiten und vollständige Umgebungen und planare Annahmen Artefakte minimieren.
Darüber hinaus wird die Gesamtanzahl der von Spatial Mapping zurückgegebenen Oberflächen durch den internen räumlichen Cache begrenzt, während die Version des Spatial Mapping-Gitters von Scene Understanding auf räumliche Zuordnungsdaten zugreifen kann, die nicht zwischengespeichert werden. Aus diesem Grund eignet sich Szenenverständnis besser zum Erfassen von Gitterdarstellungen für größere Räume (z. B. größer als ein einzelner Raum) für die Visualisierung oder weitere Gitterverarbeitung. Das mit EnableWorldMesh zurückgegebene Weltgitter weist durchweg eine konsistente Detailgenauigkeit auf, die eine ansprechendere Visualisierung ergeben kann, wenn es als Wireframe gerendert wird.