AI enrichment in Azure AI Search
In Azure AI Search, AI enrichment refers to integration with Azure AI services to process content that isn't searchable in its raw form. Through enrichment, analysis and inference are used to create searchable content and structure where none previously existed.
Because Azure AI Search is a text and vector search solution, the purpose of AI enrichment is to improve the utility of your content in search-related scenarios. Source content must be textual (you can't enrich vectors), but the content created by an enrichment pipeline can be vectorized and indexed in a vector index using skills like Text Split skill for chunking and AzureOpenAIEmbedding skill for encoding.
AI enrichment is based on skills.
Built-in skills tap Azure AI services. They apply the following transformations and processing to raw content:
- Translation and language detection for multi-lingual search
- Entity recognition to extract people names, places, and other entities from large chunks of text
- Key phrase extraction to identify and output important terms
- Optical Character Recognition (OCR) to recognize printed and handwritten text in binary files
- Image analysis to describe image content, and output the descriptions as searchable text fields
Custom skills run your external code. Custom skills can be used for any custom processing that you want to include in the pipeline.
AI enrichment is an extension of an indexer pipeline that connects to Azure data sources. An enrichment pipeline has all of the components of an indexer pipeline (indexer, data source, index), plus a skillset that specifies atomic enrichment steps.
The following diagram shows the progression of AI enrichment:
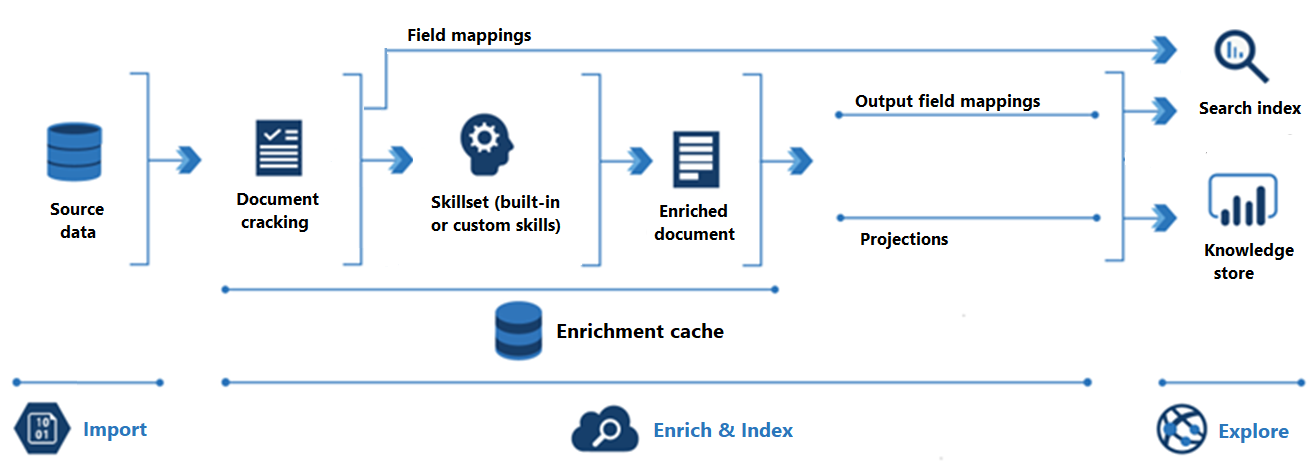
Import is the first step. Here, the indexer connects to a data source and pulls content (documents) into the search service. Azure Blob Storage is the most common resource used in AI enrichment scenarios, but any supported data source can provide content.
Enrich & Index covers most of the AI enrichment pipeline:
Enrichment starts when the indexer "cracks documents" and extracts images and text. The kind of processing that occurs next depends on your data and which skills you've added to a skillset. If you have images, they can be forwarded to skills that perform image processing. Text content is queued for text and natural language processing. Internally, skills create an "enriched document" that collects the transformations as they occur.
Enriched content is generated during skillset execution, and is temporary unless you save it. You can enable an enrichment cache to persist cracked documents and skill outputs for subsequent reuse during future skillset executions.
To get content into a search index, the indexer must have mapping information for sending enriched content to target field. Field mappings (explicit or implicit) set the data path from source data to a search index. Output field mappings set the data path from enriched documents to an index.
Indexing is the process wherein raw and enriched content is ingested into the physical data structures of a search index (its files and folders). Lexical analysis and tokenization occur in this step.
Exploration is the last step. Output is always a search index that you can query from a client app. Output can optionally be a knowledge store consisting of blobs and tables in Azure Storage that are accessed through data exploration tools or downstream processes. If you're creating a knowledge store, projections determine the data path for enriched content. The same enriched content can appear in both indexes and knowledge stores.
When to use AI enrichment
Enrichment is useful if raw content is unstructured text, image content, or content that needs language detection and translation. Applying AI through the built-in skills can unlock this content for full text search and data science applications.
You can also create custom skills to provide external processing. Open-source, third-party, or first-party code can be integrated into the pipeline as a custom skill. Classification models that identify salient characteristics of various document types fall into this category, but any external package that adds value to your content could be used.
Use-cases for built-in skills
Built-in skills are based on the Azure AI services APIs: Azure AI Computer Vision and Language Service. Unless your content input is small, expect to attach a billable Azure AI services resource to run larger workloads.
A skillset that's assembled using built-in skills is well suited for the following application scenarios:
Image processing skills include Optical Character Recognition (OCR) and identification of visual features, such as facial detection, image interpretation, image recognition (famous people and landmarks), or attributes like image orientation. These skills create text representations of image content for full text search in Azure AI Search.
Machine translation is provided by the Text Translation skill, often paired with language detection for multi-language solutions.
Natural language processing analyzes chunks of text. Skills in this category include Entity Recognition, Sentiment Detection (including opinion mining), and Personal Identifiable Information Detection. With these skills, unstructured text is mapped as searchable and filterable fields in an index.
Use-cases for custom skills
Custom skills execute external code that you provide and wrap in the custom skill web interface. Several examples of custom skills can be found in the azure-search-power-skills GitHub repository.
Custom skills aren’t always complex. For example, if you have an existing package that provides pattern matching or a document classification model, you can wrap it in a custom skill.
Storing output
In Azure AI Search, an indexer saves the output it creates. A single indexer run can create up to three data structures that contain enriched and indexed output.
| Data store | Required | Location | Description |
|---|---|---|---|
| searchable index | Required | Search service | Used for full text search and other query forms. Specifying an index is an indexer requirement. Index content is populated from skill outputs, plus any source fields that are mapped directly to fields in the index. |
| knowledge store | Optional | Azure Storage | Used for downstream apps like knowledge mining or data science. A knowledge store is defined within a skillset. Its definition determines whether your enriched documents are projected as tables or objects (files or blobs) in Azure Storage. |
| enrichment cache | Optional | Azure Storage | Used for caching enrichments for reuse in subsequent skillset executions. The cache stores imported, unprocessed content (cracked documents). It also stores the enriched documents created during skillset execution. Caching is helpful if you're using image analysis or OCR, and you want to avoid the time and expense of reprocessing image files. |
Indexes and knowledge stores are fully independent of each other. While you must attach an index to satisfy indexer requirements, if your sole objective is a knowledge store, you can ignore the index after it's populated.
Exploring content
After you've defined and loaded a search index or a knowledge store, you can explore its data.
Query a search index
Run queries to access the enriched content generated by the pipeline. The index is like any other you might create for Azure AI Search: you can supplement text analysis with custom analyzers, invoke fuzzy search queries, add filters, or experiment with scoring profiles to tune search relevance.
Use data exploration tools on a knowledge store
In Azure Storage, a knowledge store can assume the following forms: a blob container of JSON documents, a blob container of image objects, or tables in Table Storage. You can use Storage Explorer, Power BI, or any app that connects to Azure Storage to access your content.
A blob container captures enriched documents in their entirety, which is useful if you're creating a feed into other processes.
A table is useful if you need slices of enriched documents, or if you want to include or exclude specific parts of the output. For analysis in Power BI, tables are the recommended data source for data exploration and visualization in Power BI.
Availability and pricing
Enrichment is available in regions that have Azure AI services. You can check the availability of enrichment on the Azure products available by region page.
Billing follows a pay-as-you-go pricing model. The costs of using built-in skills are passed on when a multi-region Azure AI services key is specified in the skillset. There are also costs associated with image extraction, as metered by Azure AI Search. Text extraction and utility skills, however, aren't billable. For more information, see How you're charged for Azure AI Search.
Checklist: A typical workflow
An enrichment pipeline consists of indexers that have skillsets. Post-indexing, you can query an index to validate your results.
Start with a subset of data in a supported data source. Indexer and skillset design is an iterative process. The work goes faster with a small representative data set.
Create a data source that specifies a connection to your data.
Create a skillset. Unless your project is small, you should attach an Azure AI multi-service resource. If you're creating a knowledge store, define it within the skillset.
Create an index schema that defines a search index.
Create and run the indexer to bring all of the above components together. This step retrieves the data, runs the skillset, and loads the index.
An indexer is also where you specify field mappings and output field mappings that set up the data path to a search index.
Optionally, enable enrichment caching in the indexer configuration. This step allows you to reuse existing enrichments later on.
Run queries to evaluate results or start a debug session to work through any skillset issues.
To repeat any of the above steps, reset the indexer before you run it. Or, delete and recreate the objects on each run (recommended if you’re using the free tier). If you enabled caching the indexer pulls from the cache if data is unchanged at the source, and if your edits to the pipeline don't invalidate the cache.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for