Quickstart: Custom text classification
Use this article to get started with creating a custom text classification project where you can train custom models for text classification. A model is artificial intelligence software that's trained to do a certain task. For this system, the models classify text, and are trained by learning from tagged data.
Custom text classification supports two types of projects:
- Single label classification - you can assign a single class for each document in your dataset. For example, a movie script could only be classified as "Romance" or "Comedy".
- Multi label classification - you can assign multiple classes for each document in your dataset. For example, a movie script could be classified as "Comedy" or "Romance" and "Comedy".
In this quickstart you can use the sample datasets provided to build a multi label classification where you can classify movie scripts into one or more categories or you can use single label classification dataset where you can classify abstracts of scientific papers into one of the defined domains.
Prerequisites
- Azure subscription - Create one for free.
Create a new Azure AI Language resource and Azure storage account
Before you can use custom text classification, you'll need to create an Azure AI Language resource, which will give you the credentials that you need to create a project and start training a model. You'll also need an Azure storage account, where you can upload your dataset that will be used to build your model.
Important
To quickly get started, we recommend creating a new Azure AI Language resource using the steps provided in this article. Using the steps in this article will let you create the Language resource and storage account at the same time, which is easier than doing it later.
If you have a pre-existing resource that you'd like to use, you will need to connect it to storage account.
Create a new resource from the Azure portal
Go to the Azure portal to create a new Azure AI Language resource.
In the window that appears, select Custom text classification & custom named entity recognition from the custom features. Select Continue to create your resource at the bottom of the screen.
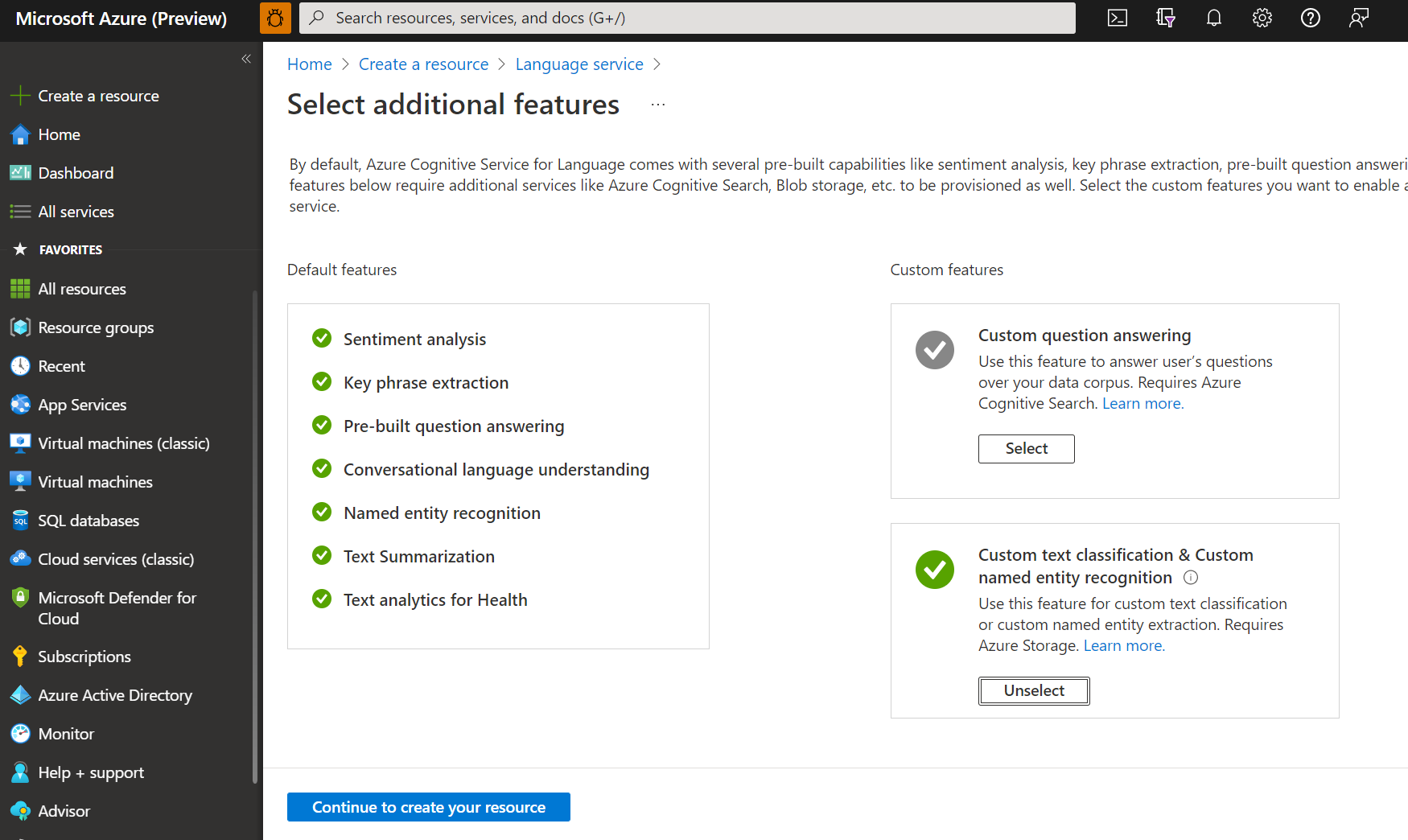
Create a Language resource with following details.
Name Required value Subscription Your Azure subscription. Resource group A resource group that will contain your resource. You can use an existing one, or create a new one. Region One of the supported regions. For example "West US 2". Name A name for your resource. Pricing tier One of the supported pricing tiers. You can use the Free (F0) tier to try the service. If you get a message saying "your login account is not an owner of the selected storage account's resource group", your account needs to have an owner role assigned on the resource group before you can create a Language resource. Contact your Azure subscription owner for assistance.
You can determine your Azure subscription owner by searching your resource group and following the link to its associated subscription. Then:
- Select the Access Control (IAM) tab
- Select Role assignments
- Filter by Role:Owner.
In the Custom text classification & custom named entity recognition section, select an existing storage account or select New storage account. Note that these values are to help you get started, and not necessarily the storage account values you’ll want to use in production environments. To avoid latency during building your project connect to storage accounts in the same region as your Language resource.
Storage account value Recommended value Storage account name Any name Storage account type Standard LRS Make sure the Responsible AI Notice is checked. Select Review + create at the bottom of the page.

Upload sample data to blob container
After you have created an Azure storage account and connected it to your Language resource, you will need to upload the documents from the sample dataset to the root directory of your container. These documents will later be used to train your model.
Download the sample dataset for multi label classification projects.
Open the .zip file, and extract the folder containing the documents.
The provided sample dataset contains about 200 documents, each of which is a summary for a movie. Each document belongs to one or more of the following classes:
- "Mystery"
- "Drama"
- "Thriller"
- "Comedy"
- "Action"
In the Azure portal, navigate to the storage account you created, and select it. You can do this by clicking Storage accounts and typing your storage account name into Filter for any field.
if your resource group does not show up, make sure the Subscription equals filter is set to All.
In your storage account, select Containers from the left menu, located below Data storage. On the screen that appears, select + Container. Give the container the name example-data and leave the default Public access level.
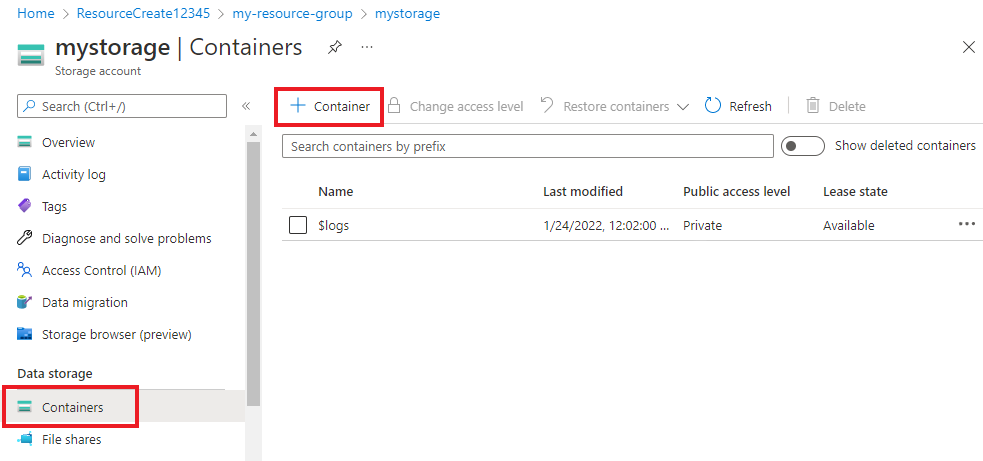
After your container has been created, select it. Then select Upload button to select the
.txtand.jsonfiles you downloaded earlier.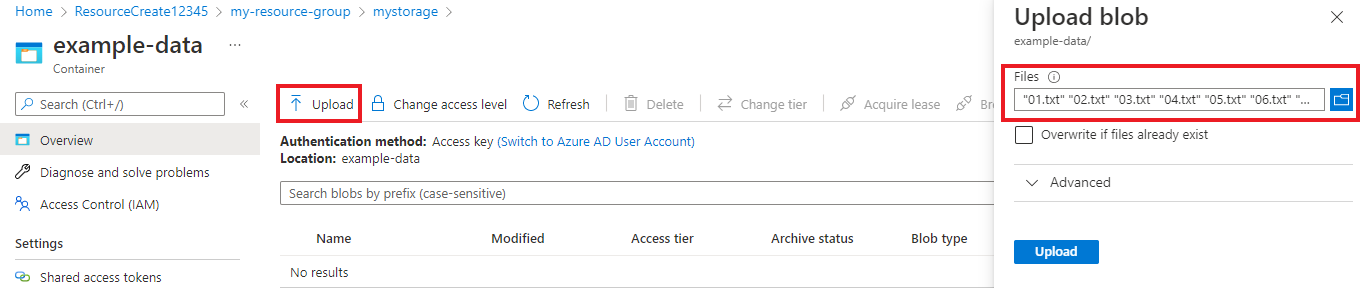


Create a custom text classification project
Once your resource and storage container are configured, create a new custom text classification project. A project is a work area for building your custom ML models based on your data. Your project can only be accessed by you and others who have access to the Language resource being used.
Sign into the Language Studio. A window will appear to let you select your subscription and Language resource. Select your Language resource.
Under the Classify text section of Language Studio, select Custom text classification.
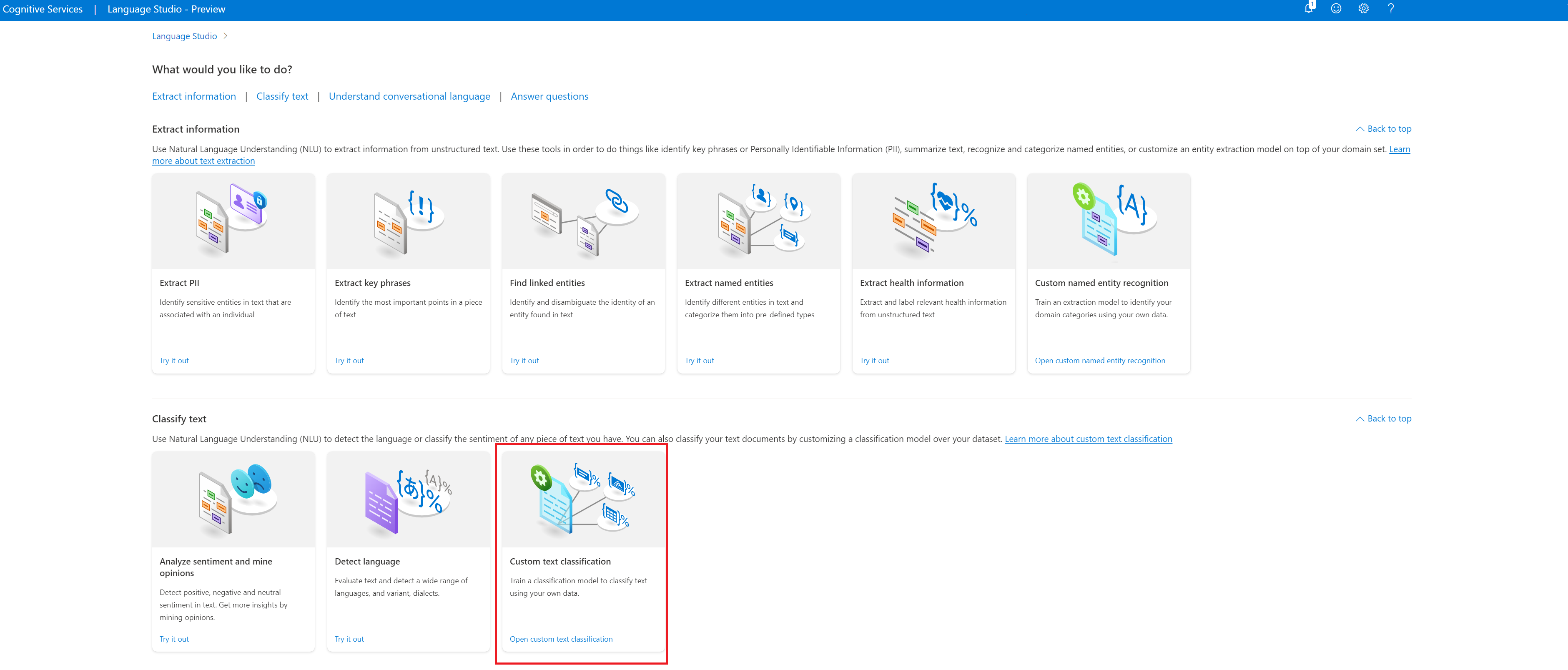
Select Create new project from the top menu in your projects page. Creating a project will let you label data, train, evaluate, improve, and deploy your models.
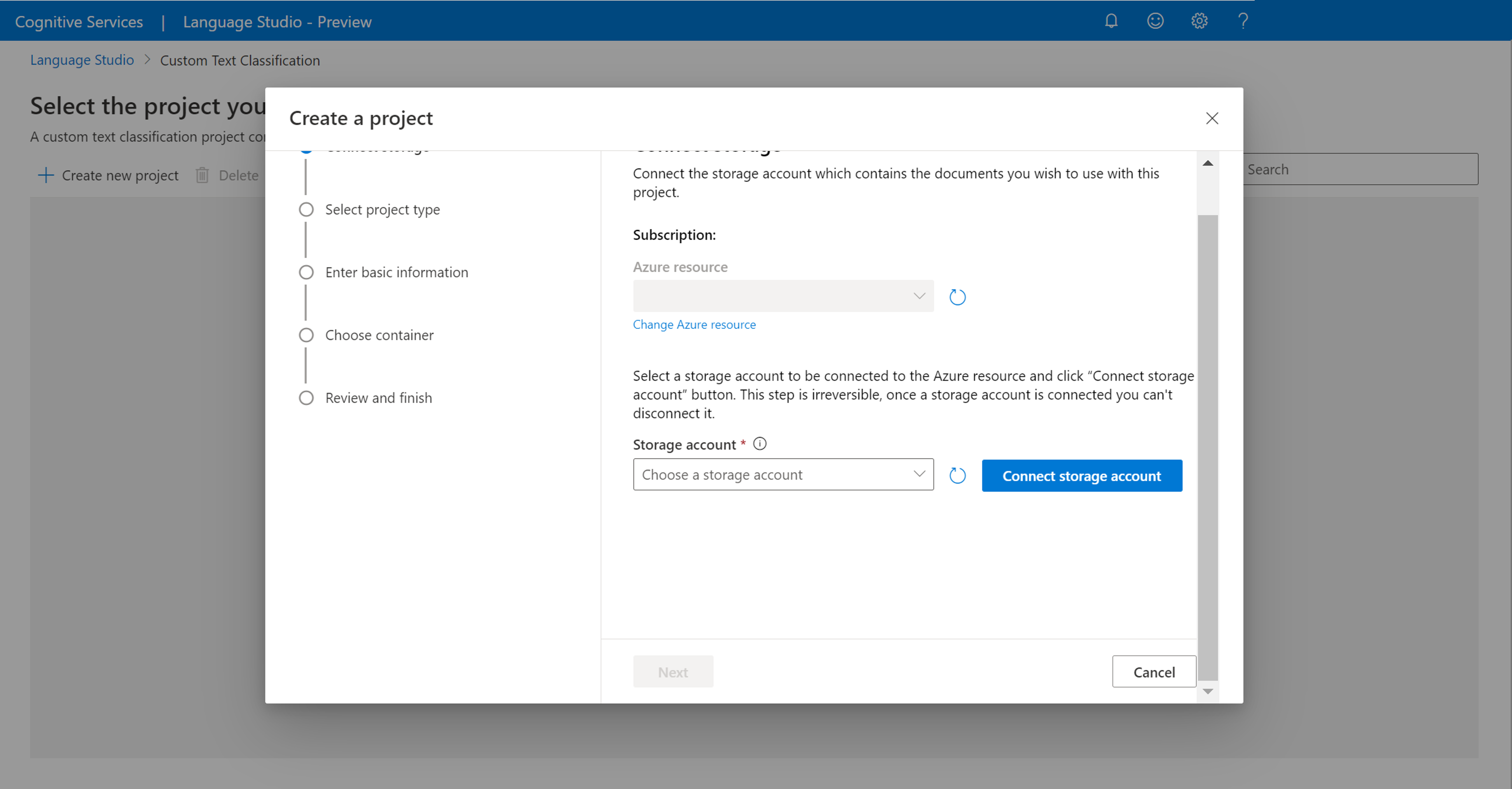
After you click, Create new project, a window will appear to let you connect your storage account. If you've already connected a storage account, you will see the storage accounted connected. If not, choose your storage account from the dropdown that appears and select Connect storage account; this will set the required roles for your storage account. This step will possibly return an error if you are not assigned as owner on the storage account.
Note
- You only need to do this step once for each new language resource you use.
- This process is irreversible, if you connect a storage account to your Language resource you cannot disconnect it later.
- You can only connect your Language resource to one storage account.
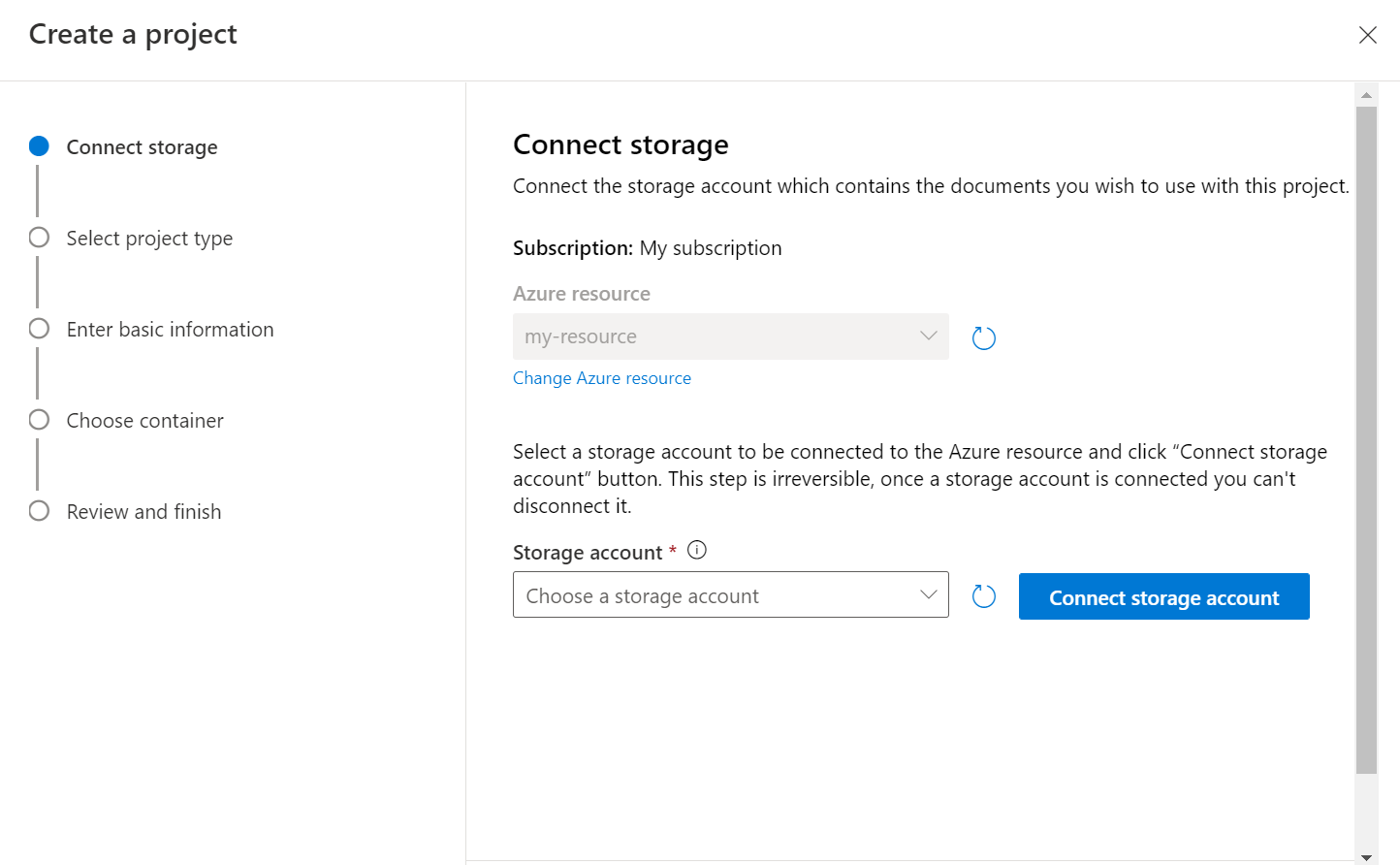
Select project type. You can either create a Multi label classification project where each document can belong to one or more classes or Single label classification project where each document can belong to only one class. The selected type can't be changed later. Learn more about project types
Enter the project information, including a name, description, and the language of the documents in your project. If you're using the example dataset, select English. You won’t be able to change the name of your project later. Select Next.
Tip
Your dataset doesn't have to be entirely in the same language. You can have multiple documents, each with different supported languages. If your dataset contains documents of different languages or if you expect text from different languages during runtime, select enable multi-lingual dataset option when you enter the basic information for your project. This option can be enabled later from the Project settings page.
Select the container where you have uploaded your dataset.
Note
If you have already labeled your data make sure it follows the supported format and select Yes, my documents are already labeled and I have formatted JSON labels file and select the labels file from the drop-down menu below.
If you’re using one of the example datasets, use the included
webOfScience_labelsFileormovieLabelsjson file. Then select Next.Review the data you entered and select Create Project.




Train your model
Typically after you create a project, you go ahead and start labeling the documents you have in the container connected to your project. For this quickstart, you have imported a sample labeled dataset and initialized your project with the sample JSON labels file.
To start training your model from within the Language Studio:
Select Training jobs from the left side menu.
Select Start a training job from the top menu.
Select Train a new model and type in the model name in the text box. You can also overwrite an existing model by selecting this option and choosing the model you want to overwrite from the dropdown menu. Overwriting a trained model is irreversible, but it won't affect your deployed models until you deploy the new model.
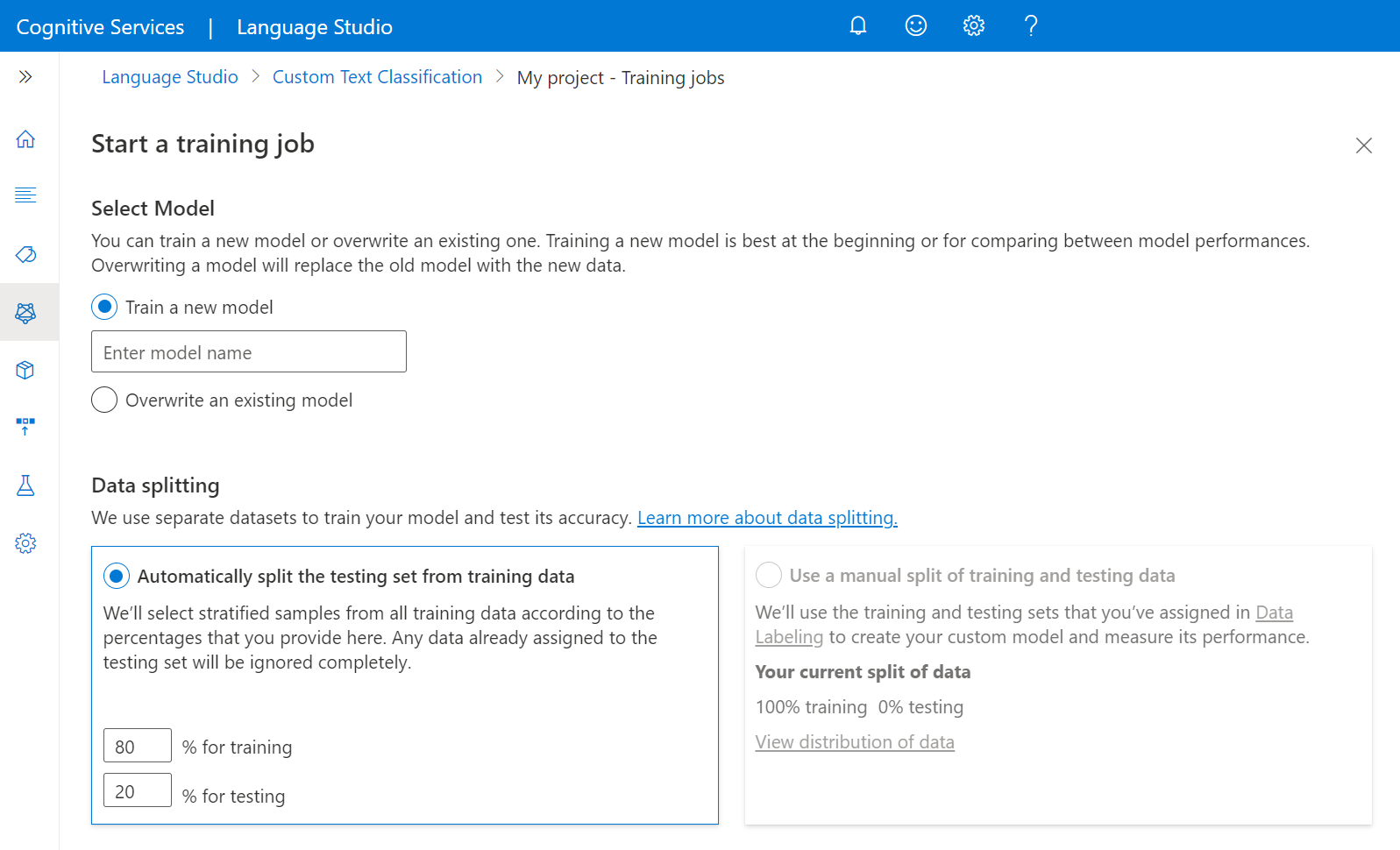
Select data splitting method. You can choose Automatically splitting the testing set from training data where the system will split your labeled data between the training and testing sets, according to the specified percentages. Or you can Use a manual split of training and testing data, this option is only enabled if you have added documents to your testing set during data labeling. See How to train a model for more information on data splitting.
Select the Train button.
If you select the training job ID from the list, a side pane will appear where you can check the Training progress, Job status, and other details for this job.
Note
- Only successfully completed training jobs will generate models.
- The time to train the model can take anywhere between a few minutes to several hours based on the size of your labeled data.
- You can only have one training job running at a time. You can't start other training job within the same project until the running job is completed.

Deploy your model
Generally after training a model you would review its evaluation details and make improvements if necessary. In this quickstart, you will just deploy your model, and make it available for you to try in Language Studio, or you can call the prediction API.
To deploy your model from within the Language Studio:
Select Deploying a model from the left side menu.
Select Add deployment to start a new deployment job.
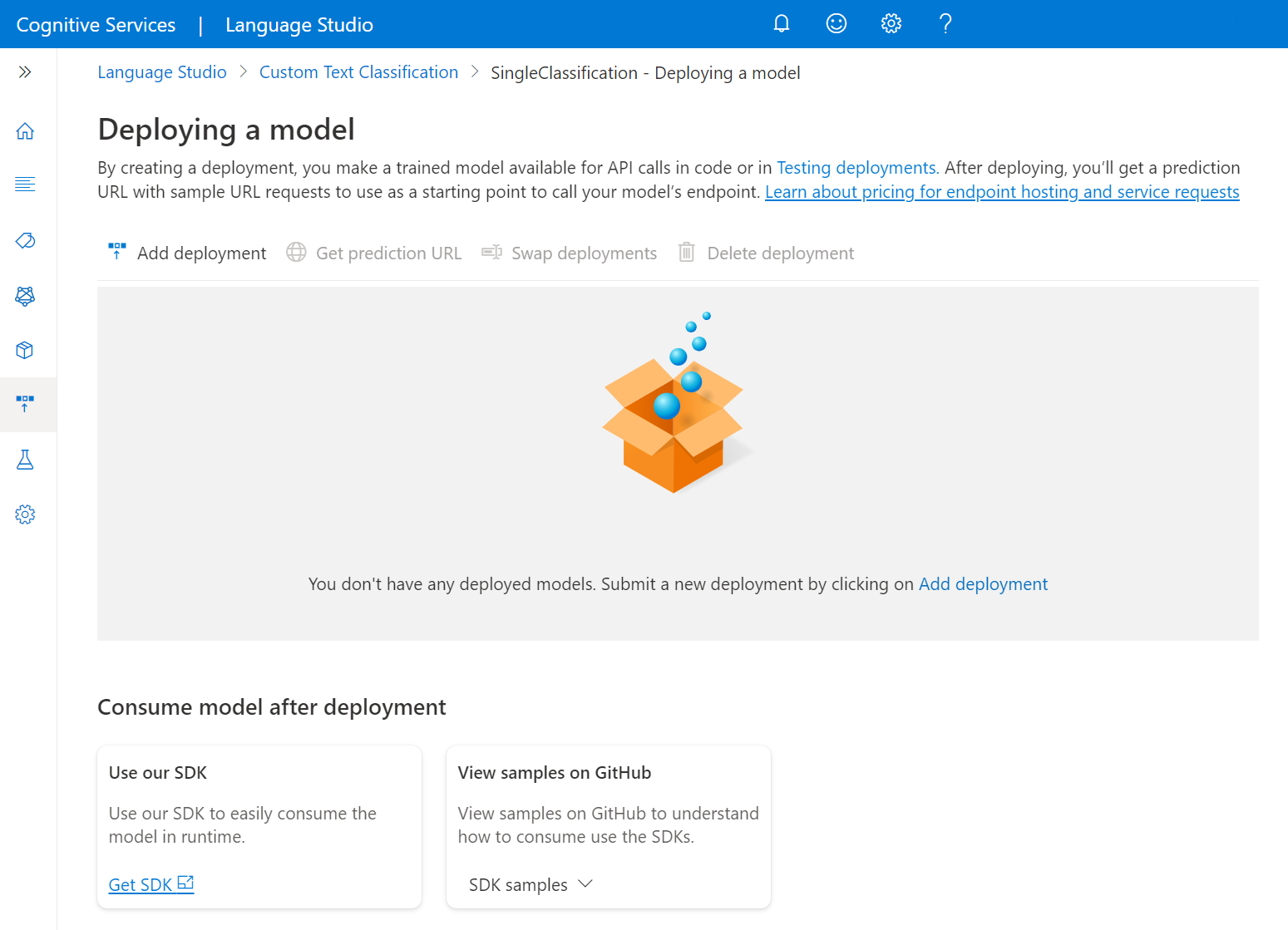
Select Create new deployment to create a new deployment and assign a trained model from the dropdown below. You can also Overwrite an existing deployment by selecting this option and select the trained model you want to assign to it from the dropdown below.
Note
Overwriting an existing deployment doesn't require changes to your Prediction API call but the results you get will be based on the newly assigned model.
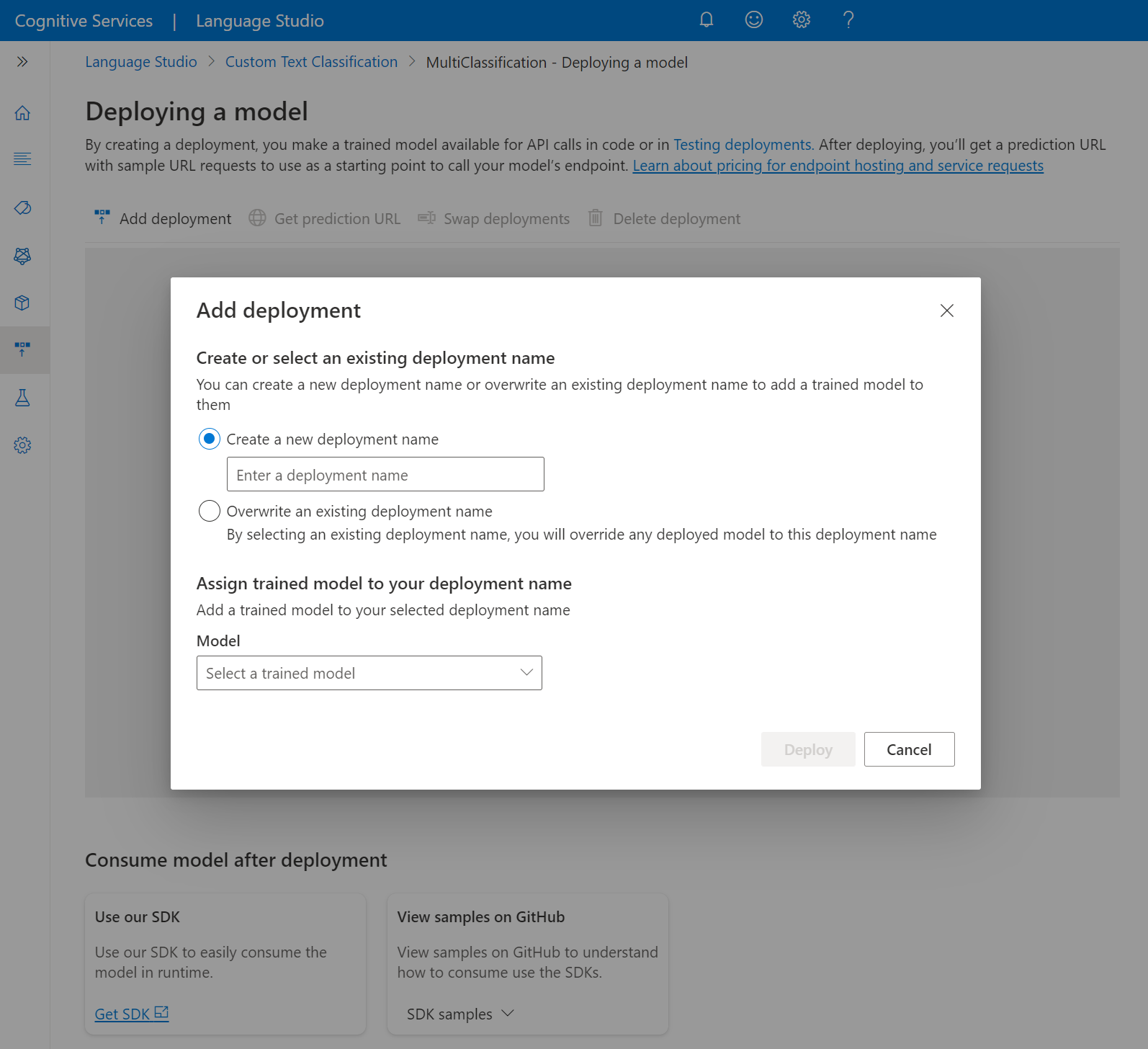
select Deploy to start the deployment job.
After deployment is successful, an expiration date will appear next to it. Deployment expiration is when your deployed model will be unavailable to be used for prediction, which typically happens twelve months after a training configuration expires.


Test your model
After your model is deployed, you can start using it to classify your text via Prediction API. For this quickstart, you will use the Language Studio to submit the custom text classification task and visualize the results. In the sample dataset you downloaded earlier you can find some test documents that you can use in this step.
To test your deployed models within Language Studio:
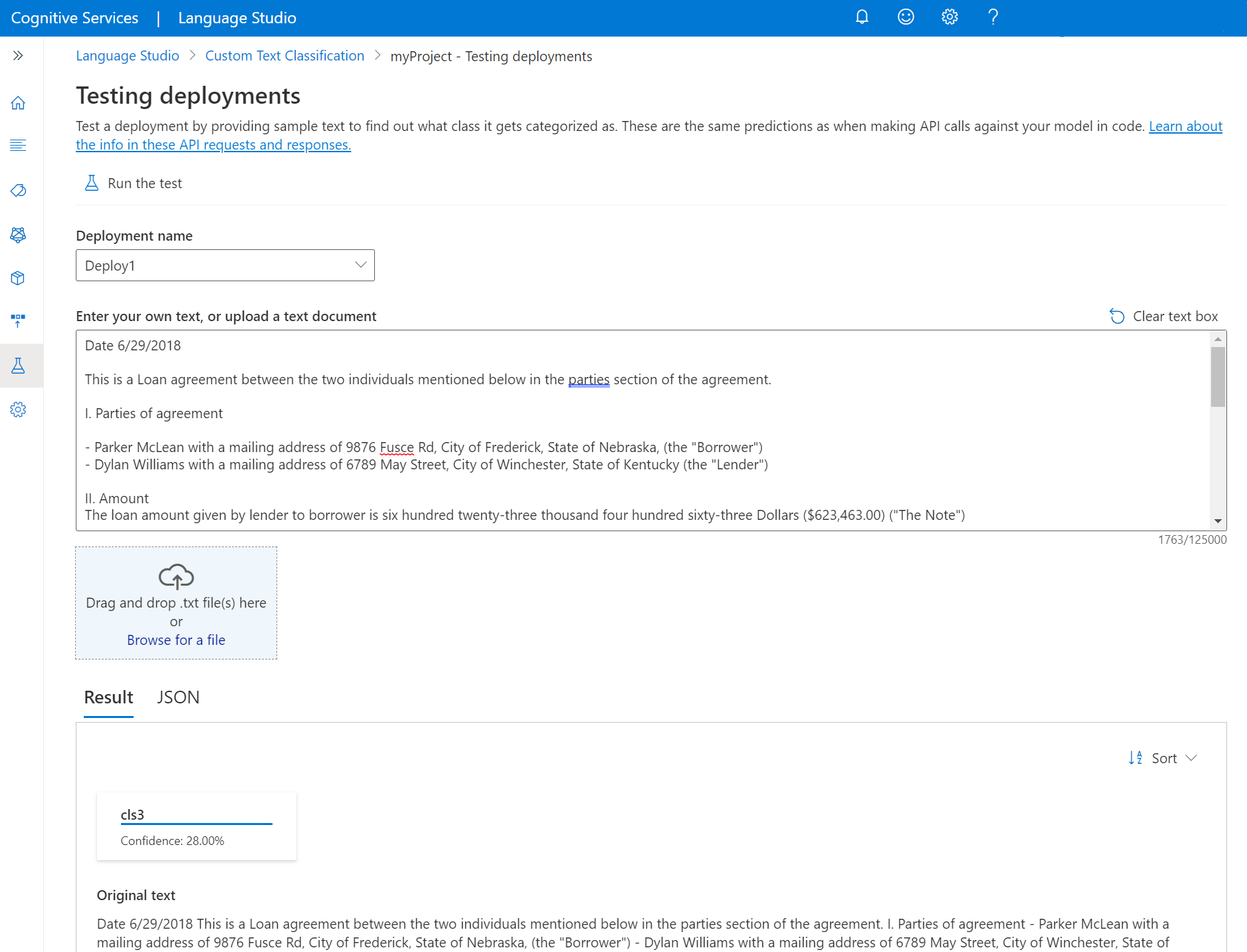
Select Testing deployments from the menu on the left side of the screen.
Select the deployment you want to test. You can only test models that are assigned to deployments.
For multilingual projects, select the language of the text you're testing using the language dropdown.
Select the deployment you want to query/test from the dropdown.
Enter the text you want to submit in the request, or upload a
.txtdocument to use. If you’re using one of the example datasets, you can use one of the included .txt files.Select Run the test from the top menu.
In the Result tab, you can see the predicted classes for your text. You can also view the JSON response under the JSON tab. The following example is for a single label classification project. A multi label classification project can return more than one class in the result.

Clean up projects
When you don't need your project anymore, you can delete your project using Language Studio. Select Custom text classification in the top, and then select the project you want to delete. Select Delete from the top menu to delete the project.
Prerequisites
- Azure subscription - Create one for free.
Create a new Azure AI Language resource and Azure storage account
Before you can use custom text classification, you'll need to create an Azure AI Language resource, which will give you the credentials that you need to create a project and start training a model. You'll also need an Azure storage account, where you can upload your dataset that will be used in building your model.
Important
To get started quickly, we recommend creating a new Azure AI Language resource using the steps provided in this article, which will let you create the Language resource, and create and/or connect a storage account at the same time, which is easier than doing it later.
If you have a pre-existing resource that you'd like to use, you will need to connect it to storage account.
Create a new resource from the Azure portal
Go to the Azure portal to create a new Azure AI Language resource.
In the window that appears, select Custom text classification & custom named entity recognition from the custom features. Select Continue to create your resource at the bottom of the screen.
Create a Language resource with following details.
Name Required value Subscription Your Azure subscription. Resource group A resource group that will contain your resource. You can use an existing one, or create a new one. Region One of the supported regions. For example "West US 2". Name A name for your resource. Pricing tier One of the supported pricing tiers. You can use the Free (F0) tier to try the service. If you get a message saying "your login account is not an owner of the selected storage account's resource group", your account needs to have an owner role assigned on the resource group before you can create a Language resource. Contact your Azure subscription owner for assistance.
You can determine your Azure subscription owner by searching your resource group and following the link to its associated subscription. Then:
- Select the Access Control (IAM) tab
- Select Role assignments
- Filter by Role:Owner.
In the Custom text classification & custom named entity recognition section, select an existing storage account or select New storage account. Note that these values are to help you get started, and not necessarily the storage account values you’ll want to use in production environments. To avoid latency during building your project connect to storage accounts in the same region as your Language resource.
Storage account value Recommended value Storage account name Any name Storage account type Standard LRS Make sure the Responsible AI Notice is checked. Select Review + create at the bottom of the page.
Upload sample data to blob container
After you have created an Azure storage account and connected it to your Language resource, you will need to upload the documents from the sample dataset to the root directory of your container. These documents will later be used to train your model.
Download the sample dataset for multi label classification projects.
Open the .zip file, and extract the folder containing the documents.
The provided sample dataset contains about 200 documents, each of which is a summary for a movie. Each document belongs to one or more of the following classes:
- "Mystery"
- "Drama"
- "Thriller"
- "Comedy"
- "Action"
In the Azure portal, navigate to the storage account you created, and select it. You can do this by clicking Storage accounts and typing your storage account name into Filter for any field.
if your resource group does not show up, make sure the Subscription equals filter is set to All.
In your storage account, select Containers from the left menu, located below Data storage. On the screen that appears, select + Container. Give the container the name example-data and leave the default Public access level.
After your container has been created, select it. Then select Upload button to select the
.txtand.jsonfiles you downloaded earlier.
Get your resource keys and endpoint
Go to your resource overview page in the Azure portal
From the menu on the left side, select Keys and Endpoint. You will use the endpoint and key for the API requests

Create a custom text classification project
Once your resource and storage container are configured, create a new custom text classification project. A project is a work area for building your custom ML models based on your data. Your project can only be accessed by you and others who have access to the Language resource being used.
Trigger import project job
Submit a POST request using the following URL, headers, and JSON body to import your labels file. Make sure that your labels file follow the accepted format.
If a project with the same name already exists, the data of that project is replaced.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Placeholder | Value | Example |
|---|---|---|
{ENDPOINT} |
The endpoint for authenticating your API request. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
The name for your project. This value is case-sensitive. | myProject |
{API-VERSION} |
The version of the API you are calling. The value referenced here is for the latest version released. Learn more about other available API versions | 2022-05-01 |
Headers
Use the following header to authenticate your request.
| Key | Value |
|---|---|
Ocp-Apim-Subscription-Key |
The key to your resource. Used for authenticating your API requests. |
Body
Use the following JSON in your request. Replace the placeholder values below with your own values.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customMultiLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class2"
}
]
}
]
}
}
| Key | Placeholder | Value | Example |
|---|---|---|---|
| api-version | {API-VERSION} |
The version of the API you are calling. The version used here must be the same API version in the URL. Learn more about other available API versions | 2022-05-01 |
| projectName | {PROJECT-NAME} |
The name of your project. This value is case-sensitive. | myProject |
| projectKind | customMultiLabelClassification |
Your project kind. | customMultiLabelClassification |
| language | {LANGUAGE-CODE} |
A string specifying the language code for the documents used in your project. If your project is a multilingual project, choose the language code of the majority of the documents. See language support to learn more about multilingual support. | en-us |
| multilingual | true |
A boolean value that enables you to have documents in multiple languages in your dataset and when your model is deployed you can query the model in any supported language (not necessarily included in your training documents. See language support to learn more about multilingual support. | true |
| storageInputContainerName | {CONTAINER-NAME} |
The name of your Azure storage container where you have uploaded your documents. | myContainer |
| classes | [] | Array containing all the classes you have in the project. These are the classes you want to classify your documents into. | [] |
| documents | [] | Array containing all the documents in your project and what the classes labeled for this document. | [] |
| location | {DOCUMENT-NAME} |
The location of the documents in the storage container. Since all the documents are in the root of the container this should be the document name. | doc1.txt |
| dataset | {DATASET} |
The test set to which this document will go to when split before training. See How to train a model for more information on data splitting. Possible values for this field are Train and Test. |
Train |
Once you send your API request, you’ll receive a 202 response indicating that the job was submitted correctly. In the response headers, extract the operation-location value. It will be formatted like this:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} is used to identify your request, since this operation is asynchronous. You’ll use this URL to get the import job status.
Possible error scenarios for this request:
- The selected resource doesn't have proper permissions for the storage account.
- The
storageInputContainerNamespecified doesn't exist. - Invalid language code is used, or if the language code type isn't string.
multilingualvalue is a string and not a boolean.
Get import job Status
Use the following GET request to get the status of your importing your project. Replace the placeholder values below with your own values.
Request URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Placeholder | Value | Example |
|---|---|---|
{ENDPOINT} |
The endpoint for authenticating your API request. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
The name of your project. This value is case-sensitive. | myProject |
{JOB-ID} |
The ID for locating your model's training status. This value is in the location header value you received in the previous step. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
The version of the API you are calling. The value referenced here is for the latest version released. Learn more about other available API versions | 2022-05-01 |
Headers
Use the following header to authenticate your request.
| Key | Value |
|---|---|
Ocp-Apim-Subscription-Key |
The key to your resource. Used for authenticating your API requests. |
Train your model
Typically after you create a project, you go ahead and start tagging the documents you have in the container connected to your project. For this quickstart, you have imported a sample tagged dataset and initialized your project with the sample JSON tags file.
Start training your model
After your project has been imported, you can start training your model.
Submit a POST request using the following URL, headers, and JSON body to submit a training job. Replace the placeholder values below with your own values.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Placeholder | Value | Example |
|---|---|---|
{ENDPOINT} |
The endpoint for authenticating your API request. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
The name of your project. This value is case-sensitive. | myProject |
{API-VERSION} |
The version of the API you are calling. The value referenced here is for the latest version released. Learn more about other available API versions | 2022-05-01 |
Headers
Use the following header to authenticate your request.
| Key | Value |
|---|---|
Ocp-Apim-Subscription-Key |
The key to your resource. Used for authenticating your API requests. |
Request body
Use the following JSON in your request body. The model will be given the {MODEL-NAME} once training is complete. Only successful training jobs will produce models.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Key | Placeholder | Value | Example |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
The model name that will be assigned to your model once trained successfully. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
This is the model version that will be used to train the model. | 2022-05-01 |
| evaluationOptions | Option to split your data across training and testing sets. | {} |
|
| kind | percentage |
Split methods. Possible values are percentage or manual. See How to train a model for more information. |
percentage |
| trainingSplitPercentage | 80 |
Percentage of your tagged data to be included in the training set. Recommended value is 80. |
80 |
| testingSplitPercentage | 20 |
Percentage of your tagged data to be included in the testing set. Recommended value is 20. |
20 |
Note
The trainingSplitPercentage and testingSplitPercentage are only required if Kind is set to percentage and the sum of both percentages should be equal to 100.
Once you send your API request, you’ll receive a 202 response indicating that the job was submitted correctly. In the response headers, extract the location value. It will be formatted like this:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} is used to identify your request, since this operation is asynchronous. You can use this URL to get the training status.
Get training job status
Training could take sometime between 10 and 30 minutes. You can use the following request to keep polling the status of the training job until it's successfully completed.
Use the following GET request to get the status of your model's training progress. Replace the placeholder values below with your own values.
Request URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Placeholder | Value | Example |
|---|---|---|
{ENDPOINT} |
The endpoint for authenticating your API request. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
The name of your project. This value is case-sensitive. | myProject |
{JOB-ID} |
The ID for locating your model's training status. This value is in the location header value you received in the previous step. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
The version of the API you are calling. The value referenced here is for the latest version released. See model lifecycle to learn more about other available API versions. | 2022-05-01 |
Headers
Use the following header to authenticate your request.
| Key | Value |
|---|---|
Ocp-Apim-Subscription-Key |
The key to your resource. Used for authenticating your API requests. |
Response Body
Once you send the request, you’ll get the following response.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Deploy your model
Generally after training a model you would review it's evaluation details and make improvements if necessary. In this quickstart, you will just deploy your model, and make it available for you to try in Language Studio, or you can call the prediction API.
Submit deployment job
Submit a PUT request using the following URL, headers, and JSON body to submit a deployment job. Replace the placeholder values below with your own values.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Placeholder | Value | Example |
|---|---|---|
{ENDPOINT} |
The endpoint for authenticating your API request. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
The name of your project. This value is case-sensitive. | myProject |
{DEPLOYMENT-NAME} |
The name of your deployment. This value is case-sensitive. | staging |
{API-VERSION} |
The version of the API you are calling. The value referenced here is for the latest version released. Learn more about other available API versions | 2022-05-01 |
Headers
Use the following header to authenticate your request.
| Key | Value |
|---|---|
Ocp-Apim-Subscription-Key |
The key to your resource. Used for authenticating your API requests. |
Request body
Use the following JSON in the body of your request. Use the name of the model you to assign to the deployment.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Key | Placeholder | Value | Example |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
The model name that will be assigned to your deployment. You can only assign successfully trained models. This value is case-sensitive. | myModel |
Once you send your API request, you’ll receive a 202 response indicating that the job was submitted correctly. In the response headers, extract the operation-location value. It will be formatted like this:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} is used to identify your request, since this operation is asynchronous. You can use this URL to get the deployment status.
Get deployment job status
Use the following GET request to query the status of the deployment job. You can use the URL you received from the previous step, or replace the placeholder values below with your own values.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Placeholder | Value | Example |
|---|---|---|
{ENDPOINT} |
The endpoint for authenticating your API request. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
The name of your project. This value is case-sensitive. | myProject |
{DEPLOYMENT-NAME} |
The name of your deployment. This value is case-sensitive. | staging |
{JOB-ID} |
The ID for locating your model's training status. This is in the location header value you received in the previous step. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
The version of the API you are calling. The value referenced here is for the latest version released. Learn more about other available API versions | 2022-05-01 |
Headers
Use the following header to authenticate your request.
| Key | Value |
|---|---|
Ocp-Apim-Subscription-Key |
The key to your resource. Used for authenticating your API requests. |
Response Body
Once you send the request, you will get the following response. Keep polling this endpoint until the status parameter changes to "succeeded". You should get a 200 code to indicate the success of the request.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Classify text
After your model is deployed successfully, you can start using it to classify your text via Prediction API. In the sample dataset you downloaded earlier you can find some test documents that you can use in this step.
Submit a custom text classification task
Use this POST request to start a text classification task.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Placeholder | Value | Example |
|---|---|---|
{ENDPOINT} |
The endpoint for authenticating your API request. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
The version of the API you are calling. The value referenced here is for the latest version released. See Model lifecycle to learn more about other available API versions. | 2022-05-01 |
Headers
| Key | Value |
|---|---|
| Ocp-Apim-Subscription-Key | Your key that provides access to this API. |
Body
{
"displayName": "Classifying documents",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Key | Placeholder | Value | Example |
|---|---|---|---|
displayName |
{JOB-NAME} |
Your job name. | MyJobName |
documents |
[{},{}] | List of documents to run tasks on. | [{},{}] |
id |
{DOC-ID} |
Document name or ID. | doc1 |
language |
{LANGUAGE-CODE} |
A string specifying the language code for the document. If this key isn't specified, the service will assume the default language of the project that was selected during project creation. See language support for a list of supported language codes. | en-us |
text |
{DOC-TEXT} |
Document task to run the tasks on. | Lorem ipsum dolor sit amet |
tasks |
List of tasks we want to perform. | [] |
|
taskName |
CustomMultiLabelClassification | The task name | CustomMultiLabelClassification |
parameters |
List of parameters to pass to the task. | ||
project-name |
{PROJECT-NAME} |
The name for your project. This value is case-sensitive. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
The name of your deployment. This value is case-sensitive. | prod |
Response
You will receive a 202 response indicating success. In the response headers, extract operation-location.
operation-location is formatted like this:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
You can use this URL to query the task completion status and get the results when task is completed.
Get task results
Use the following GET request to query the status/results of the text classification task.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Placeholder | Value | Example |
|---|---|---|
{ENDPOINT} |
The endpoint for authenticating your API request. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
The version of the API you're calling. The value referenced here is for the latest released model version version. | 2022-05-01 |
Headers
| Key | Value |
|---|---|
| Ocp-Apim-Subscription-Key | Your key that provides access to this API. |
Response body
The response will be a JSON document with the following parameters.
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxxxx-xxxxx-xxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "customMultiClassificationTasks",
"taskName": "Classify documents",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "{DOC-ID}",
"classes": [
{
"category": "Class_1",
"confidenceScore": 0.0551877357
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
Clean up resources
When you no longer need your project, you can delete it with the following DELETE request. Replace the placeholder values with your own values.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Placeholder | Value | Example |
|---|---|---|
{ENDPOINT} |
The endpoint for authenticating your API request. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
The name for your project. This value is case-sensitive. | myProject |
{API-VERSION} |
The version of the API you are calling. The value referenced here is for the latest version released. Learn more about other available API versions | 2022-05-01 |
Headers
Use the following header to authenticate your request.
| Key | Value |
|---|---|
| Ocp-Apim-Subscription-Key | The key to your resource. Used for authenticating your API requests. |
Once you send your API request, you will receive a 202 response indicating success, which means your project has been deleted. A successful call results with an Operation-Location header used to check the status of the job.
Next steps
After you've created a custom text classification model, you can:
When you start to create your own custom text classification projects, use the how-to articles to learn more about developing your model in greater detail: