Copy data from Oracle Cloud Storage using Azure Data Factory or Synapse Analytics
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This article outlines how to copy data from Oracle Cloud Storage. To learn more, read the introductory articles for Azure Data Factory and Synapse Analytics.
Supported capabilities
This Oracle Cloud Storage connector is supported for the following capabilities:
| Supported capabilities | IR |
|---|---|
| Copy activity (source/-) | ① ② |
| Lookup activity | ① ② |
| GetMetadata activity | ① ② |
| Delete activity | ① ② |
① Azure integration runtime ② Self-hosted integration runtime
Specifically, this Oracle Cloud Storage connector supports copying files as is or parsing files with the supported file formats and compression codecs. It takes advantage of Oracle Cloud Storage's S3-compatible interoperability.
Prerequisites
To copy data from Oracle Cloud Storage, please refer here for the prerequisites and required permission.
Getting started
To perform the Copy activity with a pipeline, you can use one of the following tools or SDKs:
- The Copy Data tool
- The Azure portal
- The .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- The Azure Resource Manager template
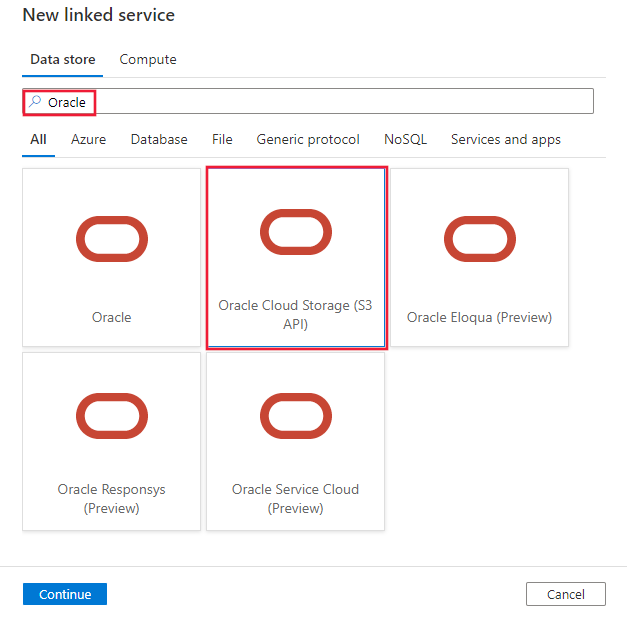
Create a linked service to Oracle Cloud Storage using UI
Use the following steps to create a linked service to Oracle Cloud Storage in the Azure portal UI.
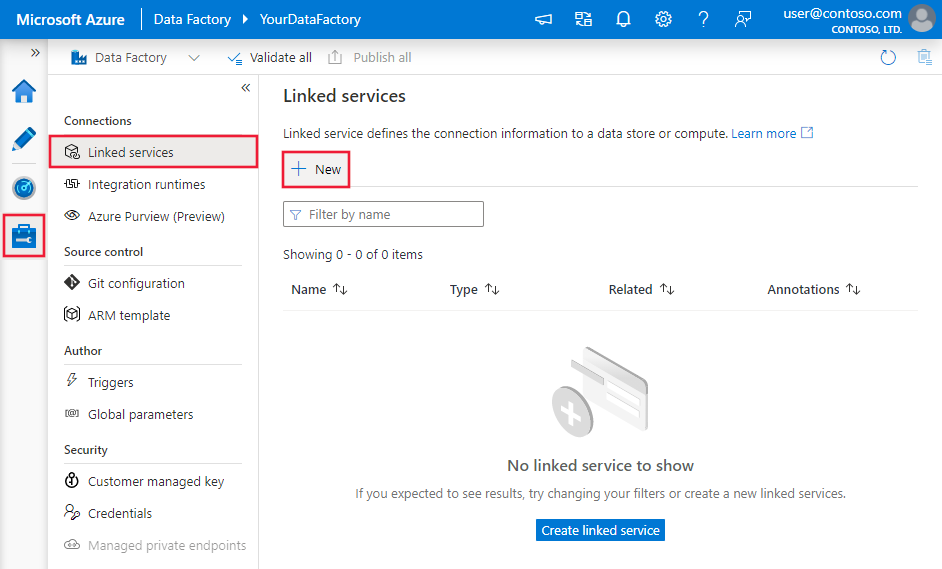
Browse to the Manage tab in your Azure Data Factory or Synapse workspace and select Linked Services, then click New:
Search for Oracle and select the Oracle Cloud Storage connector.
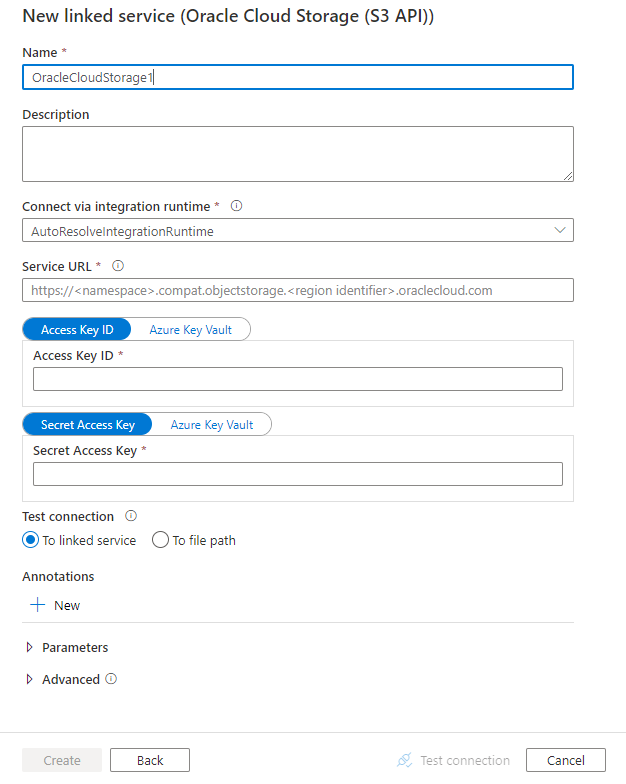
Configure the service details, test the connection, and create the new linked service.
Connector configuration details
The following sections provide details about properties that are used to define entities specific to Oracle Cloud Storage.
Linked service properties
The following properties are supported for Oracle Cloud Storage linked services:
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to OracleCloudStorage. | Yes |
| accessKeyId | ID of the secret access key. To find the access key and secret, see Prerequisites. | Yes |
| secretAccessKey | The secret access key itself. Mark this field as SecureString to store it securely, or reference a secret stored in Azure Key Vault. | Yes |
| serviceUrl | Specify the custom endpoint as https://<namespace>.compat.objectstorage.<region identifier>.oraclecloud.com. Refer here for more details |
Yes |
| connectVia | The integration runtime to be used to connect to the data store. You can use the Azure integration runtime or the self-hosted integration runtime (if your data store is in a private network). If this property isn't specified, the service uses the default Azure integration runtime. | No |
Here's an example:
{
"name": "OracleCloudStorageLinkedService",
"properties": {
"type": "OracleCloudStorage",
"typeProperties": {
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
},
"serviceUrl": "https://<namespace>.compat.objectstorage.<region identifier>.oraclecloud.com"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset properties
Azure Data Factory supports the following file formats. Refer to each article for format-based settings.
- Avro format
- Binary format
- Delimited text format
- Excel format
- JSON format
- ORC format
- Parquet format
- XML format
The following properties are supported for Oracle Cloud Storage under location settings in a format-based dataset:
| Property | Description | Required |
|---|---|---|
| type | The type property under location in the dataset must be set to OracleCloudStorageLocation. |
Yes |
| bucketName | The Oracle Cloud Storage bucket name. | Yes |
| folderPath | The path to folder under the given bucket. If you want to use a wildcard to filter the folder, skip this setting and specify that in activity source settings. | No |
| fileName | The file name under the given bucket and folder path. If you want to use a wildcard to filter the files, skip this setting and specify that in activity source settings. | No |
Example:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Oracle Cloud Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "OracleCloudStorageLocation",
"bucketName": "bucketname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Copy activity properties
For a full list of sections and properties available for defining activities, see the Pipelines article. This section provides a list of properties that the Oracle Cloud Storage source supports.
Oracle Cloud Storage as a source type
Azure Data Factory supports the following file formats. Refer to each article for format-based settings.
- Avro format
- Binary format
- Delimited text format
- Excel format
- JSON format
- ORC format
- Parquet format
- XML format
The following properties are supported for Oracle Cloud Storage under storeSettings settings in a format-based copy source:
| Property | Description | Required |
|---|---|---|
| type | The type property under storeSettings must be set to OracleCloudStorageReadSettings. |
Yes |
| Locate the files to copy: | ||
| OPTION 1: static path |
Copy from the given bucket or folder/file path specified in the dataset. If you want to copy all files from a bucket or folder, additionally specify wildcardFileName as *. |
|
| OPTION 2: Oracle Cloud Storage prefix - prefix |
Prefix for the Oracle Cloud Storage key name under the given bucket configured in the dataset to filter source Oracle Cloud Storage files. Oracle Cloud Storage keys whose names start with bucket_in_dataset/this_prefix are selected. It utilizes Oracle Cloud Storage's service-side filter, which provides better performance than a wildcard filter. |
No |
| OPTION 3: wildcard - wildcardFolderPath |
The folder path with wildcard characters under the given bucket configured in a dataset to filter source folders. Allowed wildcards are: * (matches zero or more characters) and ? (matches zero or single character). Use ^ to escape if your folder name has a wildcard or this escape character inside. See more examples in Folder and file filter examples. |
No |
| OPTION 4: wildcard - wildcardFileName |
The file name with wildcard characters under the given bucket and folder path (or wildcard folder path) to filter source files. Allowed wildcards are: * (matches zero or more characters) and ? (matches zero or single character). Use ^ to escape if your file name has a wildcard or this escape character inside. See more examples in Folder and file filter examples. |
Yes |
| OPTION 5: a list of files - fileListPath |
Indicates to copy a given file set. Point to a text file that includes a list of files you want to copy, one file per line, which is the relative path to the path configured in the dataset. When you're using this option, do not specify the file name in the dataset. See more examples in File list examples. |
No |
| Additional settings: | ||
| recursive | Indicates whether the data is read recursively from the subfolders or only from the specified folder. Note that when recursive is set to true and the sink is a file-based store, an empty folder or subfolder isn't copied or created at the sink. Allowed values are true (default) and false. This property doesn't apply when you configure fileListPath. |
No |
| deleteFilesAfterCompletion | Indicates whether the binary files will be deleted from source store after successfully moving to the destination store. The file deletion is per file, so when copy activity fails, you will see some files have already been copied to the destination and deleted from source, while others are still remaining on source store. This property is only valid in binary files copy scenario. The default value: false. |
No |
| modifiedDatetimeStart | Files are filtered based on the attribute: last modified. The files will be selected if their last modified time is greater than or equal to modifiedDatetimeStart and less than modifiedDatetimeEnd. The time is applied to the UTC time zone in the format of "2018-12-01T05:00:00Z". The properties can be NULL, which means no file attribute filter will be applied to the dataset. When modifiedDatetimeStart has a datetime value but modifiedDatetimeEnd is NULL, the files whose last modified attribute is greater than or equal to the datetime value will be selected. When modifiedDatetimeEnd has a datetime value but modifiedDatetimeStart is NULL, the files whose last modified attribute is less than the datetime value will be selected.This property doesn't apply when you configure fileListPath. |
No |
| modifiedDatetimeEnd | Same as above. | No |
| enablePartitionDiscovery | For files that are partitioned, specify whether to parse the partitions from the file path and add them as additional source columns. Allowed values are false (default) and true. |
No |
| partitionRootPath | When partition discovery is enabled, specify the absolute root path in order to read partitioned folders as data columns. If it is not specified, by default, - When you use file path in dataset or list of files on source, partition root path is the path configured in dataset. - When you use wildcard folder filter, partition root path is the sub-path before the first wildcard. For example, assuming you configure the path in dataset as "root/folder/year=2020/month=08/day=27": - If you specify partition root path as "root/folder/year=2020", copy activity will generate two more columns month and day with value "08" and "27" respectively, in addition to the columns inside the files.- If partition root path is not specified, no extra column will be generated. |
No |
| maxConcurrentConnections | The upper limit of concurrent connections established to the data store during the activity run. Specify a value only when you want to limit concurrent connections. | No |
Example:
"activities":[
{
"name": "CopyFromOracleCloudStorage",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "OracleCloudStorageReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Folder and file filter examples
This section describes the resulting behavior of the folder path and file name with wildcard filters.
| bucket | key | recursive | Source folder structure and filter result (files in bold are retrieved) |
|---|---|---|---|
| bucket | Folder*/* |
false | bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| bucket | Folder*/* |
true | bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| bucket | Folder*/*.csv |
false | bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| bucket | Folder*/*.csv |
true | bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
File list examples
This section describes the resulting behavior of using a file list path in the Copy activity source.
Assume that you have the following source folder structure and want to copy the files in bold:
| Sample source structure | Content in FileListToCopy.txt | Configuration |
|---|---|---|
| bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv Metadata FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
In dataset: - Bucket: bucket- Folder path: FolderAIn copy activity source: - File list path: bucket/Metadata/FileListToCopy.txt The file list path points to a text file in the same data store that includes a list of files you want to copy, one file per line, with the relative path to the path configured in the dataset. |
Lookup activity properties
To learn details about the properties, check Lookup activity.
GetMetadata activity properties
To learn details about the properties, check GetMetadata activity.
Delete activity properties
To learn details about the properties, check Delete activity.
Related content
For a list of data stores that the Copy activity supports as sources and sinks, see Supported data stores.