Copy data to and from Azure Databricks Delta Lake using Azure Data Factory or Azure Synapse Analytics
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This article outlines how to use the Copy activity in Azure Data Factory and Azure Synapse to copy data to and from Azure Databricks Delta Lake. It builds on the Copy activity article, which presents a general overview of copy activity.
Supported capabilities
This Azure Databricks Delta Lake connector is supported for the following capabilities:
| Supported capabilities | IR |
|---|---|
| Copy activity (source/sink) | ① ② |
| Mapping data flow (source/sink) | ① |
| Lookup activity | ① ② |
① Azure integration runtime ② Self-hosted integration runtime
In general, the service supports Delta Lake with the following capabilities to meet your various needs.
- Copy activity supports Azure Databricks Delta Lake connector to copy data from any supported source data store to Azure Databricks delta lake table, and from delta lake table to any supported sink data store. It leverages your Databricks cluster to perform the data movement, see details in Prerequisites section.
- Mapping Data Flow supports generic Delta format on Azure Storage as source and sink to read and write Delta files for code-free ETL, and runs on managed Azure Integration Runtime.
- Databricks activities supports orchestrating your code-centric ETL or machine learning workload on top of delta lake.
Prerequisites
To use this Azure Databricks Delta Lake connector, you need to set up a cluster in Azure Databricks.
- To copy data to delta lake, Copy activity invokes Azure Databricks cluster to read data from an Azure Storage, which is either your original source or a staging area to where the service firstly writes the source data via built-in staged copy. Learn more from Delta lake as the sink.
- Similarly, to copy data from delta lake, Copy activity invokes Azure Databricks cluster to write data to an Azure Storage, which is either your original sink or a staging area from where the service continues to write data to final sink via built-in staged copy. Learn more from Delta lake as the source.
The Databricks cluster needs to have access to Azure Blob or Azure Data Lake Storage Gen2 account, both the storage container/file system used for source/sink/staging and the container/file system where you want to write the Delta Lake tables.
To use Azure Data Lake Storage Gen2, you can configure a service principal on the Databricks cluster as part of the Apache Spark configuration. Follow the steps in Access directly with service principal.
To use Azure Blob storage, you can configure a storage account access key or SAS token on the Databricks cluster as part of the Apache Spark configuration. Follow the steps in Access Azure Blob storage using the RDD API.
During copy activity execution, if the cluster you configured has been terminated, the service automatically starts it. If you author pipeline using authoring UI, for operations like data preview, you need to have a live cluster, the service won't start the cluster on your behalf.
Specify the cluster configuration
In the Cluster Mode drop-down, select Standard.
In the Databricks Runtime Version drop-down, select a Databricks runtime version.
Turn on Auto Optimize by adding the following properties to your Spark configuration:
spark.databricks.delta.optimizeWrite.enabled true spark.databricks.delta.autoCompact.enabled trueConfigure your cluster depending on your integration and scaling needs.
For cluster configuration details, see Configure clusters.
Get started
To perform the Copy activity with a pipeline, you can use one of the following tools or SDKs:
- The Copy Data tool
- The Azure portal
- The .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- The Azure Resource Manager template
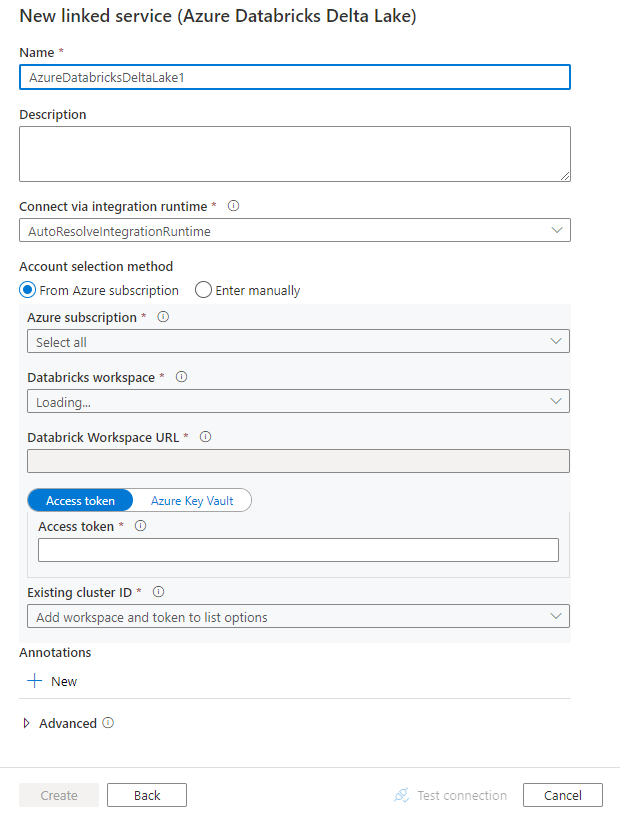
Create a linked service to Azure Databricks Delta Lake using UI
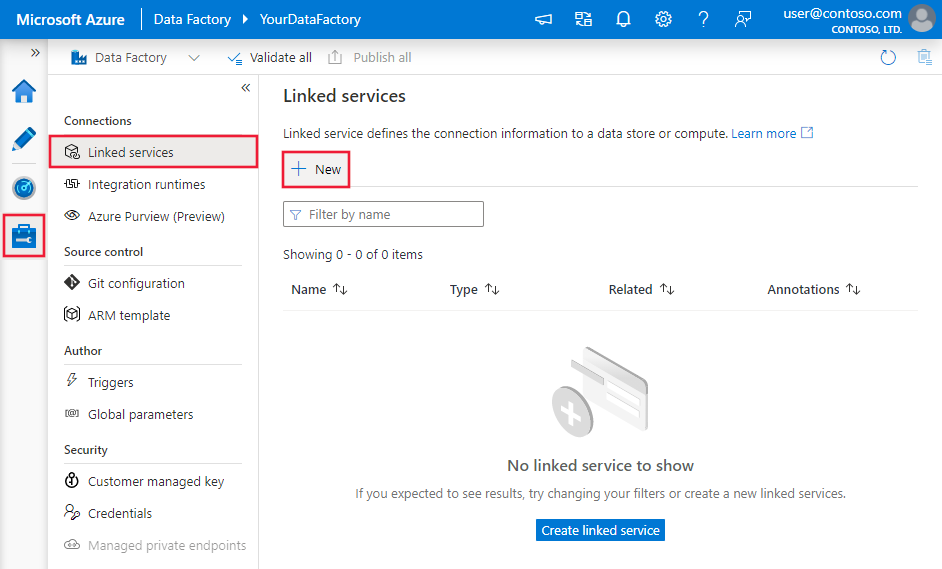
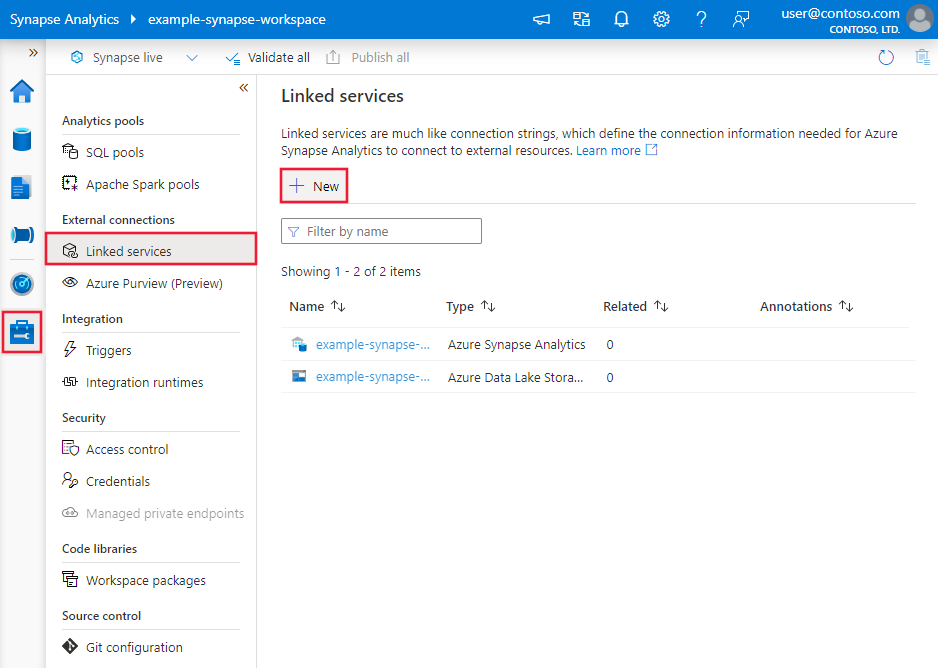
Use the following steps to create a linked service to Azure Databricks Delta Lake in the Azure portal UI.
Browse to the Manage tab in your Azure Data Factory or Synapse workspace and select Linked Services, then click New:
Search for delta and select the Azure Databricks Delta Lake connector.

Configure the service details, test the connection, and create the new linked service.
Connector configuration details
The following sections provide details about properties that define entities specific to an Azure Databricks Delta Lake connector.
Linked service properties
This Azure Databricks Delta Lake connector supports the following authentication types. See the corresponding sections for details.
- Access token
- System-assigned managed identity authentication
- User-assigned managed identity authentication
Access token
The following properties are supported for the Azure Databricks Delta Lake linked service:
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to AzureDatabricksDeltaLake. | Yes |
| domain | Specify the Azure Databricks workspace URL, e.g. https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
|
| clusterId | Specify the cluster ID of an existing cluster. It should be an already created Interactive Cluster. You can find the Cluster ID of an Interactive Cluster on Databricks workspace -> Clusters -> Interactive Cluster Name -> Configuration -> Tags. Learn more. |
|
| accessToken | Access token is required for the service to authenticate to Azure Databricks. Access token needs to be generated from the databricks workspace. More detailed steps to find the access token can be found here. | |
| connectVia | The integration runtime that is used to connect to the data store. You can use the Azure integration runtime or a self-hosted integration runtime (if your data store is located in a private network). If not specified, it uses the default Azure integration runtime. | No |
Example:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"accessToken": {
"type": "SecureString",
"value": "<access token>"
}
}
}
}
System-assigned managed identity authentication
To learn more about system-assigned managed identities for Azure resources, see system-assigned managed identity for Azure resources.
To use system-assigned managed identity authentication, follow these steps to grant permissions:
Retrieve the managed identity information by copying the value of the managed identity object ID generated along with your data factory or Synapse workspace.
Grant the managed identity the correct permissions in Azure Databricks. In general, you must grant at least the Contributor role to your system-assigned managed identity in Access control (IAM) of Azure Databricks.
The following properties are supported for the Azure Databricks Delta Lake linked service:
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to AzureDatabricksDeltaLake. | Yes |
| domain | Specify the Azure Databricks workspace URL, e.g. https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Yes |
| clusterId | Specify the cluster ID of an existing cluster. It should be an already created Interactive Cluster. You can find the Cluster ID of an Interactive Cluster on Databricks workspace -> Clusters -> Interactive Cluster Name -> Configuration -> Tags. Learn more. |
Yes |
| workspaceResourceId | Specify the workspace resource ID of your Azure Databricks. | Yes |
| connectVia | The integration runtime that is used to connect to the data store. You can use the Azure integration runtime or a self-hosted integration runtime (if your data store is located in a private network). If not specified, it uses the default Azure integration runtime. | No |
Example:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
User-assigned managed identity authentication
To learn more about user-assigned managed identities for Azure resources, see user-assigned managed identities
To use user-assigned managed identity authentication, follow these steps:
Create one or multiple user-assigned managed identities and grant permission in your Azure Databricks. In general, you must grant at least the Contributor role to your user-assigned managed identity in Access control (IAM) of Azure Databricks.
Assign one or multiple user-assigned managed identities to your data factory or Synapse workspace, and create credentials for each user-assigned managed identity.
The following properties are supported for the Azure Databricks Delta Lake linked service:
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to AzureDatabricksDeltaLake. | Yes |
| domain | Specify the Azure Databricks workspace URL, e.g. https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Yes |
| clusterId | Specify the cluster ID of an existing cluster. It should be an already created Interactive Cluster. You can find the Cluster ID of an Interactive Cluster on Databricks workspace -> Clusters -> Interactive Cluster Name -> Configuration -> Tags. Learn more. |
Yes |
| credentials | Specify the user-assigned managed identity as the credential object. | Yes |
| workspaceResourceId | Specify the workspace resource ID of your Azure Databricks. | Yes |
| connectVia | The integration runtime that is used to connect to the data store. You can use the Azure integration runtime or a self-hosted integration runtime (if your data store is located in a private network). If not specified, it uses the default Azure integration runtime. | No |
Example:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset properties
For a full list of sections and properties available for defining datasets, see the Datasets article.
The following properties are supported for the Azure Databricks Delta Lake dataset.
| Property | Description | Required |
|---|---|---|
| type | The type property of the dataset must be set to AzureDatabricksDeltaLakeDataset. | Yes |
| database | Name of the database. | No for source, yes for sink |
| table | Name of the delta table. | No for source, yes for sink |
Example:
{
"name": "AzureDatabricksDeltaLakeDataset",
"properties": {
"type": "AzureDatabricksDeltaLakeDataset",
"typeProperties": {
"database": "<database name>",
"table": "<delta table name>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Copy activity properties
For a full list of sections and properties available for defining activities, see the Pipelines article. This section provides a list of properties supported by the Azure Databricks Delta Lake source and sink.
Delta lake as source
To copy data from Azure Databricks Delta Lake, the following properties are supported in the Copy activity source section.
| Property | Description | Required |
|---|---|---|
| type | The type property of the Copy activity source must be set to AzureDatabricksDeltaLakeSource. | Yes |
| query | Specify the SQL query to read data. For the time travel control, follow the below pattern: - SELECT * FROM events TIMESTAMP AS OF timestamp_expression- SELECT * FROM events VERSION AS OF version |
No |
| exportSettings | Advanced settings used to retrieve data from delta table. | No |
Under exportSettings: |
||
| type | The type of export command, set to AzureDatabricksDeltaLakeExportCommand. | Yes |
| dateFormat | Format date type to string with a date format. Custom date formats follow the formats at datetime pattern. If not specified, it uses the default value yyyy-MM-dd. |
No |
| timestampFormat | Format timestamp type to string with a timestamp format. Custom date formats follow the formats at datetime pattern. If not specified, it uses the default value yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]. |
No |
Direct copy from delta lake
If your sink data store and format meet the criteria described in this section, you can use the Copy activity to directly copy from Azure Databricks Delta table to sink. The service checks the settings and fails the Copy activity run if the following criteria is not met:
The sink linked service is Azure Blob storage or Azure Data Lake Storage Gen2. The account credential should be pre-configured in Azure Databricks cluster configuration, learn more from Prerequisites.
The sink data format is of Parquet, delimited text, or Avro with the following configurations, and points to a folder instead of file.
- For Parquet format, the compression codec is none, snappy, or gzip.
- For delimited text format:
rowDelimiteris any single character.compressioncan be none, bzip2, gzip.encodingNameUTF-7 is not supported.
- For Avro format, the compression codec is none, deflate, or snappy.
In the Copy activity source,
additionalColumnsis not specified.If copying data to delimited text, in copy activity sink,
fileExtensionneed to be ".csv".In the Copy activity mapping, type conversion is not enabled.
Example:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Staged copy from delta lake
When your sink data store or format does not match the direct copy criteria, as mentioned in the last section, enable the built-in staged copy using an interim Azure storage instance. The staged copy feature also provides you better throughput. The service exports data from Azure Databricks Delta Lake into staging storage, then copies the data to sink, and finally cleans up your temporary data from the staging storage. See Staged copy for details about copying data by using staging.
To use this feature, create an Azure Blob storage linked service or Azure Data Lake Storage Gen2 linked service that refers to the storage account as the interim staging. Then specify the enableStaging and stagingSettings properties in the Copy activity.
Note
The staging storage account credential should be pre-configured in Azure Databricks cluster configuration, learn more from Prerequisites.
Example:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Delta lake as sink
To copy data to Azure Databricks Delta Lake, the following properties are supported in the Copy activity sink section.
| Property | Description | Required |
|---|---|---|
| type | The type property of the Copy activity sink, set to AzureDatabricksDeltaLakeSink. | Yes |
| preCopyScript | Specify a SQL query for the Copy activity to run before writing data into Databricks delta table in each run. Example : VACUUM eventsTable DRY RUN You can use this property to clean up the preloaded data, or add a truncate table or Vacuum statement. |
No |
| importSettings | Advanced settings used to write data into delta table. | No |
Under importSettings: |
||
| type | The type of import command, set to AzureDatabricksDeltaLakeImportCommand. | Yes |
| dateFormat | Format string to date type with a date format. Custom date formats follow the formats at datetime pattern. If not specified, it uses the default value yyyy-MM-dd. |
No |
| timestampFormat | Format string to timestamp type with a timestamp format. Custom date formats follow the formats at datetime pattern. If not specified, it uses the default value yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]. |
No |
Direct copy to delta lake
If your source data store and format meet the criteria described in this section, you can use the Copy activity to directly copy from source to Azure Databricks Delta Lake. The service checks the settings and fails the Copy activity run if the following criteria is not met:
The source linked service is Azure Blob storage or Azure Data Lake Storage Gen2. The account credential should be pre-configured in Azure Databricks cluster configuration, learn more from Prerequisites.
The source data format is of Parquet, delimited text, or Avro with the following configurations, and points to a folder instead of file.
- For Parquet format, the compression codec is none, snappy, or gzip.
- For delimited text format:
rowDelimiteris default, or any single character.compressioncan be none, bzip2, gzip.encodingNameUTF-7 is not supported.
- For Avro format, the compression codec is none, deflate, or snappy.
In the Copy activity source:
wildcardFileNameonly contains wildcard*but not?, andwildcardFolderNameis not specified.prefix,modifiedDateTimeStart,modifiedDateTimeEnd, andenablePartitionDiscoveryare not specified.additionalColumnsis not specified.
In the Copy activity mapping, type conversion is not enabled.
Example:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink",
"sqlReadrQuery": "VACUUM eventsTable DRY RUN"
}
}
}
]
Staged copy to delta lake
When your source data store or format does not match the direct copy criteria, as mentioned in the last section, enable the built-in staged copy using an interim Azure storage instance. The staged copy feature also provides you better throughput. The service automatically converts the data to meet the data format requirements into staging storage, then load data into delta lake from there. Finally, it cleans up your temporary data from the storage. See Staged copy for details about copying data using staging.
To use this feature, create an Azure Blob storage linked service or Azure Data Lake Storage Gen2 linked service that refers to the storage account as the interim staging. Then specify the enableStaging and stagingSettings properties in the Copy activity.
Note
The staging storage account credential should be pre-configured in Azure Databricks cluster configuration, learn more from Prerequisites.
Example:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Monitoring
The same copy activity monitoring experience is provided as for other connectors. In addition, because loading data from/to delta lake is running on your Azure Databricks cluster, you can further view detailed cluster logs and monitor performance.
Lookup activity properties
For more information about the properties, see Lookup activity.
The Lookup activity can return up to 1000 rows; if the result set contains more records, the first 1000 rows will be returned.
Related content
For a list of data stores supported as sources and sinks by Copy activity, see supported data stores and formats.