Document Intelligence batch analysis (preview)
Important
- Document Intelligence public preview releases provide early access to features that are in active development. Features, approaches, and processes may change, prior to General Availability (GA), based on user feedback.
- The public preview version of Document Intelligence client libraries default to REST API version 2024-07-31-preview.
- Public preview version 2024-07-31-preview is currently only available in the following Azure regions. Note that the custom generative (document field extraction) model in AI Studio is only available in North Central US region:
- East US
- West US2
- West Europe
- North Central US
The batch analysis API allows you to bulk process multiple documents using one asynchronous request. Rather than having to submit documents individually and track multiple request IDs, you can analyze a collection of invoices, a series of loan documents, or a group of custom model training documents simultaneously.
- To utilize batch analysis, you need an Azure Blob storage account with specific containers for both your source documents and the processed outputs.
- Upon completion, the batch operation result lists all of the individual documents processed with their status, such as
succeeded,skipped, orfailed. - The Batch API preview version is available via pay-as-you-go pricing.
The following models support batch analysis:
Read. Extract text lines, words, detected languages, and handwritten style from forms and document.
Layout. Extract text, tables, selection marks, and structure information from forms and documents.
Custom Template. Train models to extract key-value pairs, selection marks, tables, signature fields, and regions from structured forms.
Custom Neural. Train models to extract specified data fields from structured, semi-structured, and unstructured documents.
Custom Generative. Train models to extract specified data from complex objects such as nested tables, abstractive/generative fields, and truly unstructured formats.
Batch analysis guidance
The maximum number of documents processed per single batch analyze request (including skipped documents) is 10,000.
The
azureBlobFileListSourceparameter can be used to break larger requests into smaller ones.Operation results are retained for 24 hours after completion. The documents and results are in the storage account provided, but operation status is no longer available 24 hours after completion.
Ready to get started?
Prerequisites
You need an active Azure subscription. If you don't have an Azure subscription, you can create one for free.
Once you have your Azure subscription A Document Intelligence instance in the Azure portal. You can use the free pricing tier (
F0) to try the service.After your resource deploys, select Go to resource and retrieve your key and endpoint.
- You need the key and endpoint from the resource to connect your application to the Document Intelligence service. You paste your key and endpoint into the code later in the quickstart. You can find these values on the Azure portal Keys and Endpoint page.
An Azure Blob Storage account. You'll create containers in your Azure Blob Storage account for your source and result files:
- Source container. This container is where you upload your files for analysis (required).
- Result container. This container is where your processed files are stored (optional).
You can designate the same Azure Blob Storage container for source and processed documents. However, to minimize potential chances of accidentally overwriting data, we recommend choosing separate containers.
Storage container authorization
You can choose one of the following options to authorize access to your Document resource.
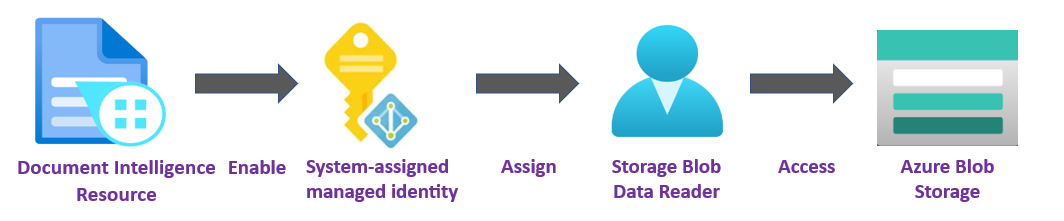
✔️ Managed Identity. A managed identity is a service principal that creates a Microsoft Entra identity and specific permissions for an Azure managed resource. Managed identities enable you to run your Document Intelligence application without having to embed credentials in your code. Managed identities are a safer way to grant access to storage data and replace the requirement for you to include shared access signature tokens (SAS) with your source and result URLs.
To learn more, see Managed identities for Document Intelligence.
Important
- When using managed identities, don't include a SAS token URL with your HTTP requests—your requests will fail. Using managed identities replaces the requirement for you to include shared access signature tokens (SAS).
✔️ Shared Access Signature (SAS). A shared access signature is a URL that grants restricted access for a specified period of time to your Document Intelligence service. To use this method, you need to create Shared Access Signature (SAS) tokens for your source and result containers. The source and result containers must include a Shared Access Signature (SAS) token, appended as a query string. The token can be assigned to your container or specific blobs.

- Your source container or blob must designate read, write, list, and delete access.
- Your result container or blob must designate write, list, delete access.
To learn more, see Create SAS tokens.
Calling the batch analysis API
Specify the Azure Blob Storage container URL for your source document set within the
azureBlobSourceorazureBlobFileListSourceobjects.Specify the Azure Blob Storage container URL for your batch analysis results using
resultContainerUrl. To avoid accidental overwriting, we recommend using separate containers for source and processed documents.- If you use the same container, set
resultContainerUrlandresultPrefixto match your inputazureBlobSource. - When using the same container, you can include the
overwriteExistingfield to decide whether to overwrite any files with the analysis result files.
- If you use the same container, set
Build and run the POST request
Before you run the POST request, replace {your-source-container-SAS-URL} and {your-result-container-SAS-URL} with the values from your Azure Blob storage container instances.
Allow only one either azureBlobSource or azureBlobFileListSource.
POST /documentModels/{modelId}:analyzeBatch
[
{
"azureBlobSource": {
"containerUrl": "{your-source-container-SAS-URL}",
"prefix": "trainingDocs/"
},
"azureBlobFileListSource": {
"containerUrl": "{your-source-container-SAS-URL}",
"fileList": "myFileList.jsonl"
},
"resultContainerUrl": "{your-result-container-SAS-URL}",
"resultPrefix": "trainingDocsResult/",
"overwriteExisting": false
}
]
Successful response
202 Accepted
Operation-Location: /documentModels/{modelId}/analyzeBatchResults/{resultId}
Retrieve batch analysis API results
After the Batch API operation is executed, you can retrieve the batch analysis results using theGET operation. This operation fetches operation status information, operation completion percentage, and operation creation and update date/time.
GET /documentModels/{modelId}/analyzeBatchResults/{resultId}
200 OK
{
"status": "running", // notStarted, running, completed, failed
"percentCompleted": 67, // Estimated based on the number of processed documents
"createdDateTime": "2021-09-24T13:00:46Z",
"lastUpdatedDateTime": "2021-09-24T13:00:49Z"
...
}
Interpreting status messages
For each document a set, there a status is assigned, either succeeded, failed, or skipped. For each document, there are two URLs provided to validate the results: sourceUrl, which is the source blob storage container for your succeeded input document, and resultUrl, which is constructed by combining resultContainerUrl andresultPrefix to create the relative path for the source file and .ocr.json.
Status
notStartedorrunning. The batch analysis operation isn't initiated or isn't completed. Wait until the operation is completed for all documents.Status
completed. The batch analysis operation is finished.Status
failed. The batch operation failed. This response usually occurs if there are overall issues with the request. Failures on individual files are returned in the batch report response, even if all the files failed. For example, storage errors don't halt the batch operation as a whole, so that you can access partial results via the batch report response.
Only files that have a succeeded status have the property resultUrl generated in the response. This enables model training to detect file names that end with .ocr.json and identify them as the only files that can be used for training.
Example of a succeeded status response:
[
"result": {
"succeededCount": 0,
"failedCount": 2,
"skippedCount": 2,
"details": [
{
"sourceUrl": "https://{your-source-container}/myContainer/trainingDocs/file2.jpg",
"status": "failed",
"error": {
"code": "InvalidArgument",
"message": "Invalid argument.",
"innererror": {
"code": "InvalidSasToken",
"message": "The shared access signature (SAS) is invalid: {details}"
}
}
}
]
}
]
...
Example of a failed status response:
- This error is only returned if there are errors in the overall batch request.
- Once the batch analysis operation is started, individual document operation status doesn't affect the status of the overall batch job, even if all the files have the status
failed.
[
"result": {
"succeededCount": 0,
"failedCount": 2,
"skippedCount": 2,
"details": [
"sourceUrl": "https://{your-source-container}/myContainer/trainingDocs/file2.jpg",
"status": "failed",
"error": {
"code": "InvalidArgument",
"message": "Invalid argument.",
"innererror": {
"code": "InvalidSasToken",
"message": "The shared access signature (SAS) is invalid: {details}"
}
}
]
}
]
...
Example of skipped status response:
[
"result": {
"succeededCount": 3,
"failedCount": 0,
"skippedCount": 2,
"details": [
...
"sourceUrl": "https://myStorageAccount.blob.core.windows.net/myContainer/trainingDocs/file4.jpg",
"status": "skipped",
"error": {
"code": "OutputExists",
"message": "Analysis skipped because result file {path} already exists."
}
]
}
]
...
The batch analysis results help you identify which files are successfully analyzed and validate the analysis results by comparing the file in the resultUrl with the output file in the resultContainerUrl.
Note
Analysis results aren't returned for individual files until the entire document set batch analysis is completed. To track detailed progress beyond percentCompleted, you can monitor *.ocr.json files as they are written into the resultContainerUrl.