Σημείωμα
Η πρόσβαση σε αυτήν τη σελίδα απαιτεί εξουσιοδότηση. Μπορείτε να δοκιμάσετε να εισέλθετε ή να αλλάξετε καταλόγους.
Η πρόσβαση σε αυτήν τη σελίδα απαιτεί εξουσιοδότηση. Μπορείτε να δοκιμάσετε να αλλάξετε καταλόγους.
Το Microsoft Fabric σάς δίνει τη δυνατότητα να θέσετε σε λειτουργία μοντέλα machine learning χρησιμοποιώντας την κλιμακούμενη συνάρτηση PREDICT. Αυτή η συνάρτηση υποστηρίζει βαθμολόγηση δέσμης σε οποιαδήποτε μηχανή υπολογιστικής λειτουργίας. Μπορείτε να δημιουργήσετε προβλέψεις δέσμης απευθείας από ένα σημειωματάριο Microsoft Fabric ή από τη σελίδα στοιχείου ενός δεδομένου μοντέλου εκμάθησης μηχανής.
Σε αυτό το άρθρο, θα μάθετε πώς μπορείτε να εφαρμόσετε την ΠΡΌΒΛΕΨΗ γράφοντας κώδικα μόνοι σας ή χρησιμοποιώντας μια εμπειρία καθοδηγούμενου περιβάλλοντος εργασίας χρήστη που χειρίζεται τη βαθμολόγηση δέσμης για εσάς.
Προαπαιτούμενα στοιχεία
Αποκτήστε συνδρομή Microsoft Fabric. Εναλλακτικά, εγγραφείτε για μια δωρεάν δοκιμή Microsoft Fabric.
Συνδεθείτε στο Microsoft Fabric.
Μεταβείτε στο Fabric χρησιμοποιώντας την εναλλαγή εμπειριών στην κάτω αριστερή πλευρά της αρχικής σελίδας σας.
Περιορισμοί
- Η συνάρτηση PREDICT υποστηρίζει προς το παρόν μόνο τις ακόλουθες εκδόσεις μοντέλου ML:
- CatBoost
- Keras
- LightGBM
- ONNX
- Προφήτης
- PyTorch
- Sklearn
- Spark
- Στατιστικά στοιχεία
- TensorFlow
- XGBoost
- Το PREDICT απαιτεί να αποθηκεύσετε μοντέλα εκμάθησης μηχανής σε μορφή ροής ML, με τις υπογραφές τους συμπληρωμένες.
- Το PREDICT δεν υποστηρίζει μοντέλα ML με εισόδους ή εξόδους πολλαπλών τανυστών.
Κλήση της predict από ένα σημειωματάριο
Το PREDICT υποστηρίζει μοντέλα συσκευασμένα με MLflow στο μητρώο Microsoft Fabric. Εάν υπάρχει ήδη εκπαιδευμένο και καταχωρημένο μοντέλο εκμάθησης μηχανής στον χώρο εργασίας σας, μπορείτε να προχωρήσετε στο βήμα 2. Αν όχι, το βήμα 1 παρέχει δείγμα κώδικα για να σας καθοδηγήσει στην εκπαίδευση ενός δείγματος μοντέλου λογιστικής παλινδρόμησης. Χρησιμοποιήστε αυτό το μοντέλο για να δημιουργήσετε προβλέψεις παρτίδας στο τέλος της διαδικασίας.
Εκπαιδεύστε ένα μοντέλο εκμάθησης μηχανής και καταχωρήστε το με το MLflow. Το επόμενο δείγμα κώδικα χρησιμοποιεί το API MLflow για να δημιουργήσει ένα πείραμα machine learning και, στη συνέχεια, ξεκινά μια εκτέλεση MLflow για ένα μοντέλο λογιστικής παλινδρόμησης scikit-learn. Στη συνέχεια, η έκδοση του μοντέλου αποθηκεύεται και καταχωρείται στο μητρώο Microsoft Fabric. Για περισσότερες πληροφορίες σχετικά με τα μοντέλα εκπαίδευσης και την παρακολούθηση των δικών σας πειραμάτων, δείτε πώς να εκπαιδεύσετε μοντέλα εκμάθησης μηχανής με το scikit-learn.
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Φόρτωση σε δεδομένα δοκιμής ως Spark DataFrame. Για να δημιουργήσετε προβλέψεις δέσμης με το μοντέλο εκμάθησης μηχανής εκπαιδευμένο στο προηγούμενο βήμα, χρειάζεστε δεδομένα δοκιμής με τη μορφή ενός Spark DataFrame. Στον παρακάτω κώδικα, αντικαταστήστε την τιμή μεταβλητής
testμε τα δικά σας δεδομένα.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))Δημιουργήστε ένα
MLFlowTransformerαντικείμενο για να φορτώσετε το μοντέλο εκμάθησης μηχανής για συμπεραίωση. Για να δημιουργήσετε έναMLFlowTransformerαντικείμενο για τη δημιουργία προβλέψεων δέσμης, εκτελέστε τις εξής ενέργειες:- Καθορίστε τις
testστήλες DataFrame που χρειάζεστε ως εισόδους μοντέλου (σε αυτήν την περίπτωση, όλες). - Επιλέξτε ένα όνομα για τη νέα στήλη εξόδου (σε αυτήν την περίπτωση,
predictions). - Δώστε το σωστό όνομα μοντέλου και την έκδοση μοντέλου για τη δημιουργία αυτών των προβλέψεων.
Εάν χρησιμοποιείτε το δικό σας μοντέλο εκμάθησης μηχανής, αντικαταστήστε τις τιμές για τις στήλες εισόδου, το όνομα στήλης εξόδου, το όνομα μοντέλου και την έκδοση μοντέλου.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- Καθορίστε τις
Δημιουργήστε προβλέψεις χρησιμοποιώντας τη συνάρτηση PREDICT. Για να καλέσετε τη συνάρτηση PREDICT, χρησιμοποιήστε το API Transformer, το Spark SQL API ή μια συνάρτηση που ορίζεται από τον χρήστη PySpark (UDF). Οι παρακάτω ενότητες δείχνουν πώς μπορείτε να δημιουργήσετε προβλέψεις δέσμης με τα δεδομένα δοκιμής και το μοντέλο εκμάθησης μηχανής που έχει οριστεί στα προηγούμενα βήματα, χρησιμοποιώντας τις διαφορετικές μεθόδους για την κλήση της συνάρτησης PREDICT.
ΠΡΟΒΛΕΨΗ με το API μετασχηματισμού
Αυτός ο κώδικας καλεί τη συνάρτηση PREDICT με το API μετασχηματισμού. Εάν χρησιμοποιείτε το δικό σας μοντέλο εκμάθησης μηχανής, αντικαταστήστε τις τιμές για το μοντέλο και ελέγξτε τα δεδομένα.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
ΠΡΌΒΛΕΨΗ με το Spark SQL API
Αυτός ο κώδικας καλεί τη συνάρτηση PREDICT χρησιμοποιώντας το Spark SQL API. Εάν χρησιμοποιείτε το δικό σας μοντέλο εκμάθησης μηχανής, αντικαταστήστε τις τιμές για το , model_nameκαι model_version με featuresτο όνομα μοντέλου, την έκδοση μοντέλου και τις στήλες δυνατοτήτων.
Σημείωμα
Όταν χρησιμοποιείτε το Spark SQL API για τη δημιουργία προβλέψεων, πρέπει να δημιουργήσετε ένα MLFlowTransformer αντικείμενο, όπως φαίνεται στο βήμα 3.
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
PREDICT με μια συνάρτηση που ορίζεται από τον χρήστη
Αυτός ο κώδικας καλεί τη συνάρτηση PREDICT χρησιμοποιώντας ένα PySpark UDF. Εάν χρησιμοποιείτε το δικό σας μοντέλο εκμάθησης μηχανής, αντικαταστήστε τις τιμές για το μοντέλο και τις δυνατότητες.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
Δημιουργία κώδικα PREDICT από τη σελίδα στοιχείου ενός μοντέλου εκμάθησης μηχανής
Από τη σελίδα στοιχείου οποιουδήποτε μοντέλου εκμάθησης μηχανής, μπορείτε να επιλέξετε μία από αυτές τις επιλογές για να ξεκινήσετε τη δημιουργία πρόβλεψης παρτίδας για μια συγκεκριμένη έκδοση μοντέλου, χρησιμοποιώντας τη συνάρτηση PREDICT:
- Αντιγράψτε ένα πρότυπο κώδικα σε ένα σημειωματάριο και προσαρμόστε τις παραμέτρους μόνοι σας.
- Χρησιμοποιήστε μια καθοδηγούμενη εμπειρία περιβάλλοντος εργασίας χρήστη για να δημιουργήσετε κώδικα PREDICT.
Χρήση εμπειρίας καθοδηγούμενου περιβάλλοντος εργασίας χρήστη
Η εμπειρία καθοδηγούμενου περιβάλλοντος εργασίας χρήστη σάς καθοδηγεί στα εξής βήματα:
- Επιλέξτε τα δεδομένα προέλευσης για βαθμολόγηση.
- Αντιστοιχίστε σωστά τα δεδομένα στις εισόδους του μοντέλου εκμάθησης μηχανής.
- Καθορίστε τον προορισμό για τις εξόδους του μοντέλου σας.
- Δημιουργήστε ένα σημειωματάριο που χρησιμοποιεί το PREDICT για τη δημιουργία και αποθήκευση αποτελεσμάτων πρόβλεψης.
Για να χρησιμοποιήσετε την καθοδηγούμενη εμπειρία,
Μεταβείτε στη σελίδα στοιχείου για μια δεδομένη έκδοση μοντέλου εκμάθησης μηχανής.
Από την αναπτυσσόμενη λίστα Εφαρμογή αυτής της έκδοσης , επιλέξτε Εφαρμογή αυτού του μοντέλου στον οδηγό.
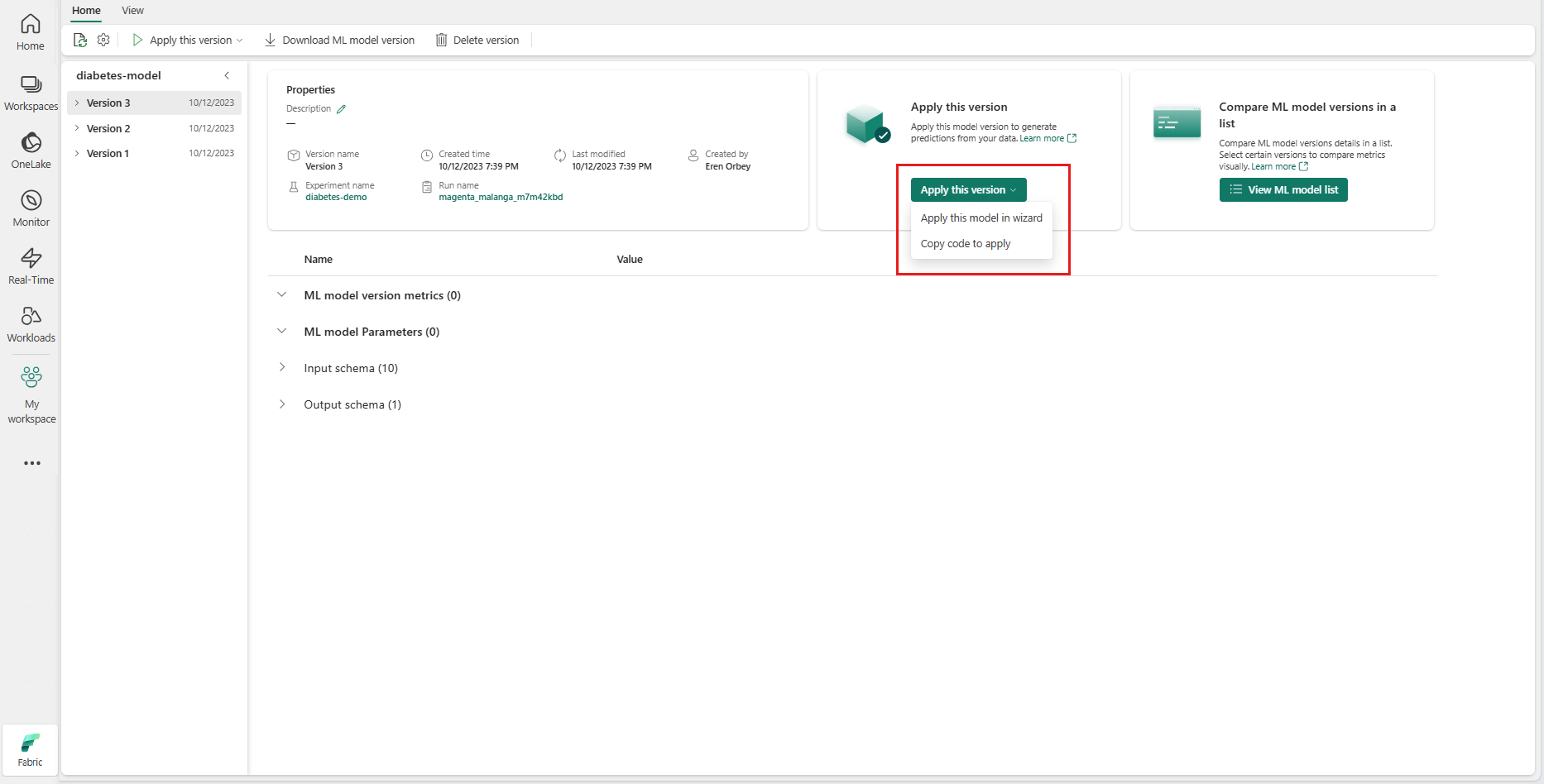
Στο βήμα "Επιλογή πίνακα εισόδου", ανοίγει το παράθυρο "Εφαρμογή προβλέψεων μοντέλου εκμάθησης μηχανής".
Επιλέξτε έναν πίνακα εισόδου από μια λίμνη στον τρέχοντα χώρο εργασίας σας.
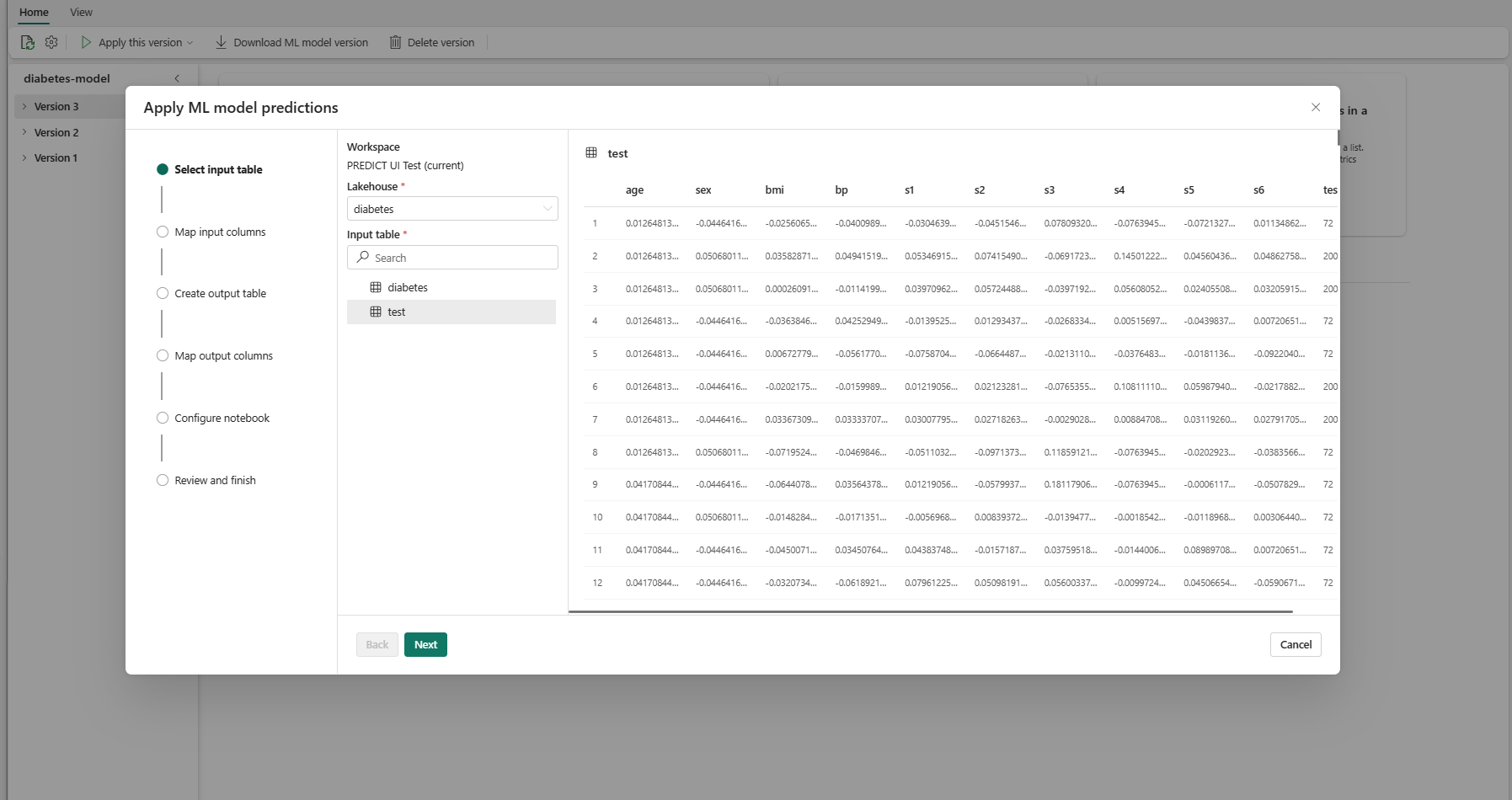
Επιλέξτε Επόμενο για να μεταβείτε στο βήμα "Αντιστοίχιση στηλών εισόδου".
Αντιστοιχίστε τα ονόματα στηλών από τον πίνακα προέλευσης στα πεδία εισόδου του μοντέλου εκμάθησης μηχανής, τα οποία αντλούνται από την υπογραφή του μοντέλου. Πρέπει να καταχωρήσετε μια στήλη εισόδου για όλα τα απαιτούμενα πεδία του μοντέλου. Επιπλέον, οι τύποι δεδομένων στήλης προέλευσης πρέπει να συμφωνούν με τους αναμενόμενους τύπους δεδομένων του μοντέλου.
Φιλοδώρημα
Ο οδηγός προ-συμπυκνώνει αυτή την αντιστοίχιση εάν τα ονόματα των στηλών του πίνακα εισόδου συμφωνούν με τα ονόματα των στηλών που είναι συνδεδεμένα στην υπογραφή μοντέλου εκμάθησης μηχανής.
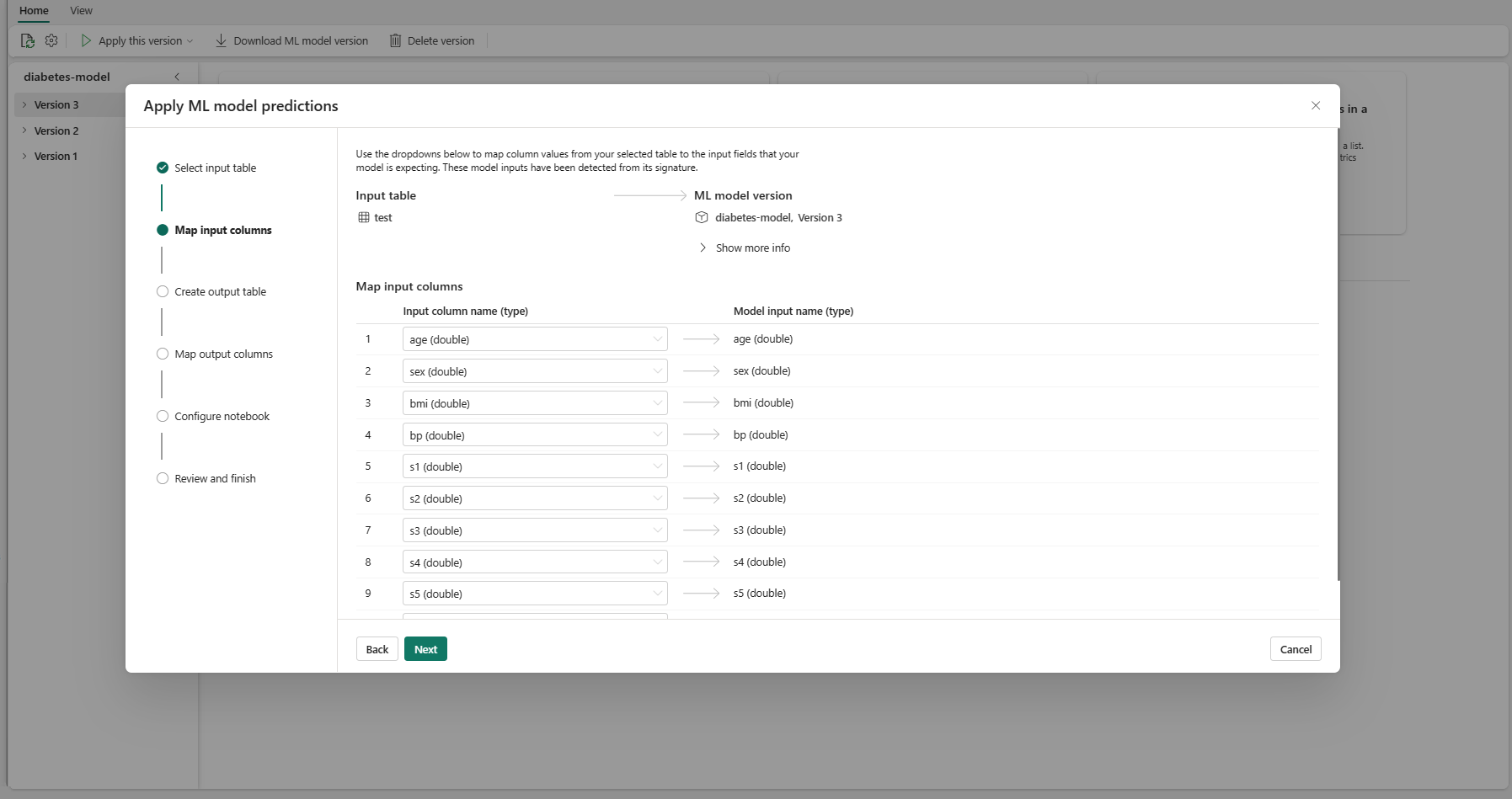
Επιλέξτε Επόμενο για να μεταβείτε στο βήμα "Δημιουργία πίνακα εξόδου".
Εισαγάγετε ένα όνομα για έναν νέο πίνακα εντός της επιλεγμένης λίμνης του τρέχοντος χώρου εργασίας σας. Αυτός ο πίνακας εξόδου αποθηκεύει τις τιμές εισόδου του μοντέλου εκμάθησης μηχανής σας και προσαρτά τις τιμές πρόβλεψης σε αυτόν τον πίνακα. Από προεπιλογή, ο πίνακας εξόδου δημιουργείται στην ίδια λίμνη με τον πίνακα εισόδου. Μπορείτε να αλλάξετε το lakehouse προορισμού.
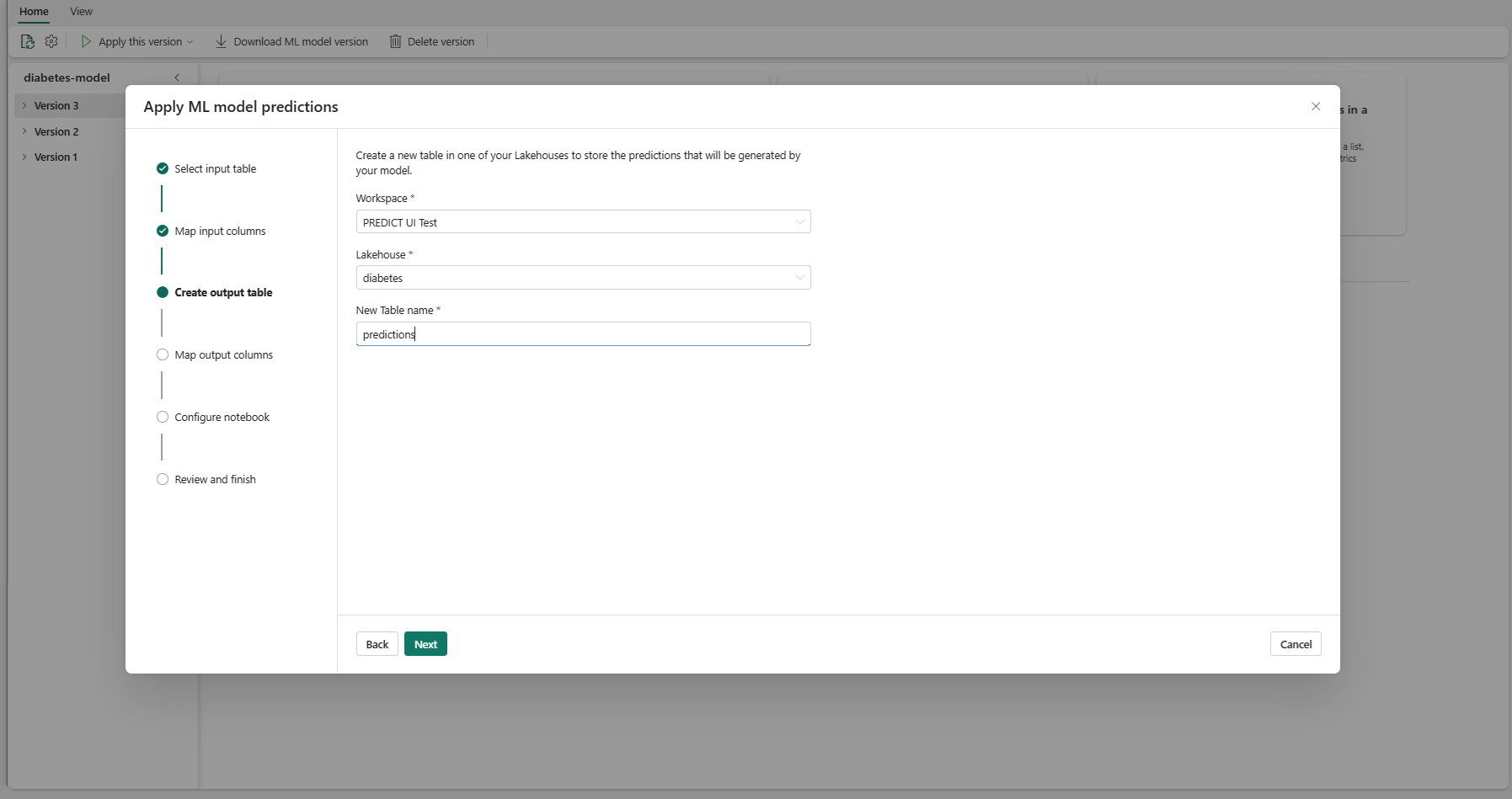
Επιλέξτε Επόμενο για να μεταβείτε στο βήμα "Αντιστοίχιση στηλών εξόδου".
Χρησιμοποιήστε τα παρεχόμενα πεδία κειμένου για να ονομάσετε τις στήλες του πίνακα εξόδου που αποθηκεύει τις προβλέψεις μοντέλου εκμάθησης μηχανής.
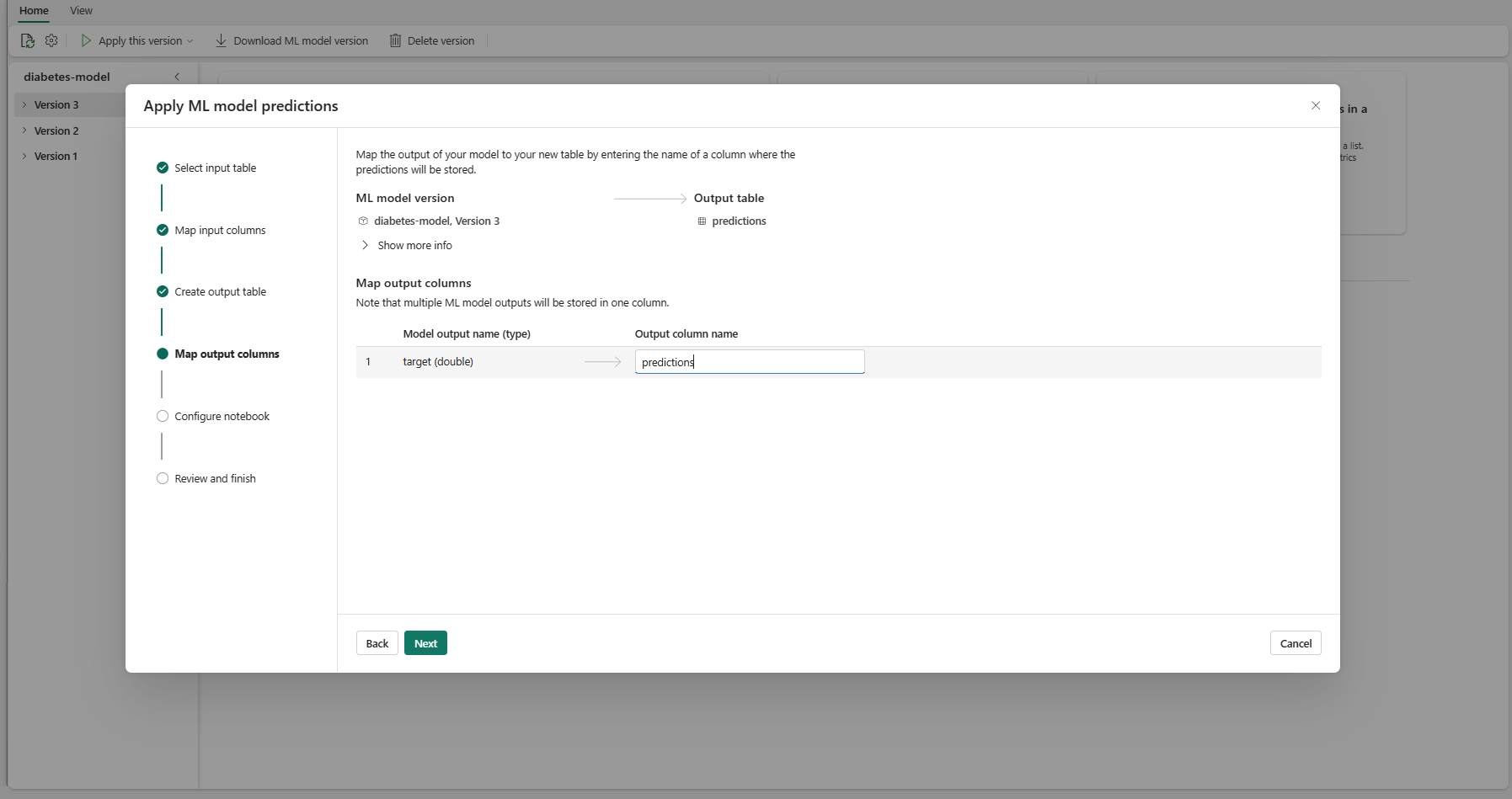
Επιλέξτε Επόμενο για να μεταβείτε στο βήμα "Ρύθμιση παραμέτρων σημειωματάριου".
Εισαγάγετε ένα όνομα για ένα νέο σημειωματάριο που εκτελεί τον κωδικό PREDICT που δημιουργείται. Ο οδηγός εμφανίζει μια προεπισκόπηση του κώδικα που δημιουργήθηκε σε αυτό το βήμα. Εάν θέλετε, μπορείτε να αντιγράψετε τον κώδικα στο πρόχειρό σας και να τον επικολλήσετε σε ένα υπάρχον σημειωματάριο.
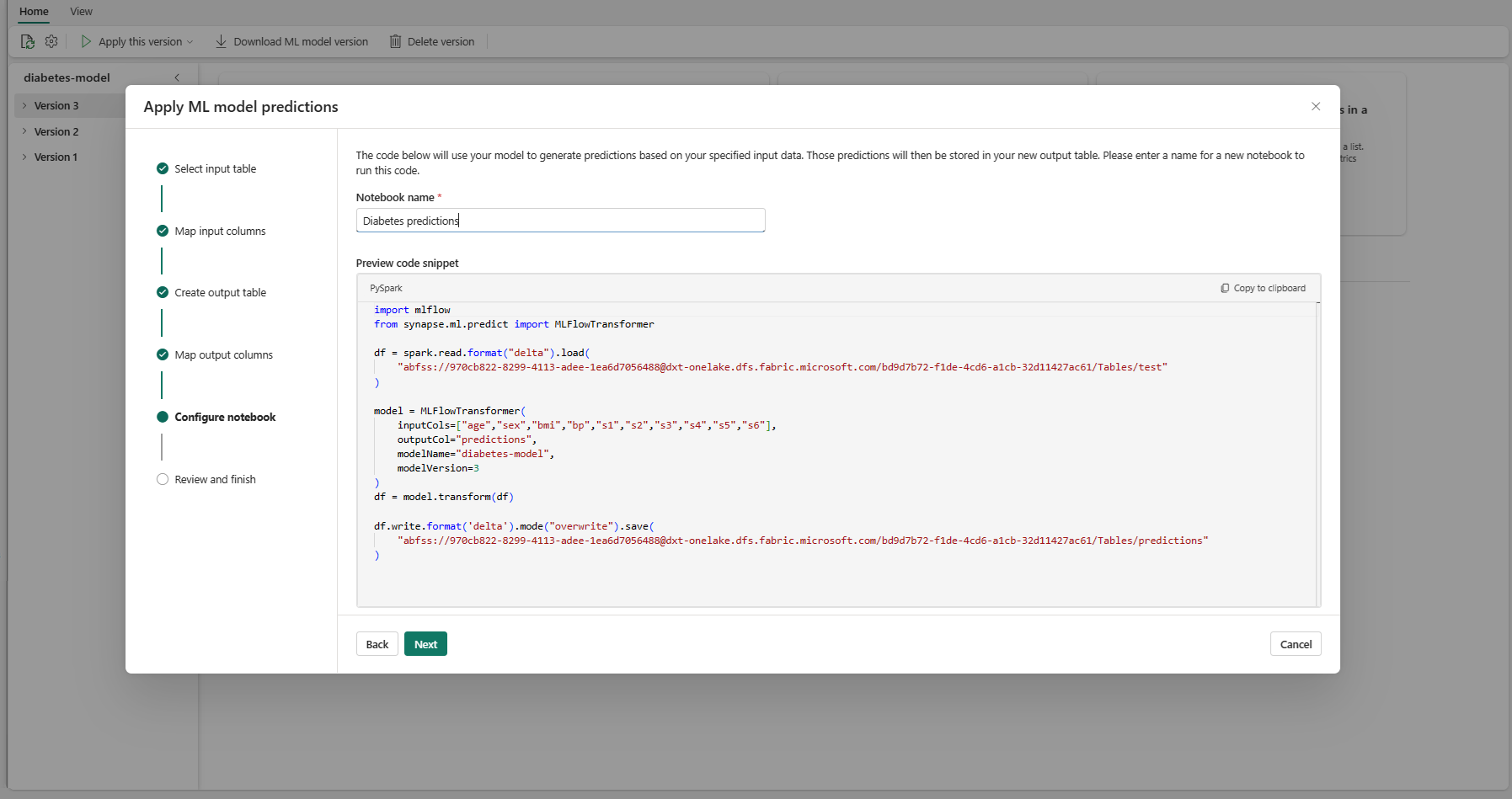
Επιλέξτε Επόμενο για να μεταβείτε στο βήμα "Αναθεώρηση και ολοκλήρωση".
Εξετάστε τις λεπτομέρειες στη σελίδα σύνοψης και επιλέξτε Δημιουργία σημειωματάριου για να προσθέσετε το νέο σημειωματάριο με τον κωδικό που δημιουργήθηκε στον χώρο εργασίας σας. Θα μεταφερθείτε απευθείας σε αυτό το σημειωματάριο, όπου μπορείτε να εκτελέσετε τον κώδικα για να δημιουργήσετε και αποθηκεύσετε προβλέψεις.
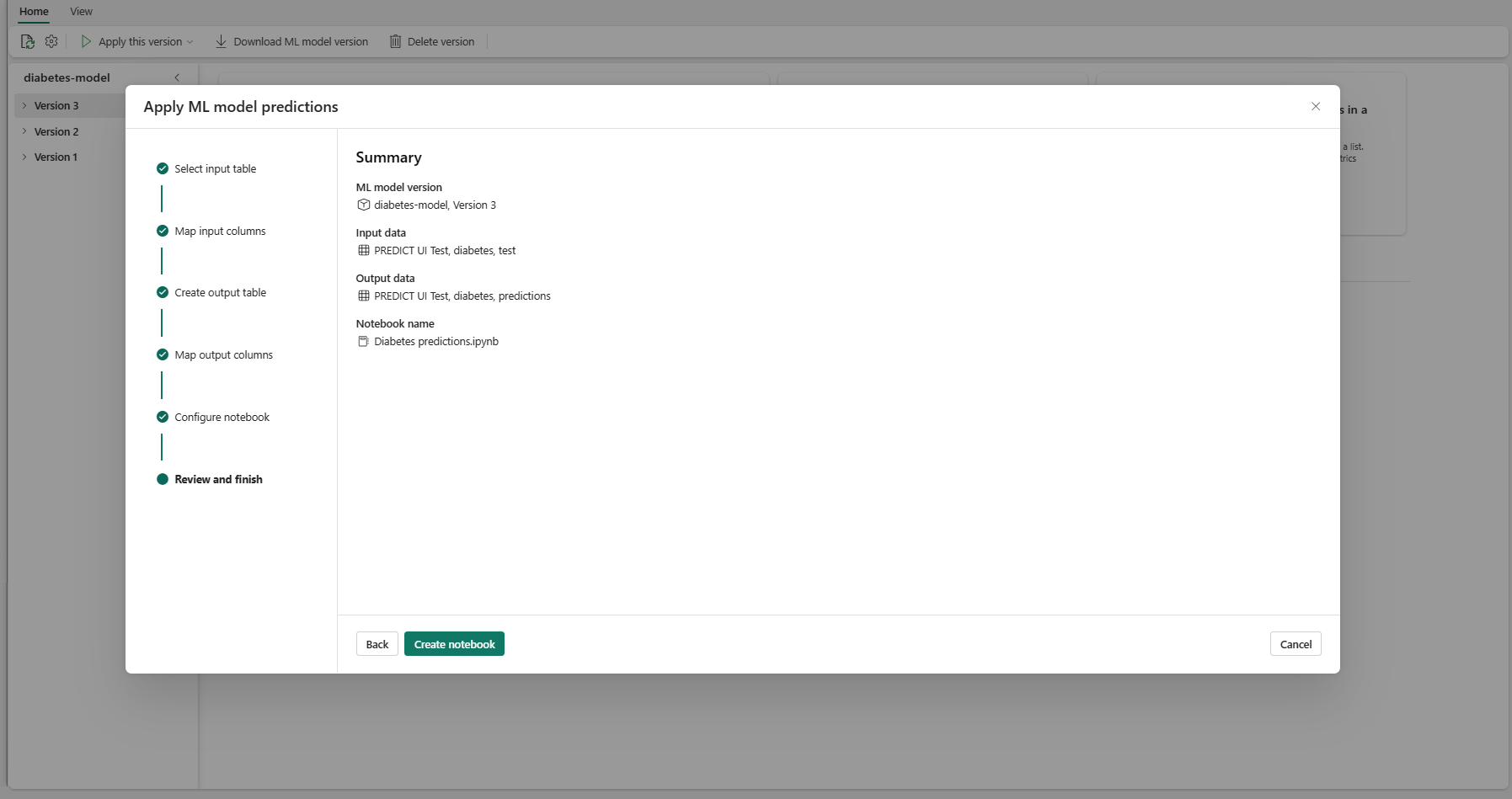







Χρήση προσαρμόσιμου προτύπου κώδικα
Για να χρησιμοποιήσετε ένα πρότυπο κώδικα για τη δημιουργία προβλέψεων δέσμης:
- Μεταβείτε στη σελίδα στοιχείου για μια δεδομένη έκδοση μοντέλου εκμάθησης μηχανής.
- Επιλέξτε Αντιγραφή κώδικα για εφαρμογή από το αναπτυσσόμενο μενού Εφαρμογή αυτής της έκδοσης . Η επιλογή αντιγράφει ένα προσαρμόσιμο πρότυπο κώδικα.
Μπορείτε να επικολλήσετε αυτό το πρότυπο κώδικα σε ένα σημειωματάριο για τη δημιουργία προβλέψεων δέσμης με το μοντέλο εκμάθησης μηχανής σας. Για να εκτελέσετε με επιτυχία το πρότυπο κώδικα, αντικαταστήστε με μη αυτόματο τρόπο τις ακόλουθες τιμές:
-
<INPUT_TABLE>: Η διαδρομή αρχείου για τον πίνακα που παρέχει εισόδους στο μοντέλο εκμάθησης μηχανής. -
<INPUT_COLS>: Ένας πίνακας ονομάτων στηλών από τον πίνακα εισόδου για τροφοδοσία στο μοντέλο εκμάθησης μηχανής. -
<OUTPUT_COLS>: Ένα όνομα για μια νέα στήλη στον πίνακα εξόδου που αποθηκεύει προβλέψεις. -
<MODEL_NAME>: Το όνομα του μοντέλου εκμάθησης μηχανής που θα χρησιμοποιηθεί για τη δημιουργία προβλέψεων. -
<MODEL_VERSION>: Η έκδοση του μοντέλου εκμάθησης μηχανής που θα χρησιμοποιηθεί για τη δημιουργία προβλέψεων. -
<OUTPUT_TABLE>: Η διαδρομή αρχείου για τον πίνακα που αποθηκεύει τις προβλέψεις.

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)