Best practices for scaling provisioned throughput (RU/s)
APPLIES TO:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Cassandra
Cassandra
![]() Gremlin
Gremlin
![]() Table
Table
This article describes best practices and strategies for scaling the throughput (RU/s) of your database or container (collection, table, or graph). The concepts apply when you're increasing either the provisioned manual RU/s or the autoscale max RU/s of any resource for any of the Azure Cosmos DB APIs.
Prerequisites
- If you're new to partitioning and scaling in Azure Cosmos DB, it's recommended to first read the article Partitioning and horizontal scaling in Azure Cosmos DB.
- If you're planning to scale your RU/s due to 429 exceptions, review the guidance in Diagnose and troubleshoot Azure Cosmos DB request rate too large (429) exceptions. Before increasing RU/s, identify the root cause of the issue and whether increasing RU/s is the right solution.
Background on scaling RU/s
When you send a request to increase the RU/s of your database or container, depending on your requested RU/s and your current physical partition layout, the scale-up operation will either complete instantly or asynchronously (typically 4-6 hours).
- Instant scale-up
- When your requested RU/s can be supported by the current physical partition layout, Azure Cosmos DB doesn’t need to split or add new partitions.
- As a result, the operation completes immediately and the RU/s are available for use.
- Asynchronous scale-up
- When the requested RU/s are higher than what can be supported by the physical partition layout, Azure Cosmos DB will split existing physical partitions. This occurs until the resource has the minimum number of partitions required to support the requested RU/s.
- As a result, the operation can take some time to complete, typically 4-6 hours. Each physical partition can support a maximum of 10,000 RU/s (applies to all APIs) of throughput and 50 GB of storage (applies to all APIs, except Cassandra, which has 30 GB of storage).
Note
If you perform a manual region failover operation or add/remove a new region while an asynchronous scale-up operation is in progress, the throughput scale-up operation will be paused. It will resume automatically when the failover or add/remove region operation is complete.
- Instant scale-down
- For scale down operation Azure Cosmos DB doesn’t need to split or add new partitions.
- As a result, the operation completes immediately and the RU/s are available for use,
- Key result of this operation is that RUs per physical partition will be reduced.
How to scale-up RU/s without changing partition layout
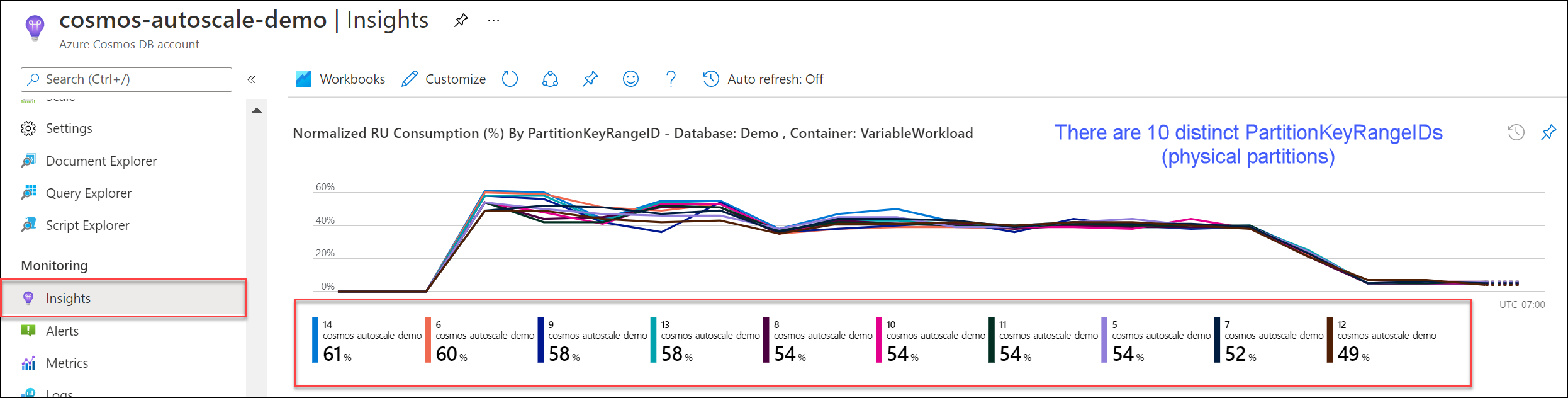
Step 1: Find the current number of physical partitions.
Navigate to Insights > Throughput > Normalized RU Consumption (%) By PartitionKeyRangeID. Count the distinct number of PartitionKeyRangeIds.
Note
The chart will only show a maximum of 50 PartitionKeyRangeIds. If your resource has more than 50, you can use the Azure Cosmos DB REST API to count the total number of partitions.
Each PartitionKeyRangeId maps to one physical partition and is assigned to hold data for a range of possible hash values.
Azure Cosmos DB distributes your data across logical and physical partitions based on your partition key to enable horizontal scaling. As data gets written, Azure Cosmos DB uses the hash of the partition key value to determine which logical and physical partition the data lives on.
Step 2: Calculate the default maximum throughput
The highest RU/s you can scale to without triggering Azure Cosmos DB to split partitions is equal to Current number of physical partitions * 10,000 RU/s. You can get this value from the Azure Cosmos DB Resource Provider. Perform a GET request on your database or container throughput setting objects and retrieve the instantMaximumThroughput property. This value is also available in the Scale and Settings page of your database or container in the portal.
Example
Suppose we have an existing container with five physical partitions and 30,000 RU/s of manual provisioned throughput. We can increase the RU/s to 5 * 10,000 RU/s = 50,000 RU/s instantly. Similarly if we had a container with autoscale max RU/s of 30,000 RU/s (scales between 3000 - 30,000 RU/s), we could increase our max RU/s to 50,000 RU/s instantly (scales between 5000 - 50,000 RU/s).
Tip
If you are scaling up RU/s to respond to request rate too large exceptions (429s), it's recommended to first increase RU/s to the highest RU/s that are supported by your current physical partition layout and assess if the new RU/s is sufficient before increasing further.
How to ensure even data distribution during asynchronous scaling
Background
When you increase the RU/s beyond the current number of physical partitions * 10,000 RU/s, Azure Cosmos DB splits existing partitions, until the new number of partitions = ROUNDUP(requested RU/s / 10,000 RU/s). During a split, parent partitions are split into two children partitions.
For example, suppose we have a container with three physical partitions and 30,000 RU/s of manual provisioned throughput. If we increased the throughput to 45,000 RU/s, Azure Cosmos DB will split two of the existing physical partitions so that in total, there are ROUNDUP(45,000 RU/s / 10,000 RU/s) = 5 physical partitions.
Note
Applications can always ingest or query data during a split. The Azure Cosmos DB client SDKs and service automatically handle this scenario and ensure that requests are routed to the correct physical partition, so no additional user action is required.
If you have a workload that is very evenly distributed with respect to storage and request volume—typically accomplished by partitioning by high cardinality fields like /id—it's recommended when you scale-up, set RU/s such that all partitions are split evenly.
To see why, let's take an example where we have an existing container with 2 physical partitions, 20,000 RU/s, and 80 GB of data.
Thanks to choosing a good partition key with high cardinality, the data is roughly evenly distributed in both physical partitions. Each physical partition is assigned roughly 50% of the keyspace, which is defined as the total range of possible hash values.
In addition, Azure Cosmos DB distributes RU/s evenly across all physical partitions. As a result, each physical partition has 10,000 RU/s and 50% (40 GB) of the total data. The following diagram shows our current state.

Now, suppose we want to increase our RU/s from 20,000 RU/s to 30,000 RU/s.
If we simply increased the RU/s to 30,000 RU/s, only one of the partitions will be split. After the split, we will have:
- One partition that contains 50% of the data (this partition wasn't split)
- Two partitions that contain 25% of the data each (these are the resulting child partitions from the parent that was split)
Because Azure Cosmos DB distributes RU/s evenly across all physical partitions, each physical partition will still get 10,000 RU/s. However, we now have a skew in storage and request distribution.
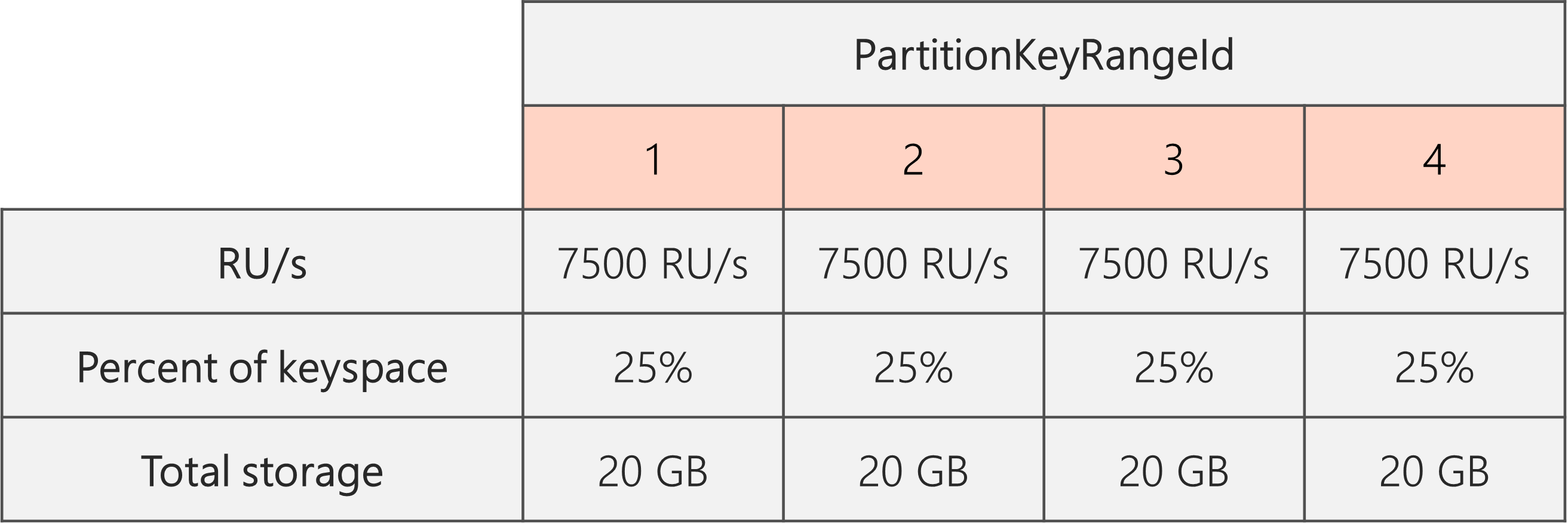
In the following diagram, we see that Partitions 3 and 4 (the children partitions of Partition 2) each have 10,000 RU/s to serve requests for 20 GB of data, while Partition 1 has 10,000 RU/s to serve requests for twice the amount of data (40 GB).

To maintain an even storage distribution, we can first scale up our RU/s to ensure every partition splits. Then, we can lower our RU/s back down to the desired state.
So, if we start with two physical partitions, to guarantee that the partitions are even post-split, we need to set RU/s such that we'll end up with four physical partitions. To achieve this, we'll first set RU/s = 4 * 10,000 RU/s per partition = 40,000 RU/s. Then, after the split completes, we can lower our RU/s to 30,000 RU/s.
As a result, we see in the following diagram that each physical partition gets 30,000 RU/s / 4 = 7500 RU/s to serve requests for 20 GB of data. Overall, we maintain even storage and request distribution across partitions.
General formula
Step 1: Increase your RU/s to guarantee that all partitions split evenly
In general, if you have a starting number of physical partitions P, and want to set a desired RU/s S:
Increase your RU/s to: 10,000 * P * (2 ^ (ROUNDUP(LOG_2 (S/(10,000 * P)))). This gives the closest RU/s to the desired value that will ensure all partitions are split evenly.
Note
When you increase the RU/s of a database or container, this can impact the minimum RU/s you can lower to in the future. Typically, the minimum RU/s is equal to MAX(400 RU/s, Current storage in GB * 1 RU/s, Highest RU/s ever provisioned / 100). For example, if the highest RU/s you've ever scaled to is 100,000 RU/s, the lowest RU/s you can set in the future is 1000 RU/s. Learn more about minimum RU/s.
Step 2: Lower your RU/s to the desired RU/s
For example, suppose we have five physical partitions, 50,000 RU/s and want to scale to 150,000 RU/s. We should first set: 10,000 * 5 * (2 ^ (ROUND(LOG_2(150,000/(10,000 * 5)))) = 200,000 RU/s, and then lower to 150,000 RU/s.
When we scaled up to 200,000 RU/s, the lowest manual RU/s we can now set in the future is 2000 RU/s. The lowest autoscale max RU/s we can set is 20,000 RU/s (scales between 2000 - 20,000 RU/s). Since our target RU/s is 150,000 RU/s, we are not affected by the minimum RU/s.
How to optimize RU/s for large data ingestion
When you plan to migrate or ingest a large amount of data into Azure Cosmos DB, it's recommended to set the RU/s of the container so that Azure Cosmos DB pre-provisions the physical partitions needed to store the total amount of data you plan to ingest upfront. Otherwise, during ingestion, Azure Cosmos DB may have to split partitions, which adds more time to the data ingestion.
We can take advantage of the fact that during container creation, Azure Cosmos DB uses the heuristic formula of starting RU/s to calculate the number of physical partitions to start with.
Step 1: Review the choice of partition key
Follow best practices for choosing a partition key to ensure you will have even distribution of request volume and storage post-migration.
Step 2: Calculate the number of physical partitions you'll need
Number of physical partitions = Total data size in GB / Target data per physical partition in GB
Each physical partition can hold a maximum of 50 GB of storage (30 GB for API for Cassandra). The value you should choose for the Target data per physical partition in GB depends on how fully packed you want the physical partitions to be and how much you expect storage to grow post-migration.
For example, if you anticipate that storage will continue to grow, you may choose to set the value to 30 GB. Assuming you've chosen a good partition key that evenly distributes storage, each partition will be ~60% full (30 GB out of 50 GB). As future data is written, it can be stored on the existing set of physical partitions, without requiring the service to immediately add more physical partitions.
In contrast, if you believe that storage will not grow significantly post-migration, you may choose to set the value higher, for example 45 GB. This means each partition will be ~90% full (45 GB out of 50 GB). This minimizes the number of physical partitions your data is spread across, which means each physical partition can get a larger fraction of the total provisioned RU/s.
Step 3: Calculate the number of RU/s to start with for all partitions
Starting RU/s for all partitions = Number of physical partitions * Initial throughput per physical partition.
Let's start with an example with an arbitrary number of target RU/s per physical partition.
Initial throughput per physical partition= 10,000 RU/s per physical partition when using autoscale or shared throughput databasesInitial throughput per physical partition= 6000 RU/s per physical partition when using manual throughput
Example
Let's say we have 1 TB (1000 GB) of data we plan to ingest and we want to use manual throughput. Each physical partition in Azure Cosmos DB has a capacity of 50 GB. Let's assume we aim to pack partitions to be 80% full (40 GB), leaving us room for future growth.
This means that for 1 TB of data, we'll need 1000 GB / 40 GB = 25 physical partitions. To ensure we'll get 25 physical partitions, if we're using manual throughput, we first provision 25 * 6000 RU/s = 150,000 RU/s. Then, after the container is created, to help our ingestion go faster, we increase the RU/s to 250,000 RU/s before the ingestion begins (happens instantly because we already have 25 physical partitions). This allows each partition to get the maximum of 10,000 RU/s.
If we're using autoscale throughput or a shared throughput database, to get 25 physical partitions, we'd first provision 25 * 10,000 RU/s = 250,000 RU/s. Because we are already at the highest RU/s that can be supported with 25 physical partitions, we would not further increase our provisioned RU/s before the ingestion.
In theory, with 250,000 RU/s and 1 TB of data, if we assume 1-kb documents and 10 RUs required for write, the ingestion can theoretically complete in: 1000 GB * (1,000,000 kb / 1 GB) * (1 document / 1 kb) * (10 RU / document) * (1 sec / 250,000 RU) * (1 hour / 3600 seconds) = 11.1 hours.
This calculation is an estimate assuming the client performing the ingestion can fully saturate the throughput and distribute writes across all physical partitions. As a best practice, it’s recommended to “shuffle” your data on the client-side. This ensures that each second, the client is writing to many distinct logical (and thus physical) partitions.
Once the migration is over, we can lower the RU/s or enable autoscale as needed.
Next steps
- Monitor normalized RU/s consumption of your database or container.
- Diagnose and troubleshoot request rate too large (429) exceptions.
- Enable autoscale on a database or container.