Σημείωμα
Η πρόσβαση σε αυτήν τη σελίδα απαιτεί εξουσιοδότηση. Μπορείτε να δοκιμάσετε να εισέλθετε ή να αλλάξετε καταλόγους.
Η πρόσβαση σε αυτήν τη σελίδα απαιτεί εξουσιοδότηση. Μπορείτε να δοκιμάσετε να αλλάξετε καταλόγους.
Αυτή η εκμάθηση διαρκεί 15 λεπτά και περιγράφει τον τρόπο επαυξητικής συγκέντρωσης δεδομένων σε ένα lakehouse χρησιμοποιώντας το Dataflow Gen2.
Η επαυξητική συγκέντρωση δεδομένων σε έναν προορισμό δεδομένων απαιτεί μια τεχνική για τη φόρτωση μόνο νέων ή ενημερωμένων δεδομένων στον προορισμό δεδομένων σας. Αυτή η τεχνική μπορεί να γίνει χρησιμοποιώντας ένα ερώτημα για το φιλτράρισμα των δεδομένων με βάση τον προορισμό δεδομένων. Αυτή η εκμάθηση δείχνει πώς μπορείτε να δημιουργήσετε μια ροή δεδομένων για να φορτώσετε δεδομένα από μια προέλευση OData σε μια λίμνη και πώς να προσθέσετε ένα ερώτημα στη ροή δεδομένων για να φιλτράρετε τα δεδομένα με βάση τον προορισμό δεδομένων.
Τα βήματα υψηλού επιπέδου σε αυτή την εκμάθηση είναι τα εξής:
- Δημιουργήστε μια ροή δεδομένων για να φορτώσετε δεδομένα από μια προέλευση OData σε ένα lakehouse.
- Προσθέστε ένα ερώτημα στη ροή δεδομένων για να φιλτράρετε τα δεδομένα με βάση τον προορισμό δεδομένων.
- (Προαιρετικό) φορτώστε εκ νέου δεδομένα χρησιμοποιώντας σημειωματάρια και διοχετεύσεις.
Προαπαιτούμενα στοιχεία
Πρέπει να έχετε έναν χώρο εργασίας με δυνατότητα Microsoft Fabric. Εάν δεν έχετε ήδη έναν, ανατρέξτε στο θέμα Δημιουργία χώρου εργασίας. Επίσης, το εκπαιδευτικό βοήθημα προϋποθέτει ότι χρησιμοποιείτε την προβολή διαγράμματος στο Dataflow Gen2. Για να ελέγξετε εάν χρησιμοποιείτε την προβολή διαγράμματος, στην επάνω κορδέλα μεταβείτε στην Προβολή και βεβαιωθείτε προβολή διαγράμματος είναι επιλεγμένη.
Δημιουργία ροής δεδομένων για φόρτωση δεδομένων από μια προέλευση OData σε μια λίμνη
Σε αυτή την ενότητα, δημιουργείτε μια ροή δεδομένων για να φορτώσετε δεδομένα από μια προέλευση OData σε μια λίμνη.
Δημιουργήστε ένα νέο lakehouse στον χώρο εργασίας σας.
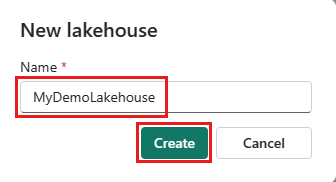
Δημιουργήστε μια νέα ροή δεδομένων Gen2 στον χώρο εργασίας σας.
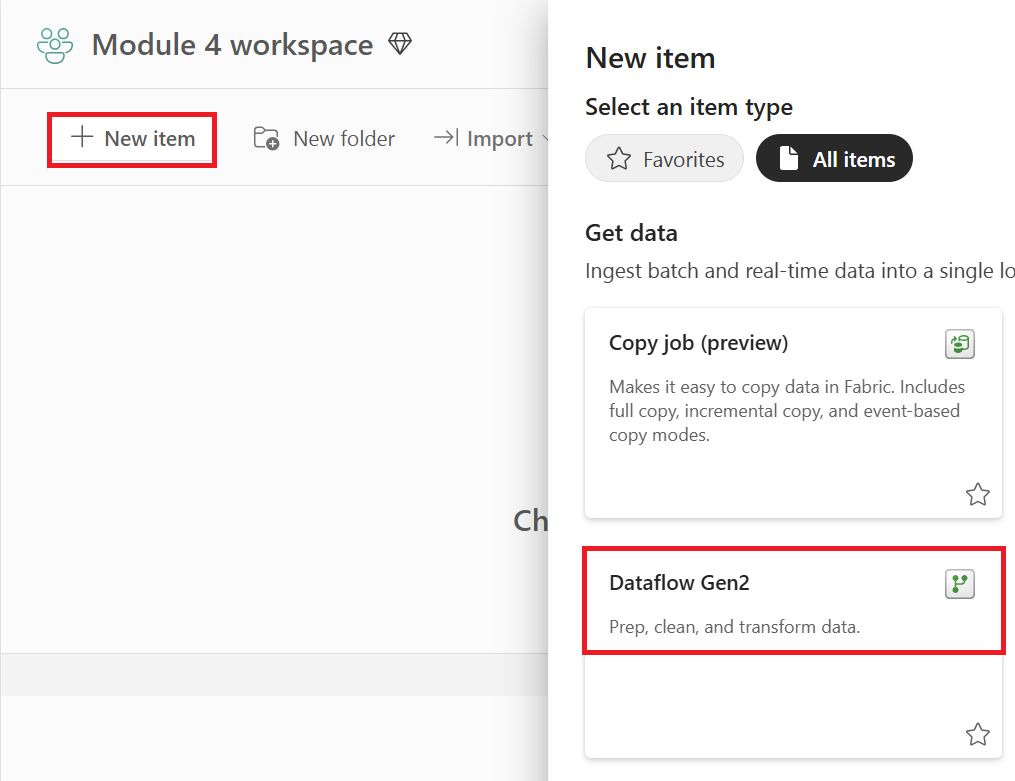
Προσθέστε μια νέα προέλευση στη ροή δεδομένων. Επιλέξτε την προέλευση OData και πληκτρολογήστε την ακόλουθη διεύθυνση URL:
https://services.OData.org/V4/Northwind/Northwind.svc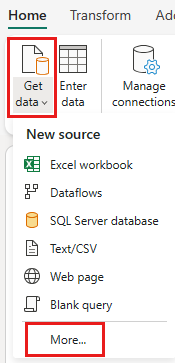
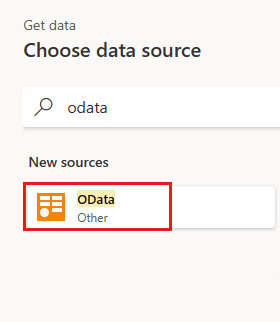
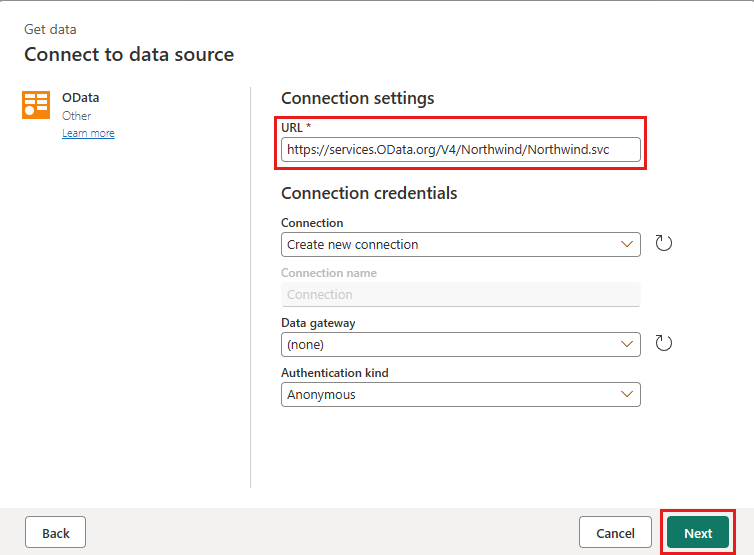
Επιλέξτε τον πίνακα Orders και επιλέξτε Next (Επόμενο).
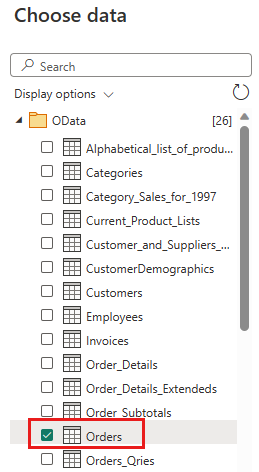
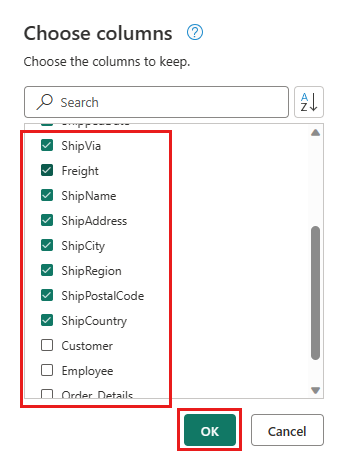
Επιλέξτε τις ακόλουθες στήλες για να τις διατηρήσετε:
OrderIDCustomerIDEmployeeIDOrderDateRequiredDateShippedDateShipViaFreightShipNameShipAddressShipCityShipRegionShipPostalCodeShipCountry
Αλλάξτε τον τύπο
OrderDateδεδομένων ,RequiredDateκαιShippedDateσεdatetime.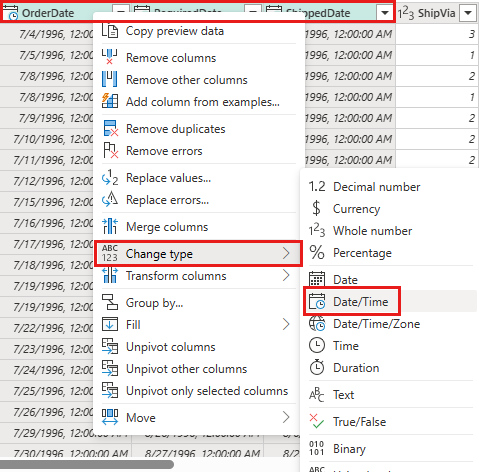
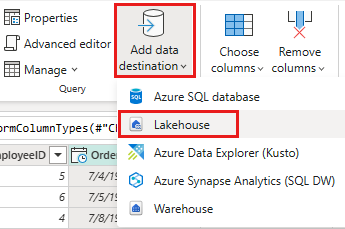
Ρυθμίστε τον προορισμό δεδομένων στο lakehouse σας χρησιμοποιώντας τις ακόλουθες ρυθμίσεις:
- Προορισμός δεδομένων:
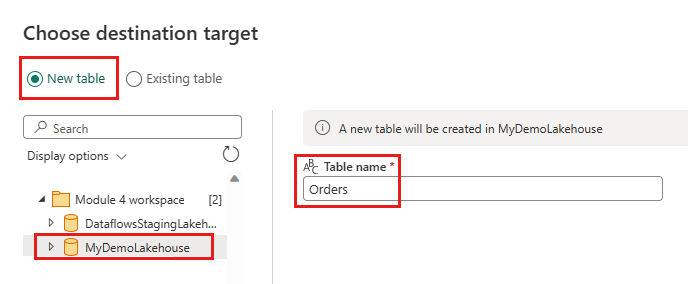
Lakehouse - Lakehouse: Επιλέξτε το lakehouse που δημιουργήσατε στο βήμα 1.
- Νέο όνομα πίνακα:
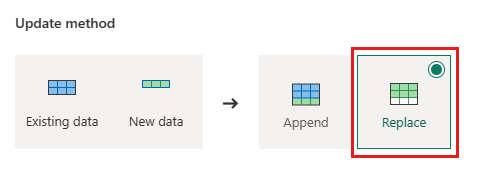
Orders - Μέθοδος ενημέρωσης:
Replace
- Προορισμός δεδομένων:
Επιλέξτε Επόμενο και δημοσιεύστε τη ροή δεδομένων.



Δημιουργήσατε τώρα μια ροή δεδομένων για να φορτώσετε δεδομένα από μια προέλευση OData σε μια λίμνη. Αυτή η ροή δεδομένων χρησιμοποιείται στην επόμενη ενότητα για να προσθέσετε ένα ερώτημα στη ροή δεδομένων για να φιλτράρετε τα δεδομένα με βάση τον προορισμό δεδομένων. Μετά από αυτό, μπορείτε να χρησιμοποιήσετε τη ροή δεδομένων για να φορτώσετε εκ νέου δεδομένα χρησιμοποιώντας σημειωματάρια και διοχετεύσεις.
Προσθέστε ένα ερώτημα στη ροή δεδομένων για να φιλτράρετε τα δεδομένα με βάση τον προορισμό δεδομένων
Αυτή η ενότητα προσθέτει ένα ερώτημα στη ροή δεδομένων για να φιλτράρει τα δεδομένα με βάση τα δεδομένα στο lakehouse προορισμού. Το ερώτημα λαμβάνει τη μέγιστη τιμή OrderID στο lakehouse στην αρχή της ανανέωσης ροής δεδομένων και χρησιμοποιεί το μέγιστο OrderId για να λάβει μόνο τις παραγγελίες με υψηλότερο OrderId από την προέλευση για προσάρτηση στον προορισμό δεδομένων σας. Αυτό προϋποθέτει ότι οι παραγγελίες προστίθενται στην προέλευση σε αύξουσα σειρά .OrderID Εάν δεν συμβαίνει αυτό, μπορείτε να χρησιμοποιήσετε διαφορετική στήλη για να φιλτράρετε τα δεδομένα. Για παράδειγμα, μπορείτε να χρησιμοποιήσετε τη OrderDate στήλη για να φιλτράρετε τα δεδομένα.
Σημείωμα
Τα φίλτρα OData εφαρμόζονται εντός του Fabric μετά τη λήψη των δεδομένων από την προέλευση δεδομένων, ωστόσο, για προελεύσεις βάσης δεδομένων όπως ο SQL Server, το φίλτρο εφαρμόζεται στο ερώτημα που υποβλήθηκε στην προέλευση δεδομένων παρασκηνίου και μόνο οι φιλτραρισμένες γραμμές επιστρέφονται στην υπηρεσία.
Μετά την ανανέωση της ροής δεδομένων, ανοίξτε ξανά τη ροή δεδομένων που δημιουργήσατε στην προηγούμενη ενότητα.
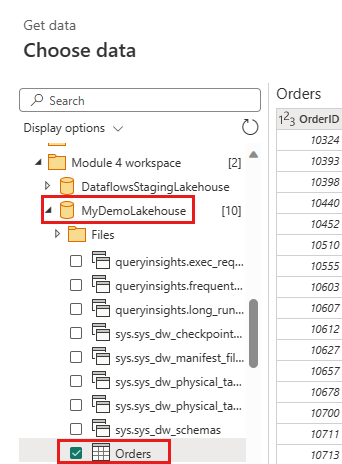
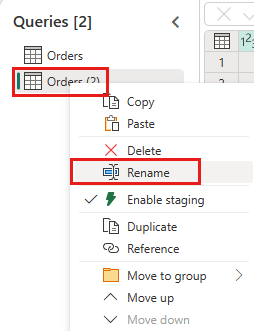
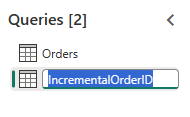
Δημιουργήστε ένα νέο ερώτημα με την ονομασία
IncrementalOrderIDκαι λάβετε δεδομένα από τον πίνακα Orders στη λίμνη που δημιουργήσατε στην προηγούμενη ενότητα.
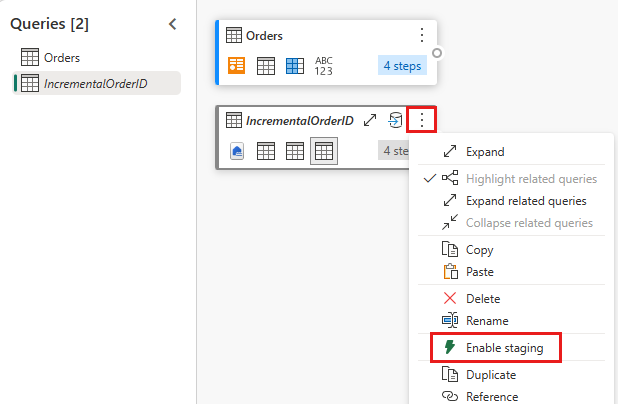
Απενεργοποίηση προεργασίας αυτού του ερωτήματος.
Στην προεπισκόπηση δεδομένων, κάντε δεξί κλικ στη
OrderIDστήλη και επιλέξτε Λεπτομερής έρευνα.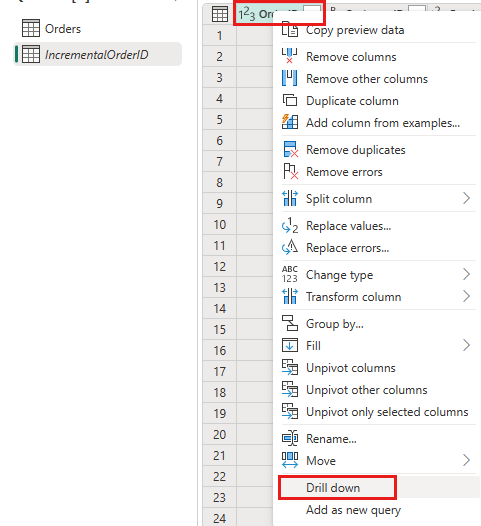
Από την κορδέλα, επιλέξτε Εργαλεία λίστας ->Στατιστικά στοιχεία ->Μέγιστο.
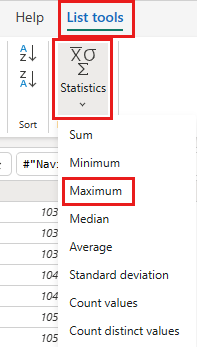
Τώρα έχετε ένα ερώτημα που επιστρέφει το μέγιστο OrderID στη λίμνη. Αυτό το ερώτημα χρησιμοποιείται για το φιλτράρισμα των δεδομένων από την προέλευση OData. Η επόμενη ενότητα προσθέτει ένα ερώτημα στη ροή δεδομένων για να φιλτράρει τα δεδομένα από την προέλευση OData με βάση το μέγιστο OrderID στο lakehouse.
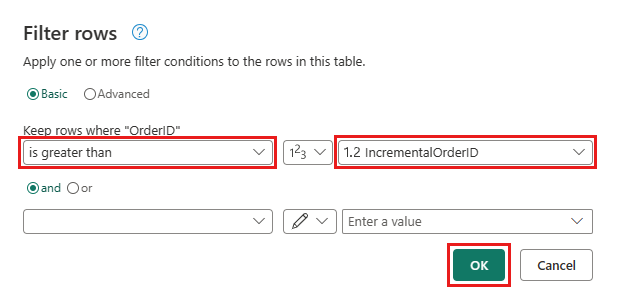
Επιστρέψτε στο ερώτημα Παραγγελίες και προσθέστε ένα νέο βήμα για να φιλτράρετε τα δεδομένα. Χρησιμοποιήστε τις παρακάτω ρυθμίσεις:
- Στήλη:
OrderID - Λειτουργία:
Greater than - Τιμή: παράμετρος
IncrementalOrderID

- Στήλη:
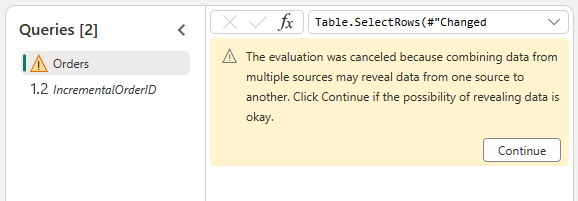
Για να είναι δυνατή ο συνδυασμός των δεδομένων από την προέλευση OData και τη λίμνη, επιβεβαιώστε το ακόλουθο παράθυρο διαλόγου:
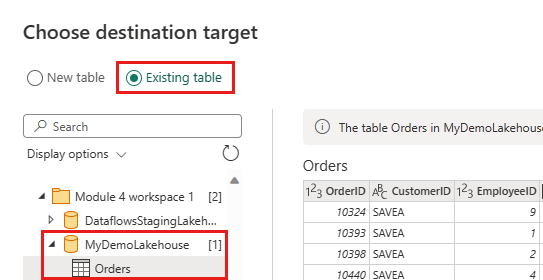
Ενημερώστε τον προορισμό δεδομένων ώστε να χρησιμοποιεί τις παρακάτω ρυθμίσεις:
- Μέθοδος ενημέρωσης:
Append

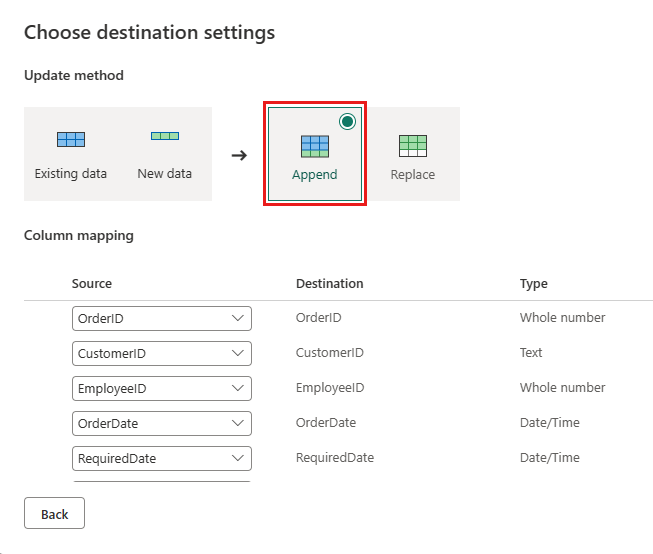
- Μέθοδος ενημέρωσης:
Δημοσιεύστε τη ροή δεδομένων.
Η ροή δεδομένων σας περιέχει τώρα ένα ερώτημα που φιλτράρει τα δεδομένα από την προέλευση OData με βάση το μέγιστο OrderID στο lakehouse. Αυτό σημαίνει ότι μόνο νέα ή ενημερωμένα δεδομένα φορτώνονται στο lakehouse. Η επόμενη ενότητα χρησιμοποιεί τη ροή δεδομένων για να φορτώσει εκ νέου δεδομένα χρησιμοποιώντας σημειωματάρια και διοχετεύσεις.
(Προαιρετικό) επαναφόρτωση δεδομένων με χρήση σημειωματάριων και διοχετεύσεων
Προαιρετικά, μπορείτε να φορτώσετε εκ νέου συγκεκριμένα δεδομένα χρησιμοποιώντας σημειωματάρια και διοχετεύσεις. Με προσαρμοσμένο κώδικα python στο σημειωματάριο, καταργείτε τα παλιά δεδομένα από το lakehouse. Στη συνέχεια, δημιουργώντας μια διοχέτευση στην οποία εκτελείτε πρώτα το σημειωματάριο και εκτελείτε διαδοχικά τη ροή δεδομένων, φορτώνετε ξανά τα δεδομένα από την προέλευση OData στο lakehouse. Τα σημειωματάρια υποστηρίζουν πολλές γλώσσες, αλλά αυτό το πρόγραμμα εκμάθησης χρησιμοποιεί το PySpark. Το Pyspark είναι ένα Python API για Spark και χρησιμοποιείται σε αυτή την εκμάθηση για την εκτέλεση ερωτημάτων Spark SQL.
Δημιουργήστε ένα νέο σημειωματάριο στον χώρο εργασίας σας.
Προσθέστε τον παρακάτω κώδικα PySpark στο σημειωματάριό σας:
### Variables LakehouseName = "YOURLAKEHOUSE" TableName = "Orders" ColName = "OrderID" NumberOfOrdersToRemove = "10" ### Remove Old Orders Reload = spark.sql("SELECT Max({0})-{1} as ReLoadValue FROM {2}.{3}".format(ColName,NumberOfOrdersToRemove,LakehouseName,TableName)).collect() Reload = Reload[0].ReLoadValue spark.sql("Delete from {0}.{1} where {2} > {3}".format(LakehouseName, TableName, ColName, Reload))Εκτελέστε το σημειωματάριο για να επαληθεύσετε ότι τα δεδομένα καταργούνται από το lakehouse.
Δημιουργήστε μια νέα διοχέτευση στον χώρο εργασίας σας.
Προσθέστε μια δραστηριότητα νέου σημειωματάριου στη διοχέτευση και επιλέξτε το σημειωματάριο που δημιουργήσατε στο προηγούμενο βήμα.
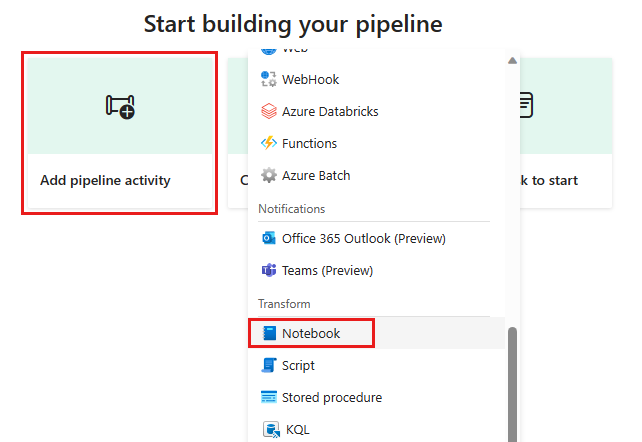
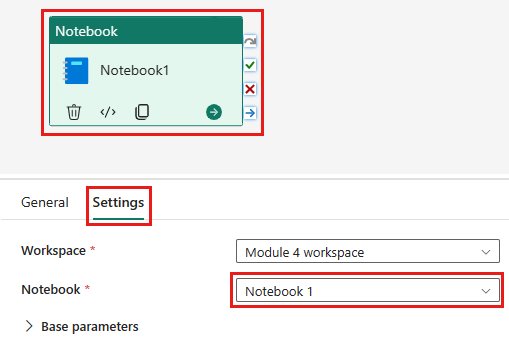
Προσθέστε μια νέα δραστηριότητα ροής δεδομένων στη διοχέτευση και επιλέξτε τη ροή δεδομένων που δημιουργήσατε στην προηγούμενη ενότητα.
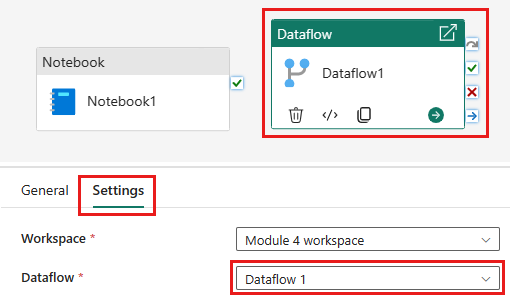
Συνδέστε τη δραστηριότητα σημειωματάριου με τη δραστηριότητα ροής δεδομένων με ένα έναυσμα επιτυχίας.
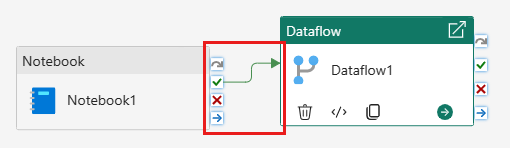
Αποθηκεύστε και εκτελέστε τη διοχέτευση.


Τώρα έχετε μια διοχέτευση που καταργεί παλιά δεδομένα από το lakehouse και φορτώνει εκ νέου τα δεδομένα από την προέλευση OData στο lakehouse. Με αυτή τη ρύθμιση, μπορείτε να φορτώσετε ξανά τα δεδομένα από την προέλευση OData στο lakehouse τακτικά.