Build large-scale data copy pipelines with metadata-driven approach in copy data tool
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
When you want to copy huge amounts of objects (for example, thousands of tables) or load data from large variety of sources, the appropriate approach is to input the name list of the objects with required copy behaviors in a control table, and then use parameterized pipelines to read the same from the control table and apply them to the jobs accordingly. By doing so, you can maintain (for example, add/remove) the objects list to be copied easily by just updating the object names in control table instead of redeploying the pipelines. What’s more, you will have single place to easily check which objects copied by which pipelines/triggers with defined copy behaviors.
Copy data tool in ADF eases the journey of building such metadata driven data copy pipelines. After you go through an intuitive flow from a wizard-based experience, the tool can generate parameterized pipelines and SQL scripts for you to create external control tables accordingly. After you run the generated scripts to create the control table in your SQL database, your pipelines will read the metadata from the control table and apply them on the copy jobs automatically.
Create metadata-driven copy jobs from copy data tool
Select Metadata-driven copy task in copy data tool.
You need to input the connection and table name of your control table, so that the generated pipeline will read metadata from that.

Input the connection of your source database. You can use parameterized linked service as well.

Select the table name to copy.

Note
If you select tabular data store, you will have chance to further select either full load or delta load in the next page. If you select storage store, you can further select full load only in the next page. Incrementally loading new files only from storage store is currently not supported.
Choose loading behavior.
Tip
If you want to do full copy on all the tables, select Full load all tables. If you want to do incremental copy, you can select configure for each table individually, and select Delta load as well as watermark column name & value to start for each table.
Select Destination data store.
In Settings page, You can decide the max number of copy activities to copy data from your source store concurrently via Number of concurrent copy tasks. The default value is 20.

After pipeline deployment, you can copy or download the SQL scripts from UI for creating control table and store procedure.

You will see two SQL scripts.
- The first SQL script is used to create two control tables. The main control table stores the table list, file path or copy behaviors. The connection control table stores the connection value of your data store if you used parameterized linked service.
- The second SQL script is used to create a store procedure. It is used to update the watermark value in main control table when the incremental copy jobs complete every time.
Open SSMS to connect to your control table server, and run the two SQL scripts to create control tables and store procedure.
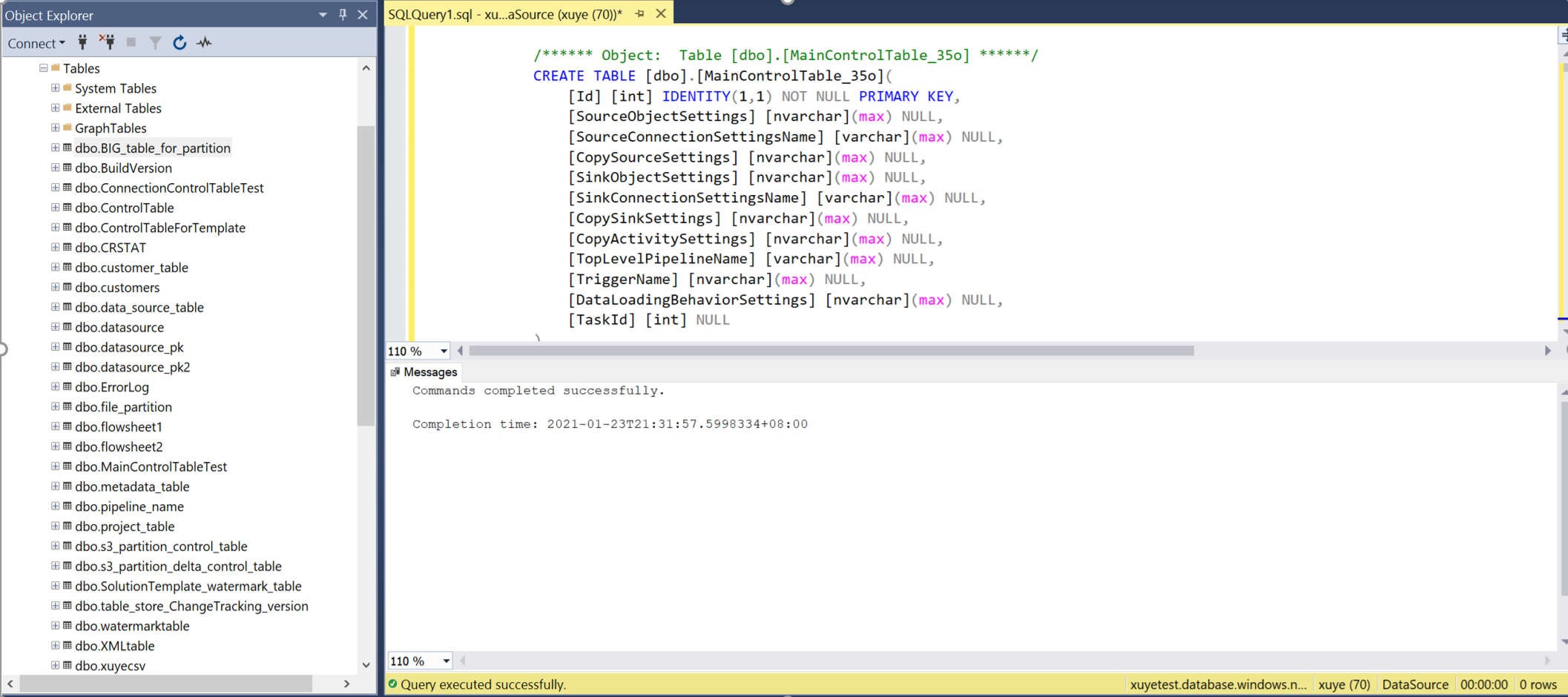
Query the main control table and connection control table to review the metadata in it.
Main control table

Connection control table

Go back to ADF portal to view and debug pipelines. You will see a folder created by naming "MetadataDrivenCopyTask_#########". Click the pipeline naming with "MetadataDrivenCopyTask###_TopLevel" and click debug run.
You are required to input the following parameters:
Parameters name Description MaxNumberOfConcurrentTasks You can always change the max number of concurrent copy activities run before pipeline run. The default value will be the one you input in copy data tool. MainControlTableName You can always change the main control table name, so the pipeline will get the metadata from that table before run. ConnectionControlTableName You can always change the connection control table name (optional), so the pipeline will get the metadata related to data store connection before run. MaxNumberOfObjectsReturnedFromLookupActivity In order to avoid reaching the limit of output lookup activity, there is a way to define the max number of objects returned by lookup activity. In most cases, the default value is not required to be changed. windowStart When you input dynamic value (for example, yyyy/mm/dd) as folder path, the parameter is used to pass the current trigger time to pipeline in order to fill the dynamic folder path. When the pipeline is triggered by schedule trigger or tumbling windows trigger, users do not need to input the value of this parameter. Sample value: 2021-01-25T01:49:28Z Enable the trigger to operationalize the pipelines.
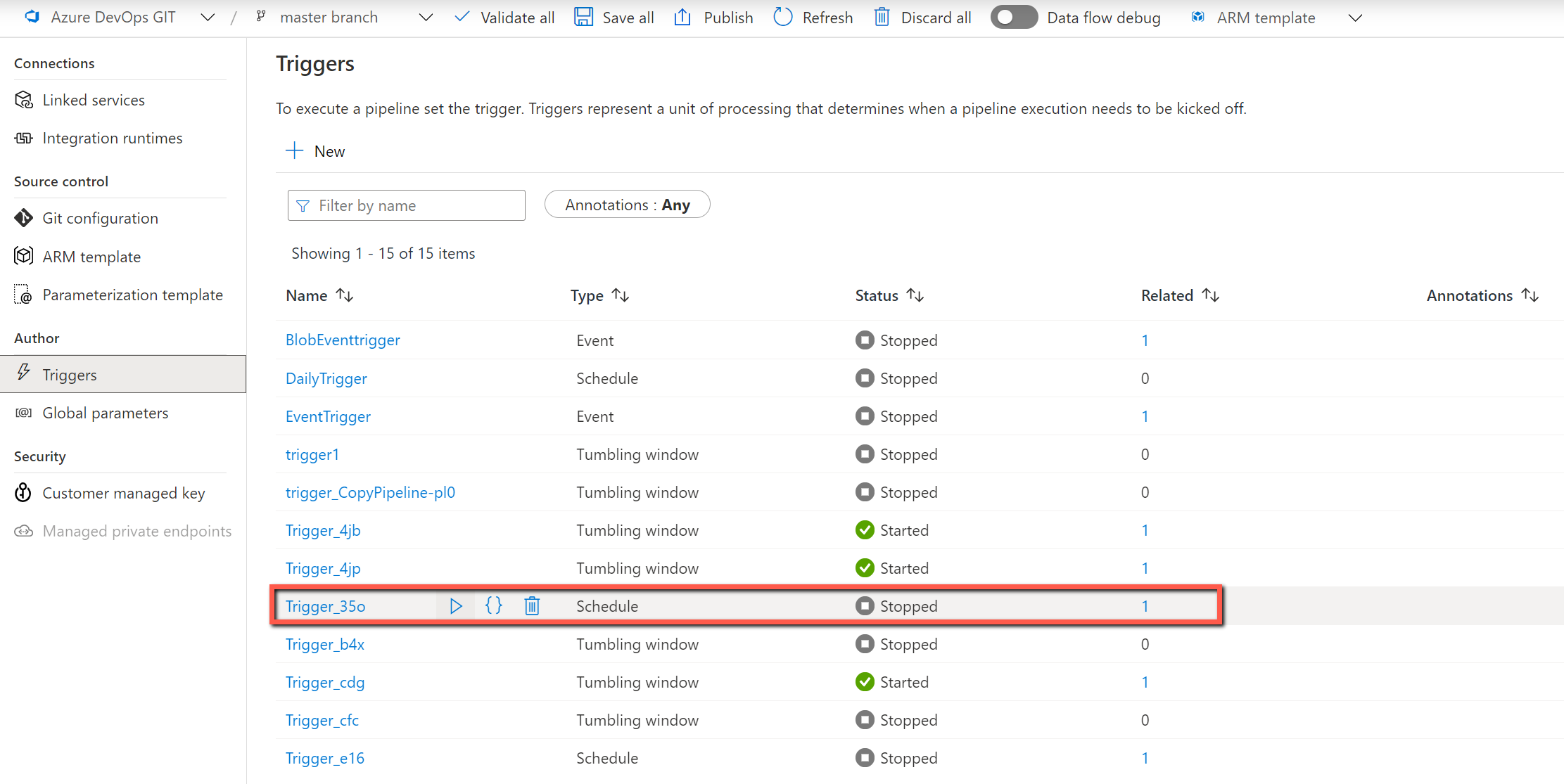
Update control table by copy data tool
You can always directly update the control table by adding or removing the object to be copied or changing the copy behavior for each table. We also create UI experience in copy data tool to ease the journey of editing the control table.
Right-click the top-level pipeline: MetadataDrivenCopyTask_xxx_TopLevel, and then select Edit control table.

Select rows from the control table to edit.

Go throughput the copy data tool, and it will come up with a new SQL script for you. Rerun the SQL script to update your control table.

Note
The pipeline will NOT be redeployed. The new created SQL script help you to update the control table only.
Control tables
Main control table
Each row in control table contains the metadata for one object (for example, one table) to be copied.
| Column name | Description |
|---|---|
| ID | Unique ID of the object to be copied. |
| SourceObjectSettings | Metadata of source dataset. It can be schema name, table name etc. Here is an example. |
| SourceConnectionSettingsName | The name of the source connection setting in connection control table. It is optional. |
| CopySourceSettings | Metadata of source property in copy activity. It can be query, partitions etc. Here is an example. |
| SinkObjectSettings | Metadata of destination dataset. It can be file name, folder path, table name etc. Here is an example. If dynamic folder path specified, the variable value will not be written here in control table. |
| SinkConnectionSettingsName | The name of the destination connection setting in connection control table. It is optional. |
| CopySinkSettings | Metadata of sink property in copy activity. It can be preCopyScript, tableOption etc. Here is an example. |
| CopyActivitySettings | Metadata of translator property in copy activity. It is used to define column mapping. |
| TopLevelPipelineName | Top Pipeline name, which can copy this object. |
| TriggerName | Trigger name, which can trigger the pipeline to copy this object. If debug run, the name is Sandbox. If manual execution, the name is Manual. If scheduled run, the name is the associated trigger name. It can be input multiple names. |
| DataLoadingBehaviorSettings | Full load vs. delta load. |
| TaskId | The order of objects to be copied following the TaskId in control table (ORDER BY [TaskId] DESC). If you have huge amounts of objects to be copied but only limited concurrent number of copied allowed, you can change the TaskId for each object to decide which objects can be copied earlier. The default value is 0. |
| CopyEnabled | Specify if the item is enabled in data ingestion process. Allowed values: 1 (enabled), 0 (disabled). Default value is 1. |
Connection control table
Each row in control table contains one connection setting for the data store.
| Column name | Description |
|---|---|
| Name | Name of the parameterized connection in main control table. |
| ConnectionSettings | The connection settings. It can be DB name, Server name and so on. |
Pipelines
You will see three levels of pipelines are generated by copy data tool.
MetadataDrivenCopyTask_xxx_TopLevel
This pipeline will calculate the total number of objects (tables etc.) required to be copied in this run, come up with the number of sequential batches based on the max allowed concurrent copy task, and then execute another pipeline to copy different batches sequentially.
Parameters
| Parameters name | Description |
|---|---|
| MaxNumberOfConcurrentTasks | You can always change the max number of concurrent copy activities run before pipeline run. The default value will be the one you input in copy data tool. |
| MainControlTableName | The table name of main control table. The pipeline will get the metadata from this table before run |
| ConnectionControlTableName | The table name of connection control table (optional). The pipeline will get the metadata related to data store connection before run |
| MaxNumberOfObjectsReturnedFromLookupActivity | In order to avoid reaching the limit of output lookup activity, there is a way to define the max number of objects returned by lookup activity. In most cases, the default value is not required to be changed. |
| windowStart | When you input dynamic value (for example, yyyy/mm/dd) as folder path, the parameter is used to pass the current trigger time to pipeline in order to fill the dynamic folder path. When the pipeline is triggered by schedule trigger or tumbling windows trigger, users do not need to input the value of this parameter. Sample value: 2021-01-25T01:49:28Z |
Activities
| Activity name | Activity type | Description |
|---|---|---|
| GetSumOfObjectsToCopy | Lookup | Calculate the total number of objects (tables etc.) required to be copied in this run. |
| CopyBatchesOfObjectsSequentially | ForEach | Come up with the number of sequential batches based on the max allowed concurrent copy tasks, and then execute another pipeline to copy different batches sequentially. |
| CopyObjectsInOneBtach | Execute Pipeline | Execute another pipeline to copy one batch of objects. The objects belonging to this batch will be copied in parallel. |
MetadataDrivenCopyTask_xxx_ MiddleLevel
This pipeline will copy one batch of objects. The objects belonging to this batch will be copied in parallel.
Parameters
| Parameters name | Description |
|---|---|
| MaxNumberOfObjectsReturnedFromLookupActivity | In order to avoid reaching the limit of output lookup activity, there is a way to define the max number of objects returned by lookup activity. In most case, the default value is not required to be changed. |
| TopLevelPipelineName | The name of top layer pipeline. |
| TriggerName | The name of trigger. |
| CurrentSequentialNumberOfBatch | The ID of sequential batch. |
| SumOfObjectsToCopy | The total number of objects to copy. |
| SumOfObjectsToCopyForCurrentBatch | The number of objects to copy in current batch. |
| MainControlTableName | The name of main control table. |
| ConnectionControlTableName | The name of connection control table. |
Activities
| Activity name | Activity type | Description |
|---|---|---|
| DivideOneBatchIntoMultipleGroups | ForEach | Divide objects from single batch into multiple parallel groups to avoid reaching the output limit of lookup activity. |
| GetObjectsPerGroupToCopy | Lookup | Get objects (tables etc.) from control table required to be copied in this group. The order of objects to be copied following the TaskId in control table (ORDER BY [TaskId] DESC). |
| CopyObjectsInOneGroup | Execute Pipeline | Execute another pipeline to copy objects from one group. The objects belonging to this group will be copied in parallel. |
MetadataDrivenCopyTask_xxx_ BottomLevel
This pipeline will copy objects from one group. The objects belonging to this group will be copied in parallel.
Parameters
| Parameters name | Description |
|---|---|
| ObjectsPerGroupToCopy | The number of objects to copy in current group. |
| ConnectionControlTableName | The name of connection control table. |
| windowStart | It used to pass the current trigger time to pipeline in order to fill the dynamic folder path if configured by user. |
Activities
| Activity name | Activity type | Description |
|---|---|---|
| ListObjectsFromOneGroup | ForEach | List objects from one group and iterate each of them to downstream activities. |
| RouteJobsBasedOnLoadingBehavior | Switch | Check the loading behavior for each object. If it is default or FullLoad case, do full load. If it is DeltaLoad case, do incremental load via watermark column to identify changes |
| FullLoadOneObject | Copy | Take a full snapshot on this object and copy it to the destination. |
| DeltaLoadOneObject | Copy | Copy the changed data only from last time via comparing the value in watermark column to identify changes. |
| GetMaxWatermarkValue | Lookup | Query the source object to get the max value from watermark column. |
| UpdateWatermarkColumnValue | StoreProcedure | Write back the new watermark value to control table to be used next time. |
Known limitations
- IR name, database type, file format type cannot be parameterized in ADF. For example, if you want to ingest data from both Oracle Server and SQL Server, you will need two different parameterized pipelines. But the single control table can be shared by two sets of pipelines.
- OPENJSON is used in generated SQL scripts by copy data tool. If you are using SQL Server to host control table, it must be SQL Server 2016 (13.x) and later in order to support OPENJSON function.
Related content
Try these tutorials that use the Copy Data tool: