Σημείωση
Η πρόσβαση σε αυτή τη σελίδα απαιτεί εξουσιοδότηση. Μπορείτε να δοκιμάσετε να συνδεθείτε ή να αλλάξετε καταλόγους.
Η πρόσβαση σε αυτή τη σελίδα απαιτεί εξουσιοδότηση. Μπορείτε να δοκιμάσετε να αλλάξετε καταλόγους.
Ισχύει για:✅ Warehouse στο Microsoft Fabric
Αυτό το άρθρο επισημαίνει τα χαρακτηριστικά και τις καινοτομίες στην αρχιτεκτονική του Fabric Data Warehouse που ενισχύουν την απόδοση, την επεκτασιμότητα και την αποδοτικότητα κόστους.
Το Fabric Data Warehouse εκτελείται σε μια αρχιτεκτονική έτοιμη για το μέλλον σε μια συγκλίνουσα πλατφόρμα δεδομένων. Με μια ανοιχτή μορφή αποθήκευσης Delta και ενοποίηση OneLake, τα δεδομένα σας στο Fabric Data Warehouse είναι έτοιμα για ανάλυση.
Αρχιτεκτονική υψηλού επιπέδου

Το Fabric Data Warehouse έχει σχεδιαστεί ειδικά για ανάλυση σε κλίμακα με τα ακόλουθα δομικά στοιχεία:
| Δομικό στοιχείο | Description |
|---|---|
| Ενοποιημένο εργαλείο βελτιστοποίησης ερωτημάτων | Δημιουργεί ένα βέλτιστο σχέδιο εκτέλεσης για κατανεμημένα περιβάλλοντα cloud, ανεξάρτητα από την ποιότητα των ερωτημάτων SQL που έχουν συνταχθεί από τον χρήστη. |
| Κατανεμημένη επεξεργασία ερωτημάτων | Υποστηρίζει μαζική παράλληλη εκτέλεση ερωτημάτων με υποδομή cloud ταχείας αυτόματης κλιμάκωσης, παρέχοντας άμεσα τους απαραίτητους υπολογιστικούς πόρους για ερωτήματα. Οι ξεχωριστοί φόρτοι εργασίας SELECT και DML χρησιμοποιούν διακριτές ομάδες για αποτελεσματική και απομονωμένη εκτέλεση. |
| Μηχανισμός εκτέλεσης ερωτημάτων | Μια μηχανή βασισμένη σε SQL για την εκτέλεση ερωτημάτων ανάλυσης σε μεγάλο όγκο δεδομένων με γρήγορη απόδοση και υψηλή ταυτόχρονη χρήση. |
| Μεταδεδομένα και διαχείριση συναλλαγών | Τα μεταδεδομένα βρίσκονται στο frontend, στο backend και τόσο στην τοπική κρυφή μνήμη SSD όσο και στην απομακρυσμένη αποθήκευση OneLake. Υποστηρίζει ταυτόχρονες συναλλαγές και διασφαλίζει τη συμμόρφωση με το ACID. |
| Αποθήκευση στο OneLake | Καταγραφή δομημένων πινάκων που υλοποιούνται χρησιμοποιώντας τη μορφή ανοιχτού πίνακα Delta, ένα μοντέλο lakehouse με ασφαλή ανοιχτό χώρο αποθήκευσης. |
| Υφασμάτινη πλατφόρμα | Η πλατφόρμα Fabric παρέχει ένα ενοποιημένο μοντέλο ελέγχου ταυτότητας και ασφάλειας, παρακολούθησης και ελέγχου. Η αποθήκη δεδομένων Fabric είναι αυτόματα διαθέσιμη σε άλλες υπηρεσίες πλατφόρμας Fabric για την κάλυψη επιχειρηματικών αναγκών, συμπεριλαμβανομένου του Power BI, των διοχετεύσεων δεδομένων στο Data Factory, του Real-Time Intelligence και άλλων. |
Ενοποιημένος μηχανισμός βελτιστοποίησης ερωτημάτων
Το ενοποιημένο εργαλείο βελτιστοποίησης ερωτημάτων στο Fabric Data Warehouse είναι ο μηχανισμός που αποφασίζει τον πιο έξυπνο τρόπο εκτέλεσης των ερωτημάτων SQL.
Όταν υποβάλλετε ένα ερώτημα, το ενοποιημένο εργαλείο βελτιστοποίησης ερωτημάτων εξετάζει πιθανούς τρόπους εκτέλεσής του: πώς να ενώσετε πίνακες, πού να μετακινήσετε δεδομένα και πώς να χρησιμοποιήσετε πόρους όπως CPU, μνήμη και δίκτυο. Το ενοποιημένο εργαλείο βελτιστοποίησης ερωτημάτων δεν επιλέγει απλώς την πρώτη επιλογή, αλλά επιλέγει το βέλτιστο σχέδιο εντός του επιτρεπόμενου χρόνου, αξιολογώντας το κόστος σε αυτούς τους παράγοντες και τα διαθέσιμα μετα-δεδομένα και στατιστικά στοιχεία.
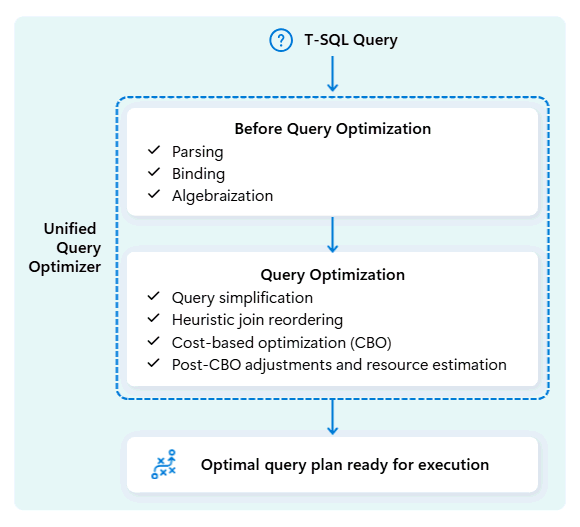
Κατά τη βελτιστοποίηση του σχεδίου εκτέλεσης ενός ερωτήματος, το ενοποιημένο εργαλείο βελτιστοποίησης ερωτημάτων λαμβάνει υπόψη τα πάντα με μία κίνηση: το σχήμα του ερωτήματός σας, την κατανομή δεδομένων των πινάκων σας και το κόστος της μετακίνησης δεδομένων έναντι της τοπικής επεξεργασίας. Το ενοποιημένο εργαλείο βελτιστοποίησης ερωτημάτων μπορεί να κάνει έξυπνους συμβιβασμούς, όπως να αποφασίσει εάν η μετάδοση ενός μικρού τραπεζιού είναι φθηνότερη από το ανακάτεμα ενός μεγάλου. Αυτό σημαίνει λιγότερες περιττές ανακάτεμα δεδομένων, καλύτερη χρήση υπολογιστών και ταχύτερη απόδοση, ακόμη και για πολύπλοκα ή κακογραμμένα ερωτήματα T-SQL.
Η συνεπής απόδοση δεν απαιτεί από τους προγραμματιστές να αφιερώνουν χρόνο σε μη αυτόματο συντονισμό ερωτημάτων T-SQL. Για παράδειγμα, δεν χρειάζεται να προσδιορίσετε με μη αυτόματο τρόπο την καλύτερη JOIN σειρά στα ερωτήματα. Εάν η SQL σας παραθέτει πρώτα τον μεγάλο πίνακα και μετά έναν μικρότερο, εξαιρετικά επιλεκτικό πίνακα δεδομένων, ο βελτιστοποιητής μπορεί να αλλάξει αυτόματα τις θέσεις του για καλύτερη απόδοση. Θα χρησιμοποιήσει τον μικρότερο πίνακα ως σημείο εκκίνησης για την αντιστοίχιση σειρών (η πλευρά "build") και τον μεγαλύτερο πίνακα ως αυτόν που θα αναζητήσει (η πλευρά "probe", ελεγμένη για αντιστοιχίσεις). Αυτή η προσέγγιση ελαχιστοποιεί τη χρήση μνήμης, μειώνει την κίνηση των δεδομένων και βελτιώνει τον παραλληλισμό, ενώ εξακολουθεί να παρέχει ακριβή αποτελέσματα.
Το ενοποιημένο εργαλείο βελτιστοποίησης ερωτημάτων μαθαίνει συνεχώς από προηγούμενες εκτελέσεις ερωτημάτων καθώς εξελίσσονται οι φόρτοι εργασίας, βελτιώνοντας τον αλγόριθμο βελτιστοποίησής του για να προσφέρει την καλύτερη δυνατή απόδοση. Οι χρήστες επωφελούνται από τη γρήγορη εκτέλεση ερωτημάτων αυτόματα, ανεξάρτητα από την πολυπλοκότητα και χωρίς να χρειάζεται να παρέμβουν.
Κατανεμημένη μηχανή επεξεργασίας ερωτημάτων
Στο Fabric Data Warehouse, ο κατανεμημένος μηχανισμός επεξεργασίας ερωτημάτων εκχωρεί υπολογιστικούς πόρους σε εργασίες σε σχέδια ερωτημάτων. Η κατανεμημένη μηχανή επεξεργασίας ερωτημάτων μπορεί να προγραμματίσει εργασίες σε υπολογιστικούς κόμβους, ώστε κάθε κόμβος να εκτελεί μέρος ενός σχεδίου ερωτήματος, επιτρέποντας την παράλληλη εκτέλεση για ταχύτερη απόδοση. Οι σύνθετες αναφορές σε μεγάλα σύνολα δεδομένων μπορούν να επωφεληθούν από την κατανεμημένη επεξεργασία ερωτημάτων.
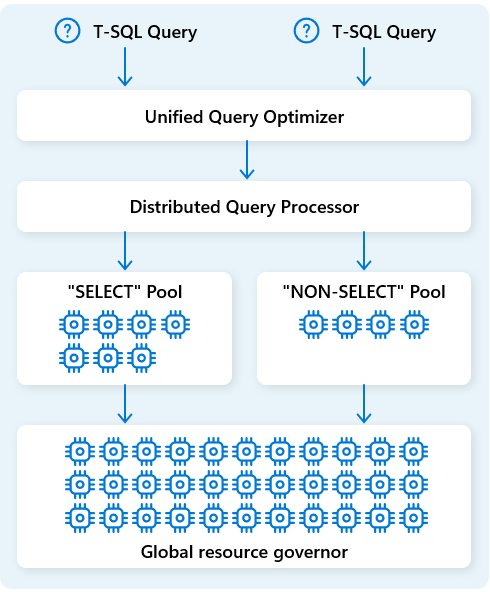
Για περαιτέρω βελτιστοποίηση των πόρων, η κατανεμημένη μηχανή επεξεργασίας ερωτημάτων διαχωρίζει τους υπολογιστικούς πόρους σε δύο ομάδες: για SELECT ερωτήματα και για εργασίες πρόσληψης δεδομένων (NON-SELECT ερωτήματα). Κάθε φόρτος εργασίας λαμβάνει αποκλειστικούς πόρους ανάλογα με τις ανάγκες. Αυτό σημαίνει, για παράδειγμα, ότι οι νυχτερινές σας εργασίες ETL δεν θα καθυστερήσουν τους πρωινούς πίνακες ελέγχου.
Με την ταχεία παροχή κόμβων στο cloud, η κατανεμημένη μηχανή επεξεργασίας ερωτημάτων κλιμακώνει αυτόματα τους υπολογιστικούς πόρους προς τα πάνω ή προς τα κάτω ως απόκριση σε αλλαγές στον όγκο ερωτημάτων, το μέγεθος δεδομένων και την πολυπλοκότητα των ερωτημάτων. Το Fabric Data Warehouse έχει δυνατότητες παράλληλης επεξεργασίας για μικρά σύνολα δεδομένων ή δεδομένα σε κλίμακα πολλών petabyte.
Μηχανή εκτέλεσης ερωτημάτων
Η μηχανή εκτέλεσης ερωτημάτων είναι μια διαδικασία που εκτελεί τμήματα του κατανεμημένου σχεδίου εκτέλεσης που έχουν εκχωρηθεί στους μεμονωμένους υπολογιστικούς κόμβους. Ο μηχανισμός εκτέλεσης ερωτημάτων βασίζεται στον ίδιο μηχανισμό που χρησιμοποιείται από τον SQL Server και τη βάση δεδομένων SQL Azure για τη χρήση εκτέλεσης λειτουργίας δέσμης και μορφών στηλών δεδομένων για αποτελεσματική ανάλυση σε μεγάλα δεδομένα με βέλτιστο κόστος.
Ο μηχανισμός εκτέλεσης ερωτημάτων διαβάζει δεδομένα απευθείας από αρχεία Delta Parquet που είναι αποθηκευμένα στο Fabric OneLake και αξιοποιεί πολλαπλά επίπεδα προσωρινής αποθήκευσης (μνήμη και SSD) για να επιταχύνει την απόδοση των ερωτημάτων και να διασφαλίσει ότι τα ερωτήματα εκτελούνται με τη βέλτιστη ταχύτητα. Ο μηχανισμός εκτέλεσης ερωτημάτων επεξεργάζεται δεδομένα στη μνήμη και, όταν είναι απαραίτητο, ανακτά πρόσθετα δεδομένα από την κρυφή μνήμη SSD ή τον χώρο αποθήκευσης OneLake.
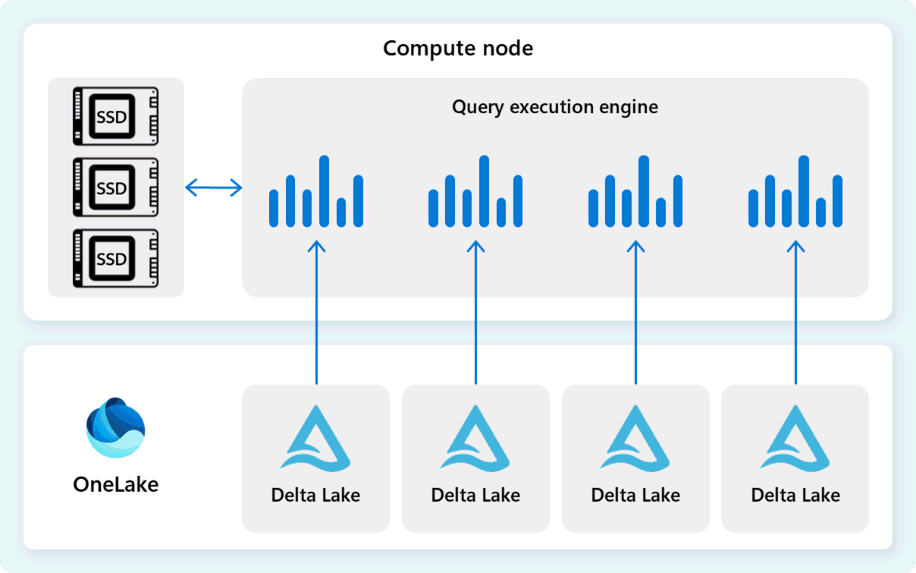
Καθώς επεξεργάζεται δεδομένα, ο μηχανισμός εκτέλεσης ερωτήματος εκτελεί την εξάλειψη στηλών και ομάδων γραμμών για να παραλείψει τμήματα που δεν σχετίζονται με το ερώτημα. Αυτή η βελτιστοποίηση μειώνει τον όγκο των δεδομένων που σαρώνονται από τα αρχεία και την προσωρινή μνήμη, συμβάλλοντας στην ελαχιστοποίηση της χρήσης πόρων και στη βελτίωση του συνολικού χρόνου εκτέλεσης.
Η μηχανή εκτέλεσης ερωτημάτων υπερέχει στο φιλτράρισμα και τη συγκέντρωση δισεκατομμυρίων σειρών, υποστηρίζοντας τα γενικά μοτίβα ανάλυσης δεδομένων που χρησιμοποιούνται στις σύγχρονες λύσεις αποθήκης δεδομένων. Η εκτέλεση της λειτουργίας δέσμης εκμεταλλεύεται τη σύγχρονη ικανότητα της CPU να επεξεργάζεται πολλές σειρές παράλληλα, μειώνοντας δραματικά τα γενικά έξοδα και κάνοντας τα ερωτήματα να εκτελούνται έως και εκατοντάδες φορές πιο γρήγορα σε σύγκριση με την παραδοσιακή εκτέλεση σειρά προς σειρά.
Μεταδεδομένα και διαχείριση συναλλαγών
Ο μηχανισμός αποθήκης χρησιμοποιεί μετα-δεδομένα για να περιγράψει το σχήμα πίνακα, την οργάνωση αρχείων, το ιστορικό εκδόσεων και τις καταστάσεις συναλλαγών. Αυτά τα μεταδεδομένα επιτρέπουν στη μηχανή αποθήκης να διαχειρίζεται αποτελεσματικά και να αναζητά δεδομένα. Το Fabric Data Warehouse προσφέρει μια ισχυρή και ολοκληρωμένη αρχιτεκτονική μεταδεδομένων και διαχείρισης συναλλαγών, επεκτείνοντας έναν διαχειριστή συναλλαγών OLTP για να ενορχηστρώνει εξαιρετικά ταυτόχρονες λειτουργίες μεταδεδομένων και να διασφαλίζει τη συμμόρφωση με το ACID.
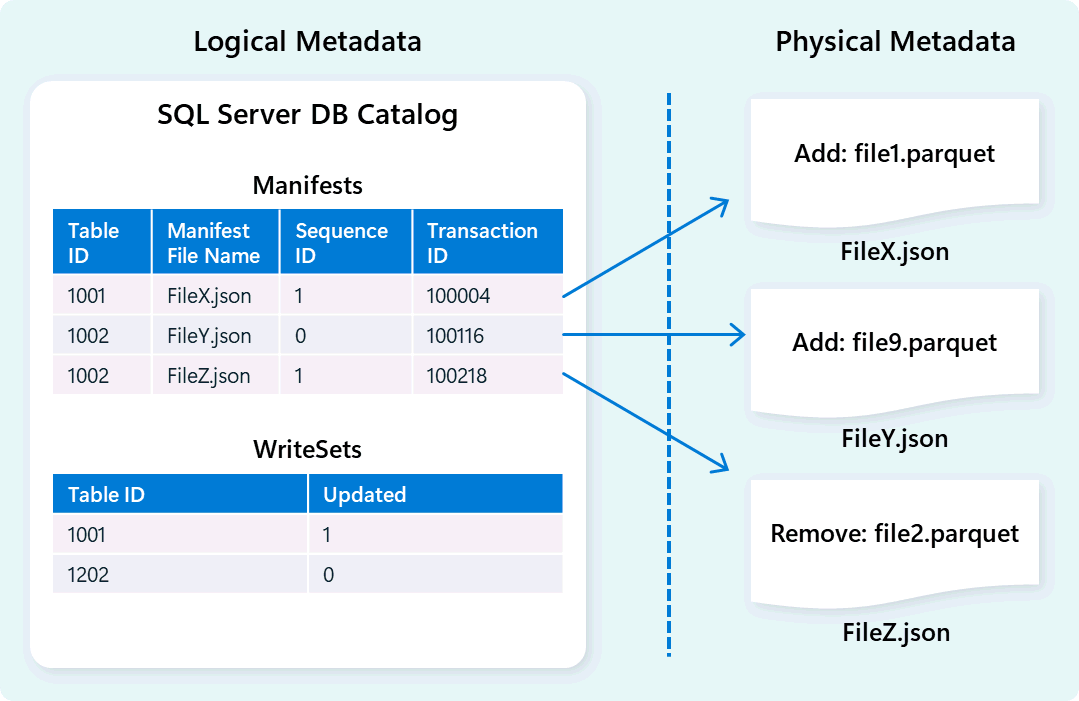
Αυτός ο σχεδιασμός επιτρέπει τη γρήγορη, αξιόπιστη πλοήγηση σε καταστάσεις συναλλαγών, υποστηρίζοντας φόρτους εργασίας με υψηλή ταυτόχρονη χρήση, διασφαλίζοντας παράλληλα συνέπεια.
Αποθήκευση και πρόσληψη δεδομένων
Το Fabric Data Warehouse χρησιμοποιεί μια αρχιτεκτονική lakehouse με τη μορφή Delta ανοιχτού κώδικα για επεκτάσιμη, ασφαλή αποθήκευση υψηλής απόδοσης. Η μορφή πίνακα Delta υποστηρίζει την έκδοση δεδομένων, επιτρέποντας την άμεση πρόσβαση σε ιστορικά στιγμιότυπα μέσω ταξιδιού στο χρόνο και κλωνοποίησης μηδενικού αντιγράφου για ασφαλείς δοκιμές και λειτουργίες επαναφοράς. Τα δεδομένα χρήστη αποθηκεύονται στο OneLake, επιτρέποντας σε όλες τις μηχανές Fabric να έχουν αποτελεσματική πρόσβαση σε κοινόχρηστα δεδομένα χωρίς πλεονασμό.
Με βάση αυτό το θεμέλιο, το Fabric Data Warehouse έχει σχεδιαστεί για να παρέχει βέλτιστη απόδοση πρόσληψης δεδομένων με έμφαση στην απλότητα και την ευελιξία. Ο κινητήρας διαχειρίζεται αποτελεσματικά την αποθήκευση δεδομένων πίνακα μέσω αυτόματης συμπίεσης δεδομένων, η οποία ενοποιεί κατακερματισμένα αρχεία στο παρασκήνιο για να μειώσει την περιττή σάρωση δεδομένων. Η έξυπνη μέθοδος διανομής δεδομένων του διαιρεί και οργανώνει τα δεδομένα σε μικροδιαμερισμένα κελιά για να ενισχύσει την παράλληλη επεξεργασία και να βελτιώσει τα αποτελέσματα των ερωτημάτων. Αυτές οι δυνατότητες λειτουργούν αυτόνομα, χωρίς να χρειάζονται χειροκίνητες ρυθμίσεις.