Continuous integration and delivery in Azure Data Factory
APPLIES TO:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
Continuous integration is the practice of testing each change made to your codebase automatically and as early as possible. Continuous delivery follows the testing that happens during continuous integration and pushes changes to a staging or production system.
In Azure Data Factory, continuous integration and delivery (CI/CD) means moving Data Factory pipelines from one environment (development, test, production) to another. Azure Data Factory utilizes Azure Resource Manager templates to store the configuration of your various ADF entities (pipelines, datasets, data flows, and so on). There are two suggested methods to promote a data factory to another environment:
- Automated deployment using Data Factory's integration with Azure Pipelines
- Manually upload a Resource Manager template using Data Factory UX integration with Azure Resource Manager.
Note
We recommend that you use the Azure Az PowerShell module to interact with Azure. To get started, see Install Azure PowerShell. To learn how to migrate to the Az PowerShell module, see Migrate Azure PowerShell from AzureRM to Az.
CI/CD lifecycle
Note
For more information, see Continuous deployment improvements.
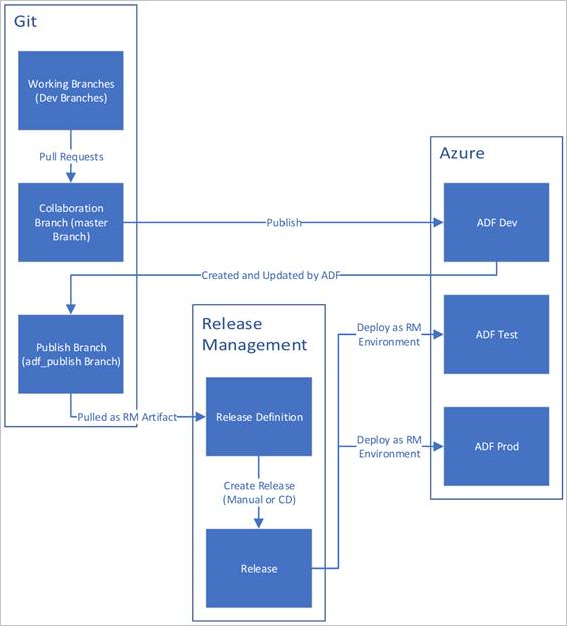
Below is a sample overview of the CI/CD lifecycle in an Azure data factory that's configured with Azure Repos Git. For more information on how to configure a Git repository, see Source control in Azure Data Factory.
A development data factory is created and configured with Azure Repos Git. All developers should have permission to author Data Factory resources like pipelines and datasets.
A developer creates a feature branch to make a change. They debug their pipeline runs with their most recent changes. For more information on how to debug a pipeline run, see Iterative development and debugging with Azure Data Factory.
After a developer is satisfied with their changes, they create a pull request from their feature branch to the main or collaboration branch to get their changes reviewed by peers.
After a pull request is approved and changes are merged in the main branch, the changes get published to the development factory.
When the team is ready to deploy the changes to a test or UAT (User Acceptance Testing) factory, the team goes to their Azure Pipelines release and deploys the desired version of the development factory to UAT. This deployment takes place as part of an Azure Pipelines task and uses Resource Manager template parameters to apply the appropriate configuration.
After the changes have been verified in the test factory, deploy to the production factory by using the next task of the pipelines release.
Note
Only the development factory is associated with a git repository. The test and production factories shouldn't have a git repository associated with them and should only be updated via an Azure DevOps pipeline or via a Resource Management template.
The below image highlights the different steps of this lifecycle.
Best practices for CI/CD
If you're using Git integration with your data factory and have a CI/CD pipeline that moves your changes from development into test and then to production, we recommend these best practices:
Git integration. Configure only your development data factory with Git integration. Changes to test and production are deployed via CI/CD and don't need Git integration.
Pre- and post-deployment script. Before the Resource Manager deployment step in CI/CD, you need to complete certain tasks, like stopping and restarting triggers and performing cleanup. We recommend that you use PowerShell scripts before and after the deployment task. For more information, see Update active triggers. The data factory team has provided a script to use located at the bottom of this page.
Note
Use the PrePostDeploymentScript.Ver2.ps1 if you would like to turn off/ on only the triggers that have been modified instead of turning all triggers off/ on during CI/CD.
Warning
Make sure to use PowerShell Core in ADO task to run the script.
Warning
If you do not use latest versions of PowerShell and Data Factory module, you may run into deserialization errors while running the commands.
Integration runtimes and sharing. Integration runtimes don't change often and are similar across all stages in your CI/CD. So Data Factory expects you to have the same name, type and sub-type of integration runtime across all stages of CI/CD. If you want to share integration runtimes across all stages, consider using a ternary factory just to contain the shared integration runtimes. You can use this shared factory in all of your environments as a linked integration runtime type.
Note
The integration runtime sharing is only available for self-hosted integration runtimes. Azure-SSIS integration runtimes don't support sharing.
Managed private endpoint deployment. If a private endpoint already exists in a factory and you try to deploy an ARM template that contains a private endpoint with the same name but with modified properties, the deployment will fail. In other words, you can successfully deploy a private endpoint as long as it has the same properties as the one that already exists in the factory. If any property is different between environments, you can override it by parameterizing that property and providing the respective value during deployment.
Key Vault. When you use linked services whose connection information is stored in Azure Key Vault, it is recommended to keep separate key vaults for different environments. You can also configure separate permission levels for each key vault. For example, you might not want your team members to have permissions to production secrets. If you follow this approach, we recommend that you to keep the same secret names across all stages. If you keep the same secret names, you don't need to parameterize each connection string across CI/CD environments because the only thing that changes is the key vault name, which is a separate parameter.
Resource naming. Due to ARM template constraints, issues in deployment may arise if your resources contain spaces in the name. The Azure Data Factory team recommends using '_' or '-' characters instead of spaces for resources. For example, 'Pipeline_1' would be a preferable name over 'Pipeline 1'.
Altering repository. ADF manages GIT repository content automatically. Altering or adding manually unrelated files or folder into anywhere in ADF Git repository data folder could cause resource loading errors. For example, presence of .bak files can cause ADF CI/CD error, so they should be removed for ADF to load.
Exposure control and feature flags. When working in a team, there are instances where you may merge changes, but don't want them to be run in elevated environments such as PROD and QA. To handle this scenario, the ADF team recommends the DevOps concept of using feature flags. In ADF, you can combine global parameters and the if condition activity to hide sets of logic based upon these environment flags.
To learn how to set up a feature flag, see the below video tutorial:
Unsupported features
By design, Data Factory doesn't allow cherry-picking of commits or selective publishing of resources. Publishes will include all changes made in the data factory.
- Data factory entities depend on each other. For example, triggers depend on pipelines, and pipelines depend on datasets and other pipelines. Selective publishing of a subset of resources could lead to unexpected behaviors and errors.
- On rare occasions when you need selective publishing, consider using a hotfix. For more information, see Hotfix production environment.
The Azure Data Factory team doesn’t recommend assigning Azure RBAC controls to individual entities (pipelines, datasets, etc.) in a data factory. For example, if a developer has access to a pipeline or a dataset, they should be able to access all pipelines or datasets in the data factory. If you feel that you need to implement many Azure roles within a data factory, look at deploying a second data factory.
You can't publish from private branches.
You can't currently host projects on Bitbucket.
You can't currently export and import alerts and matrices as parameters.
Partial ARM templates in your publish branch are no longer supported as of November 1, 2021. If your project utilized this feature, please switch to a supported mechanism for deployments, using:
ARMTemplateForFactory.jsonorlinkedTemplatesfiles.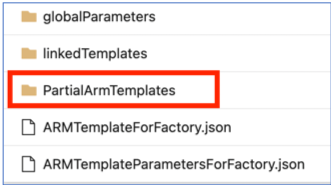
Related content
- Continuous deployment improvements
- Automate continuous integration using Azure Pipelines releases
- Manually promote a Resource Manager template to each environment
- Use custom parameters with a Resource Manager template
- Linked Resource Manager templates
- Using a hotfix production environment
- Sample pre- and post-deployment script