Manifest-based ingestion concepts
Manifest-based file ingestion provides end-users and systems a robust mechanism for loading metadata about datasets in Azure Data Manager for Energy instance. This metadata is indexed by the system and allows the end-user to search the datasets.
Manifest-based file ingestion is an opaque ingestion that do not parse or understand the file contents. It creates a metadata record based on the manifest and makes the record searchable.
What is a Manifest?
A manifest is a JSON document that has a pre-determined structure for capturing entities defined as 'kind', that is, registered as schemas with the Schema service - Well-known Schema (WKS) definitions.
You can find an example manifest json document here.
The manifest schema has containers for the following OSDU® Group types:
- ReferenceData (zero or more) - A set of permissible values to be used by other (master or transaction) data fields. Examples include Unit of Measure (feet), Currency, etc.
- MasterData (zero or more) - A single source of basic business data used across multiple systems, applications, and/or process. Examples include Wells and Wellbores
- WorkProduct (WP) (one - must be present if loading WorkProductComponents) - A session boundary or collection (project, study) encompasses a set of entities that need to be processed together. As an example, you can take the ingestion of one or more log collections.
- WorkProductComponents (WPC) (zero or more - must be present if loading datasets) - A typed, smallest, independently usable unit of business data content transferred as part of a Work Product (a collection of things ingested together). Each Work Product Component (WPC) typically uses reference data, belongs to some master data, and maintains a reference to datasets. Example: Well Logs, Faults, Documents
- Datasets (zero or more - must be present if loading WorkProduct and WorkProductComponent records) - Each Work Product Component (WPC) consists of one or more data containers known as datasets.
The Manifest data is loaded in a particular sequence:
- The 'ReferenceData' array (if populated).
- The 'MasterData' array (if populated).
- The 'Data' structure is processed last (if populated). Inside the 'Data' property, processing is done in the following order:
- the 'Datasets' array
- the 'WorkProductComponents' array
- the 'WorkProduct'.
Any arrays are ordered. should there be interdependencies, the dependent items must be placed behind their relationship targets, for example, a master-data Well record must be placed in the 'MasterData' array before its Wellbores.
Manifest-based file ingestion workflow
Azure Data Manager for Energy instance has out-of-the-box support for Manifest-based file ingestion workflow. Osdu_ingest Airflow DAG is pre-configured in your instance.
Manifest-based file ingestion workflow components
The Manifest-based file ingestion workflow consists of the following components:
- Workflow Service - A wrapper service running on top of the Airflow workflow engine.
- Airflow engine - A workflow orchestration engine that executes workflows registered as DAGs (Directed Acyclic Graphs). Airflow is the chosen workflow engine by the OSDU® community to orchestrate and run ingestion workflows. Airflow isn't directly exposed, instead its features are accessed through the workflow service.
- Storage Service - A service that is used to save the manifest metadata records into the data platform.
- Schema Service - A service that manages OSDU® defined schemas in the data platform. Schemas are being referenced during the Manifest-based file ingestion.
- Entitlements Service - A service that manages access groups. This service is used during the ingestion for verification of ingestion permissions. This service is also used during the metadata record retrieval for validation of "read" writes.
- Legal Service - A service that validates compliance through legal tags.
- Search Service is used to perform referential integrity check during the manifest ingestion process.
Pre-requisites
Before running the Manifest-based file ingestion workflow, customers must ensure that the user accounts running the workflow have access to the core services (Search, Storage, Schema, Entitlement and Legal) and Workflow service (see Entitlement roles for details). As part of Azure Data Manager for Energy instance provisioning, the OSDU® standard schemas and associated reference data are pre-loaded. Customers must ensure that the user account used for ingesting the manifests is included in appropriate owners and viewers ACLs. Customers must ensure that manifests are configured with correct legal tags, owners and viewers ACLs, reference data, etc.
Workflow sequence
The following illustration provides the Manifest-based file ingestion workflow:
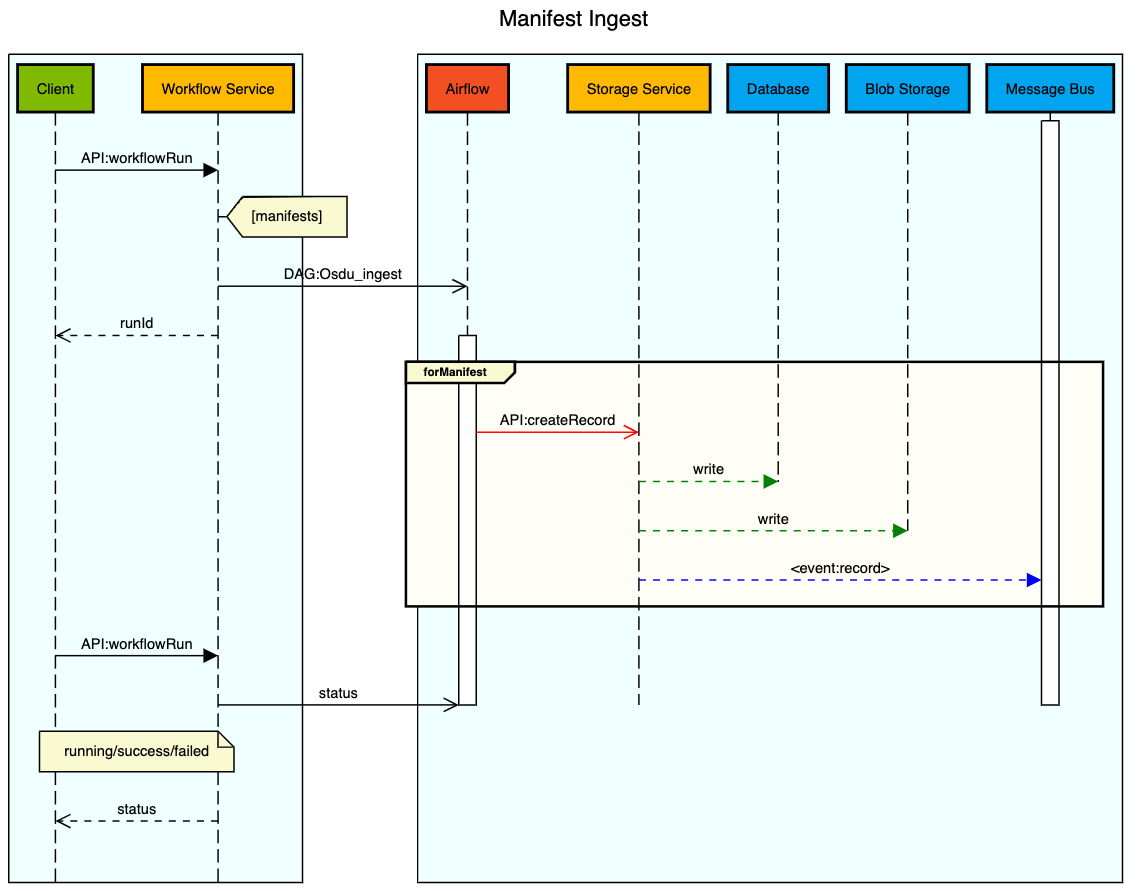
A user submits a manifest to the Workflow Service using the manifest ingestion workflow name ("Osdu_ingest"). If the request is proper and the user is authorized to run the workflow, the workflow service loads the manifest and initiates the manifest ingestion workflow.
The workflow service executes a series of manifest syntax validation like manifest structure and attribute validation as per the defined schema and check for mandatory schema attributes. The system then perform referential integrity validation between Work Product Components and Datasets. For example, whether the referenced parent data exists.
Once the validations are successful, the system processes the content into storage by writing each valid entity into the data platform using the Storage Service API.
OSDU® is a trademark of The Open Group.