Ενοποίηση oneLake με το Azure Synapse Analytics
Το Azure Synapse είναι μια υπηρεσία απεριόριστης ανάλυσης, η οποία συνδυάζει την αποθήκευση επιχειρησιακών δεδομένων και την ανάλυση μεγάλων δεδομένων. Αυτή η εκμάθηση δείχνει πώς μπορείτε να συνδεθείτε στο OneLake χρησιμοποιώντας το Azure Synapse Analytics.
Εγγραφή δεδομένων από το Synapse με χρήση του Apache Spark
Ακολουθήστε αυτά τα βήματα για να χρησιμοποιήσετε το Apache Spark για να γράψετε δείγμα δεδομένων στο OneLake από το Azure Synapse Analytics.
Ανοίξτε τον χώρο εργασίας σας Synapse και δημιουργήστε έναν χώρο συγκέντρωσης Apache Spark με τις παραμέτρους που προτιμάτε.
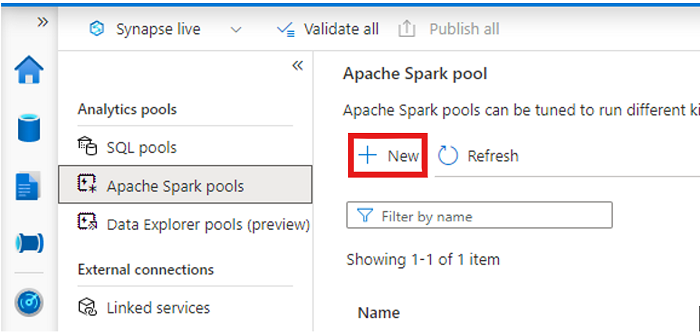
Δημιουργήστε ένα νέο σημειωματάριο Apache Spark.
Ανοίξτε το σημειωματάριο, ορίστε τη γλώσσα σε PySpark (Python) και συνδέστε το στο χώρο συγκέντρωσης Spark που μόλις δημιουργήσατε.
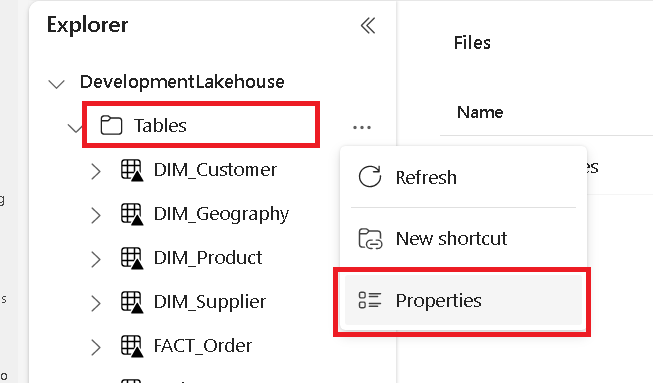
Σε ξεχωριστή καρτέλα, μεταβείτε στη λίμνη Microsoft Fabric και βρείτε τον φάκελο πινάκων ανώτατου επιπέδου.
Κάντε δεξί κλικ στον φάκελο Πίνακες και επιλέξτε Ιδιότητες.
Αντιγράψτε τη διαδρομή ABFS από το τμήμα παραθύρου ιδιοτήτων.
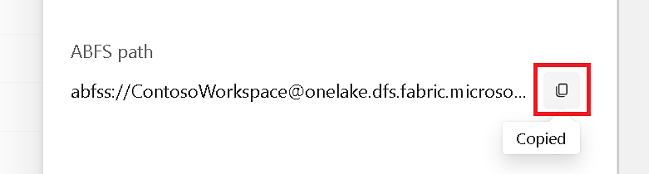
Πίσω στο σημειωματάριο Azure Synapse, στο πρώτο νέο κελί κώδικα, δώστε τη διαδρομή lakehouse. Αυτό το lakehouse είναι το σημείο όπου τα δεδομένα σας γράφονται αργότερα. Εκτελέστε το κελί.
# Replace the path below with the ABFS path to your lakehouse Tables folder. oneLakePath = 'abfss://WorkspaceName@onelake.dfs.fabric.microsoft.com/LakehouseName.lakehouse/Tables'Σε ένα νέο κελί κώδικα, φορτώστε δεδομένα από ένα ανοικτό σύνολο δεδομένων Azure σε ένα πλαίσιο δεδομένων. Αυτό το σύνολο δεδομένων είναι αυτό που φορτώνετε στο lakehouse σας. Εκτελέστε το κελί.
yellowTaxiDf = spark.read.parquet('wasbs://nyctlc@azureopendatastorage.blob.core.windows.net/yellow/puYear=2018/puMonth=2/*.parquet') display(yellowTaxiDf.limit(10))Σε ένα νέο κελί κώδικα, φιλτράρετε, μετασχηματίστε ή προετοιμασία των δεδομένων σας. Για αυτό το σενάριο, μπορείτε να περιορίσετε το σύνολο δεδομένων σας για ταχύτερη φόρτωση, να συνδεθείτε με άλλα σύνολα δεδομένων ή να φιλτράρετε προς τα κάτω για συγκεκριμένα αποτελέσματα. Εκτελέστε το κελί.
filteredTaxiDf = yellowTaxiDf.where(yellowTaxiDf.tripDistance>2).where(yellowTaxiDf.passengerCount==1) display(filteredTaxiDf.limit(10))Σε ένα νέο κελί κώδικα, χρησιμοποιώντας τη διαδρομή Σας OneLake, γράψτε το φιλτραρισμένο πλαίσιο δεδομένων σας σε ένα νέο πίνακα Delta-Parquet στο lakehouse Fabric σας. Εκτελέστε το κελί.
filteredTaxiDf.write.format("delta").mode("overwrite").save(oneLakePath + '/Taxi/')Τέλος, σε ένα νέο κελί κώδικα, ελέγξτε ότι τα δεδομένα σας γράφτηκαν με επιτυχία διαβάζοντας το αρχείο σας που μόλις φορτώθηκε από το OneLake. Εκτελέστε το κελί.
lakehouseRead = spark.read.format('delta').load(oneLakePath + '/Taxi/') display(lakehouseRead.limit(10))
Συγχαρητήρια. Μπορείτε πλέον να διαβάζετε και να γράφετε δεδομένα στο OneLake χρησιμοποιώντας το Apache Spark στο Azure Synapse Analytics.
Ανάγνωση δεδομένων από το Synapse με χρήση SQL
Ακολουθήστε τα παρακάτω βήματα για να χρησιμοποιήσετε τη δυνατότητα SQL χωρίς τη χρήση διακομιστή για την ανάγνωση δεδομένων από το OneLake από το Azure Synapse Analytics.
Ανοίξτε μια λίμνη Fabric και αναγνωρίστε έναν πίνακα στον οποίο θέλετε να υποβάλετε ερώτημα από τη Synapse.
Κάντε δεξί κλικ στον πίνακα και επιλέξτε Ιδιότητες.
Αντιγράψτε τη διαδρομή ABFS για τον πίνακα.
Ανοίξτε τον χώρο εργασίας Synapse στο Synapse Studio.
Δημιουργήστε μια νέα δέσμη ενεργειών SQL.
Στο πρόγραμμα επεξεργασίας ερωτημάτων SQL, πληκτρολογήστε το παρακάτω ερώτημα, αντικαθιστώντας
ABFS_PATH_HEREτο με τη διαδρομή που αντιγράψατε προηγουμένως.SELECT TOP 10 * FROM OPENROWSET( BULK 'ABFS_PATH_HERE', FORMAT = 'delta') as rows;Εκτελέστε το ερώτημα για να προβάλετε τις 10 πρώτες γραμμές του πίνακα.
Συγχαρητήρια. Τώρα, μπορείτε να διαβάσετε δεδομένα από το OneLake χρησιμοποιώντας SQL χωρίς τη χρήση διακομιστή στο Azure Synapse Analytics.
Σχετικό περιεχόμενο
Σχόλια
Σύντομα διαθέσιμα: Καθ' όλη τη διάρκεια του 2024 θα καταργήσουμε σταδιακά τα ζητήματα GitHub ως μηχανισμό ανάδρασης για το περιεχόμενο και θα το αντικαταστήσουμε με ένα νέο σύστημα ανάδρασης. Για περισσότερες πληροφορίες, ανατρέξτε στο θέμα: https://aka.ms/ContentUserFeedback.
Υποβολή και προβολή σχολίων για