Wie das Ressourcenverwaltungssystem Sprachtags zuordnet
Im vorherigen Thema (Wie das Ressourcenverwaltungssystem Ressourcen zuordnet und auswählt) wird die Zuordnung von Qualifizierern im Allgemeinen behandelt. Dieses Thema konzentriert sich ausführlicher auf den Vergleich von Sprachtags.
Einführung
Ressourcen mit Sprachtagqualifizierern werden basierend auf der App-Laufzeitsprachenliste verglichen und bewertet. Definitionen zu den verschiedenen Sprachlisten finden Sie unter Verständnis der Benutzerprofilsprachen und der App-Manifestsprachen. Der Abgleich für die erste Sprache in einer Liste erfolgt vor dem Abgleich der zweiten Sprache in einer Liste, auch für andere regionale Varianten. Beispielsweise wird eine Ressource für en-GB über eine fr-CA-Ressource ausgewählt, wenn die App-Laufzeitsprache en-US ist. Nur wenn es keine Ressourcen für eine Form von en gibt, wird eine Ressource für fr-CA ausgewählt (beachten Sie, dass die Standardsprache der App in diesem Fall nicht auf eine Form von en eingestellt werden kann).
Der Bewertungsmechanismus verwendet Daten, die in der BCP-47-Subtagregistrierung und anderen Datenquellen enthalten sind. Er ermöglicht einen Bewertungsverlauf mit unterschiedlichen Übereinstimmungsqualitäten und wählt, wenn mehrere Kandidaten verfügbar sind, den Kandidaten mit der besten Übereinstimmungsbewertung aus.
Sie können also Sprachinhalte mit allgemeinen Begriffen kennzeichnen, aber Sie können bei Bedarf auch spezifische Inhalte angeben. Ihre App könnte zum Beispiel viele englische Zeichenketten enthalten, die sowohl in den Vereinigten Staaten als auch in Großbritannien und anderen Regionen üblich sind. Wenn Sie diese Zeichenketten als „en“ (Englisch) markieren, sparen Sie Speicherplatz und Lokalisierungsaufwand. Wenn Unterscheidungen getroffen werden müssen, wie z.B. bei einer Zeichenkette, die das Wort „color/colour“ enthält, können die US-amerikanische und die britische Version separat mit den Subtags „en-US“ und „en-GB“ für Sprache und Region gekennzeichnet werden.
Sprachkennzeichen
Sprachen werden mit normalisierten, wohlgeformten BCP-47-Sprachtags identifiziert. Subtag-Komponenten werden in der BCP-47-Subtagregistrierung definiert. Die normale Struktur für ein BCP-47-Sprachtag besteht aus einem oder mehreren der folgenden Subtagelemente.
- Language Subtag (erforderlich).
- Skript-Subtag (der anhand der in der Subtag-Registrierung angegebenen Standardwerte abgeleitet werden kann).
- Regions-Subtag (Option).
- Variant-Subtag (Option).
Zusätzliche Subtag-Elemente können vorhanden sein, aber sie haben einen unerheblichen Einfluss auf den Sprachabgleich. Es gibt keine Sprachbereiche, die mit dem Wild-Karte („“), z.B. „en-“, definiert sind.
Abgleichen von zwei Sprachen
Wenn Windows zwei Sprachen vergleicht, erfolgt dies in der Regel im Kontext eines größeren Prozesses. Es kann sich im Kontext der Bewertung mehrerer Sprachen befinden, z.B. wenn Windows die Anwendungssprachenliste generiert (siehe Benutzerprofilsprachen und App-Manifest-Sprachen verstehen). Windows führt dies durch Abgleichen mehrerer Sprachen aus den Benutzereinstellungen mit den im App-Manifest angegebenen Sprachen aus. Der Vergleich kann sich auch im Kontext der Bewertung der Sprache zusammen mit anderen Qualifizierern für eine bestimmte Ressource befinden. Ein Beispiel dafür ist, dass Windows eine bestimmte Dateiressource in einen bestimmten Ressourcenkontext auflöst, wobei der Heimatort des Benutzers oder die aktuelle Skalierung oder dpi des Geräts als weitere Faktoren (neben der Sprache) in die Ressourcenauswahl einfließen.
Wenn zwei Sprachtags verglichen werden, wird dem Vergleich basierend auf der Nähe der Übereinstimmung eine Bewertung zugewiesen.
| Übereinstimmung | Ergebnis | Beispiel |
|---|---|---|
| Genaue Übereinstimmung | Am höchsten | en-AU : en-AU |
| Variant-Übereinstimmung (Sprache, Skript, Region, Variante) | en-AU-variant1 : en-AU-variant1-t-ja | |
| Regionszuordnung (Sprache, Skript, Region) | en-AU : en-AU-variant1 | |
| Partielle Übereinstimmung (Sprache, Skript) | ||
| - Übereinstimmung Makro-Region | en-AU : en-053 | |
| - Regionsneutrale Übereinstimmung | en-AU : en | |
| - Orthografische Affinitäts-Übereinstimmung (eingeschränkte Unterstützung) | en-AU : en-GB | |
| - Übereinstimmung der bevorzugten Region | en-AU : en-US | |
| - Übereinstimmung mit jeder Region | en-AU : en-CA | |
| Nicht festgelegte Sprache (Übereinstimmung mit jeder Sprache) | en-AU : und | |
| Keine Übereinstimmung (Skriptübereinstimmung oder Tag der Primärsprache stimmt nicht überein) | Niedrigste | en-AU : fr-FR |
Genaue Übereinstimmung
Die Tags sind exakt gleich (alle Subtag-Elemente stimmen überein). Ein Vergleich kann von einem Varianten- oder Regionsvergleich zu dieser Abgleichsart befördert werden. en-US entspricht z.B. en-US.
Variant-Übereinstimmung
Die Tags stimmen in den Subtags Sprache, Schrift, Region und Variante überein, unterscheiden sich aber in einigen anderen Punkten.
Übereinstimmung der Region
Die Tags stimmen in den Subtags Sprache, Schrift und Region überein, unterscheiden sich aber in einigen anderen Punkten. Beispielsweise entspricht de-DE-1996 de-DE und en-US-x-Pirate en-US.
Teilweise Übereinstimmungen
Die Tags stimmen in den Subtags Sprache und Schrift überein, unterscheiden sich aber in der Region oder einigen anderen Subtags. Beispielsweise stimmt en-US mit en oder en-US mit en-* überein.
Übereinstimmung Makro-Region
Die Tags stimmen in den Subtags für Sprache und Skript überein; Beide weisen Regions-Subtags auf, von denen einer eine Makro-Region angibt, der die andere Region umfasst. Die Subtags für Makro-Regionen sind immer numerisch und werden aus der Abteilung Statistik der Vereinten Nationen M.49 für Länder- und Ortsvorwahlen abgeleitet. Einzelheiten zu den umfassenden Beziehungen finden Sie unter Zusammensetzung der makrogeografischen (kontinentalen) Regionen, der geografischen Subregionen und ausgewählter wirtschaftlicher und anderer Gruppierungen.
Notiz UN-Codes für „wirtschaftliche Gruppierungen“ oder „andere Gruppierungen“ werden in BCP-47 nicht unterstützt.
Notiz: Ein Tag mit dem Makro-Region-Subtag „001“ wird als Äquivalent zu einem regionsneutralen Tag betrachtet. Beispielsweise werden „es-001“ und "es" als Synonym behandelt.
Regionsneutrale Übereinstimmung
Die Tags stimmen in Subtags für Sprache und Skript überein, und nur ein Tag verfügt über ein Regionstag. Eine übergeordnete Übereinstimmung wird gegenüber anderen partiellen Übereinstimmungen bevorzugt.
Übereinstimmung der orthografischen Affinität
Die Tags stimmen für Subtags für Sprache und Skript überein, und die Regions-Subtags weisen eine orthografische Affinität auf. Die Affinität beruht auf Daten, die in Windows verwaltet werden und sprachspezifische affine Regionen definieren, zum Beispiel „en-IE“ und „en-GB“.
Übereinstimmung der bevorzugten Region
Die Tags stimmen für Subtags für Sprache und Skript überein, und eines der Regions-Subtags ist das Standard-Regions-Subtag für die Sprache. Beispielsweise ist „fr-FR“ der Standardbereich für das Subtag „fr“. Also ist fr-FR eine bessere Übereinstimmung für fr-BE als fr-CA. Dies beruht auf Daten, die in Windows verwaltet werden und eine Standardregion für jede Sprache definieren, in der Windows lokalisiert ist.
Gleichgeordnete Übereinstimmung
Die Tags stimmen für Subtags für Sprache und Skript überein, und beide weisen Regions-Subtags auf, aber keine andere Beziehung wird zwischen ihnen definiert. Bei mehreren übereinstimmenden Geschwisterpaarungen ist das zuletzt aufgeführte Geschwisterpaar der Gewinner, falls es keine höhere Übereinstimmung gibt.
Nicht festgelegte Sprache
Eine Ressource kann als „und“ gekennzeichnet werden, um anzugeben, dass sie mit einer beliebigen Sprache übereinstimmt. Dieses Tag kann auch mit einem Skripttag verwendet werden, um Übereinstimmungen basierend auf dem Skript zu filtern. Beispielsweise entspricht „und-Latn“ jedem Sprachtag, das lateinische Schrift verwendet. Weitere Informationen finden Sie unten.
Nicht übereinstimmende Skripts
Wenn die Tags nur für das Primäre Sprachtag, aber nicht für das Skript übereinstimmen, wird das Paar als nicht übereinstimmend betrachtet und unter der Ebene einer gültigen Übereinstimmung bewertet.
Keine Übereinstimmung
Nicht übereinstimmende Subtags für primäre Sprachen werden unter der Ebene einer gültigen Übereinstimmung bewertet. Beispielsweise stimmt zh-Hant nicht mit zh-Hans überein.
Beispiele
Eine Benutzersprache „zh-Hans-CN“ (Chinesisch vereinfacht (China)) entspricht den folgenden Ressourcen in der angezeigten Prioritätsreihenfolge. Ein X gibt keine Übereinstimmung an.
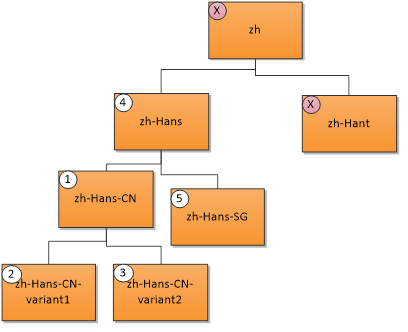
- Genaue Übereinstimmung; 2. & 3. Übereinstimmung der Region; 4. Übergeordnete Übereinstimmung; 5. Gleichgeordnete Übereinstimmung.
Wenn für ein Sprach-Subtag in der BCP-47-Subtag-Registrierung der Wert Suppress-Script definiert ist, erfolgt ein entsprechender Abgleich, der den Wert des unterdrückten Skript-Codes annimmt. So entspricht en-Latn-US zum Beispiel en-US. Im nächsten Beispiel lautet die Benutzersprache „en-AU“ (Englisch (Australien)).
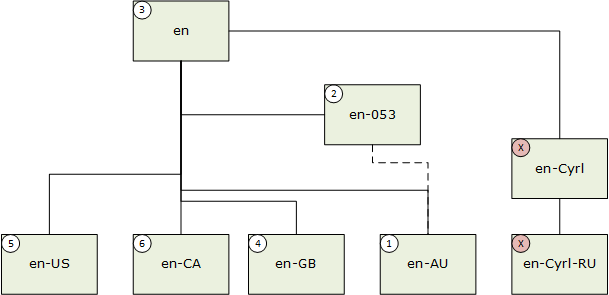
- Genaue Übereinstimmung; 2. Übereinstimmung Makro-Region; 3. Regionsneutrale Übereinstimmung; 4. Übereinstimmung der orthografischen Affinität; 5. Übereinstimmung der bevorzugten Region; 6. Gleichgeordnete Übereinstimmung.
Zuordnen einer Sprache zu einer Sprachliste
Manchmal erfolgt die Zuordnung als Teil eines größeren Abgleichprozesses einer einzelnen Sprache zu einer Liste von Sprachen. Es kann z.B. eine Übereinstimmung mit einer einzelnen sprachbasierten Ressource zur Sprachliste einer App geben. Die Bewertung der Übereinstimmung wird durch die Position der ersten übereinstimmenden Sprache in der Liste gewichtet. Je niedriger die Sprache in der Liste ist, desto niedriger ist die Bewertung.
Wenn die Sprachliste zwei oder mehr regionale Varianten mit den gleichen Sprach- und Skript-Subtags enthält, werden Vergleiche für das erste Sprachtag nur für genaue Übereinstimmungen, Varianten und Regionen bewertet. Die Bewertung partieller Übereinstimmungen wird auf die letzte regionale Variante verschoben. Auf diese Weise können Benutzer das Abgleichsverhalten für ihre Sprachliste präziser steuern. Das Abgleichverhalten kann beinhalten, dass eine exakte Übereinstimmung für ein zweites Element in der Liste gegenüber einer teilweisen Übereinstimmung für das erste Element in der Liste bevorzugt wird, wenn es ein drittes Element gibt, das mit der Sprache und Schrift des ersten Elements übereinstimmt. Im Folgenden sehen Sie ein Beispiel.
- Sprachenliste (in der Reihenfolge): „pt-PT“ (Portugiesisch (Portugal)), „en-US“ (Englisch (USA)), „pt-BR“ (Portugiesisch (Brasilien)).
- Ressourcen: „en-US“, „pt-BR“.
- Ressource mit der höheren Bewertung: „en-US“.
- Beschreibung: Der Vergleich beginnt mit „pt-PT“, findet aber keine genaue Übereinstimmung. Aufgrund der Anwesenheit von „pt-BR“ in der Sprachliste des Benutzers wird der teilweise Abgleich auf den Vergleich mit „pt-BR“ verschoben. Der nächste Sprachvergleich ist „en-US“, der eine genaue Übereinstimmung aufweist. Die Gewinner-Ressource lautet also „en-US“.
ODER
- Sprachenliste (in der Reihenfolge): „es-MX“ (Spanisch (Mexiko)), „es-HO“ (Spanisch (Honduras)).
- Ressourcen: „en-ES“, „es-HO“.
- Ressource mit der höheren Bewertung: „es-HO“.
Nicht festgelegte Sprache („und“)
Das Sprachtag „und“ kann verwendet werden, um eine Ressource anzugeben, die mit jeder Sprache übereinstimmt, wenn keine bessere Übereinstimmung vorliegt. Es kann als ähnlich wie der BCP-47-Sprachbereich „“ oder „-<Script>„ angesehen werden. Im Folgenden sehen Sie ein Beispiel.
- Sprachliste: „en-US“, „zh-Hans-CN“.
- Ressourcen: „zh-Hans-CN“, „und“.
- Ressource mit der höheren Bewertung: „und“.
- Beschreibung: Der Vergleich beginnt mit „en-US“, findet aber keine Übereinstimmung basierend auf „en“ (teilweise oder besser). Da eine Ressource mit „und“ markiert ist, verwendet der übereinstimmende Algorithmus dies.
Mit dem Tag „und“ können mehrere Sprachen eine einzelne Ressource gemeinsam nutzen und einzelne Sprachen als Ausnahmen behandelt werden. Beispiel:
- Sprachliste: „zh-Hans-CN“, „en-US“.
- Ressourcen: „zh-Hans-CN“, „und“.
- Ressource mit dem höheren Wert: „zh-Hans-CN“.
- Beschreibung: Der Vergleich findet eine genaue Übereinstimmung für das erste Element und sucht daher nicht nach der Ressource mit der Bezeichnung „und“.
Sie können „und“ mit einem Skripttag verwenden, um Ressourcen nach Skript zu filtern. Beispiel:
- Sprachliste: „ru“.
- Ressourcen: „und-Latn“, „und-Cyrl“, „und-Arab“.
- Ressource mit der höheren Bewertung: „und-Cyrl“.
- Beschreibung: Der Vergleich findet keine Übereinstimmung für „ru“ (teilweise oder besser), und entspricht daher dem Sprachtag „und“. Der Suppress-Script-Wert „Cyrl“, der dem Sprachtag „ru“ zugeordnet ist, entspricht der Ressource „und-Cyrl“.
Orthografische regionale Affinität
Wenn zwei Sprach-Tags mit unterschiedlichen Regions-Subtags abgeglichen werden, können bestimmte Paare von Regionen eine höhere Affinität zueinander haben als andere. Die einzigen unterstützten affinen Gruppen sind für Englisch („en“). Die Region-Subtags „PH“ (Philippinen) und „LR“ (Liberia) haben orthografische Affinität zum Subtag „US“. Alle anderen Regions-Subtags sind mit dem Untergeordneten Tag „GB“ (Vereinigtes Königreich) verknüpft. Wenn also sowohl „en-US“- als auch „en-GB“-Ressourcen verfügbar sind, erhält eine Sprachliste mit „en-HK“ (Englisch (Hongkong SAR)) mit „en-GB“-Ressourcen eine höhere Punktzahl als mit „en-US“-Ressourcen.
Behandeln von Sprachen mit vielen regionalen Varianten
Bestimmte Sprachen haben große Sprachgemeinschaften in verschiedenen Regionen, die unterschiedliche Varianten dieser Sprache verwenden - Sprachen wie Englisch, Französisch und Spanisch, die zu den am häufigsten unterstützten Sprachen in mehrsprachigen Apps gehören. Regionale Unterschiede können Unterschiede in der Orthografie (z.B. „Color“ und „Colour“) oder Dialektunterschiede wie Vokabular (z. B. „Truck“ oder „Lorry“) umfassen.
Diese Sprachen mit bedeutenden regionalen Varianten stellen bei der Entwicklung einer weltweit einsetzbaren App eine gewisse Herausforderung dar: „Wie viele verschiedene regionale Varianten sollten unterstützt werden?“ „Welche?“ „Wie kann ich diese regionalen Varianten für meine App am kostengünstigsten verwalten?“ Es würde den Rahmen dieses Themas sprengen, all diese Fragen zu beantworten. Die Sprachabgleichsmechanismen in Windows bieten jedoch Funktionen, die Ihnen bei der Behandlung regionaler Varianten helfen können.
Apps unterstützen oft nur eine einzige Variante einer bestimmten Sprache. Nehmen wir an, eine App verfügt lediglich für eine einzige Variante des Englischen über Ressourcen, die von Englischsprachigen genutzt werden soll, unabhängig davon, aus welcher Region sie kommen. In diesem Fall würde das Tag „en“ ohne Regions-Subtag diese Erwartung widerspiegeln. Apps haben jedoch möglicherweise in der Vergangenheit ein Tag wie „en-US“ verwendet, das ein Regions-Subtag enthält. In diesem Fall funktioniert das auch: Die App verwendet nur eine Variante des Englischen, und Windows gleicht eine Ressource, die für eine regionale Variante gekennzeichnet ist, mit einer Spracheinstellung des Benutzers für eine andere regionale Variante auf angemessene Weise ab.
Wenn jedoch zwei oder mehr regionale Varianten unterstützt werden sollen, kann ein Unterschied wie „en“ gegenüber „en-US“ erhebliche Auswirkungen auf die Benutzerfreundlichkeit haben, und es ist wichtig zu überlegen, welche regionalen Subtags verwendet werden sollen.
Angenommen, Sie möchten separate französische Lokalisierungen für das in Kanada verwendete Französisch und das europäische Französisch anbieten. Für Kanadisches Französisch kann „fr-CA“ verwendet werden. Für europäische Muttersprachler wird die Lokalisierung auf Französisch (Frankreich) erfolgen, so dass „fr-FR“ dafür verwendet werden kann. Aber was ist, wenn ein Benutzer aus Belgien kommt und die Sprache „fr-BE“ bevorzugt, was bekommt er dann? Die Region „BE“ unterscheidet sich sowohl von „FR“ als auch von „CA“, und schlägt für beide eine Übereinstimmung mit „beliebiger Region“ vor. Frankreich ist jedoch die bevorzugte Region für Französisch, und daher wird die „fr-FR“ in diesem Fall als die beste Übereinstimmung betrachtet.
Nehmen wir an, Sie haben Ihre App zunächst nur für eine Variante des Französischen lokalisiert, indem Sie französische (Frankreich) Zeichenketten verwendet haben, diese aber generisch als „fr“ qualifiziert haben, und dann möchten Sie Unterstützung für kanadisches Französisch hinzufügen. Wahrscheinlich müssen nur bestimmte Ressourcen für Kanadisches Französisch neu übersetzt werden. Sie können alle Original-Assets weiter verwenden, indem Sie sie als „fr“ qualifizieren, und nur die kleine Gruppe neuer Assets mit „fr-CA“ hinzufügen. Wenn die Benutzerspracheinstellung „fr-CA“ lautet, hat die Ressource „fr-CA“ eine höhere Übereinstimmungsbewertung als die Ressource „fr“. Wenn der Benutzer jedoch eine andere Variante des Französischen bevorzugt, dann ist das regionsneutrale Asset „fr“ besser geeignet als das Asset „fr-CA“.
Ein weiteres Beispiel: Nehmen wir an, Sie möchten separate spanische Lokalisierungen für spanische und lateinamerikanische Muttersprachler anbieten. Nehmen Sie weiter an, dass die Übersetzungen für Lateinamerika von einem Anbieter in Mexiko geliefert wurden. Sollten Sie „es-ES“ (Spanien) und „es-MX“ (Mexiko) für zwei Gruppen von Ressourcen verwenden? Wenn Sie das täten, könnte das zu Problemen für Muttersprachler aus anderen lateinamerikanischen Regionen wie Argentinien oder Kolumbien führen, da diese die „es-ES“-Ressourcen erhalten würden. In diesem Fall gibt es eine bessere Alternative: Sie können ein Makroregion-Subtag „es-419“ verwenden, um zu verdeutlichen, dass Sie die Assets für Sprecher aus einem beliebigen Teil Lateinamerikas oder der Karibik verwenden möchten.
Regionsneutrale Sprachtags und Subtags für Makroregionen können sehr effektiv sein, wenn Sie mehrere regionale Varianten unterstützen möchten. Um die Anzahl der benötigten separaten Ressourcen zu minimieren, können Sie eine bestimmte Ressource so qualifizieren, dass sie den größtmöglichen Geltungsbereich widerspiegelt, für den sie geeignet ist. Ergänzen Sie dann bei Bedarf eine allgemein anwendbare Ressource mit einer spezifischeren Variante. Eine Ressource mit einem regionsneutralen Sprachqualifizierer wird für Benutzer aller Regionen verwendet, es sei denn, es gibt eine andere Datei mit einem regionsspezifischen Qualifizierer, der für diesen Benutzer gilt. Zum Beispiel wird eine „en“-Ressource für einen australisch-englischen Benutzer passen, aber ein Asset mit „en-053“ (Englisch, wie es in Australien oder Neuseeland verwendet wird) wird eine bessere Übereinstimmung für diesen Benutzer sein, während ein Asset mit „en-AU“ die bestmögliche Übereinstimmung sein wird.
Englisch braucht besondere Berücksichtigung. Wenn eine App Lokalisierung für zwei Englisch-Varianten hinzufügt, werden diese wahrscheinlich für US-Englisch und für UK oder „internationales“ Englisch verwendet. Wie bereits erwähnt, folgen bestimmte Regionen außerhalb der USA den Rechtschreibkonventionen der Vereinigten Staaten, und die Windows-Spracherkennung berücksichtigt dies. In diesem Szenario wird nicht empfohlen, das regionsneutrale Tag „en“ für eine der Varianten zu verwenden; Verwenden Sie stattdessen „en-GB“ und „en-US“. (Wenn für eine bestimmte Ressource keine separaten Varianten erforderlich sind, kann „en“ jedoch verwendet werden.) Wenn entweder „en-GB“ oder „en-US“ durch „en“ ersetzt wird, wird dies die orthografische regionale Affinität von Windows beeinträchtigen. Wenn eine dritte englische Lokalisierung hinzugefügt wird, verwenden Sie für die zusätzlichen Varianten je nach Bedarf ein spezifisches oder Makro-Region-Subtag (z.B. „en-CA“, „en-AU“ oder „en-053“), aber verwenden Sie weiterhin „en-GB“ und „en-US“.
Zugehörige Themen
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für