Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die InkAnalysis-APIs bieten Tablet-PC-Entwicklern leistungsstarke Tools zum programmgesteuerten Untersuchen von Freihandeingaben. Die API klassifiziert Freihand in aussagekräftige Kategorien wie Wörter, Linien, Absätze und Zeichnungen.
Sie können jede Klassifizierung auf verschiedene Arten verwenden, einschließlich der Verbesserung der Erkennungsergebnisse für die Handschrift.
Grundlagen der Freihandanalyse
In diesem Abschnitt wird die Tablet PC Platform-Freihandanalysetechnologie vorgestellt und erläutert, wann und wie sie verwendet wird.
Die InkAnalysis-APIs kombinieren effektiv zwei unterschiedliche, aber ergänzende Technologien: Handschrifterkennung und Layoutklassifizierung. Die Kombination dieser beiden Technologien führt definitiv zu größeren Ergebnissen als die Einzelteile.
Die Handschrifterkennung ist die berechnungsbasierte Analyse handschriftlicher digitaler Freihandeingaben, um zeichenbasierte Interpretationen in einer bestimmten Sprache zurückzugeben. Das heißt, mit der Handschrifterkennung "liest" der Computer die Handschrift einer Person.
Die Freihandanalyse kann weiter in Freihandklassifizierung und Layoutanalyse unterteilt werden. Bei der Freihandklassifizierung handelt es sich um die rechnerische Aufteilung von Freihand in semantisch aussagekräftige Einheiten wie Absätze, Linien, Wörter und Zeichnungen. Die Layoutanalyse ist die berechnungsbasierte Untersuchung von Freihandeingaben, um die Position der Freihandfarbe auf der Freihandoberfläche zu bestimmen und zu bestimmen, wie die Striche räumlich und sogar semantisch miteinander in Beziehung stehen. Die Layoutanalyse kann Beispielsweise feststellen, dass ein bestimmtes Freihandstück eine Anmerkung oder ein Aufruf ist.
Erkennung
Ein Beispiel dafür, wie die Kombination von Erkennung mit Freihandanalyse in der InkAnalysis-API dem Entwickler hilft, ist die Verbesserung der Erkennungsergebnisse. Die Tablet PC-Handschrifterkennungs-Engines wurden in erster Linie für die Erkennung einer einzelnen horizontalen Freihandlinie entwickelt. Personen neigen jedoch dazu, beim Notieren mehrere Zeilen zu schreiben, und es ist nicht garantiert, dass diese Zeilen in Bezug auf die Seite horizontal sind. Mit der InkAnalysis-API wird Freihand vom Freihandanalysator vorverarbeitet, bevor sie an die Erkennung gesendet wird. Die analysierte Freihand wird vor der Erkennung in horizontal transformiert, was die Erkennungsergebnisse verbessert.
Andere Vorteile für die Erkennung ergeben sich, wenn das Freihandanalysetool falsche Strichreihenfolgeinformationen korrigiert, bevor die Freihandeingabe an die Erkennung gesendet wird. Darüber hinaus sind Erkennungsergebnisse jetzt selektiv verfügbar. Das heißt, der Entwickler kann die Erkennungsergebnisse für ein einzelnes Wort, eine Zeile oder einen Absatz in einem Einzigen Aufruf schnell abrufen.
Freihandklassifizierung
Es gibt natürlich eine Vielzahl von Szenarien, in denen Sie die Freihanddaten intakt halten können, anstatt sie sofort in Text zu konvertieren. Die Freihandanalyse bietet auch hier Vorteile. Insbesondere bieten die InkAnalysis-APIs die Möglichkeit, Freihandstriche je nachdem zu teilen, ob es sich um Schreib- oder Zeichnungen handelt. Freihandstriche, die als Schrift klassifiziert werden, sind diejenigen, die ein Wort oder Zeichen bilden. Alle anderen Striche sind Zeichnungen. Dadurch erhalten Sie eine neue Möglichkeit, auf Freihanddaten zuzugreifen und neue Benutzerszenarien zu ermöglichen. Für instance können Sie die Auswahl so implementieren, dass sie sich je nach Art der Striche unterscheidet, auf die der Benutzer tippt. Wenn ein Benutzer auf einen Schreibstrich tippt, wählt die Anwendung den gesamten Satz von Strichen aus, aus denen das Wort besteht. Wenn der Benutzer auf eine Zeichnung tippt, wählt die Anwendung nur diesen Strich aus.
Layoutanalyse
Eine nützliche Layoutanalyse geht weit über die relativ einfache Aufschlüsselung von Freihand in Schreib- und Zeichnungskomponenten hinaus.
Die Freihandanalyse umfasst auch eine umfassendere Aufschlüsselung der Schreib- und Zeichnungsstriche. Nehmen Sie ein sehr einfaches Beispiel für ein Blob mit Freihand, wie in der folgenden Abbildung gezeigt.

Nachdem die Plattform diese Striche analysiert hat, gibt sie eine Strukturdarstellung dieser Striche zurück, wie in der folgenden Abbildung gezeigt. In diesem einfachen Fall enthält die Struktur nur Absatz-, Zeilen- und Wortinformationen, aber der Reichtum dieser Struktur steigt, wenn die Komplexität des Freihanddokuments zunimmt.
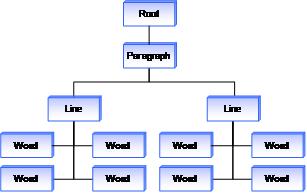
Da diese Informationen jetzt in verwaltbare Einheiten unterteilt sind, können Sie jetzt leistungsfähigere Features erstellen. Als Beispiel kann die Anwendung das Feature erweitern, in dem der Benutzer auf ein Wort tippt, um ein Feature auszuwählen, in dem der Benutzer einmal tippt, um das Wort auszuwählen, zweimal, um die gesamte Zeile auszuwählen, und dreimal tippen, um den gesamten Absatz auszuwählen. Durch Nutzung der vom Analysevorgang zurückgegebenen Struktur kann die Anwendung den getippten Bereich wieder mit einem Strich in der Struktur verknüpfen. Nachdem die Anwendung eine Strich gefunden hat, kann sie in der Struktur nach oben gehen, um zu bestimmen, wie und welche benachbarten Striche ausgewählt werden sollen.
Die Auswahl einer ganzen Linie ist ein einfaches Beispiel für die Vorteile der Freihandanalyse, aber die Möglichkeiten werden groß, wenn man die verschiedenen Arten von hierarchischen Strukturen betrachtet, die der Freihandanalyser erkennen kann:
- Sortierte und nicht sortierte Listen
- Formen
- Kommentare, die inline mit dem Text geschrieben wurden
Die Arten von Features variieren von Anwendung zu Anwendung und basieren auf den Anforderungen und den verfügbaren Freihandanalyse- und Erkennungs-Engines.
Wichtige Freihandanalysefeatures
Die wichtigsten Funktionen der InkAnalysis-API umfassen die folgenden Features:
- Inkrementelle Analyse
- Persistenz
- Datenproxy
- Versöhnung
- Erweiterungen
Inkrementelle Analyse
Wenn Endbenutzer mit Freihand arbeiten, behandeln sie diese in der Regel wie Handschrift. Die Freihandeingabe unterliegt kontinuierlich Bearbeitungsvorgängen, z. B. dem Hinzufügen neuer Freihandeingaben, dem Löschen vorhandener Freihandeingaben und der Änderung von Freihandeigenschaften, die alle auf die gleiche Weise erfolgen, wie die Handschrift kontinuierlich bearbeitet wird. Diese Bearbeitungsvorgänge wirken sich auf die Analyseergebnisse aus. Wenn Bearbeitungen erfolgen, können sie in der Regel zu bestimmten Zeitpunkten in Abschnitte des Dokuments isoliert werden. Angenommen, ein Benutzer schreibt fünf Freihandzeilen. Die Standardmethode, mit der Anwendungen Freihand analysieren, besteht darin, zu warten, bis der Benutzer alle fünf Freihandzeilen – einen Absatz für instance – fertig geschrieben hat, und dann die Ergebnisse synchron oder asynchron zu analysieren.
Sie können die Gesamtzeit für die Analyse dieser fünf Zeilen optimieren, indem Sie die Bereiche isolieren, die beim Schreiben analysiert werden, und dann nur die Teile der Ergebnisse erneut analysieren, die sich geändert haben. Nachdem die erste Zeile analysiert wurde, wird sie nie wieder erkannt, es sei denn, sie wird vom Endbenutzer geändert. Die Erkennung der zweiten Zeile wird als eigenständiger Erkennungsvorgang behandelt.
Dieser inkrementelle Ansatz funktioniert gut auf Zeilenebene für die Erkennungsvorgänge, muss aber auf einer höheren Ebene für den Freihandanalysevorgang funktionieren. Da der Freihandanalysator unterschiedliche Klassifizierungen auf höherer Ebene für diese fünf Freihandzeilen erkennen kann (z. B. kann es sich um einen Standardabsatz oder fünf Elemente in einer Liste handeln), besteht der inkrementelle Ansatz für das Freihandanalysetool darin, dass diese höheren Strukturen analysiert werden müssen. Das heißt, nachdem der Freihandanalysator die erste Freihandzeile als Zeile klassifiziert hat, wird doppelt überprüft, ob es sich bei der Klassifizierung der zweiten Zeile noch um eine Zeile handelt. Das Freihandanalysator isoliert diese doppelte Überprüfung jedoch mit dem Absatz und ignoriert den ersten Absatz beim Analysieren eines zweiten Absatzes und behandelt den zweiten Absatz als unabhängigen Freihandanalysevorgang. Dieser inkrementelle Analyseansatz spart erheblich Verarbeitungszeit, wenn bereits große Freihandmengen in der Anwendung vorhanden sind.
Persistenz
Die inkrementelle Analyse funktioniert gut innerhalb einer bestimmten Sitzung oder instance eines InkAnalyzer-Objekts. Die erste Generation der Tablet-PC-Plattform-APIs kann jedoch keine inkrementelle Analyse durchführen, nachdem die Freihand auf dem Datenträger beibehalten wurde. Die InkAnalysis-API ermöglicht das Speichern von Freihand auf einem Datenträger zusammen mit einer dauerhaften Form der Analyseergebnisse. Die Analyseergebnisse können beim Laden der Freihand geladen und in eine neue instance eines InkAnalyzers eingefügt werden. Eine neue instance des InkAnalyzer-Objekts weist dann den gleichen Ergebniszustand auf, den sie zuvor hatte, und kann jetzt alle Änderungen als inkrementelle Änderungen am vorhandenen Zustand akzeptieren, anstatt alles noch einmal zu analysieren.
Datenproxy
Viele Anwendungen verfügen bereits über eine Dokumentstruktur in ihren Anwendungen. für instance, ein Diagramm oder eine Datenbank. Der InkAnalyzer stellt die Ergebnisse auch in strukturierter Form in einer Struktur von ContextNode-Objekten dar. Die InkAnalyzer-Struktur und die vorhandene Struktur der Anwendung müssen in zwei Richtungen zusammenarbeiten: Ergebnisse werden vom InkAnalyzer in die Anwendung abgerufen, und der Zustand wird von der Anwendung in den InkAnalyzer gepusht.
Wenn das Abrufen der Ergebnisse aus dem InkAnalyzer in die Struktur der Anwendung nur erforderlich wäre, wäre dies relativ einfach. Anwendungen würden die Ergebnisstruktur durchlaufen und alle benötigten Ergebnisse in ihre vorhandene Datenstruktur kopieren (integrieren). Da jedoch viele horizontale Anwendungen eine inkrementelle Analyse und Persistenz auf dem Datenträger erfordern, wird das Problem zweidirektional. Zustand (frühere Ergebnisse) muss aus der Struktur der Anwendung abgerufen und in den InkAnalyzer gepusht werden.
Um diese Anforderung zu erfüllen, enthält der InkAnalyzer eine Reihe von Ereignissen, die während eines Analysevorgangs zur geeigneten Zeit ausgelöst werden, damit Anwendungen die Anforderung für Daten zurück an ihre vorhandenen Strukturen senden können. Diese Ereignisse werden nur für die ContextNode-Objekte ausgelöst, die für den inkrementellen Vorgang erforderlich sind.
Versöhnung
Die meisten Anwendungen möchten die Freihandeingabe im Hintergrund analysieren, um Unterbrechungen der Benutzeroberfläche auf ein Minimum zu beschränken. Die Analyse von Freihand im Hintergrund führt jedoch zu Problemen, wenn der Benutzer die zu analysierende Freihand (oder die benachbarte Freihandfarbe) ändert. Wenn der Benutzer beispielsweise die Freihand während des Hintergrundvorgangs löscht, spiegelt die resultierende Struktur den Zustand des Dokuments wider, als der Hintergrundvorgang gestartet wurde, und nicht, wenn er abgeschlossen wurde.
Um Anwendungen zu unterstützen, stimmt der InkAnalyzer die Unterschiede im Dokumentzustand zwischen Beginn und Ende des Analysevorgangs ab. Änderungen, die vom Benutzer oder der Anwendung vorgenommen werden, während die Analyse im Hintergrund ausgeführt wird, überschreiben immer die im Hintergrund berechneten Ergebnisse. Nach der Abstimmung werden nur die Teile der Ergebnisstruktur gemeldet, die nicht mit Dokumentänderungen in Konflikt stehen, und die in Konflikt stehenden Striche werden für zukünftige Analysen markiert. Wenn der Hintergrundanalysevorgang das nächste Mal ausgeführt wird, werden die Ergebnisse basierend auf dem neuen Zustand neu berechnet.
Im folgenden Diagramm wird der Prozess veranschaulicht. Die Zeit wird linear von oben nach unten im Diagramm ausgedrückt.
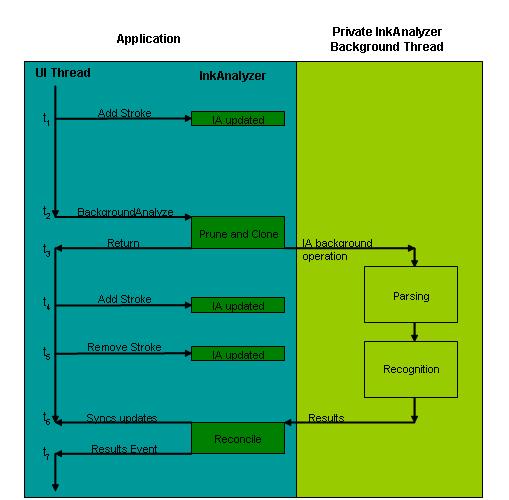
- Zum Zeitpunkt 1 (t1) sammelt die Anwendung Freihandeingaben vom Endbenutzer, einschließlich aller Arten von Freihandänderungen, z. B. Hinzufügen, Entfernen oder Ändern.
- Bei t2 ruft die Anwendung den Hintergrundanalysevorgang auf. Der InkAnalyzer bestimmt, welche Freihandeingabe keine Ergebnisse hat und welche Freihand doppelt überprüft werden muss. Es kopiert die erforderlichen Freihanddaten, damit der Hintergrundthread unabhängig ausgeführt werden kann.
- Bei t3 gibt inkAnalyzer die Ausführung des Benutzeroberflächenthreads an die Anwendung zurück. Der InkAnalyzer erstellt einen zweiten Thread, den Hintergrundanalysethread, und die Freihandanalyse- und Erkennungs-Engines analysieren die kopierten Freihanddaten.
- Während der Analysevorgang im zweiten Hintergrundthread ausgeführt wird, bearbeitet der Endbenutzer das Dokument und fügt Strichdaten bei t4 und t5 hinzu und entfernt diese. Diese Bearbeitungen können in Konflikt mit der Arbeit stehen, die im Hintergrund verarbeitet wird.
- Bei t6 hat der Hintergrundthread den Analysevorgang abgeschlossen, und die Ergebnisse sind bereit. Bevor inkAnalyzer die Ergebnisse an die Anwendung übermittelt werden, führt es einen Abstimmungsalgorithmus aus, um festzustellen, ob der Benutzer Änderungen vorgenommen hat, während der Analysevorgang berechnet wurde (t4 und t5) mit den Ergebnissen in Konflikt stehen. Wenn Kollisionen erkannt werden, werden die kollidierenden Striche zur erneuten Analyse gekennzeichnet. Dies geschieht, wenn die Anwendung das nächste Mal den Hintergrundanalysevorgang aufruft.
- Schließlich präsentiert der InkAnalyzer bei t7, da alle Kollisionen erkannt wurden, die Ergebnisse an die Anwendung.
Erweiterungen
Mit den InkAnalysis-APIs können neue Arten von Analyse-Engines von Anwendungen verwendet werden, um zu verhindern, dass die Anwendung alle Vorteile der InkAnalysis-API, einschließlich Abstimmung, Datenproxy, Persistenz und inkrementeller Analyse, umschreiben muss.
Zugehörige Themen