Create and configure an availability group for SQL Server on Linux
Applies to: ![]() SQL Server - Linux
SQL Server - Linux
This tutorial covers how to create and configure an availability group (AG) for SQL Server on Linux. Unlike SQL Server 2016 (13.x) and earlier on Windows, you can enable an AG with or without creating the underlying Pacemaker cluster first. Integration with the cluster, if needed, isn't done until later.
The tutorial includes the following tasks:
- Enable availability groups.
- Create availability group endpoints and certificates.
- Use SQL Server Management Studio (SSMS) or Transact-SQL to create an availability group.
- Create the SQL Server login and permissions for Pacemaker.
- Create availability group resources in a Pacemaker cluster (External type only).
Prerequisites
Deploy the Pacemaker high availability cluster as described in Deploy a Pacemaker cluster for SQL Server on Linux.
Enable the availability groups feature
Unlike on Windows, you can't use PowerShell or SQL Server Configuration Manager to enable the availability groups (AG) feature. Under Linux, you must use mssql-conf to enable the feature. There are two ways to enable the availability groups feature: use the mssql-conf utility, or edit the mssql.conf file manually.
Important
The AG feature must be enabled for configuration-only replicas, even on SQL Server Express.
Use the mssql-conf utility
At a prompt, issue the following command:
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
Edit the mssql.conf file
You can also modify the mssql.conf file, located under the /var/opt/mssql folder, to add the following lines:
[hadr]
hadr.hadrenabled = 1
Restart SQL Server
After enabling availability groups, as on Windows, you must restart SQL Server, using the following command:
sudo systemctl restart mssql-server
Create the availability group endpoints and certificates
An availability group uses TCP endpoints for communication. Under Linux, endpoints for an AG are only supported if certificates are used for authentication. You must restore the certificate from one instance on all other instances that will participate as replicas in the same AG. The certificate process is required even for a configuration-only replica.
Creating endpoints and restoring certificates can only be done via Transact-SQL. You can use non-SQL Server-generated certificates as well. You also need a process to manage and replace any certificates that expire.
Important
If you plan to use the SQL Server Management Studio wizard to create the AG, you still need to create and restore the certificates by using Transact-SQL on Linux.
For full syntax on the options available for the various commands (including security), consult:
Note
Although you're creating an availability group, the type of endpoint uses FOR DATABASE_MIRRORING, because some underlying aspects were once shared with that now-deprecated feature.
This example creates certificates for a three-node configuration. The instance names are LinAGN1, LinAGN2, and LinAGN3.
Execute the following script on
LinAGN1to create the master key, certificate, and endpoint, and back up the certificate. For this example, the typical TCP port of 5022 is used for the endpoint.CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<StrongPassword>'; GO CREATE CERTIFICATE LinAGN1_Cert WITH SUBJECT = 'LinAGN1 AG Certificate'; GO BACKUP CERTIFICATE LinAGN1_Cert TO FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING(AUTHENTICATION = CERTIFICATE LinAGN1_Cert, ROLE = ALL); GODo the same on
LinAGN2:CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<StrongPassword>'; GO CREATE CERTIFICATE LinAGN2_Cert WITH SUBJECT = 'LinAGN2 AG Certificate'; GO BACKUP CERTIFICATE LinAGN2_Cert TO FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN2_Cert, ROLE = ALL); GOFinally, perform the same sequence on
LinAGN3:CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<StrongPassword>'; GO CREATE CERTIFICATE LinAGN3_Cert WITH SUBJECT = 'LinAGN3 AG Certificate'; GO BACKUP CERTIFICATE LinAGN3_Cert TO FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING(AUTHENTICATION = CERTIFICATE LinAGN3_Cert, ROLE = ALL); GOUsing
scpor another utility, copy the backups of the certificate to each node that will be part of the AG.For this example:
- Copy
LinAGN1_Cert.certoLinAGN2andLinAGN3. - Copy
LinAGN2_Cert.certoLinAGN1andLinAGN3. - Copy
LinAGN3_Cert.certoLinAGN1andLinAGN2.
- Copy
Change ownership and the group associated with the copied certificate files to
mssql.sudo chown mssql:mssql <CertFileName>Create the instance-level logins and users associated with
LinAGN2andLinAGN3onLinAGN1.CREATE LOGIN LinAGN2_Login WITH PASSWORD = '<StrongPassword>'; CREATE USER LinAGN2_User FOR LOGIN LinAGN2_Login; GO CREATE LOGIN LinAGN3_Login WITH PASSWORD = '<StrongPassword>'; CREATE USER LinAGN3_User FOR LOGIN LinAGN3_Login; GORestore
LinAGN2_CertandLinAGN3_CertonLinAGN1. Having the other replicas' certificates is an important aspect of AG communication and security.CREATE CERTIFICATE LinAGN2_Cert AUTHORIZATION LinAGN2_User FROM FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GO CREATE CERTIFICATE LinAGN3_Cert AUTHORIZATION LinAGN3_User FROM FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GOGrant the logins associated with
LinAG2andLinAGN3permission to connect to the endpoint onLinAGN1.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN2_Login; GO GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN3_Login; GOCreate the instance-level logins and users associated with
LinAGN1andLinAGN3onLinAGN2.CREATE LOGIN LinAGN1_Login WITH PASSWORD = '<StrongPassword>'; CREATE USER LinAGN1_User FOR LOGIN LinAGN1_Login; GO CREATE LOGIN LinAGN3_Login WITH PASSWORD = '<StrongPassword>'; CREATE USER LinAGN3_User FOR LOGIN LinAGN3_Login; GORestore
LinAGN1_CertandLinAGN3_CertonLinAGN2.CREATE CERTIFICATE LinAGN1_Cert AUTHORIZATION LinAGN1_User FROM FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE CERTIFICATE LinAGN3_Cert AUTHORIZATION LinAGN3_User FROM FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GOGrant the logins associated with
LinAG1andLinAGN3permission to connect to the endpoint onLinAGN2.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN1_Login; GO GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN3_Login; GOCreate the instance-level logins and users associated with
LinAGN1andLinAGN2onLinAGN3.CREATE LOGIN LinAGN1_Login WITH PASSWORD = '<StrongPassword>'; CREATE USER LinAGN1_User FOR LOGIN LinAGN1_Login; GO CREATE LOGIN LinAGN2_Login WITH PASSWORD = '<StrongPassword>'; CREATE USER LinAGN2_User FOR LOGIN LinAGN2_Login; GORestore
LinAGN1_CertandLinAGN2_CertonLinAGN3.CREATE CERTIFICATE LinAGN1_Cert AUTHORIZATION LinAGN1_User FROM FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE CERTIFICATE LinAGN2_Cert AUTHORIZATION LinAGN2_User FROM FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GOGrant the logins associated with
LinAG1andLinAGN2permission to connect to the endpoint onLinAGN3.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN1_Login; GO GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN2_Login; GO
Create the availability group
This section covers how to use SQL Server Management Studio (SSMS) or Transact-SQL to create the availability group for SQL Server.
Use SQL Server Management Studio
This section shows how to create an AG with a cluster type of External using SSMS with the New Availability Group Wizard.
In SSMS, expand Always On High Availability, right-click Availability Groups, and select New Availability Group Wizard.
On the Introduction dialog, select Next.
In the Specify Availability Group Options dialog, enter a name for the availability group, and select a cluster type of
EXTERNALorNONEin the dropdown list. External should be used when Pacemaker will be deployed. None is for specialized scenarios, such as read scale-out. Selecting the option for database level health detection is optional. For more information on this option, see Availability group database level health detection failover option. Select Next.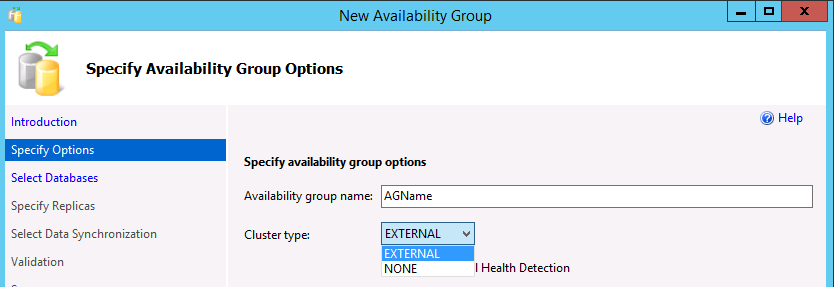
In the Select Databases dialog, select the databases that will participate in the AG. Each database must have a full backup before it can be added to an AG. Select Next.
In the Specify Replicas dialog, select Add Replica.
In the Connect to Server dialog, enter the name of the Linux instance of SQL Server that will be the secondary replica, and the credentials to connect. Select Connect.
Repeat the previous two steps for the instance that will contain a configuration-only replica or another secondary replica.
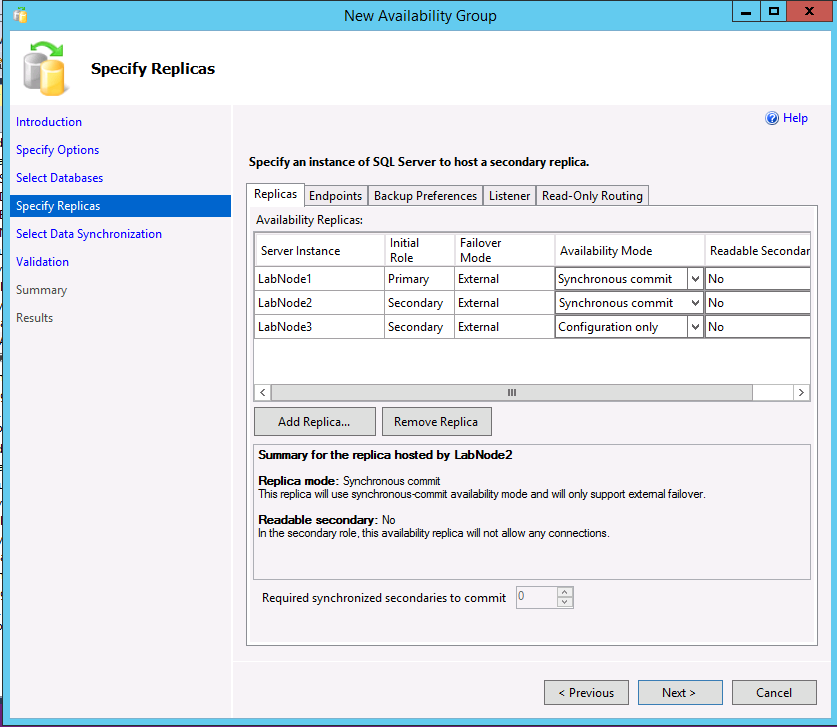
All three instances should now be listed on the Specify Replicas dialog. If using a cluster type of External, for the secondary replica that will be a true secondary, make sure the Availability Mode matches that of the primary replica and failover mode is set to External. For the configuration-only replica, select an availability mode of Configuration only.
The following example shows an AG with two replicas, a cluster type of External, and a configuration-only replica.
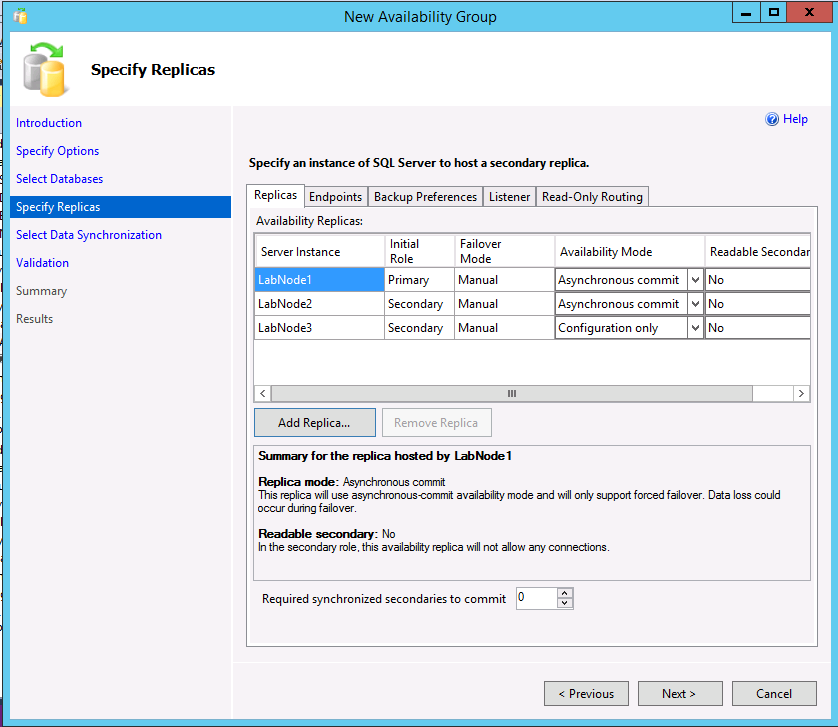
The following example shows an AG with two replicas, a cluster type of None, and a configuration-only replica.
If you want to alter the backup preferences, select the Backup Preferences tab. For more information on backup preferences with AGs, see Configure backups on secondary replicas of an Always On availability group.
If using readable secondaries or creating an AG with a cluster type of None for read-scale, you can create a listener by selecting the Listener tab. A listener can also be added later. To create a listener, choose the option Create an availability group listener and enter a name, a TCP/IP port, and whether to use a static or automatically assigned DHCP IP address. Remember that for an AG with a cluster type of None, the IP should be static and set to the primary's IP address.
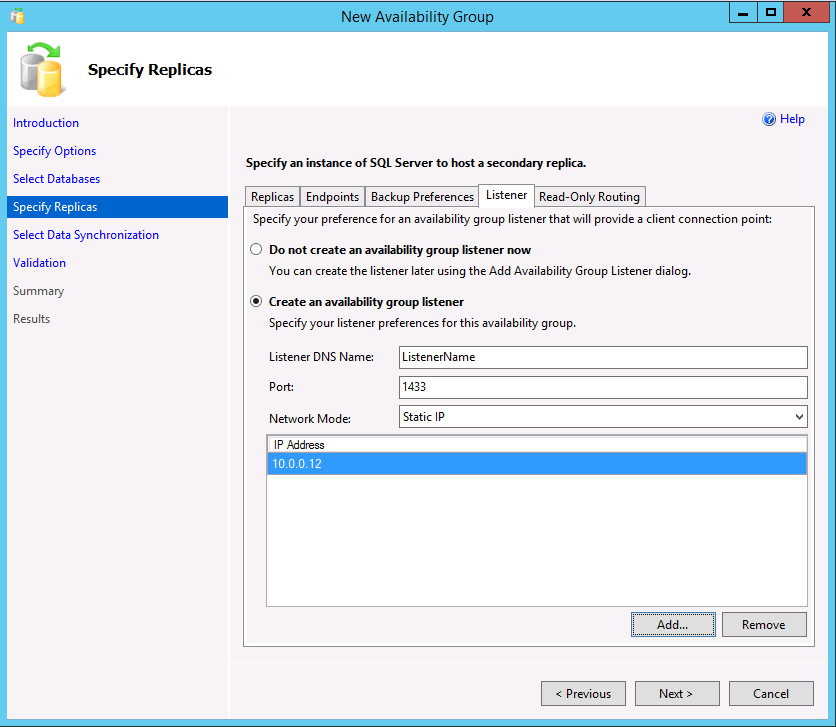
If a listener is created for readable scenarios, SSMS 17.3 or later allows the creation of the read-only routing in the wizard. It can also be added later via SSMS or Transact-SQL. To add read-only routing now:
Select the Read-Only Routing tab.
Enter the URLs for the read-only replicas. These URLs are similar to the endpoints, except they use the port of the instance, not the endpoint.
Select each URL and from the bottom, select the readable replicas. To multi-select, hold down SHIFT or select-drag.
Select Next.
Choose how the secondary replicas will be initialized. The default is to use automatic seeding, which requires the same path on all servers participating in the AG. You can also have the wizard do a backup, copy, and restore (the second option); have it join if you have manually backed up, copied, and restored the database on the replicas (third option); or add the database later (last option). As with certificates, if you're manually making backups and copying them, permissions on the backup files needs to be set on the other replicas. Select Next.
On the Validation dialog, if everything doesn't come back as Success, investigate. Some warnings are acceptable and not fatal, such as if you don't create a listener. Select Next.
On the Summary dialog, select Finish. The process to create the AG now begins.
When the AG creation is complete, select Close on the Results. You can now see the AG on the replicas in the dynamic management views, and under the Always On High Availability folder in SSMS.




Use Transact-SQL
This section shows examples of creating an AG using Transact-SQL. The listener and read-only routing can be configured after the AG is created. The AG itself can be modified with ALTER AVAILABILITY GROUP, but changing the cluster type can't be done in SQL Server 2017 (14.x). If you didn't mean to create an AG with a cluster type of External, you must delete it and recreate it with a cluster type of None. More information and other options can be found at the following links:
- CREATE AVAILABILITY GROUP (Transact-SQL)
- ALTER AVAILABILITY GROUP (Transact-SQL)
- Configure read-only routing for an Always On availability group
- Configure a listener for an Always On availability group
Example A: Two replicas with a configuration-only replica (External cluster type)
This example shows how to create a two-replica AG that uses a configuration-only replica.
Execute on the node that will be the primary replica containing the fully read/write copy of the databases. This example uses automatic seeding.
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = EXTERNAL) FOR DATABASE <DBName> REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N' TCP://LinAGN1.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC), N'LinAGN3' WITH ( ENDPOINT_URL = N'TCP://LinAGN3.FullyQualified.Name:5022', AVAILABILITY_MODE = CONFIGURATION_ONLY); GOIn a query window connected to the other replica, execute the following to join the replica to the AG and initiate the seeding process from the primary to the secondary replica.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GOIn a query window connected to the configuration only replica, join it to the AG.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO
Example B: Three replicas with read-only routing (External cluster type)
This example shows three full replicas and how read-only routing can be configured as part of the initial AG creation.
Execute on the node that will be the primary replica containing the fully read/write copy of the databases. This example uses automatic seeding.
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = EXTERNAL) FOR DATABASE < DBName > REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N'TCP://LinAGN1.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN2.FullyQualified.Name', 'LinAGN3.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN1.FullyQualified.Name:1433') ), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN1.FullyQualified.Name', 'LinAGN3.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN2.FullyQualified.Name:1433') ), N'LinAGN3' WITH ( ENDPOINT_URL = N'TCP://LinAGN3.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN1.FullyQualified.Name', 'LinAGN2.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN3.FullyQualified.Name:1433') ) LISTENER '<ListenerName>' ( WITH IP = ('<IPAddress>', '<SubnetMask>'), Port = 1433 ); GOA few things to note about this configuration:
AGNameis the name of the availability group.DBNameis the name of the database that is used with the availability group. It can also be a list of names separated by commas.ListenerNameis a name that is different than any of the underlying servers/nodes. It will be registered in DNS along withIPAddress.IPAddressis an IP address that is associated withListenerName. It's also unique and not the same as any of the servers/nodes. Applications and end users use eitherListenerNameorIPAddressto connect to the AG.SubnetMaskis the subnet mask ofIPAddress. In SQL Server 2019 (15.x) and previous versions, this is255.255.255.255. In SQL Server 2022 (16.x) and later versions, this is0.0.0.0.
In a query window connected to the other replica, execute the following to join the replica to the AG and initiate the seeding process from the primary to the secondary replica.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GORepeat Step 2 for the third replica.
Example C: Two replicas with read-only routing (None cluster type)
This example shows the creation of a two-replica configuration using a cluster type of None. It's used for the read scale scenario where no failover is expected. This creates the listener that is actually the primary replica, and the read-only routing, using the round robin functionality.
- Execute on the node that will be the primary replica containing the fully read/write copy of the databases. This example uses automatic seeding.
CREATE AVAILABILITY
GROUP [<AGName>]
WITH (CLUSTER_TYPE = NONE)
FOR DATABASE <DBName> REPLICA ON
N'LinAGN1' WITH (
ENDPOINT_URL = N'TCP://LinAGN1.FullyQualified.Name: <PortOfEndpoint>',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
PRIMARY_ROLE(
ALLOW_CONNECTIONS = READ_WRITE,
READ_ONLY_ROUTING_LIST = (('LinAGN1.FullyQualified.Name'.'LinAGN2.FullyQualified.Name'))
),
SECONDARY_ROLE(
ALLOW_CONNECTIONS = ALL,
READ_ONLY_ROUTING_URL = N'TCP://LinAGN1.FullyQualified.Name:<PortOfInstance>'
)
),
N'LinAGN2' WITH (
ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:<PortOfEndpoint>',
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC,
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = (
('LinAGN1.FullyQualified.Name',
'LinAGN2.FullyQualified.Name')
)),
SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN2.FullyQualified.Name:<PortOfInstance>')
),
LISTENER '<ListenerName>' (WITH IP = (
'<PrimaryReplicaIPAddress>',
'<SubnetMask>'),
Port = <PortOfListener>
);
GO
Where:
AGNameis the name of the availability group.DBNameis the name of the database that will be used with the availability group. It can also be a list of names separated by commas.PortOfEndpointis the port number used by the endpoint created.PortOfInstanceis the port number used by the instance of SQL Server.ListenerNameis a name that is different than any of the underlying replicas but isn't actually used.PrimaryReplicaIPAddressis the IP address of the primary replica.SubnetMaskis the subnet mask ofIPAddress. In SQL Server 2019 (15.x) and previous versions, this is255.255.255.255. In SQL Server 2022 (16.x) and later versions, this is0.0.0.0.
Join the secondary replica to the AG and initiate automatic seeding.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = NONE); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GO
Create the SQL Server login and permissions for Pacemaker
A Pacemaker high availability cluster underlying SQL Server on Linux needs access to the SQL Server instance, and permissions on the availability group itself. These steps create the login and the associated permissions, along with a file that tells Pacemaker how to log into SQL Server.
In a query window connected to the first replica, execute the following script:
CREATE LOGIN PMLogin WITH PASSWORD ='<StrongPassword>'; GO GRANT VIEW SERVER STATE TO PMLogin; GO GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::<AGThatWasCreated> TO PMLogin; GOOn Node 1, enter the command
sudo emacs /var/opt/mssql/secrets/passwdThis opens the Emacs editor.
Enter the following two lines into the editor:
PMLogin <StrongPassword>Hold down the
Ctrlkey, then pressX, thenC, to exit and save the file.Execute
sudo chmod 400 /var/opt/mssql/secrets/passwdto lock down the file.
Repeat Steps 1-5 on the other servers that will serve as replicas.
Create the availability group resources in the Pacemaker cluster (External only)
After an availability group is created in SQL Server, the corresponding resources must be created in Pacemaker, when a cluster type of External is specified. There are two resources associated with an AG: the AG itself and an IP address. Configuring the IP address resource is optional if you aren't using the listener functionality, but is recommended.
The AG resource you created is a type of resource called a clone. The AG resource essentially has copies on each node, and there's one controlling resource called the master. The master is associated with the server hosting the primary replica. The other resources host secondary replicas (regular or configuration-only) and can be promoted to master in a failover.
Note
Bias-free communication
This article contains references to the term slave, a term Microsoft considers offensive when used in this context. The term appears in this article because it currently appears in the software. When the term is removed from the software, we will remove it from the article.
Create the AG resource with the following syntax:
sudo pcs resource create <NameForAGResource> ocf:mssql:ag ag_name=<AGName> meta failure-timeout=30s --master meta notify=trueWhere
NameForAGResourceis the unique name given to this cluster resource for the AG, andAGNameis the name of the AG that was created.On RHEL 7.7 and Ubuntu 18.04, and later versions, you might encounter a warning with the use of
--master, or an error likesqlag_monitor_0 on ag1 'not configured' (6): call=6, status=complete, exitreason='Resource must be configured with notify=true'. To avoid this situation, use:sudo pcs resource create <NameForAGResource> ocf:mssql:ag ag_name=<AGName> meta failure-timeout=30s master notify=trueCreate the IP address resource for the AG that will be associated with the listener functionality.
sudo pcs resource create <NameForIPResource> ocf:heartbeat:IPaddr2 ip=<IPAddress> cidr_netmask=<Netmask>Where
NameForIPResourceis the unique name for the IP resource, andIPAddressis the static IP address assigned to the resource.To ensure that the IP address and the AG resource are running on the same node, a colocation constraint must be configured.
sudo pcs constraint colocation add <NameForIPResource> <NameForAGResource>-master INFINITY with-rsc-role=MasterWhere
NameForIPResourceis the name for the IP resource, andNameForAGResourceis the name for the AG resource.Create an ordering constraint to ensure that the AG resource is up and running before the IP address. While the colocation constraint implies an ordering constraint, this enforces it.
sudo pcs constraint order promote <NameForAGResource>-master then start <NameForIPResource>Where
NameForIPResourceis the name for the IP resource, andNameForAGResourceis the name for the AG resource.
Next step
In this tutorial, you learned how to create and configure an availability group for SQL Server on Linux. You learned how to:
- Enable availability groups.
- Create AG endpoints and certificates.
- Use SQL Server Management Studio (SSMS) or Transact-SQL to create an AG.
- Create the SQL Server login and permissions for Pacemaker.
- Create AG resources in a Pacemaker cluster.
For most AG administration tasks, including upgrades and failing over, see: