Δειγματοληψία γραμμής υψηλής πυκνότητας στο Power BI
Ο αλγόριθμος δειγματοληψίας στο Power BI βελτιώνει τις απεικονίσεις που κάνουν δειγματοληψία δεδομένων υψηλής πυκνότητας. Για παράδειγμα, μπορείτε να δημιουργήσετε ένα γράφημα γραμμών από τα αποτελέσματα πωλήσεων των καταστημάτων λιανικής σας και κάθε κατάστημα να έχει περισσότερες από 10.000 αποδείξεις πώλησης κάθε χρόνο. Ένα γράφημα γραμμών με αυτές τις πληροφορίες πωλήσεων θα έκανε δειγματοληψία δεδομένων από τα δεδομένα για κάθε χώρο αποθήκευσης και θα δημιουργούσε ένα γράφημα γραμμών πολλών σειρών που θα αναπαραστά τα υποκείμενα δεδομένα. Βεβαιωθείτε ότι έχετε επιλέξει μια χαρακτηριστική αναπαράσταση αυτών των δεδομένων, για να απεικονίστε πώς κυμαίνονται οι πωλήσεις με την πάροδο του χρόνου. Αυτή η πρακτική είναι κοινή στην απεικόνιση δεδομένων υψηλής πυκνότητας. Οι λεπτομέρειες της δειγματοληψίας δεδομένων υψηλής πυκνότητας περιγράφονται σε αυτό το άρθρο.
Σημείωμα
Ο αλγόριθμος δειγματοληψίας υψηλής πυκνότητας που περιγράφεται σε αυτό το άρθρο είναι διαθέσιμος τόσο στο Power BI Desktop όσο και στο Υπηρεσία Power BI.
Πώς λειτουργεί η δειγματοληψία γραμμής υψηλής πυκνότητας
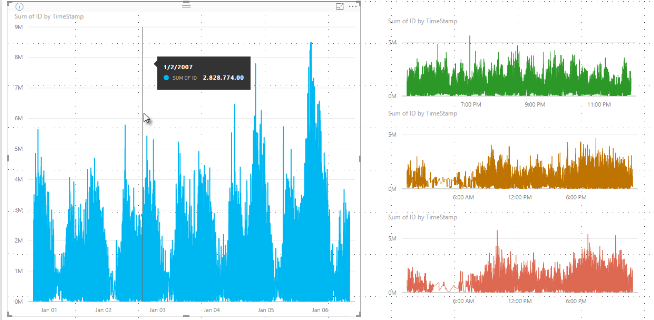
Στο παρελθόν, το Power BI είχε επιλέξει μια συλλογή δειγμάτων σημείων δεδομένων από όλο το εύρος των υποκείμενων δεδομένων με αιτιοκρατικό τρόπο. Για παράδειγμα, με τα δεδομένα υψηλής πυκνότητας σε μια απεικόνιση που εκτείνονται σε ένα ημερολογιακό έτος, ενδέχεται να υπάρχουν 350 δείγματα σημείων δεδομένων που εμφανίζονται στην απεικόνιση, κάθε ένα από τα οποία επιλέχθηκε για να διασφαλιστεί ότι όλο το εύρος των δεδομένων αντιπροσωπευόταν στην απεικόνιση. Για να κατανοήσετε πώς συμβαίνει αυτό, φανταστείτε ότι σχεδιάζετε τιμές μετοχών για μια περίοδο ενός έτους και επιλέγετε 365 σημεία δεδομένων για να δημιουργήσετε μια απεικόνιση γραφήματος γραμμών. Αυτό είναι ένα σημείο δεδομένων για κάθε ημέρα.
Σε αυτή την περίπτωση, υπάρχουν πολλές τιμές για μια τιμή μετοχών μέσα σε κάθε ημέρα. Φυσικά, υπάρχει μια ημερήσια υψηλή και χαμηλή τιμή, αλλά αυτές μπορούν να προκύψουν ανά πάσα στιγμή κατά τη διάρκεια της ημέρας, όταν το χρηματιστήριο είναι ανοιχτό. Για τη δειγματοληψία γραμμής υψηλής πυκνότητας, εάν το υποκείμενο δείγμα δεδομένων ληφθεί στις 10:30 π.μ. και 12:00 μ.μ. καθημερινά, θα λάβετε ένα αντιπροσωπευτικό στιγμιότυπο των υποκείμενων δεδομένων, όπως την τιμή στις 10:30 π.μ. και 12:00 Μ.Μ. Ωστόσο, το στιγμιότυπο μπορεί να μην καταγράφει την πραγματική υψηλή και χαμηλή τιμή της μετοχής για αυτό το αντιπροσωπευτικό σημείο δεδομένων εκείνη την ημέρα. Σε αυτή την περίπτωση, αλλά και σε άλλες, η δειγματοληψία είναι αντιπροσωπευτική των υποκείμενων δεδομένων, αλλά δεν καταγράφει πάντα σημαντικά σημεία, τα οποία στη συγκεκριμένη περίπτωση θα ήταν οι υψηλές και οι χαμηλές ημερήσιες τιμές των μετοχών.
Εξ ορισμού, η δειγματοληψία δεδομένων υψηλής πυκνότητας πραγματοποιείται για τη γρήγορη δημιουργία απεικονίσεων που ανταποκρίνονται στην αλληλεπίδραση. Η ύπαρξη πάρα πολλών σημείων δεδομένων σε μια απεικόνιση μπορεί να την δυσαναγκάσει και μπορεί να αποσπά την προσοχή από τις τάσεις. Ο τρόπος δειγματοληψίας των δεδομένων είναι η βάση για τη δημιουργία του αλγόριθμου δειγματοληψίας, προκειμένου να παρέχεται η καλύτερη εμπειρία απεικόνισης. Στο Power BI Desktop, ο αλγόριθμος παρέχει τον καλύτερο συνδυασμό ανταπόκρισης, απεικόνισης και σαφούς διατήρησης των σημαντικών σημείων σε κάθε χρονική περίοδο.
Πώς λειτουργεί ο νέος αλγόριθμος δειγματοληψίας γραμμής
Ο αλγόριθμος δειγματοληψίας γραμμής υψηλής πυκνότητας είναι διαθέσιμος για απεικονίσεις γραφήματος γραμμών και γραφήματος περιοχών με συνεχή άξονα x.
Για μια απεικόνιση υψηλής πυκνότητας, το Power BI τεμαχίσει με έξυπνο τρόπο τα δεδομένα σας σε τμήματα υψηλής ανάλυσης και, στη συνέχεια, επιλέγει σημαντικά σημεία για να αναπαραστήσει κάθε τμήμα. Αυτή η διαδικασία τεμαχισμού δεδομένων υψηλής ανάλυσης έχει ρυθμιστεί ώστε να διασφαλίζει ότι το γράφημα που προκύπτει είναι οπτικά μη διακριτό από ότι αν αποδίδονταν όλα τα υποκείμενα σημεία δεδομένων, αλλά είναι ταχύτερο και πιο αλληλεπιδραστικό.
Ελάχιστες και μέγιστες τιμές για απεικονίσεις γραμμής υψηλής πυκνότητας
Για οποιαδήποτε απεικόνιση, ισχύουν οι ακόλουθοι περιορισμοί:
3.500 είναι ο μέγιστος αριθμός σημείων δεδομένων που εμφανίζονται στις περισσότερες απεικονίσεις, ανεξάρτητα από τον αριθμό των υποκείμενων σημείων δεδομένων ή τις σειρές, ανατρέξτε στις εξαιρέσεις στην παρακάτω λίστα. Για παράδειγμα, εάν έχετε 10 σειρές με 350 σημεία δεδομένων η κάθε μία, η απεικόνιση έχει συμπληρώσει το μέγιστο συνολικό όριο σημείων δεδομένων. Εάν έχετε μία σειρά, μπορεί να έχει έως 3.500 σημεία δεδομένων εάν ο αλγόριθμος κρίνει ότι αυτή είναι η καλύτερη δειγματοληψία για τα υποκείμενα δεδομένα.
Υπάρχει ένα μέγιστο 60 σειρών για οποιαδήποτε απεικόνιση. Εάν έχετε περισσότερες από 60 σειρές, διασπάστε τα δεδομένα και δημιουργήστε πολλές απεικονίσεις με 60 ή λιγότερες σειρές η κάθε μία. Είναι καλή πρακτική να χρησιμοποιείτε έναν αναλυτή για να εμφανίσετε μόνο τμήματα των δεδομένων, αλλά μόνο για ορισμένες σειρές. Για παράδειγμα, εάν εμφανίζετε όλες τις υποκατηγορίες στο υπόμνημα, μπορείτε να χρησιμοποιήσετε έναν αναλυτή για να φιλτράρετε με βάση τη συνολική κατηγορία στην ίδια σελίδα αναφοράς.
Ο μέγιστος αριθμός ορίων δεδομένων είναι υψηλότερος για τους ακόλουθους τύπους απεικονίσεων, οι οποίοι αποτελούν εξαιρέσεις στο όριο των 3.500 σημείων δεδομένων:
- Μέγιστος αριθμός 150.000 σημείων δεδομένων για απεικονίσεις R.
- 30.000 σημεία δεδομένων για απεικονίσεις χάρτη Azure.
- 10.000 σημεία δεδομένων για ορισμένες ρυθμίσεις παραμέτρων γραφήματος διασποράς (η προεπιλογή είναι τα γραφήματα διασποράς είναι 3500).
- 3.500 για όλες τις άλλες απεικονίσεις με δειγματοληψία υψηλής πυκνότητας. Ορισμένες άλλες απεικονίσεις μπορεί να απεικονίζουν περισσότερα δεδομένα, αλλά δεν θα χρησιμοποιούν δειγματοληψία.
Αυτές οι παράμετροι εξασφαλίζουν ότι οι απεικονίσεις στο Power BI Desktop αποδίδονται γρήγορα, ανταποκρίνονται στην αλληλεπίδραση με τους χρήστες και δεν οδηγούν σε άσκοπη υπολογιστική επιβάρυνση στον υπολογιστή που αποδίδει την απεικόνιση.
Αξιολόγηση αντιπροσωπευτικών σημείων δεδομένων για απεικονίσεις γραμμής υψηλής πυκνότητας
Όταν ο αριθμός των υποκείμενων σημείων δεδομένων υπερβαίνει το μέγιστο πλήθος σημείων δεδομένων που μπορούν να αναπαρασταθούν στην απεικόνιση, ξεκινά μια διαδικασία που ονομάζεται αποθήκευση δεδομένων σε κάδους. Η τοποθέτηση σε κάδους διαιρεί τα υποκείμενα δεδομένα σε ομάδες που ονομάζονται κάδοι και, στη συνέχεια, βελτιώνει επαναληπτικά αυτούς τους κάδους.
Ο αλγόριθμος δημιουργεί όσο το δυνατόν περισσότερους κάδους για να δημιουργήσει τις μεγαλύτερες λεπτομέρειες για την απεικόνιση. Μέσα σε κάθε κάδο, ο αλγόριθμος εντοπίζει την ελάχιστη και τη μέγιστη τιμή δεδομένων για να εξασφαλίσει ότι σημαντικές τιμές, όπως τα έκτοπα, καταγράφονται και εμφανίζονται στην απεικόνιση. Με βάση τα αποτελέσματα της αποθήκευσης δεδομένων σε κάδους και της επακόλουθης αξιολόγησης των δεδομένων από το Power BI, προσδιορίζεται η ελάχιστη ανάλυση για τον άξονα x για την απεικόνιση, ώστε να διασφαλιστεί το μέγιστο επίπεδο υποδιαίρεσης για την απεικόνιση.
Όπως αναφέρθηκε προηγουμένως, η ελάχιστη υποδιαίρεση για κάθε σειρά είναι 350 σημεία και η μέγιστη τιμή είναι 3.500 για τις περισσότερες απεικονίσεις. Οι εξαιρέσεις παρατίθενται στις προηγούμενες παραγράφους.
Κάθε κάδος αντιπροσωπεύεται από δύο σημεία δεδομένων, τα οποία αποτελούν τα αντιπροσωπευτικά σημεία δεδομένων του κάδου στην απεικόνιση. Τα σημεία δεδομένων είναι η υψηλή και χαμηλή τιμή για αυτόν τον κάδο. Επιλέγοντας την υψηλή και τη χαμηλή τιμή, η διαδικασία αποθήκευσης δεδομένων σε κάδους εξασφαλίζει ότι οποιαδήποτε σημαντική υψηλή τιμή ή σημαντική χαμηλή τιμή καταγράφεται και αποδίδεται στην απεικόνιση.
Εάν αυτό μοιάζει να είναι πολλή ανάλυση για την καταγραφή μιας περιστασιακής ακραίας τιμής και τη σωστή εμφάνισή της στην απεικόνιση, έχετε δίκιο. Αυτός ακριβώς είναι ο λόγος για τον αλγόριθμο και τη διαδικασία αποθήκευσης δεδομένων σε κάδους.
Συμβουλές εργαλείων και δειγματοληψία γραμμής υψηλής πυκνότητας
Είναι σημαντικό να έχετε υπόψη ότι αυτή η διαδικασία αποθήκευσης δεδομένων σε κάδους, η οποία έχει ως αποτέλεσμα την καταγραφή και την εμφάνιση της ελάχιστης και μέγιστης τιμής κάθε κάδου, μπορεί να επηρεάσει τον τρόπο εμφάνισης των δεδομένων στις συμβουλές εργαλείων κατά την τοποθέτηση του δείκτη του ποντικιού επάνω στα σημεία δεδομένων. Για να εξηγήσουμε πώς και γιατί συμβαίνει αυτό, ας δούμε ξανά το παράδειγμα με τις τιμές μετοχών.
Ας υποθέσουμε ότι δημιουργείτε μια απεικόνιση με βάση τις τιμές των μετοχών και ότι συγκρίνετε δύο διαφορετικές μετοχές που χρησιμοποιούν δειγματοληψία υψηλής πυκνότητας. Τα υποκείμενα δεδομένα για κάθε σειρά έχουν πολλά σημεία δεδομένων. Για παράδειγμα, ίσως καταγράφετε την τιμή της μετοχής κάθε δευτερόλεπτο της ημέρας. Ο αλγόριθμος δειγματοληψίας γραμμής υψηλής πυκνότητας εκτελεί αποθήκευση δεδομένων σε κάδους για κάθε σειρά ανεξάρτητα.
Τώρα, ας υποθέσουμε ότι η τιμή της πρώτης μετοχής αυξάνεται χύμα στις 12:02 και, στη συνέχεια, επιστρέφει γρήγορα 10 δευτερόλεπτα αργότερα. Αυτό είναι ένα σημαντικό σημείο δεδομένων. Κατά την αποθήκευση σε κάδους για αυτή τη μετοχή, η υψηλή τιμή στις 12:02 είναι ένα αντιπροσωπευτικό σημείο δεδομένων για αυτόν τον κάδο.
Ωστόσο, για τη δεύτερη μετοχή, η τιμή στις 12:02 δεν ήταν υψηλή ούτε χαμηλή για τον κάδο που περιλάμβανε αυτό το χρονικό διάστημα. Ίσως η υψηλή και η χαμηλή τιμή για τον κάδο που περιλαμβάνει τις 12:02 να παρουσιάστηκε τρία λεπτά αργότερα. Σε αυτή την περίπτωση, όταν δημιουργηθεί το γράφημα γραμμών και τοποθετήσετε τον δείκτη επάνω στις 12:02, θα δείτε μια τιμή στη συμβουλή εργαλείου για την πρώτη μετοχή. Αυτό συμβαίνει επειδή ανέβηκε στις 12:02 και αυτή η τιμή επιλέχθηκε ως το υψηλό σημείο δεδομένων αυτού του κάδου. Ωστόσο, δεν θα δείτε καμία τιμή στη συμβουλή εργαλείου στις 12:02 για τη δεύτερη μετοχή. Αυτό συμβαίνει επειδή η δεύτερη μετοχή δεν είχε υψηλή ή χαμηλή τιμή για τον κάδο που περιλάμβανε την ώρα 12:02. Επομένως, δεν υπάρχουν δεδομένα για εμφάνιση για τη δεύτερη μετοχή στις 12:02 και, επομένως, δεν εμφανίζονται δεδομένα συμβουλής εργαλείου.
Αυτή η κατάσταση θα συμβαίνει συχνά με τις συμβουλές εργαλείων. Οι υψηλές και χαμηλές τιμές για έναν συγκεκριμένο κάδο πιθανώς δεν θα ταιριάζουν απόλυτα με τα ομοιόμορφα κλιμακώνονται σημεία τιμών του άξονα x και η συμβουλή εργαλείου δεν εμφανίζει την τιμή.
Πώς μπορείτε να ενεργοποιήσετε τη δειγματοληψία γραμμής υψηλής πυκνότητας
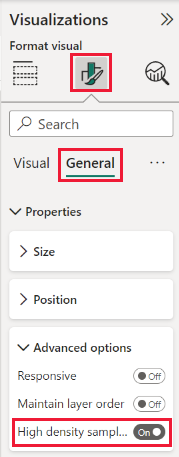
Από προεπιλογή, ο αλγόριθμος είναι στη θέση Ενεργό. Για να αλλάξετε αυτήν τη ρύθμιση, μεταβείτε στο τμήμα παραθύρου Μορφοποίηση , στην κάρτα Γενικά και στο κάτω μέρος βλέπετε το ρυθμιστικό δειγματοληψίας υψηλής πυκνότητας. Επιλέξτε το ρυθμιστικό για να ενεργοποιήσετε ή να απενεργοποιήσετε.
Ζητήματα προς εξέταση και περιορισμοί
Ο αλγόριθμος δειγματοληψίας γραμμής υψηλής πυκνότητας αποτελεί σημαντική βελτίωση στο Power BI, αλλά υπάρχουν ορισμένα ζητήματα που πρέπει να γνωρίζετε όταν εργάζεστε με τιμές και δεδομένα υψηλής πυκνότητας.
Λόγω της αυξημένης υποδιαίρεσης και της διαδικασίας αποθήκευσης δεδομένων σε κάδους, οι συμβουλές εργαλείων μπορεί να εμφανίζουν μια τιμή μόνο εάν τα αντιπροσωπευτικά δεδομένα είναι ευθυγραμμισμένα με τον δρομέα σας. Για περισσότερες πληροφορίες, ανατρέξτε στην ενότητα Συμβουλές εργαλείων και δειγματοληψία γραμμής υψηλής πυκνότητας σε αυτό το άρθρο.
Όταν το μέγεθος μιας συνολικής προέλευσης δεδομένων είναι πολύ μεγάλο, ο αλγόριθμος εξαλείφει σειρές (στοιχεία υπομνήματος) προκειμένου να ικανοποιήσει τον περιορισμό μέγιστης εισαγωγής δεδομένων.
- Σε αυτή την περίπτωση, ο αλγόριθμος ταξινομεί τις σειρές υπομνήματος αλφαβητικά, ξεκινώντας από τη λίστα των στοιχείων υπομνήματος με αλφαβητική σειρά μέχρι να επιτευχθεί το μέγιστο όριο εισαγωγής δεδομένων και δεν εισάγει άλλες σειρές.
Όταν ένα υποκείμενο σύνολο δεδομένων έχει περισσότερες από 60 σειρές, ο μέγιστος αριθμός σειρών, ο αλγόριθμος ταξινομεί τις σειρές αλφαβητικά και εξαλείφει τις σειρές πέρα από την 60η αλφαβητική σειρά.
Εάν οι τιμές στα δεδομένα δεν είναι τύπου αριθμητικές ή ημερομηνίας/ώρας, το Power BI δεν θα χρησιμοποιήσει τον αλγόριθμο και θα επιστρέψει στον προηγούμενο αλγόριθμο δειγματοληψίας μη υψηλής πυκνότητας.
Η ρύθμιση Εμφάνιση στοιχείων χωρίς δεδομένα δεν υποστηρίζεται με τον αλγόριθμο.
Ο αλγόριθμος δεν υποστηρίζεται κατά τη χρήση μιας δυναμικής σύνδεσης σε ένα μοντέλο που φιλοξενείται Υπηρεσίες ανάλυσης του SQL Server έκδοση 2016 ή παλαιότερη. Υποστηρίζεται σε μοντέλα που φιλοξενούνται στο Power BI ή το Υπηρεσίες Ανάλυσης του Azure.