Using Tiles
You can use tiling to maximize the acceleration of your app. Tiling divides threads into equal rectangular subsets or tiles. If you use an appropriate tile size and tiled algorithm, you can get even more acceleration from your C++ AMP code. The basic components of tiling are:
tile_staticvariables. The primary benefit of tiling is the performance gain fromtile_staticaccess. Access to data intile_staticmemory can be significantly faster than access to data in the global space (arrayorarray_viewobjects). An instance of atile_staticvariable is created for each tile, and all threads in the tile have access to the variable. In a typical tiled algorithm, data is copied intotile_staticmemory once from global memory and then accessed many times from thetile_staticmemory.tile_barrier::wait Method. A call to
tile_barrier::waitsuspends execution of the current thread until all of the threads in the same tile reach the call totile_barrier::wait. You cannot guarantee the order that the threads will run in, only that no threads in the tile will execute past the call totile_barrier::waituntil all of the threads have reached the call. This means that by using thetile_barrier::waitmethod, you can perform tasks on a tile-by-tile basis rather than a thread-by-thread basis. A typical tiling algorithm has code to initialize thetile_staticmemory for the whole tile followed by a call totile_barrier::wait. Code that followstile_barrier::waitcontains computations that require access to all thetile_staticvalues.Local and global indexing. You have access to the index of the thread relative to the entire
array_vieworarrayobject and the index relative to the tile. Using the local index can make your code easier to read and debug. Typically, you use local indexing to accesstile_staticvariables, and global indexing to accessarrayandarray_viewvariables.tiled_extent Class and tiled_index Class. You use a
tiled_extentobject instead of anextentobject in theparallel_for_eachcall. You use atiled_indexobject instead of anindexobject in theparallel_for_eachcall.
To take advantage of tiling, your algorithm must partition the compute domain into tiles and then copy the tile data into tile_static variables for faster access.
Example of Global, Tile, and Local Indices
Note
C++ AMP headers are deprecated starting with Visual Studio 2022 version 17.0.
Including any AMP headers will generate build errors. Define _SILENCE_AMP_DEPRECATION_WARNINGS before including any AMP headers to silence the warnings.
The following diagram represents an 8x9 matrix of data that is arranged in 2x3 tiles.
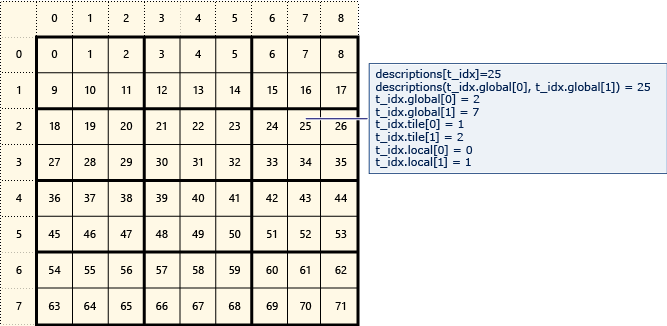
The following example displays the global, tile, and local indices of this tiled matrix. An array_view object is created by using elements of type Description. The Description holds the global, tile, and local indices of the element in the matrix. The code in the call to parallel_for_each sets the values of the global, tile, and local indices of each element. The output displays the values in the Description structures.
#include <iostream>
#include <iomanip>
#include <Windows.h>
#include <amp.h>
using namespace concurrency;
const int ROWS = 8;
const int COLS = 9;
// tileRow and tileColumn specify the tile that each thread is in.
// globalRow and globalColumn specify the location of the thread in the array_view.
// localRow and localColumn specify the location of the thread relative to the tile.
struct Description {
int value;
int tileRow;
int tileColumn;
int globalRow;
int globalColumn;
int localRow;
int localColumn;
};
// A helper function for formatting the output.
void SetConsoleColor(int color) {
int colorValue = (color == 0) 4 : 2;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), colorValue);
}
// A helper function for formatting the output.
void SetConsoleSize(int height, int width) {
COORD coord;
coord.X = width;
coord.Y = height;
SetConsoleScreenBufferSize(GetStdHandle(STD_OUTPUT_HANDLE), coord);
SMALL_RECT* rect = new SMALL_RECT();
rect->Left = 0;
rect->Top = 0;
rect->Right = width;
rect->Bottom = height;
SetConsoleWindowInfo(GetStdHandle(STD_OUTPUT_HANDLE), true, rect);
}
// This method creates an 8x9 matrix of Description structures.
// In the call to parallel_for_each, the structure is updated
// with tile, global, and local indices.
void TilingDescription() {
// Create 72 (8x9) Description structures.
std::vector<Description> descs;
for (int i = 0; i < ROWS * COLS; i++) {
Description d = {i, 0, 0, 0, 0, 0, 0};
descs.push_back(d);
}
// Create an array_view from the Description structures.
extent<2> matrix(ROWS, COLS);
array_view<Description, 2> descriptions(matrix, descs);
// Update each Description with the tile, global, and local indices.
parallel_for_each(descriptions.extent.tile< 2, 3>(),
[=] (tiled_index< 2, 3> t_idx) restrict(amp)
{
descriptions[t_idx].globalRow = t_idx.global[0];
descriptions[t_idx].globalColumn = t_idx.global[1];
descriptions[t_idx].tileRow = t_idx.tile[0];
descriptions[t_idx].tileColumn = t_idx.tile[1];
descriptions[t_idx].localRow = t_idx.local[0];
descriptions[t_idx].localColumn= t_idx.local[1];
});
// Print out the Description structure for each element in the matrix.
// Tiles are displayed in red and green to distinguish them from each other.
SetConsoleSize(100, 150);
for (int row = 0; row < ROWS; row++) {
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Value: " << std::setw(2) << descriptions(row, column).value << " ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Tile: " << "(" << descriptions(row, column).tileRow << "," << descriptions(row, column).tileColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Global: " << "(" << descriptions(row, column).globalRow << "," << descriptions(row, column).globalColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Local: " << "(" << descriptions(row, column).localRow << "," << descriptions(row, column).localColumn << ") ";
}
std::cout << "\n";
std::cout << "\n";
}
}
int main() {
TilingDescription();
char wait;
std::cin >> wait;
}
The main work of the example is in the definition of the array_view object and the call to parallel_for_each.
The vector of
Descriptionstructures is copied into an 8x9array_viewobject.The
parallel_for_eachmethod is called with atiled_extentobject as the compute domain. Thetiled_extentobject is created by calling theextent::tile()method of thedescriptionsvariable. The type parameters of the call toextent::tile(),<2,3>, specify that 2x3 tiles are created. Thus, the 8x9 matrix is tiled into 12 tiles, four rows and three columns.The
parallel_for_eachmethod is called by using atiled_index<2,3>object (t_idx) as the index. The type parameters of the index (t_idx) must match the type parameters of the compute domain (descriptions.extent.tile< 2, 3>()).When each thread is executed, the index
t_idxreturns information about which tile the thread is in (tiled_index::tileproperty) and the location of the thread within the tile (tiled_index::localproperty).
Tile Synchronization—tile_static and tile_barrier::wait
The previous example illustrates the tile layout and indices, but is not in itself very useful. Tiling becomes useful when the tiles are integral to the algorithm and exploit tile_static variables. Because all threads in a tile have access to tile_static variables, calls to tile_barrier::wait are used to synchronize access to the tile_static variables. Although all of the threads in a tile have access to the tile_static variables, there is no guaranteed order of execution of threads in the tile. The following example shows how to use tile_static variables and the tile_barrier::wait method to calculate the average value of each tile. Here are the keys to understanding the example:
The rawData is stored in an 8x8 matrix.
The tile size is 2x2. This creates a 4x4 grid of tiles and the averages can be stored in a 4x4 matrix by using an
arrayobject. There are only a limited number of types that you can capture by reference in an AMP-restricted function. Thearrayclass is one of them.The matrix size and sample size are defined by using
#definestatements, because the type parameters toarray,array_view,extent, andtiled_indexmust be constant values. You can also useconst int staticdeclarations. As an additional benefit, it is trivial to change the sample size to calculate the average over 4x4 tiles.A
tile_static2x2 array of float values is declared for each tile. Although the declaration is in the code path for every thread, only one array is created for each tile in the matrix.There is a line of code to copy the values in each tile to the
tile_staticarray. For each thread, after the value is copied to the array, execution on the thread stops due to the call totile_barrier::wait.When all of the threads in a tile have reached the barrier, the average can be calculated. Because the code executes for every thread, there is an
ifstatement to only calculate the average on one thread. The average is stored in the averages variable. The barrier is essentially the construct that controls calculations by tile, much as you might use aforloop.The data in the
averagesvariable, because it is anarrayobject, must be copied back to the host. This example uses the vector conversion operator.In the complete example, you can change SAMPLESIZE to 4 and the code executes correctly without any other changes.
#include <iostream>
#include <amp.h>
using namespace concurrency;
#define SAMPLESIZE 2
#define MATRIXSIZE 8
void SamplingExample() {
// Create data and array_view for the matrix.
std::vector<float> rawData;
for (int i = 0; i < MATRIXSIZE * MATRIXSIZE; i++) {
rawData.push_back((float)i);
}
extent<2> dataExtent(MATRIXSIZE, MATRIXSIZE);
array_view<float, 2> matrix(dataExtent, rawData);
// Create the array for the averages.
// There is one element in the output for each tile in the data.
std::vector<float> outputData;
int outputSize = MATRIXSIZE / SAMPLESIZE;
for (int j = 0; j < outputSize * outputSize; j++) {
outputData.push_back((float)0);
}
extent<2> outputExtent(MATRIXSIZE / SAMPLESIZE, MATRIXSIZE / SAMPLESIZE);
array<float, 2> averages(outputExtent, outputData.begin(), outputData.end());
// Use tiles that are SAMPLESIZE x SAMPLESIZE.
// Find the average of the values in each tile.
// The only reference-type variable you can pass into the parallel_for_each call
// is a concurrency::array.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before you calculate the average.
t_idx.barrier.wait();
// If you remove the if statement, then the calculation executes for every
// thread in the tile, and makes the same assignment to averages each time.
if (t_idx.local[0] == 0 && t_idx.local[1] == 0) {
for (int trow = 0; trow < SAMPLESIZE; trow++) {
for (int tcol = 0; tcol < SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE * SAMPLESIZE);
}
});
// Print out the results.
// You cannot access the values in averages directly. You must copy them
// back to a CPU variable.
outputData = averages;
for (int row = 0; row < outputSize; row++) {
for (int col = 0; col < outputSize; col++) {
std::cout << outputData[row*outputSize + col] << " ";
}
std::cout << "\n";
}
// Output for SAMPLESIZE = 2 is:
// 4.5 6.5 8.5 10.5
// 20.5 22.5 24.5 26.5
// 36.5 38.5 40.5 42.5
// 52.5 54.5 56.5 58.5
// Output for SAMPLESIZE = 4 is:
// 13.5 17.5
// 45.5 49.5
}
int main() {
SamplingExample();
}
Race Conditions
It might be tempting to create a tile_static variable named total and increment that variable for each thread, like this:
// Do not do this.
tile_static float total;
total += matrix[t_idx];
t_idx.barrier.wait();
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
The first problem with this approach is that tile_static variables cannot have initializers. The second problem is that there is a race condition on the assignment to total, because all of the threads in the tile have access to the variable in no particular order. You could program an algorithm to only allow one thread to access the total at each barrier, as shown next. However, this solution is not extensible.
// Do not do this.
tile_static float total;
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
total = matrix[t_idx];
}
t_idx.barrier.wait();
if (t_idx.local[0] == 0&& t_idx.local[1] == 1) {
total += matrix[t_idx];
}
t_idx.barrier.wait();
// etc.
Memory Fences
There are two kinds of memory accesses that must be synchronized—global memory access and tile_static memory access. A concurrency::array object allocates only global memory. A concurrency::array_view can reference global memory, tile_static memory, or both, depending on how it was constructed. There are two kinds of memory that must be synchronized:
global memory
tile_static
A memory fence ensures that memory accesses are available to other threads in the thread tile, and that memory accesses are executed according to program order. To ensure this, compilers and processors do not reorder reads and writes across the fence. In C++ AMP, a memory fence is created by a call to one of these methods:
tile_barrier::wait Method: Creates a fence around both global and
tile_staticmemory.tile_barrier::wait_with_all_memory_fence Method: Creates a fence around both global and
tile_staticmemory.tile_barrier::wait_with_global_memory_fence Method: Creates a fence around only global memory.
tile_barrier::wait_with_tile_static_memory_fence Method: Creates a fence around only
tile_staticmemory.
Calling the specific fence that you require can improve the performance of your app. The barrier type affects how the compiler and the hardware reorder statements. For example, if you use a global memory fence, it applies only to global memory accesses and therefore, the compiler and the hardware might reorder reads and writes to tile_static variables on the two sides of the fence.
In the next example, the barrier synchronizes the writes to tileValues, a tile_static variable. In this example, tile_barrier::wait_with_tile_static_memory_fence is called instead of tile_barrier::wait.
// Using a tile_static memory fence.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before calculating the average.
t_idx.barrier.wait_with_tile_static_memory_fence();
// If you remove the if statement, then the calculation executes
// for every thread in the tile, and makes the same assignment to
// averages each time.
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
for (int trow = 0; trow <SAMPLESIZE; trow++) {
for (int tcol = 0; tcol <SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
}
});
See also
C++ AMP (C++ Accelerated Massive Parallelism)
tile_static Keyword