Ενοποίηση OneLake με το Azure HDInsight
Το Azure HDInsight είναι μια διαχειριζόμενη υπηρεσία που βασίζεται στο cloud για μεγάλες αναλύσεις δεδομένων που βοηθά τους οργανισμούς να επεξεργάζονται δεδομένα μεγάλου όγκου. Αυτή η εκμάθηση δείχνει πώς μπορείτε να συνδεθείτε στο OneLake με ένα σημειωματάριο Jupyter από ένα σύμπλεγμα Azure HDInsight.
Χρήση του Azure HDInsight
Για να συνδεθείτε στο OneLake με ένα σημειωματάριο Jupyter από ένα σύμπλεγμα HDInsight:
Δημιουργήστε ένα σύμπλεγμα APache Spark HDInsight (HDI). Ακολουθήστε αυτές τις οδηγίες: Ρύθμιση συμπλεγμάτων στο HDInsight.
Παρέχοντας πληροφορίες συμπλέγματος, να θυμάστε το Όνομα χρήστη και τον Κωδικό πρόσβασης σύνδεσης συμπλέγματος καθώς τα χρειάζεστε για να αποκτήσετε πρόσβαση στο σύμπλεγμα αργότερα.
Δημιουργία διαχειριζόμενης ταυτότητας (UAMI) στον χρήστη: Δημιουργήστε το για Azure HDInsight - UAMI και επιλέξτε το ως ταυτότητα στην οθόνη Χώρος αποθήκευσης .
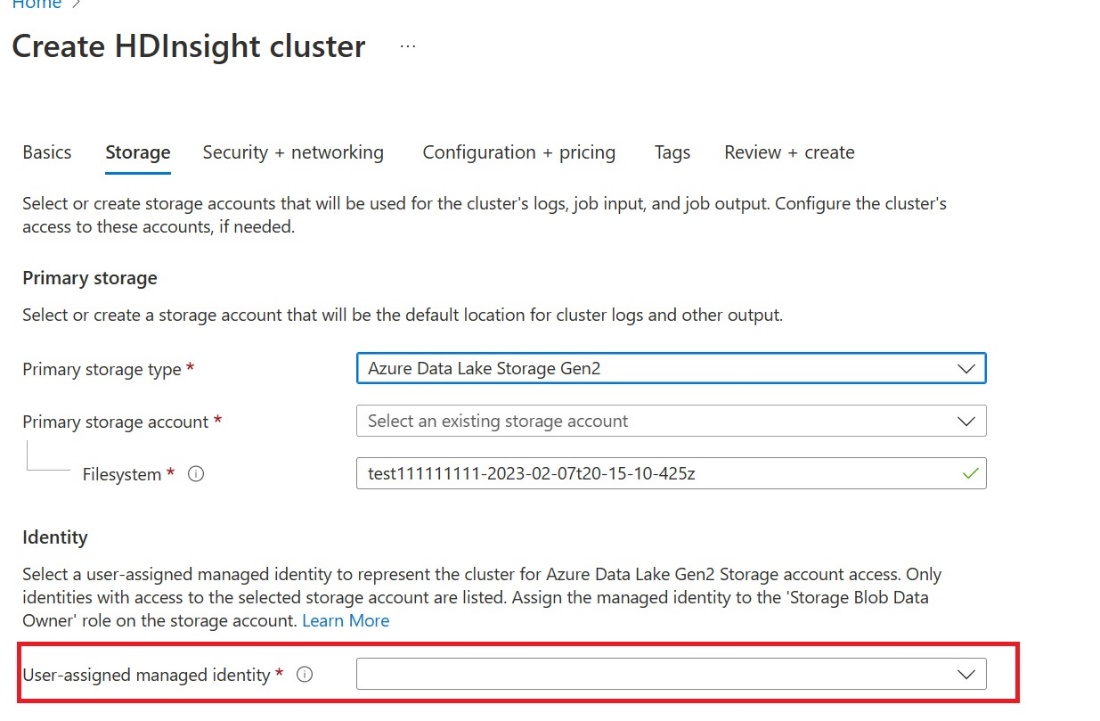
Εκχωρήστε σε αυτό το UAMI πρόσβαση στον χώρο εργασίας Fabric που περιέχει τα στοιχεία σας. Για βοήθεια σχετικά με τον ρόλο που είναι καλύτερος, ανατρέξτε στο θέμα Ρόλοι χώρου εργασίας.
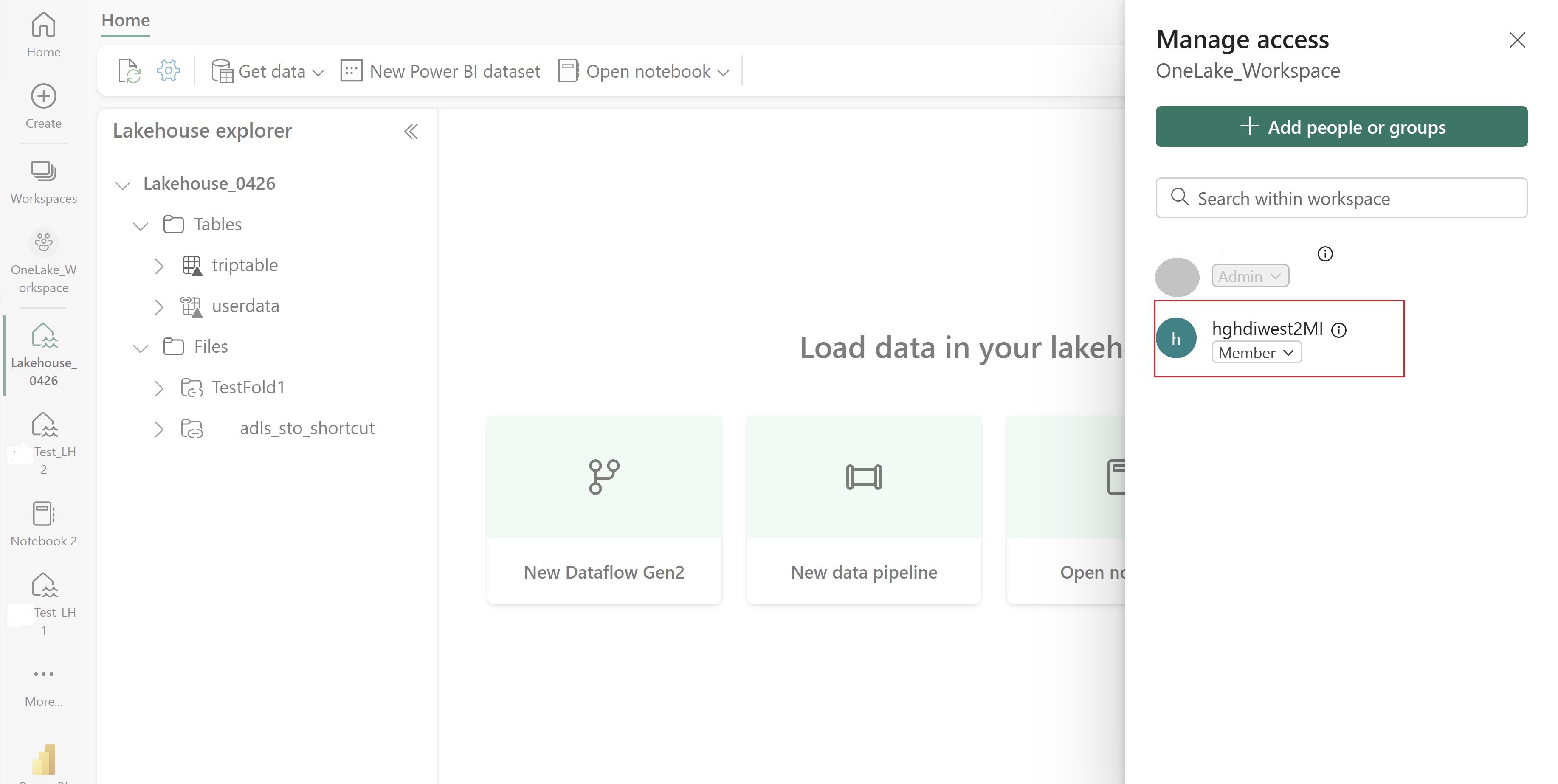
Μεταβείτε στο lakehouse σας και βρείτε το όνομα για τον χώρο εργασίας και το lakehouse σας. Μπορείτε να τις βρείτε στη διεύθυνση URL του lakehouse ή στο τμήμα παραθύρου Ιδιότητες για ένα αρχείο.
Στην πύλη Azure, αναζητήστε το σύμπλεγμα και επιλέξτε το σημειωματάριο.

Εισαγάγετε τις πληροφορίες διαπιστευτηρίων που παρείχατε κατά τη δημιουργία του συμπλέγματος.

Δημιουργήστε ένα νέο σημειωματάριο Apache Spark.
Αντιγράψτε τα ονόματα χώρου εργασίας και lakehouse στο σημειωματάριό σας και δημιουργήστε τη διεύθυνση URL OneLake για το lakehouse σας. Τώρα μπορείτε να διαβάσετε οποιοδήποτε αρχείο από αυτή τη διαδρομή αρχείου.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()Δοκιμάστε να γράψετε ορισμένα δεδομένα στο lakehouse.
writecsvdf = df.write.format("csv").save(fp + "out.csv")Ελέγξτε ότι τα δεδομένα σας γράφτηκαν με επιτυχία ελέγχοντας το lakehouse ή διαβάζοντας το αρχείο που μόλις φορτώστηκε.




Μπορείτε πλέον να διαβάζετε και να γράφετε δεδομένα στο OneLake χρησιμοποιώντας το σημειωματάριό σας Jupyter σε ένα σύμπλεγμα HDI Spark.
Σχετικό περιεχόμενο
Σχόλια
Σύντομα διαθέσιμα: Καθ' όλη τη διάρκεια του 2024 θα καταργήσουμε σταδιακά τα ζητήματα GitHub ως μηχανισμό ανάδρασης για το περιεχόμενο και θα το αντικαταστήσουμε με ένα νέο σύστημα ανάδρασης. Για περισσότερες πληροφορίες, ανατρέξτε στο θέμα: https://aka.ms/ContentUserFeedback.
Υποβολή και προβολή σχολίων για