Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Lakeflow Designer lets you build data transformation workflows on a visual, drag-and-drop canvas. This page explains how to create a visual data prep — from adding a data source and chaining operators to previewing results and writing to Unity Catalog.
Requirements
To use Lakeflow Designer, you must have:
- A Azure Databricks workspace with Unity Catalog enabled.
CAN USEpermission on at least one general purpose compute resource (serverless or all-purpose).
Select which compute to use from the compute picker in the top right of Designer, next to the Schedule button.
Create a new visual data prep
To create a new visual data prep, click ![]() New in the sidebar and select Visual data prep.
New in the sidebar and select Visual data prep.
Designer opens with a welcome screen where you can add a data source or explore a sample visual data prep.
Add a data source
Every visual data prep starts with one or more data sources. The Source operator represents a data source on the canvas.
To add a data source:
- Add a Source operator. From the welcome screen, click Select source operator. From the canvas, open the operator menu and select Source.
- In the Source configuration pane, choose how to bring in your data. You can browse for an existing table, upload a local CSV or Excel file, create a table from a file, or import from Google Drive or SharePoint.
- Select or configure your data source. The Source operator appears on the canvas.
You can also drag and drop a CSV or Excel file directly onto the canvas to quickly create a Source operator.
To change the source later, open the Source operator and click Select a new data source. Changing the source invalidates the output cache for all downstream operators.
For the full details on each ingestion option, see Ingest data into Lakeflow Designer.
Add and configure operators
To add an operator, open the operator menu in the side pane on the left side of the canvas. Click an operator to add it to the canvas, or drag an operator from the menu onto the canvas. You can also click the + button next to any existing operator to add a new operator with an automatic connection.

To configure an operator, double-click it, or hold the pointer over it and click ![]() (Edit operator), to open the configuration pane. Set the options for that operator type, then click Apply.
(Edit operator), to open the configuration pane. Set the options for that operator type, then click Apply.
For details on each available operator, see Built-in operators in Lakeflow Designer. For details on creating your own user-defined operators, see User-defined operators in Lakeflow Designer.
Connect operators
To connect two operators, click and drag from the output handle (the small circle on the right edge of an operator) to the input handle (the small circle on the left edge of the next operator). This specifies that data flows from the first operator into the second. Data flows from left to right through the visual data prep.
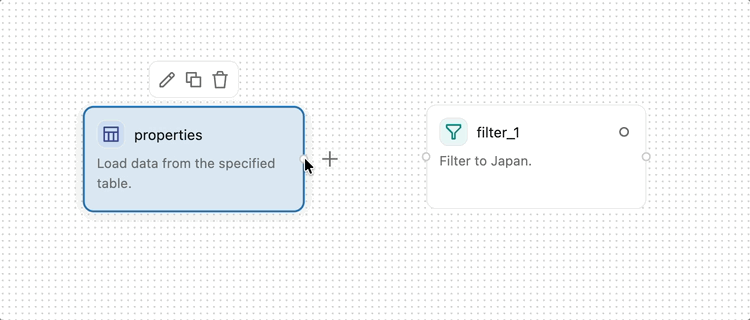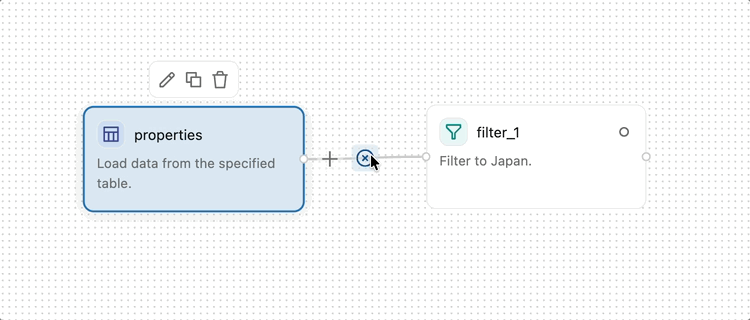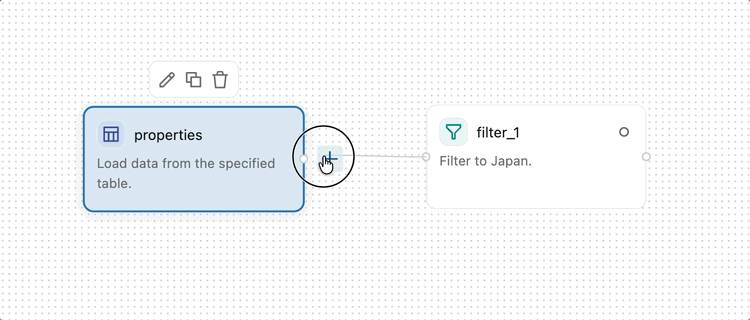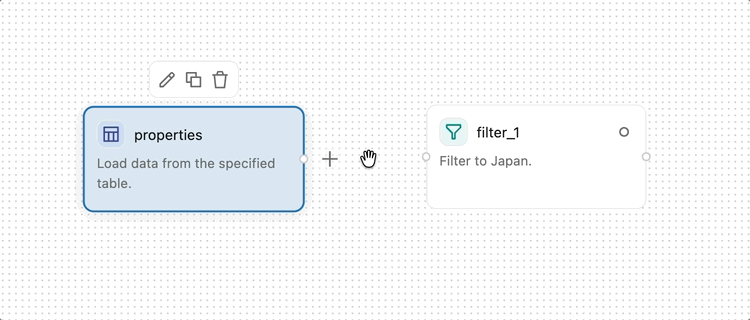
Some operators, such as Join and Combine, accept multiple inputs.
To remove a connection, hold the pointer over it and click ![]() in the toolbar that appears over the connection.
in the toolbar that appears over the connection.
Use Genie Code
At any time while editing in Lakeflow Designer, you can create prompts to Genie Code to help. See Genie Code.
When using Genie Code, the following buttons provide additional functionality:
 : Uploads an image to use as part of the prompt.
: Uploads an image to use as part of the prompt. : Use to mention objects, such as tables or files, to use as part of the prompt.
: Use to mention objects, such as tables or files, to use as part of the prompt. : Starts a new chat thread with new agent context.
: Starts a new chat thread with new agent context. : Opens the side pane for conversation history, and a more detailed view of what the agent is doing.
: Opens the side pane for conversation history, and a more detailed view of what the agent is doing.
Genie Code shows a one-line summary of its most recent edit above the input box.
Preview results
Select any operator to see the results in the output pane at the bottom of the screen. For most operator types, the input data is on the left and output data is on the right. Operators that produce non-table results, such as plots, HTML, or images, render those outputs directly in the output pane.
Use the view control in the output pane to switch between input and output (the default), input only, or output only. In the combined view, drag the divider to resize the input and output panes.
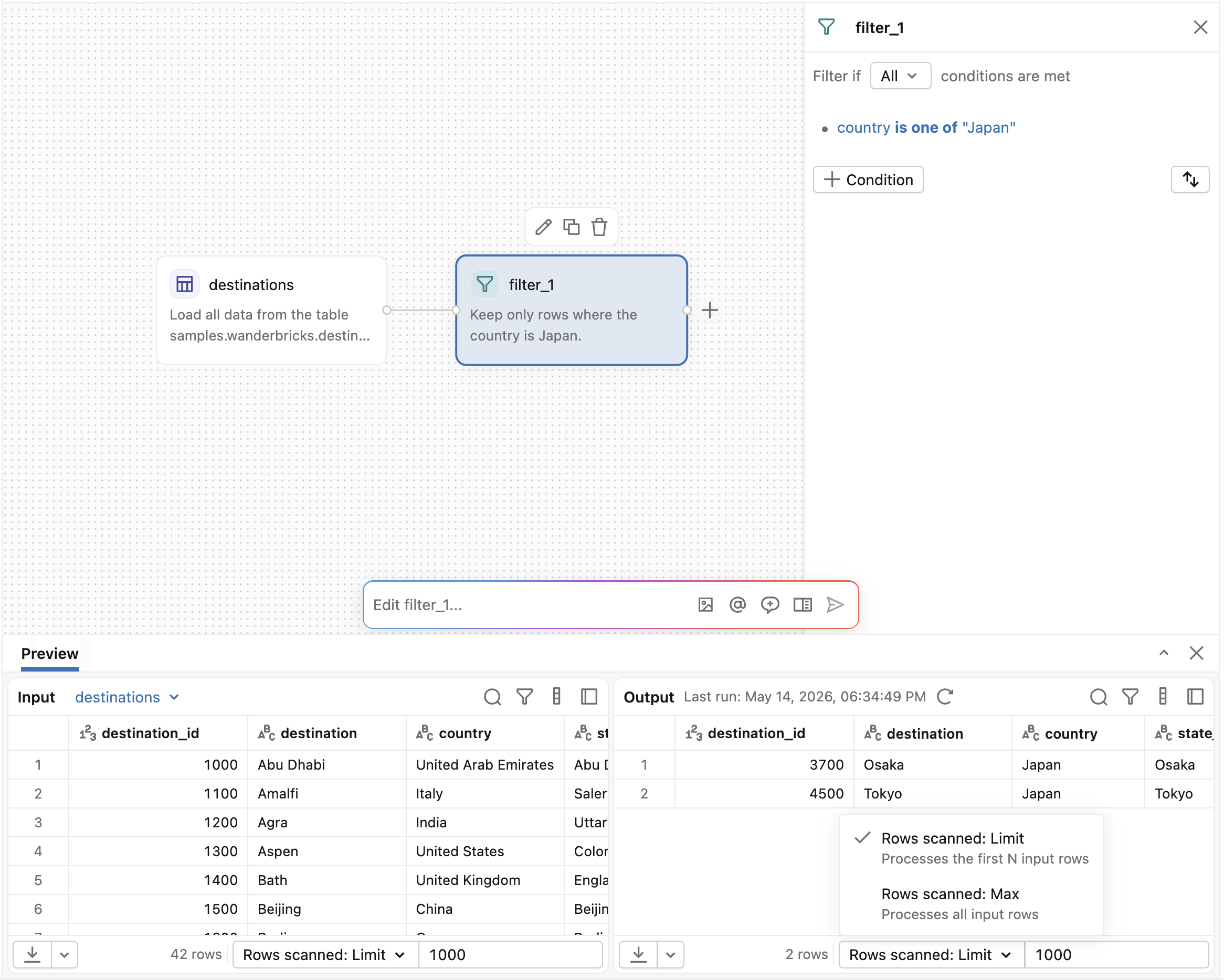
By default, operators process a limited sample of data, for previews. Use the Rows scanned dropdown in the output pane to control how many rows to process:
- Rows scanned: Limit: Processes the first N input rows. Specify the number of rows in the field next to the dropdown.
- Rows scanned: Max: Processes all input rows.
Warning
Running with Rows scanned: Max reruns all upstream operators with the complete, unbounded dataset and can take a long time.
The Rows scanned setting controls preview processing only. Scheduled runs and job runs always process the complete dataset.
Write results to Unity Catalog
Add an Output operator to write your results to a table in Unity Catalog:
- Open the operator menu and select Output, or click + next to your last operator and select Output.
- Connect the output handle of your last transformation to the Output operator's input handle if not already connected.
- Double-click the Output operator to open its configuration pane.
- Type a Table name and select the Output location (catalog and schema).
- Click Run.
Each run creates or replaces the managed output table, so scheduled runs overwrite it rather than appending. See Output.
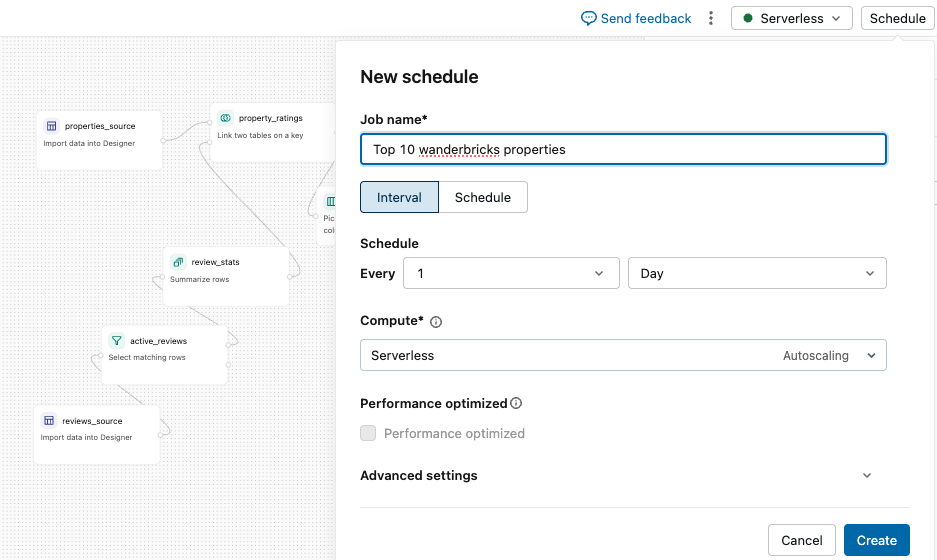
Schedule or run in production
You can automate your workflows by scheduling them as jobs.
- Schedule directly: Click the Schedule button in the top menu to create a scheduled job for your visual data prep.
- Add to a job: Create a Azure Databricks job and choose your visual data prep as a task. This lets you combine that visual data prep with other tasks in a larger pipeline.
To view and manage existing schedules, click Schedule again to open the list. Click Add schedule to create another, or open a schedule's ![]() kebab menu to Edit, Run now, Pause, Clone, View in Jobs, or Delete it.
kebab menu to Edit, Run now, Pause, Clone, View in Jobs, or Delete it.
When you schedule a visual data prep, you can optionally override its parameter values for that schedule. For example, you can create one schedule that runs with an environment parameter set to test and another that runs with it set to production. See Parameters.
Store and manage visual data prep files
Visual data prep files are stored natively in the workspace. You can export them, import them, and track them with Git when they are placed inside a Git folder.
Export a visual data prep file
- Click
 in the top-right corner.
in the top-right corner. - Select File > Export.
- The file is exported as
<file_name>.designer.ipynb.
Import a visual data prep file
- In the workspace file system, click .
- Select Import.
- Choose the visual data prep file to import.
Use visual data prep files with Git
- Create a Git folder in your workspace.
- Move the visual data prep file into that Git folder.
- Track, commit, and version the file like any other notebook in Git.
- In Git, the file appears as
<file_name>.designer.ipynb.
Rename a visual data prep
To rename a visual data prep, click the tab showing its name at the top of the editor, then type a new name.
Delete a visual data prep
To delete a visual data prep, open the ![]() kebab menu for the file and select Move to trash.
kebab menu for the file and select Move to trash.
To delete multiple visual data prep files at once, open Workspace from the left navigation, select the files you want to remove, and choose Move to trash at the top of the list.
Additional tips when working in the canvas
The following actions are available on the canvas to help you edit your visual data prep.
- Rename an operator: Click the text field at the top of any configuration pane to rename the operator. Descriptive names make your visual data prep easier to understand at a glance. Some operators, such as the SQL operator, can reference the output of other operators by name.
- Copy an operator: Hold the pointer over an operator and click
 , or select an operator and press Cmd/Ctrl+C then Cmd/Ctrl+V.
, or select an operator and press Cmd/Ctrl+C then Cmd/Ctrl+V. - Delete an operator: Hold the pointer over an operator and click
 in the toolbar that appears above it, or select the operator and press Delete.
in the toolbar that appears above it, or select the operator and press Delete. - Auto-layout: Click
 in the header toolbar to automatically arrange all operators in a compact layout.
in the header toolbar to automatically arrange all operators in a compact layout. - Fit view: Click
 in the header toolbar to see all operators in the current viewport.
in the header toolbar to see all operators in the current viewport. - Undo and redo: Press Cmd/Ctrl+Z and Cmd/Ctrl+Shift+Z, or use the undo and redo buttons in the header toolbar.
- View generated code: To see the PySpark code generated by Designer, open Version history in the right pane, push the file to a Git folder and view it there, or view the code in the job run details.
- View version history: Click
 in the right pane to open the visual data prep's version history, which lists its changes. Select a version to compare it with the following version.
in the right pane to open the visual data prep's version history, which lists its changes. Select a version to compare it with the following version.