CPUSets für die Entwicklung von Spielen
Einführung
Die Universelle Windows-Plattform (UWP) steht im Mittelpunkt einer breiten Palette von Elektronischen Geräten für Verbraucher. Daher ist eine allgemeine API erforderlich, um die Anforderungen aller Arten von Anwendungen von Spielen bis hin zu eingebetteten Apps zu Unternehmenssoftware zu erfüllen, die auf Servern ausgeführt wird. Indem Sie die richtigen Informationen nutzen, die von der API bereitgestellt werden, können Sie sicherstellen, dass Ihr Spiel auf jeder Hardware optimal ausgeführt wird.
CPUSets-API
Die CPUSets-API bietet Kontrolle darüber, welche CPU-Sätze verfügbar sind, damit Threads geplant werden können. Zwei Funktionen stehen zur Verfügung, um zu steuern, wo Threads geplant sind:
- SetProcessDefaultCpuSets – Diese Funktion kann verwendet werden, um anzugeben, auf welchen CPU-Sätzen neue Threads ausgeführt werden können, wenn sie bestimmten CPU-Sätzen nicht zugewiesen sind.
- SetThreadSelectedCpuSets – Mit dieser Funktion können Sie die CPU-Sätze einschränken, auf denen ein bestimmter Thread ausgeführt werden kann.
Wenn die SetProcessDefaultCpuSets-Funktion nie verwendet wird, werden neu erstellte Threads möglicherweise für alle CPU-Sätze geplant, die für Ihren Prozess verfügbar sind. In diesem Abschnitt werden die Grundlagen der CPUSets-API erläutert.
GetSystemCpuSetInformation
Die erste API, die zum Sammeln von Informationen verwendet wird, ist die GetSystemCpuSetInformation-Funktion . Diese Funktion füllt Informationen in einem Array von SYSTEM_CPU_SET_INFORMATION Objekten auf, die vom Titelcode bereitgestellt werden. Der Speicher für das Ziel muss durch Spielcode zugewiesen werden, dessen Größe durch Aufrufen von GetSystemCpuSetInformation selbst bestimmt wird. Dies erfordert zwei Aufrufe von GetSystemCpuSetInformation , wie im folgenden Beispiel gezeigt.
unsigned long size;
HANDLE curProc = GetCurrentProcess();
GetSystemCpuSetInformation(nullptr, 0, &size, curProc, 0);
std::unique_ptr<uint8_t[]> buffer(new uint8_t[size]);
PSYSTEM_CPU_SET_INFORMATION cpuSets = reinterpret_cast<PSYSTEM_CPU_SET_INFORMATION>(buffer.get());
GetSystemCpuSetInformation(cpuSets, size, &size, curProc, 0);
Jede Instanz von SYSTEM_CPU_SET_INFORMATION zurückgegeben enthält Informationen zu einer eindeutigen Verarbeitungseinheit, die auch als CPU-Satz bezeichnet wird. Dies bedeutet nicht unbedingt, dass es ein einzigartiges physisches Hardwarestück darstellt. CPUs, die Hyperthreading verwenden, verfügen über mehrere logische Kerne, die auf einem einzigen physischen Verarbeitungskern ausgeführt werden. Das Planen mehrerer Threads auf verschiedenen logischen Kernen, die sich auf demselben physischen Kern befinden, ermöglicht die Optimierung der Ressourcen auf Hardwareebene, die andernfalls zusätzliche Arbeit auf Kernelebene erfordern würde. Zwei Threads, die auf separaten logischen Kernen auf demselben physischen Kern geplant sind, müssen CPU-Zeit gemeinsam nutzen, aber effizienter ausgeführt werden, als wenn sie für denselben logischen Kern geplant wurden.
SYSTEM_CPU_SET_INFORMATION
Die Informationen in jeder Instanz dieser Datenstruktur, die von GetSystemCpuSetInformation zurückgegeben wird, enthält Informationen zu einer eindeutigen Verarbeitungseinheit, für die Threads geplant werden können. Angesichts des möglichen Bereichs von Zielgeräten können viele Informationen in der SYSTEM_CPU_SET_INFORMATION Datenstruktur nicht für die Spieleentwicklung gelten. Tabelle 1 enthält eine Erläuterung von Datenelementen, die für die Spieleentwicklung nützlich sind.
Tabelle 1. Datenmitglieder, die für die Spieleentwicklung nützlich sind.
| Membername | Datentyp | BESCHREIBUNG |
|---|---|---|
| type | CPU_SET_INFORMATION_TYPE | Der Informationstyp in der Struktur. Wenn der Wert dieses Werts nicht "CpuSetInformation" lautet, sollte er ignoriert werden. |
| Kennung | unsigned long | Die ID des angegebenen CPU-Satzes. Dies ist die ID, die mit CPU-Set-Funktionen wie SetThreadSelectedCpuSets verwendet werden soll. |
| Group | unsigned short | Gibt die "Prozessorgruppe" des CPU-Satzes an. Prozessorgruppen ermöglichen es einem PC, mehr als 64 logische Kerne zu haben, und das Hot Swapping von CPUs während der Ausführung des Systems zu ermöglichen. Es ist ungewöhnlich, einen PC zu sehen, der kein Server mit mehr als einer Gruppe ist. Wenn Sie keine Anwendungen schreiben, die auf großen Servern oder Serverfarmen ausgeführt werden sollen, empfiehlt es sich, CPU-Sätze in einer einzelnen Gruppe zu verwenden, da die meisten Heimanwender-PCs nur über eine Prozessorgruppe verfügen. Alle anderen Werte in dieser Struktur sind relativ zur Gruppe. |
| LogicalProcessorIndex | unsigned char | Relativer Gruppenindex des CPU-Satzes |
| CoreIndex | unsigned char | Gruppenrelativer Index des physischen CPU-Kerns, in dem sich der CPU-Satz befindet |
| LastLevelCacheIndex | unsigned char | Gruppenrelativer Index des letzten Caches, der diesem CPU-Satz zugeordnet ist. Dies ist der langsamste Cache, es sei denn, das System verwendet NUMA-Knoten, in der Regel den L2- oder L3-Cache. |
Die anderen Datenmber stellen Informationen bereit, die wahrscheinlich keine Beschreibung von CPUs auf Heimanwender-PCs oder anderen Heimanwendergeräten darstellen und unwahrscheinlich sind. Die von den zurückgegebenen Daten bereitgestellten Informationen können dann verwendet werden, um Threads auf unterschiedliche Weise zu organisieren. Der Abschnitt "Überlegungen zur Spieleentwicklung " dieses Whitepapers enthält einige Möglichkeiten, diese Daten zur Optimierung der Threadzuordnung zu nutzen.
Im Folgenden sind einige Beispiele für die Art von Informationen aufgeführt, die aus UWP-Anwendungen gesammelt werden, die auf verschiedenen Hardwaretypen ausgeführt werden.
Tabelle 2: Informationen, die von einer UWP-App zurückgegeben werden, die auf einem Microsoft Lumia 950 ausgeführt wird. Dies ist ein Beispiel für ein System mit mehreren Caches der letzten Ebene. Das Lumia 950 verfügt über einen Snapdragon-Prozess von Qualcomm 808, der einen Dual core Arm Cortex A57 und quad core Arm Cortex A53 CPUs enthält.
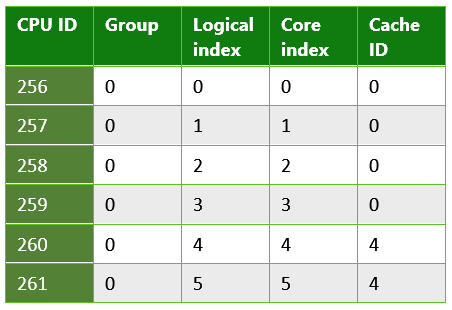
Tabelle 3. Informationen, die von einer UWP-App zurückgegeben werden, die auf einem typischen PC ausgeführt wird. Dies ist ein Beispiel für ein System, das Hyperthreading verwendet; Jeder physische Kern verfügt über zwei logische Kerne, auf die Threads geplant werden können. In diesem Fall enthielt das System eine Intel Xenon CPU E5-2620.
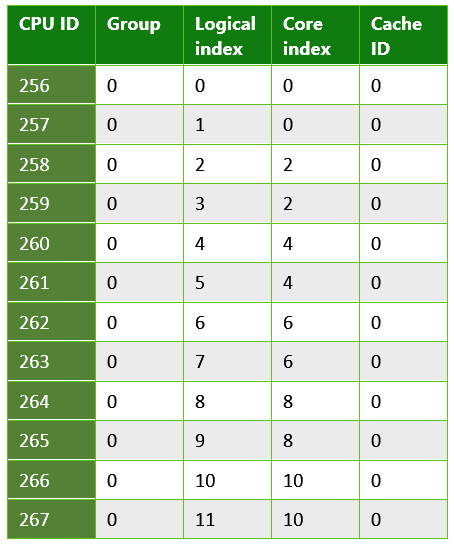
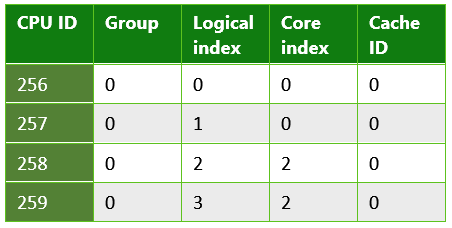
Tabelle 4. Informationen, die von einer UWP-App zurückgegeben werden, die auf einem Quad-Core-Microsoft Surface Pro 4 ausgeführt wird. Dieses System hatte eine Intel Core i5-6300 CPU.
SetThreadSelectedCpuSets
Da nun Informationen zu den CPU-Sätzen verfügbar sind, können sie zum Organisieren von Threads verwendet werden. Das Handle eines mit CreateThread erstellten Threads wird zusammen mit einem Array von IDs der CPU-Sätze, für die der Thread geplant werden kann, an diese Funktion übergeben. Ein Beispiel für die Verwendung wird im folgenden Code veranschaulicht.
HANDLE audioHandle = CreateThread(nullptr, 0, AudioThread, nullptr, 0, nullptr);
unsigned long retsize = 0;
(void)GetSystemCpuSetInformation( nullptr, 0, &retsize,
GetCurrentProcess(), 0);
std::unique_ptr<uint8_t[]> data( new uint8_t[retsize] );
if ( !GetSystemCpuSetInformation(
reinterpret_cast<PSYSTEM_CPU_SET_INFORMATION>( data.get() ),
retsize, &retsize, GetCurrentProcess(), 0) )
{
// Error!
}
std::vector<DWORD> cores;
uint8_t const * ptr = data.get();
for( DWORD size = 0; size < retsize; ) {
auto info = reinterpret_cast<const SYSTEM_CPU_SET_INFORMATION*>( ptr );
if ( info->Type == CpuSetInformation ) {
cores.push_back( info->CpuSet.Id );
}
ptr += info->Size;
size += info->Size;
}
if ( cores.size() >= 2 ) {
SetThreadSelectedCpuSets(audioHandle, cores.data(), 2);
}
In diesem Beispiel wird ein Thread basierend auf einer als "AudioThread" deklarierten Funktion erstellt. Dieser Thread darf dann auf einem von zwei CPU-Sätzen geplant werden. Der Threadbesitz des CPU-Satzes ist nicht exklusiv. Threads, die erstellt werden, ohne für einen bestimmten CPU-Satz gesperrt zu sein, können Zeit aus dem AudioThread dauern. Ebenso können auch andere erstellte Threads zu einem späteren Zeitpunkt auf einen oder beide dieser CPU-Sätze gesperrt werden.
SetProcessDefaultCpuSets
Umgekehrt zu SetThreadSelectedCpuSets ist SetProcessDefaultCpuSets. Wenn Threads erstellt werden, müssen sie nicht in bestimmte CPU-Sätze gesperrt werden. Wenn diese Threads nicht für bestimmte CPU-Sätze (z. B. von Ihrem Renderthread oder Audiothread) ausgeführt werden sollen, können Sie diese Funktion verwenden, um anzugeben, auf welchen Kernen diese Threads geplant werden dürfen.
Überlegungen zur Spieleentwicklung
Wie wir gesehen haben, bietet die CPUSets-API viele Informationen und Flexibilität bei der Planung von Threads. Anstatt den Bottom-up-Ansatz zu verwenden, um nach Verwendungsmöglichkeiten für diese Daten zu suchen, ist es effektiver, den Top-Down-Ansatz zu finden, um zu ermitteln, wie die Daten für allgemeine Szenarien verwendet werden können.
Arbeiten mit zeitkritischen Threads und Hyperthreading
Diese Methode ist effektiv, wenn Ihr Spiel über einige Threads verfügt, die in Echtzeit zusammen mit anderen Arbeitsthreads ausgeführt werden müssen, die relativ wenig CPU-Zeit erfordern. Einige Aufgaben, z. B. kontinuierliche Hintergrundmusik, müssen ohne Unterbrechung ausgeführt werden, um ein optimales Spielerlebnis zu erzielen. Selbst ein einzelner Frame der Starvation für einen Audiothread kann zu Popping oder Glitching führen, daher ist es wichtig, dass er die erforderliche CPU-Zeit jedes Frames empfängt.
Die Verwendung von SetThreadSelectedCpuSets in Verbindung mit SetProcessDefaultCpuSets kann sicherstellen, dass ihre schweren Threads durch alle Arbeitsthreads unterbrechungsfrei bleiben. SetThreadSelectedCpuSets können verwendet werden, um Ihre schweren Threads bestimmten CPU-Sätzen zuzuweisen. SetProcessDefaultCpuSets können dann verwendet werden, um sicherzustellen, dass alle nicht zugewiesenen Threads auf anderen CPU-Sätzen platziert werden. Bei CPUs, die Hyperthreading verwenden, ist es auch wichtig, logische Kerne auf demselben physischen Kern zu berücksichtigen. Arbeitsthreads sollten nicht auf logischen Kernen ausgeführt werden dürfen, die denselben physischen Kern wie ein Thread verwenden, den Sie mit Echtzeit-Reaktionsfähigkeit ausführen möchten. Der folgende Code veranschaulicht, wie Sie ermitteln können, ob ein PC Hyperthreading verwendet.
unsigned long retsize = 0;
(void)GetSystemCpuSetInformation( nullptr, 0, &retsize,
GetCurrentProcess(), 0);
std::unique_ptr<uint8_t[]> data( new uint8_t[retsize] );
if ( !GetSystemCpuSetInformation(
reinterpret_cast<PSYSTEM_CPU_SET_INFORMATION>( data.get() ),
retsize, &retsize, GetCurrentProcess(), 0) )
{
// Error!
}
std::set<DWORD> cores;
std::vector<DWORD> processors;
uint8_t const * ptr = data.get();
for( DWORD size = 0; size < retsize; ) {
auto info = reinterpret_cast<const SYSTEM_CPU_SET_INFORMATION*>( ptr );
if ( info->Type == CpuSetInformation ) {
processors.push_back( info->CpuSet.Id );
cores.insert( info->CpuSet.CoreIndex );
}
ptr += info->Size;
size += info->Size;
}
bool hyperthreaded = processors.size() != cores.size();
Wenn das System Hyperthreading verwendet, ist es wichtig, dass der Satz der Standard-CPU-Sätze keine logischen Kerne auf demselben physischen Kern wie Echtzeitthreads enthält. Wenn das System nicht hyperthreading ist, ist es nur erforderlich, sicherzustellen, dass die Standard-CPU-Sätze nicht den gleichen Kern wie der CPU-Satz enthalten, der ihren Audiothread ausführt.
Ein Beispiel für das Organisieren von Threads basierend auf physischen Kernen finden Sie im CPUSets-Beispiel, das im GitHub-Repository verfügbar ist, das im Abschnitt "Zusätzliche Ressourcen " verknüpft ist.
Reduzieren der Kosten für die Cachekohärenz mit dem Cache der letzten Ebene
Die Cachekohärenz ist das Konzept, bei dem zwischengespeicherter Arbeitsspeicher für mehrere Hardwareressourcen identisch ist, die auf dieselben Daten reagieren. Wenn Threads auf unterschiedlichen Kernen geplant sind, aber an denselben Daten arbeiten, arbeiten sie möglicherweise an separaten Kopien dieser Daten in verschiedenen Caches. Um die richtigen Ergebnisse zu erzielen, müssen diese Caches miteinander kohärent bleiben. Die Aufrechterhaltung der Kohärenz zwischen mehreren Caches ist relativ teuer, ist jedoch erforderlich, damit ein mehrkerniges System ausgeführt werden kann. Darüber hinaus ist es völlig außerhalb der Kontrolle des Clientcodes; Das zugrunde liegende System funktioniert unabhängig voneinander, um Caches auf dem neuesten Stand zu halten, indem auf freigegebene Speicherressourcen zwischen Kernen zugegriffen wird.
Wenn Ihr Spiel über mehrere Threads verfügt, die eine besonders große Datenmenge gemeinsam nutzen, können Sie die Kosten der Cachekohärenz minimieren, indem Sie sicherstellen, dass sie für CPU-Sätze geplant sind, die einen Cache der letzten Ebene gemeinsam nutzen. Der Cache der letzten Ebene ist der langsamste Cache, der für einen Kern auf Systemen verfügbar ist, die keine NUMA-Knoten verwenden. Es ist extrem selten, dass ein Gaming-PC NUMA-Knoten verwendet. Wenn Kerne keinen Cache der letzten Ebene gemeinsam nutzen, erfordert die Aufrechterhaltung der Kohärenz den Zugriff auf eine höhere Ebene und daher langsamere Speicherressourcen. Das Sperren von zwei Threads an separate CPU-Sätze, die einen Cache gemeinsam nutzen, und ein physischer Kern kann eine noch bessere Leistung bieten als die Planung auf separaten physischen Kernen, wenn sie nicht mehr als 50 % der Zeit in einem bestimmten Frame benötigen.
In diesem Codebeispiel wird gezeigt, wie Sie bestimmen, ob Threads, die häufig kommunizieren, einen Cache der letzten Ebene gemeinsam nutzen können.
unsigned long retsize = 0;
(void)GetSystemCpuSetInformation(nullptr, 0, &retsize,
GetCurrentProcess(), 0);
std::unique_ptr<uint8_t[]> data(new uint8_t[retsize]);
if (!GetSystemCpuSetInformation(
reinterpret_cast<PSYSTEM_CPU_SET_INFORMATION>(data.get()),
retsize, &retsize, GetCurrentProcess(), 0))
{
// Error!
}
bool sharedcache = false;
std::map<unsigned char, std::vector<const SYSTEM_CPU_SET_INFORMATION*>> cachemap;
uint8_t const * ptr = data.get();
for(DWORD size = 0; size < retsize;)
{
auto cpuset = reinterpret_cast<const SYSTEM_CPU_SET_INFORMATION*>(ptr);
if (cpuset->Type == CpuSetInformation)
{
if (cachemap.find(cpuset->CpuSet.LastLevelCacheIndex) == cachemap.end())
{
std::pair<unsigned char, std::vector<const SYSTEM_CPU_SET_INFORMATION*>> newvalue;
newvalue.first = cpuset->CpuSet.LastLevelCacheIndex;
newvalue.second.push_back(cpuset);
cachemap.insert(newvalue);
}
else
{
sharedcache = true;
cachemap[cpuset->CpuSet.LastLevelCacheIndex].push_back(cpuset);
}
}
ptr += cpuset->Size;
size += cpuset->Size;
}
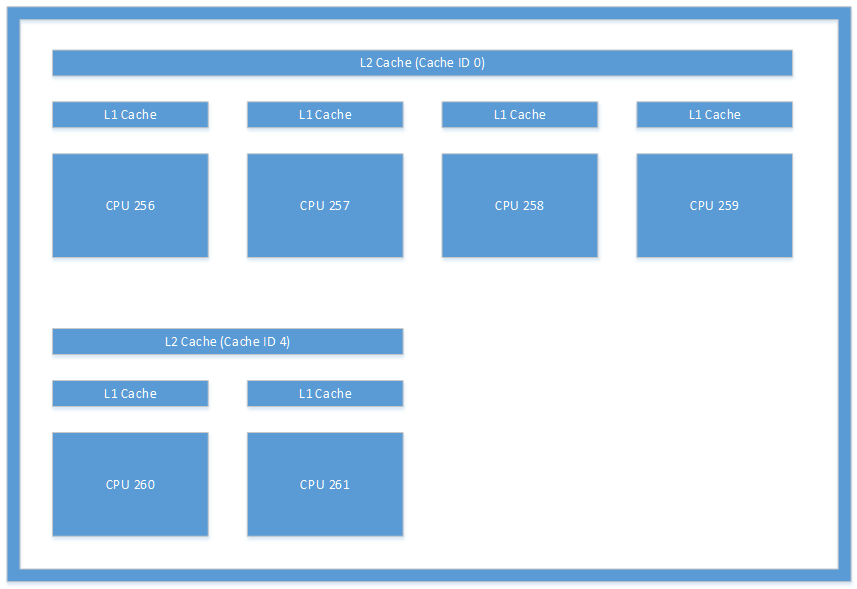
Das in Abbildung 1 dargestellte Cachelayout ist ein Beispiel für den Typ des Layouts, den Sie möglicherweise aus einem System sehen. Diese Abbildung zeigt die Caches in einem Microsoft Lumia 950. Die Interthreadkommunikation zwischen CPU 256 und CPU 260 würde erheblichen Aufwand verursachen, da das System die L2-Caches kohärent halten müsste.
Abbildung 1. Cachearchitektur auf einem Microsoft Lumia 950-Gerät.
Zusammenfassung
Die cpuSets-API, die für die UWP-Entwicklung verfügbar ist, bietet eine beträchtliche Menge an Informationen und Kontrolle über Ihre Multithreading-Optionen. Die hinzugefügten Komplexitäten im Vergleich zu früheren Multithread-APIs für die Windows-Entwicklung haben eine gewisse Lernkurve, aber die erhöhte Flexibilität ermöglicht letztendlich eine bessere Leistung in einer Reihe von Heimanwender-PCs und anderen Hardwarezielen.