Kernels for Jupyter Notebook on Apache Spark clusters in Azure HDInsight
HDInsight Spark clusters provide kernels that you can use with the Jupyter Notebook on Apache Spark for testing your applications. A kernel is a program that runs and interprets your code. The three kernels are:
- PySpark - for applications written in Python2. (Applicable only for Spark 2.4 version clusters)
- PySpark3 - for applications written in Python3.
- Spark - for applications written in Scala.
In this article, you learn how to use these kernels and the benefits of using them.
Prerequisites
An Apache Spark cluster in HDInsight. For instructions, see Create Apache Spark clusters in Azure HDInsight.
Create a Jupyter Notebook on Spark HDInsight
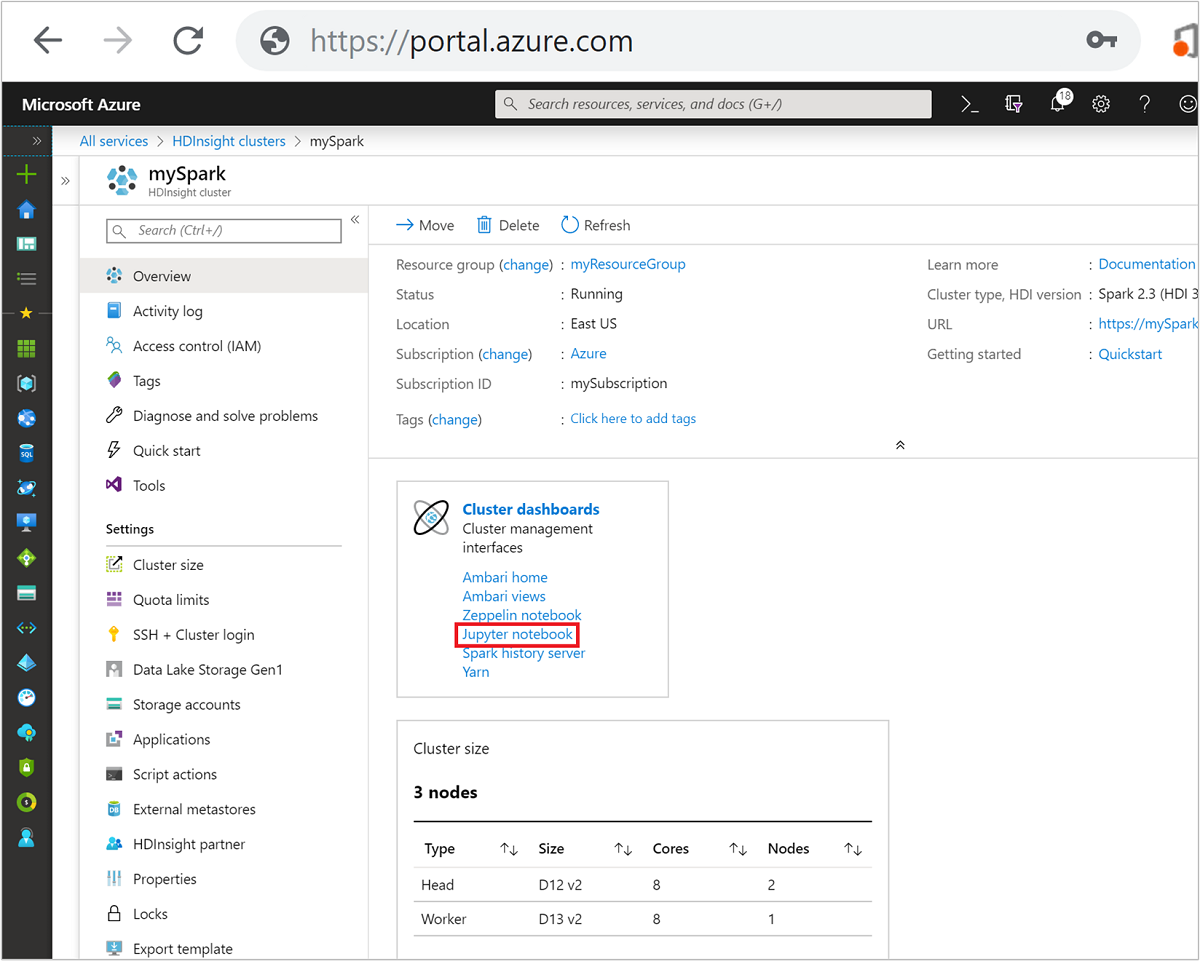
From the Azure portal, select your Spark cluster. See List and show clusters for the instructions. The Overview view opens.
From the Overview view, in the Cluster dashboards box, select Jupyter Notebook. If prompted, enter the admin credentials for the cluster.
Note
You may also reach the Jupyter Notebook on Spark cluster by opening the following URL in your browser. Replace CLUSTERNAME with the name of your cluster:
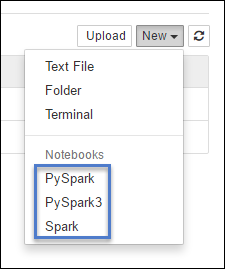
https://CLUSTERNAME.azurehdinsight.net/jupyterSelect New, and then select either Pyspark, PySpark3, or Spark to create a notebook. Use the Spark kernel for Scala applications, PySpark kernel for Python2 applications, and PySpark3 kernel for Python3 applications.
Note
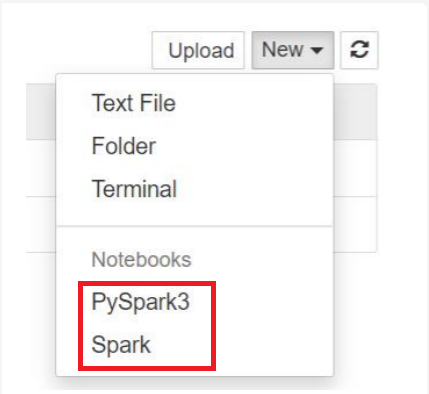
For Spark 3.1, only PySpark3, or Spark will be available.
- A notebook opens with the kernel you selected.
Benefits of using the kernels
Here are a few benefits of using the new kernels with Jupyter Notebook on Spark HDInsight clusters.
Preset contexts. With PySpark, PySpark3, or the Spark kernels, you don't need to set the Spark or Hive contexts explicitly before you start working with your applications. These contexts are available by default. These contexts are:
sc - for Spark context
sqlContext - for Hive context
So, you don't have to run statements like the following to set the contexts:
sc = SparkContext('yarn-client') sqlContext = HiveContext(sc)Instead, you can directly use the preset contexts in your application.
Cell magics. The PySpark kernel provides some predefined "magics", which are special commands that you can call with
%%(for example,%%MAGIC<args>). The magic command must be the first word in a code cell and allow for multiple lines of content. The magic word should be the first word in the cell. Adding anything before the magic, even comments, causes an error. For more information on magics, see here.The following table lists the different magics available through the kernels.
Magic Example Description help %%helpGenerates a table of all the available magics with example and description info %%infoOutputs session information for the current Livy endpoint configure %%configure -f{"executorMemory": "1000M","executorCores": 4}Configures the parameters for creating a session. The force flag ( -f) is mandatory if a session has already been created, which ensures that the session is dropped and recreated. Look at Livy's POST /sessions Request Body for a list of valid parameters. Parameters must be passed in as a JSON string and must be on the next line after the magic, as shown in the example column.sql %%sql -o <variable name>
SHOW TABLESExecutes a Hive query against the sqlContext. If the -oparameter is passed, the result of the query is persisted in the %%local Python context as a Pandas dataframe.local %%locala=1All the code in later lines is executed locally. Code must be valid Python2 code no matter which kernel you're using. So, even if you selected PySpark3 or Spark kernels while creating the notebook, if you use the %%localmagic in a cell, that cell must only have valid Python2 code.logs %%logsOutputs the logs for the current Livy session. delete %%delete -f -s <session number>Deletes a specific session of the current Livy endpoint. You can't delete the session that is started for the kernel itself. cleanup %%cleanup -fDeletes all the sessions for the current Livy endpoint, including this notebook's session. The force flag -f is mandatory. Note
In addition to the magics added by the PySpark kernel, you can also use the built-in IPython magics, including
%%sh. You can use the%%shmagic to run scripts and block of code on the cluster headnode.Auto visualization. The Pyspark kernel automatically visualizes the output of Hive and SQL queries. You can choose between several different types of visualizations including Table, Pie, Line, Area, Bar.
Parameters supported with the %%sql magic
The %%sql magic supports different parameters that you can use to control the kind of output that you receive when you run queries. The following table lists the output.
| Parameter | Example | Description |
|---|---|---|
| -o | -o <VARIABLE NAME> |
Use this parameter to persist the result of the query, in the %%local Python context, as a Pandas dataframe. The name of the dataframe variable is the variable name you specify. |
| -q | -q |
Use this parameter to turn off visualizations for the cell. If you don't want to autovisualize the content of a cell and just want to capture it as a dataframe, then use -q -o <VARIABLE>. If you want to turn off visualizations without capturing the results (for example, for running a SQL query, like a CREATE TABLE statement), use -q without specifying a -o argument. |
| -m | -m <METHOD> |
Where METHOD is either take or sample (default is take). If the method is take, the kernel picks elements from the top of the result data set specified by MAXROWS (described later in this table). If the method is sample, the kernel randomly samples elements of the data set according to -r parameter, described next in this table. |
| -r | -r <FRACTION> |
Here FRACTION is a floating-point number between 0.0 and 1.0. If the sample method for the SQL query is sample, then the kernel randomly samples the specified fraction of the elements of the result set for you. For example, if you run a SQL query with the arguments -m sample -r 0.01, then 1% of the result rows are randomly sampled. |
| -n | -n <MAXROWS> |
MAXROWS is an integer value. The kernel limits the number of output rows to MAXROWS. If MAXROWS is a negative number such as -1, then the number of rows in the result set isn't limited. |
Example:
%%sql -q -m sample -r 0.1 -n 500 -o query2
SELECT * FROM hivesampletable
The statement above does the following actions:
- Selects all records from hivesampletable.
- Because we use -q, it turns off autovisualization.
- Because we use
-m sample -r 0.1 -n 500, it randomly samples 10% of the rows in the hivesampletable and limits the size of the result set to 500 rows. - Finally, because we used
-o query2it also saves the output into a dataframe called query2.
Considerations while using the new kernels
Whichever kernel you use, leaving the notebooks running consumes the cluster resources. With these kernels, because the contexts are preset, simply exiting the notebooks doesn't kill the context. And so the cluster resources continue to be in use. A good practice is to use the Close and Halt option from the notebook's File menu when you're finished using the notebook. The closure kills the context and then exits the notebook.
Where are the notebooks stored?
If your cluster uses Azure Storage as the default storage account, Jupyter Notebooks are saved to storage account under the /HdiNotebooks folder. Notebooks, text files, and folders that you create from within Jupyter are accessible from the storage account. For example, if you use Jupyter to create a folder myfolder and a notebook myfolder/mynotebook.ipynb, you can access that notebook at /HdiNotebooks/myfolder/mynotebook.ipynb within the storage account. The reverse is also true, that is, if you upload a notebook directly to your storage account at /HdiNotebooks/mynotebook1.ipynb, the notebook is visible from Jupyter as well. Notebooks remain in the storage account even after the cluster is deleted.
Note
HDInsight clusters with Azure Data Lake Storage as the default storage do not store notebooks in associated storage.
The way notebooks are saved to the storage account is compatible with Apache Hadoop HDFS. If you SSH into the cluster you can use the file management commands:
| Command | Description |
|---|---|
hdfs dfs -ls /HdiNotebooks |
# List everything at the root directory – everything in this directory is visible to Jupyter from the home page |
hdfs dfs –copyToLocal /HdiNotebooks |
# Download the contents of the HdiNotebooks folder |
hdfs dfs –copyFromLocal example.ipynb /HdiNotebooks |
# Upload a notebook example.ipynb to the root folder so it's visible from Jupyter |
Whether the cluster uses Azure Storage or Azure Data Lake Storage as the default storage account, the notebooks are also saved on the cluster headnode at /var/lib/jupyter.
Supported browser
Jupyter Notebooks on Spark HDInsight clusters are supported only on Google Chrome.
Suggestions
The new kernels are in evolving stage and will mature over time. So the APIs could change as these kernels mature. We would appreciate any feedback that you have while using these new kernels. The feedback is useful in shaping the final release of these kernels. You can leave your comments/feedback under the Feedback section at the bottom of this article.