Run batch predictions using Azure Machine Learning designer
In this article, you learn how to use the designer to create a batch prediction pipeline. Batch prediction lets you continuously score large datasets on-demand using a web service that can be triggered from any HTTP library.
In this how-to, you learn to do the following tasks:
- Create and publish a batch inference pipeline
- Consume a pipeline endpoint
- Manage endpoint versions
To learn how to set up batch scoring services using the SDK, see the accompanying tutorial on pipeline batch scoring.
Prerequisites
This how-to assumes you already have a training pipeline. For a guided introduction to the designer, complete part one of the designer tutorial.
Important
If you do not see graphical elements mentioned in this document, such as buttons in studio or designer, you may not have the right level of permissions to the workspace. Please contact your Azure subscription administrator to verify that you have been granted the correct level of access. For more information, see Manage users and roles.
Create a batch inference pipeline
Your training pipeline must be run at least once to be able to create an inferencing pipeline.
Go to the Designer tab in your workspace.
Select the training pipeline that trains the model you want to use to make prediction.
Submit the pipeline.

You'll see a submission list on the left of canvas. You can select the job detail link to go to the job detail page, and after the training pipeline job completes, you can create a batch inference pipeline.

In job detail page, above the canvas, select the dropdown Create inference pipeline. Select Batch inference pipeline.
Note
Currently auto-generating inference pipeline only works for training pipeline built purely by the designer built-in components.

It will create a batch inference pipeline draft for you. The batch inference pipeline draft uses the trained model as MD- node and transformation as TD- node from the training pipeline job.
You can also modify this inference pipeline draft to better handle your input data for batch inference.



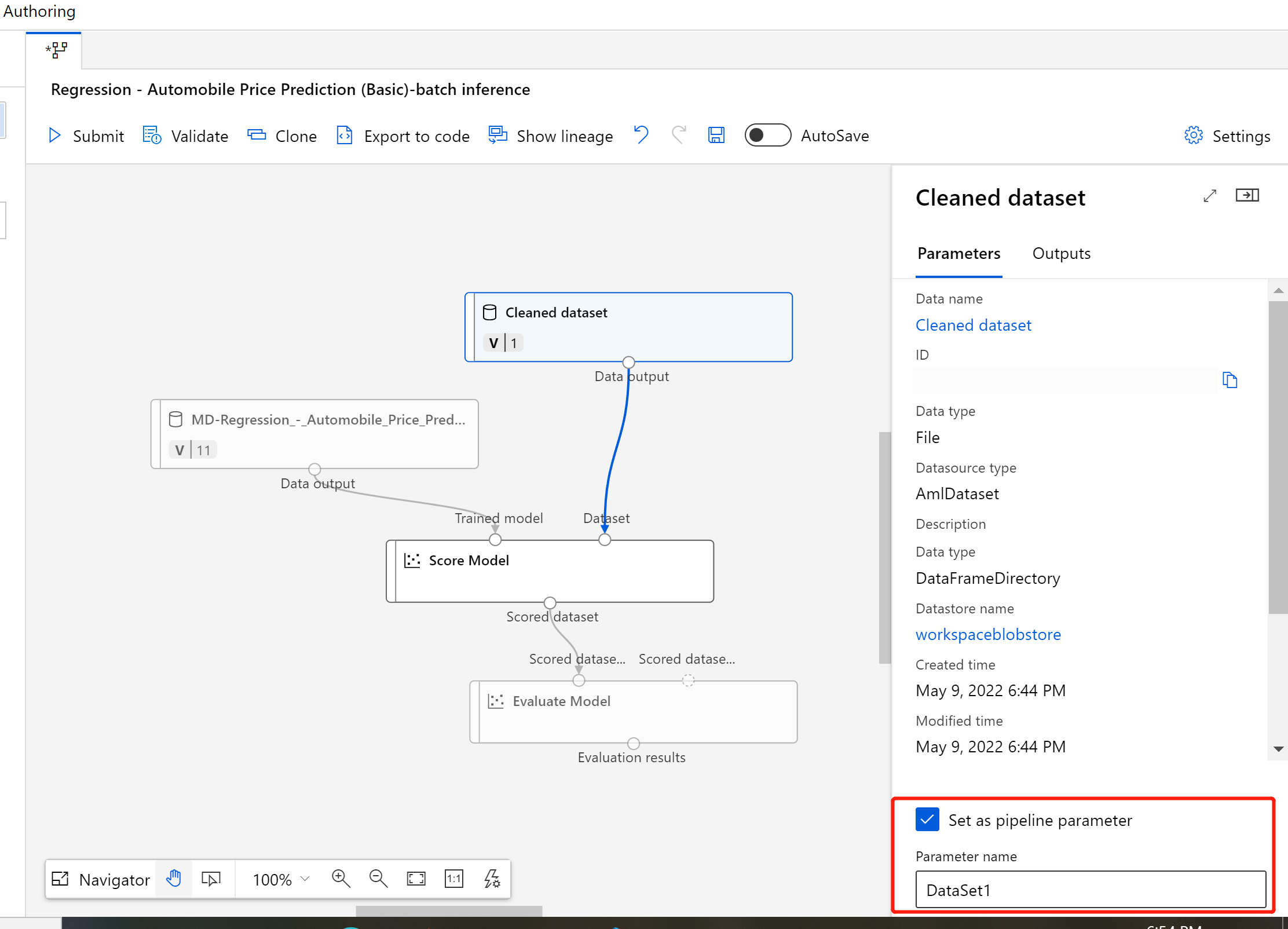
Add a pipeline parameter
To create predictions on new data, you can either manually connect a different dataset in this pipeline draft view or create a parameter for your dataset. Parameters let you change the behavior of the batch inferencing process at runtime.
In this section, you create a dataset parameter to specify a different dataset to make predictions on.
Select the dataset component.
A pane will appear to the right of the canvas. At the bottom of the pane, select Set as pipeline parameter.
Enter a name for the parameter, or accept the default value.
Submit the batch inference pipeline and go to job detail page by selecting the job link in the left pane.

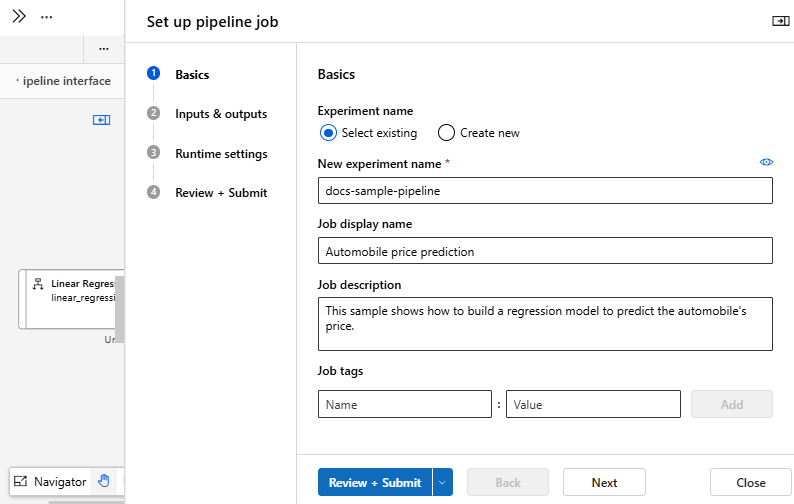
Publish your batch inference pipeline
Now you're ready to deploy the inference pipeline. This will deploy the pipeline and make it available for others to use.
Select the Publish button.
In the dialog that appears, expand the drop-down for PipelineEndpoint, and select New PipelineEndpoint.
Provide an endpoint name and optional description.
Near the bottom of the dialog, you can see the parameter you configured with a default value of the dataset ID used during training.
Select Publish.

Consume an endpoint
Now, you have a published pipeline with a dataset parameter. The pipeline will use the trained model created in the training pipeline to score the dataset you provide as a parameter.
Submit a pipeline job
In this section, you'll set up a manual pipeline job and alter the pipeline parameter to score new data.
After the deployment is complete, go to the Endpoints section.
Select Pipeline endpoints.
Select the name of the endpoint you created.

Select Published pipelines.
This screen shows all published pipelines published under this endpoint.
Select the pipeline you published.
The pipeline details page shows you a detailed job history and connection string information for your pipeline.
Select Submit to create a manual run of the pipeline.

Change the parameter to use a different dataset.
Select Submit to run the pipeline.

Use the REST endpoint
You can find information on how to consume pipeline endpoints and published pipeline in the Endpoints section.
You can find the REST endpoint of a pipeline endpoint in the job overview panel. By calling the endpoint, you're consuming its default published pipeline.
You can also consume a published pipeline in the Published pipelines page. Select a published pipeline and you can find the REST endpoint of it in the Published pipeline overview panel to the right of the graph.
To make a REST call, you'll need an OAuth 2.0 bearer-type authentication header. See the following tutorial section for more detail on setting up authentication to your workspace and making a parameterized REST call.
Versioning endpoints
The designer assigns a version to each subsequent pipeline that you publish to an endpoint. You can specify the pipeline version that you want to execute as a parameter in your REST call. If you don't specify a version number, the designer will use the default pipeline.
When you publish a pipeline, you can choose to make it the new default pipeline for that endpoint.

You can also set a new default pipeline in the Published pipelines tab of your endpoint.

Update pipeline endpoint
If you make some modifications in your training pipeline, you might want to update the newly trained model to the pipeline endpoint.
After your modified training pipeline completes successfully, go to the job detail page.
Right click Train Model component and select Register data

Input name and select File type.

Find the previous batch inference pipeline draft, or you can just Clone the published pipeline into a new draft.
Replace the MD- node in the inference pipeline draft with the registered data in the step above.

Updating data transformation node TD- is the same as the trained model.
Then you can submit the inference pipeline with the updated model and transformation, and publish again.


Next steps
- Follow the designer tutorial to train and deploy a regression model.
- For how to publish and run a published pipeline using the SDK v1, see the How to deploy pipelines article.