Deploy a model to an Azure Kubernetes Service cluster with v1
Important
This article explains how to use the Azure Machine Learning CLI (v1) and Azure Machine Learning SDK for Python (v1) to deploy a model. For the recommended approach for v2, see Deploy and score a machine learning model by using an online endpoint.
Learn how to use Azure Machine Learning to deploy a model as a web service on Azure Kubernetes Service (AKS). AKS is good for high-scale production deployments. Use AKS if you need one or more of the following capabilities:
- Fast response time
- Autoscaling of the deployed service
- Logging
- Model data collection
- Authentication
- TLS termination
- Hardware acceleration options such as GPU and field-programmable gate arrays (FPGA)
When deploying to AKS, you deploy to an AKS cluster that's connected to your workspace. For information on connecting an AKS cluster to your workspace, see Create and attach an Azure Kubernetes Service cluster.
Important
We recommend that you debug locally before deploying to the web service. For more information, see Troubleshooting with a local model deployment.
Note
Azure Machine Learning Endpoints (v2) provide an improved, simpler deployment experience. Endpoints support both real-time and batch inference scenarios. Endpoints provide a unified interface to invoke and manage model deployments across compute types. See What are Azure Machine Learning endpoints?.
Prerequisites
An Azure Machine Learning workspace. For more information, see Create an Azure Machine Learning workspace.
A machine learning model registered in your workspace. If you don't have a registered model, see Deploy machine learning models to Azure.
The Azure CLI extension (v1) for Machine Learning service, Azure Machine Learning Python SDK, or the Azure Machine Learning Visual Studio Code extension.
Important
Some of the Azure CLI commands in this article use the
azure-cli-ml, or v1, extension for Azure Machine Learning. Support for the v1 extension will end on September 30, 2025. You will be able to install and use the v1 extension until that date.We recommend that you transition to the
ml, or v2, extension before September 30, 2025. For more information on the v2 extension, see Azure ML CLI extension and Python SDK v2.The Python code snippets in this article assume that the following variables are set:
ws- Set to your workspace.model- Set to your registered model.inference_config- Set to the inference configuration for the model.
For more information on setting these variables, see How and where to deploy models.
The CLI snippets in this article assume that you already created an inferenceconfig.json document. For more information on creating this document, see Deploy machine learning models to Azure.
An AKS cluster connected to your workspace. For more information, see Create and attach an Azure Kubernetes Service cluster.
- If you want to deploy models to GPU nodes or FPGA nodes (or any specific product), then you must create a cluster with the specific product. There's no support for creating a secondary node pool in an existing cluster and deploying models in the secondary node pool.
Understand deployment processes
The word deployment is used in both Kubernetes and Azure Machine Learning. Deployment has different meanings in these two contexts. In Kubernetes, a deployment is a concrete entity, specified with a declarative YAML file. A Kubernetes deployment has a defined lifecycle and concrete relationships to other Kubernetes entities such as Pods and ReplicaSets. You can learn about Kubernetes from docs and videos at What is Kubernetes?.
In Azure Machine Learning, deployment is used in the more general sense of making available and cleaning up your project resources. The steps that Azure Machine Learning considers part of deployment are:
- Zipping the files in your project folder, ignoring those specified in .amlignore or .gitignore
- Scaling up your compute cluster (relates to Kubernetes)
- Building or downloading the dockerfile to the compute node (relates to Kubernetes)
- The system calculates a hash of:
- The base image
- Custom docker steps (see Deploy a model using a custom Docker base image)
- The conda definition YAML (see Create & use software environments in Azure Machine Learning)
- The system uses this hash as the key in a lookup of the workspace Azure Container Registry (ACR)
- If it's not found, it looks for a match in the global ACR
- If it's not found, the system builds a new image that's cached and pushed to the workspace ACR
- The system calculates a hash of:
- Downloading your zipped project file to temporary storage on the compute node
- Unzipping the project file
- The compute node executing
python <entry script> <arguments> - Saving logs, model files, and other files written to ./outputs to the storage account associated with the workspace
- Scaling down compute, including removing temporary storage (relates to Kubernetes)
Azure Machine Learning router
The front-end component (azureml-fe) that routes incoming inference requests to deployed services automatically scales as needed. Scaling of azureml-fe is based on the AKS cluster purpose and size (number of nodes). The cluster purpose and nodes are configured when you create or attach an AKS cluster. There's one azureml-fe service per cluster, which might be running on multiple pods.
Important
- When using a cluster configured as
dev-test, the self-scaler is disabled. Even for FastProd/DenseProd clusters, Self-Scaler is only enabled when telemetry shows that it's needed. - Azure Machine Learning doesn't automatically upload or store logs from any containers, including system containers. For comprehensive debugging, it's recommended that you enable Container Insights for your AKS cluster. This allows you to save, manage, and share container logs with the AML team when needed. Without this, AML can't guarantee support for issues related to azureml-fe.
- The maximum request payload is 100MB.
Azureml-fe scales both up (vertically) to use more cores, and out (horizontally) to use more pods. When making the decision to scale up, the time that it takes to route incoming inference requests is used. If this time exceeds the threshold, a scale-up occurs. If the time to route incoming requests continues to exceed the threshold, a scale-out occurs.
When scaling down and in, CPU usage is used. If the CPU usage threshold is met, the front end is first scaled down. If the CPU usage drops to the scale-in threshold, a scale-in operation happens. Scaling up and out only occurs if there are enough cluster resources available.
When scale-up or scale-down, azureml-fe pods are restarted to apply the cpu/memory changes. Restarts don't affect inferencing requests.
Understand connectivity requirements for AKS inferencing cluster
When Azure Machine Learning creates or attaches an AKS cluster, the AKS cluster is deployed with one of the following two network models:
- Kubenet networking: The network resources are typically created and configured as the AKS cluster is deployed.
- Azure Container Networking Interface (CNI) networking: The AKS cluster is connected to an existing virtual network resource and configurations.
For Kubenet networking, the network is created and configured properly for Azure Machine Learning service. For the CNI networking, you need to understand the connectivity requirements and ensure DNS resolution and outbound connectivity for AKS inferencing. For example, you might be using a firewall to block network traffic.
The following diagram shows the connectivity requirements for AKS inferencing. Black arrows represent actual communication, and blue arrows represent the domain names. You might need to add entries for these hosts to your firewall or to your custom DNS server.
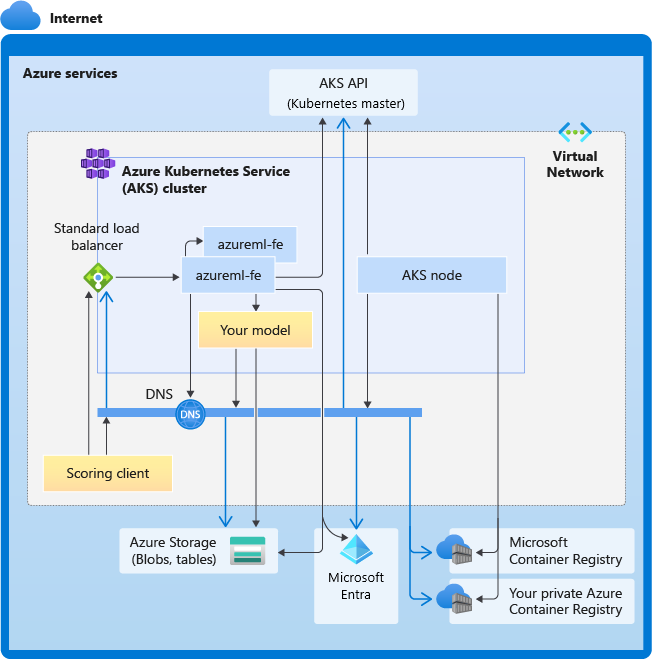
For general AKS connectivity requirements, see Limit network traffic with Azure Firewall in AKS.
For accessing Azure Machine Learning services behind a firewall, see Configure inbound and outbound network traffic.
Overall DNS resolution requirements
DNS resolution within an existing virtual network is under your control. For example, a firewall or custom DNS server. The following hosts must be reachable:
| Host name | Used by |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
AKS API server |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Your Azure Container Registry (ACR) |
<account>.table.core.windows.net |
Azure Storage Account (table storage) |
<account>.blob.core.windows.net |
Azure Storage Account (blob storage) |
api.azureml.ms |
Microsoft Entra authentication |
ingest-vienna<region>.kusto.windows.net |
Kusto endpoint for uploading telemetry |
<leaf-domain-label + auto-generated suffix>.<region>.cloudapp.azure.com |
Endpoint domain name, if you autogenerated with Azure Machine Learning. If you used a custom domain name, you don't need this entry. |
Connectivity requirements in chronological order
In the process of AKS create or attach, Azure Machine Learning router (azureml-fe) is deployed into the AKS cluster. In order to deploy Azure Machine Learning router, AKS node should be able to:
- Resolve DNS for AKS API server
- Resolve DNS for MCR in order to download docker images for Azure Machine Learning router
- Download images from MCR, where outbound connectivity is required
Right after azureml-fe is deployed, it attempts to start and this requires you to:
- Resolve DNS for AKS API server
- Query AKS API server to discover other instances of itself (it's a multi-pod service)
- Connect to other instances of itself
Once azureml-fe is started, it requires the following connectivity to function properly:
- Connect to Azure Storage to download dynamic configuration
- Resolve DNS for Microsoft Entra authentication server api.azureml.ms and communicate with it when the deployed service uses Microsoft Entra authentication.
- Query AKS API server to discover deployed models
- Communicate to deployed model PODs
At model deployment time, for a successful model deployment, AKS node should be able to:
- Resolve DNS for customer's ACR
- Download images from customer's ACR
- Resolve DNS for Azure BLOBs where model is stored
- Download models from Azure BLOBs
After the model is deployed and service starts, azureml-fe automatically discovers it using AKS API, and is ready to route request to it. It must be able to communicate to model PODs.
Note
If the deployed model requires any connectivity (for example, querying external database or other REST service, or downloading a BLOB), then both DNS resolution and outbound communication for these services should be enabled.
Deploy to AKS
To deploy a model to AKS, create a deployment configuration that describes the compute resources needed. For example, the number of cores and memory. You also need an inference configuration, which describes the environment needed to host the model and web service. For more information on creating the inference configuration, see How and where to deploy models.
Note
The number of models to be deployed is limited to 1,000 models per deployment (per container).
APPLIES TO:  Python SDK azureml v1
Python SDK azureml v1
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute import AksCompute
aks_target = AksCompute(ws,"myaks")
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and AML components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
For more information on the classes, methods, and parameters used in this example, see the following reference documents:
Autoscaling
APPLIES TO:
Python SDK azureml v1
The component that handles autoscaling for Azure Machine Learning model deployments is azureml-fe, which is a smart request router. Since all inference requests go through it, it has the necessary data to automatically scale the deployed models.
Important
Don't enable Kubernetes Horizontal Pod Autoscaler (HPA) for model deployments. Doing so causes the two auto-scaling components to compete with each other. Azureml-fe is designed to auto-scale models deployed by Azure Machine Learning, where HPA would have to guess or approximate model utilization from a generic metric like CPU usage or a custom metric configuration.
Azureml-fe does not scale the number of nodes in an AKS cluster, because this could lead to unexpected cost increases. Instead, it scales the number of replicas for the model within the physical cluster boundaries. If you need to scale the number of nodes within the cluster, you can manually scale the cluster or configure the AKS cluster autoscaler.
Autoscaling can be controlled by setting autoscale_target_utilization, autoscale_min_replicas, and autoscale_max_replicas for the AKS web service. The following example demonstrates how to enable autoscaling:
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
autoscale_target_utilization=30,
autoscale_min_replicas=1,
autoscale_max_replicas=4)
Decisions to scale up or down is based on utilization of the current container replicas. The number of replicas that are busy (processing a request) divided by the total number of current replicas is the current utilization. If this number exceeds autoscale_target_utilization, then more replicas are created. If it's lower, then replicas are reduced. By default, the target utilization is 70%.
Decisions to add replicas are eager and fast (around 1 second). Decisions to remove replicas are conservative (around 1 minute).
You can calculate the required replicas by using the following code:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
For more information on setting autoscale_target_utilization, autoscale_max_replicas, and autoscale_min_replicas, see the AksWebservice module reference.
Web service authentication
When deploying to Azure Kubernetes Service, key-based authentication is enabled by default. You can also enable token-based authentication. Token-based authentication requires clients to use a Microsoft Entra account to request an authentication token, which is used to make requests to the deployed service.
To disable authentication, set the auth_enabled=False parameter when creating the deployment configuration. The following example disables authentication using the SDK:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, auth_enabled=False)
For information on authenticating from a client application, see the Consume an Azure Machine Learning model deployed as a web service.
Authentication with keys
If key authentication is enabled, you can use the get_keys method to retrieve a primary and secondary authentication key:
primary, secondary = service.get_keys()
print(primary)
Important
If you need to regenerate a key, use service.regen_key.
Authentication with tokens
To enable token authentication, set the token_auth_enabled=True parameter when you're creating or updating a deployment. The following example enables token authentication using the SDK:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, token_auth_enabled=True)
If token authentication is enabled, you can use the get_token method to retrieve a JWT token and that token's expiration time:
token, refresh_by = service.get_token()
print(token)
Important
You need to request a new token after the token's refresh_by time.
Microsoft strongly recommends that you create your Azure Machine Learning workspace in the same region as your AKS cluster. To authenticate with a token, the web service makes a call to the region in which your Azure Machine Learning workspace is created. If your workspace's region is unavailable, then you can't to fetch a token for your web service even, if your cluster is in a different region than your workspace. This effectively results in token-based authentication being unavailable until your workspace's region is available again. In addition, the greater the distance between your cluster's region and your workspace's region, the longer it takes to fetch a token.
To retrieve a token, you must use the Azure Machine Learning SDK or the az ml service get-access-token command.
Vulnerability scanning
Microsoft Defender for Cloud provides unified security management and advanced threat protection across hybrid cloud workloads. You should allow Microsoft Defender for Cloud to scan your resources and follow its recommendations. For more, see Container security in Microsoft Defender for containers.
Related content
- Use Azure role-based access control for Kubernetes authorization
- Secure an Azure Machine Learning inferencing environment with virtual networks
- Use a custom container to deploy a model to an online endpoint
- Troubleshooting remote model deployment
- Update a deployed web service
- Use TLS to secure a web service through Azure Machine Learning
- Consume an Azure Machine Learning model deployed as a web service
- Monitor and collect data from ML web service endpoints
- Collect data from models in production
Σχόλια
Σύντομα διαθέσιμα: Καθ' όλη τη διάρκεια του 2024 θα καταργήσουμε σταδιακά τα ζητήματα GitHub ως μηχανισμό ανάδρασης για το περιεχόμενο και θα το αντικαταστήσουμε με ένα νέο σύστημα ανάδρασης. Για περισσότερες πληροφορίες, ανατρέξτε στο θέμα: https://aka.ms/ContentUserFeedback.
Υποβολή και προβολή σχολίων για